给 Agent 加一个规划与反思层
echo-agent 前身为 2025 年 11 月启动的个人助理项目 fubot,最初面向长期陪伴型个人智能体,围绕认知记忆、上下文延续、用户偏好沉淀、任务闭环与持续自我优化展开。随着真实场景迭代,项目逐步形成多入口接入、统一事件模型、消息总线、Agent Loop、多模型抽象、工具调用、MCP 接入、任务调度、权限审批、运行轨迹、长期记忆和受控自演进等能力。目前已支持微信、QQ、CLI、Gateway、Webhook、Cron 等入口,服务用户超过 20 万、累计下载超过 50 万,是面向长期运行、记忆增强和可持续成长智能体的开源 Agent Runtime。

你让 Agent “帮我修复测试失败”。它不能只看见这句话就立刻改代码。
更合理的过程应该是:先运行测试拿到证据,再定位模块,再做最小修改,最后重新验证。如果中间发现依赖缺失、权限不足或判断错误,它还要调整路线,而不是硬着头皮继续。
这就是规划与反思层要解决的问题:让 Agent 不再把任务执行压缩成一次模型输出,而是显式组织成目标、步骤、行动、观察和反馈。
问题入口
很多 Agent demo 会把“规划”写成一句提示词:
Please think step by step before using tools.
这有帮助,但不够。因为模型写出的“思考步骤”如果只是自然语言,它很容易变成回答里的装饰,对真实执行没有约束力。
一个能执行任务的 Agent 至少要回答三个问题:
| 问题 | 工程含义 |
|---|---|
| 下一步做什么 | 有明确步骤,而不是一次性猜结论 |
| 用什么能力做 | 步骤能关联工具、权限和上下文 |
| 做完怎么判断 | 执行结果能回写状态,并触发继续、停止或重规划 |
会写计划不等于会执行任务;计划只有进入状态、工具和反馈链路,才会成为 Agent 的控制结构。
为了不停留在抽象层面,下面以 echo-agent 的实现为例。当前规划系统位于 echo_agent.agent.planning:models.py 定义计划、步骤、行动和反馈;strategies.py 定义 ReAct、Plan-Execute、Tree-of-Thought、LATS;planner.py 负责策略选择;reflection.py 做结构化反馈。
先说清边界:当前主 Pipeline 对规划的集成是轻量的。ContextStage 创建计划并注入模型消息,InferenceStage 根据推理轮次标记步骤完成;但 AgentPlanner.execute_step 和 AgentPlanner.reflect 还没有完全替代模型原生工具调用。echo-agent 现在是“规划增强上下文”,不是“规划器接管执行”。
计划模型
规划不是替模型思考,而是约束任务结构。
如果计划只是普通文本,系统无法知道哪一步完成了、哪一步失败了、哪一步应该重试。生产级计划必须是结构化对象,至少包含步骤、状态、结果和当前进度。
echo-agent 的 PlanStep 大致可以理解成这样:
class StepStatus(str, Enum): PENDING = "pending" RUNNING = "running" COMPLETED = "completed" FAILED = "failed" SKIPPED = "skipped" @dataclass class PlanStep: index: int description: str tool_hint: str = "" status: StepStatus = StepStatus.PENDING result: str = "" reasoning: str = ""
这里最容易被忽略的是 tool_hint。规划器并不直接执行工具,但它可以给某一步提示可能使用的工具。模型在主推理循环里看到计划后,再结合实际工具定义决定是否调用。
完整计划 Plan 则维护目标、步骤、当前进度和反思结果。它提供 next_step、mark_step_complete、mark_step_failed 这类方法,让计划从静态文本变成可演进状态。
