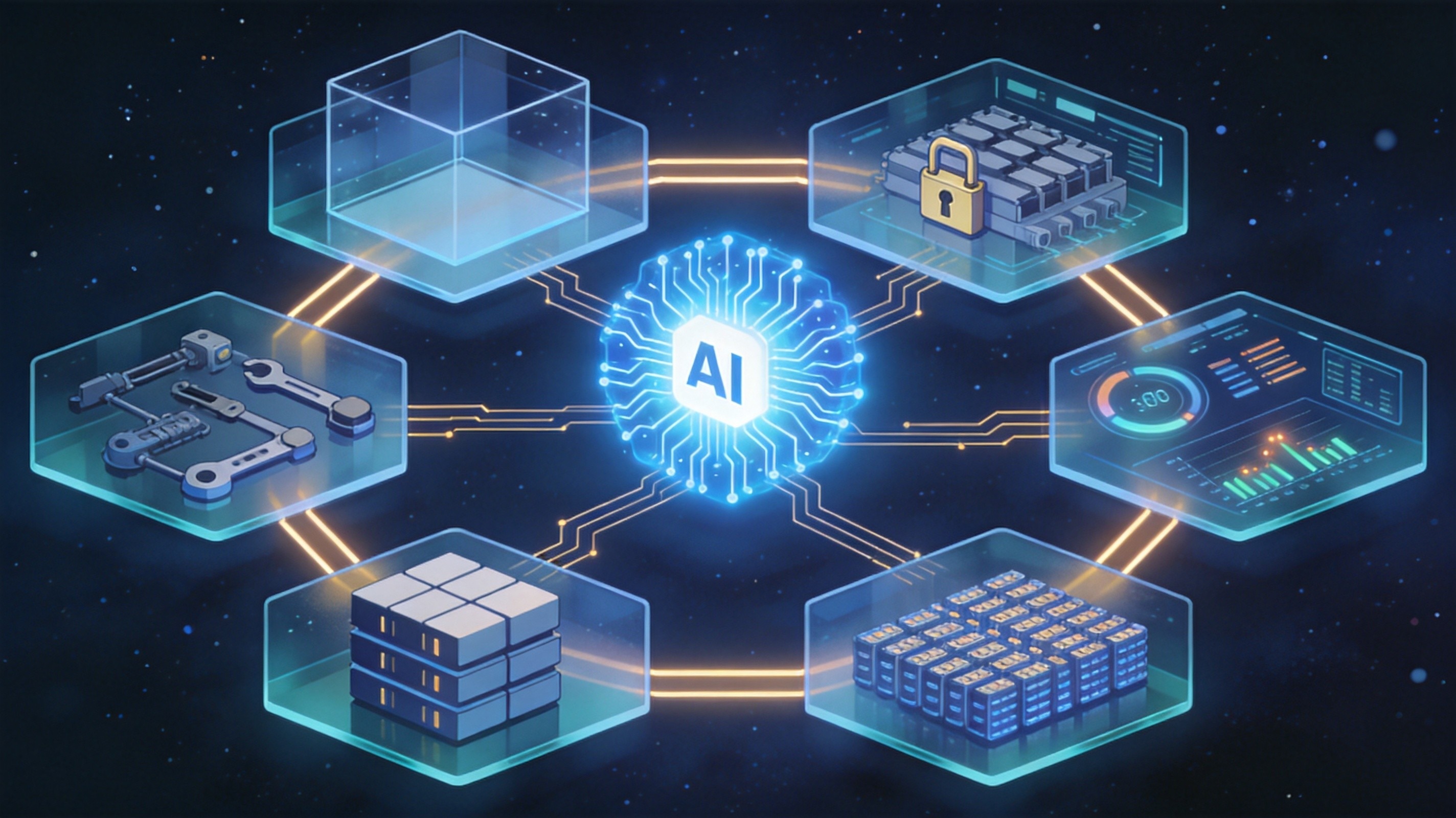
企业搭建 AI 基础设施,为什么不能只看算力?
很多企业做 AI,第一反应是先买算力、接模型、搭平台。
但真正落地后会发现,AI 基础设施不是一个单点能力部署,而是一条完整链路。算力只是开始,后面还有模型怎么调用、Token 成本怎么算、网络稳不稳、数据能不能信、智能体能不能接进业务流程、团队会不会用这些问题。
如果这些环节没有打通,AI 应用很容易停留在试点阶段:模型能跑,但跑不稳;业务能接,但不好管;数据能查,但不敢信;成本在增加,但价值不清楚。
一、算力不是越多越好,关键是能不能统一调度
AI 应用要跑,底层离不开算力。但企业真实环境里的算力资源往往很复杂:不同厂商、不同架构、不同集群、不同机房同时存在,GPU、NPU、CPU 混合使用也很常见。
如果缺少统一管理,算力很容易变成资源孤岛。看起来资源不少,但真正用起来,可能会出现任务排队、资源闲置、调度困难、利用率不高等问题。
所以,AI 基础设施的第一步,不只是“有算力”,而是把异构算力统一纳管起来,形成可调度、可分配、可监控的资源池。
二、模型调用越多,越需要统一入口和成本管理
企业使用大模型时,往往不会只用一个模型。开源模型、商业模型、私有模型、行业模型可能同时存在,不同部门、不同业务也会选择不同模型。
问题随之而来:接口不统一、权限不好管、调用成本不透明、Token 消耗看不清、安全审计难追溯。
尤其到了智能体阶段,一个任务可能连续调用多个模型和工具,Token 消耗会快速放大。这个时候,模型调用就不能只靠业务部门各自接入,而需要统一的模型入口、Token 计量、调度策略、成本分析和安全审计能力。
三、网络问题会直接影响 AI 任务效率
很多人聊 AI 基础设施,容易只看算力和模型,但网络同样关键。
AI 训练、推理、数据同步、跨集群调用都依赖网络。任务变慢时,不一定是模型效果差,也可能是链路拥塞、静默丢包、网络抖动、异常流量占用资源。
因此,AI 基础设施需要具备算网协同能力。简单说,就是要看清算力、网络、存储和业务之间的关系,知道问题出在哪里,并能尽快定位和恢复。
同时,流量也不能只做带宽统计。对运营商、云服务商和大型企业来说,流量来源、业务结构、IP 关系、异常流量和成本构成,都会影响网络运营效率和业务体验。
四、数据能查到,不代表结论可信
企业通常不缺数据。业务系统、报表、数据仓库、Excel、接口数据都很多。真正的问题是:数据口径是否统一,查询过程是否透明,结果能不能复核。
很多企业都会遇到这种情况:同一个指标,不同部门查出来不一样;AI 给了答案,但不知道它按哪个口径算的;数据看起来有了,但不敢直接拿来做经营决策。
所以,AI 基础设施里还需要数据治理和语义层能力。不是简单让 AI 去查表,而是先把指标口径、业务术语、计算规则和权限体系统一起来,让数据结果有来源、有口径、可追溯、可复核。
五、AI 应用不能只停留在问答框里
企业最初做 AI 应用,常见场景是知识问答、客服助手、文档生成。这些场景有价值,但还不够。
真实业务往往不是“问一句、答一句”,而是一整套流程:查资料、调系统、生成内容、走审批、触发工具、输出结果。如果 AI 不能接入这些流程,就很难真正进入业务主干。
因此,企业需要智能体应用能力,把模型、知识库、工具系统和业务流程连接起来,让 AI 不只是回答问题,而是参与任务执行。
六、平台建起来以后,还要有人会用
AI 基础设施不是建完就结束。平台再多,工具再强,最后还是要有人会用、会管、会优化。
高校需要培养懂 AI、懂数据、懂实训的人才;企业需要让员工掌握新的工具和方法;个人也需要持续提升数智技能。
所以,人才培养也是 AI 基础设施落地的一部分。课程、实训、评测、认证和竞赛体系,决定了这些平台能力能不能长期转化为组织能力。
写在最后:AI Infra 是一条落地链路
说白了,AI 基础设施不是买几块 GPU、接几个模型、上线一个工具就结束了。
前面要有算力和模型调用,保证 AI 能跑;中间要有网络、流量和数据治理,保证 AI 跑得稳、结果可信;后面还要有智能体应用和人才培养,保证 AI 能真正进入业务、被长期用起来。
企业做 AI,真正影响落地效果的,往往不是某一个单点能力有多强,而是这些环节能不能连起来、跑顺了。
围绕这些方向,相关企业也在逐步形成覆盖算力纳管、模型调度、算网运维、流量分析、数据治理、智能体应用和数智人才培养的全栈能力,帮助企业补齐 AI 基础设施建设中的关键环节。

欢迎加入 MCP 技术社区!与志同道合者携手前行,一同解锁 MCP 技术的无限可能!
更多推荐


 0
0 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)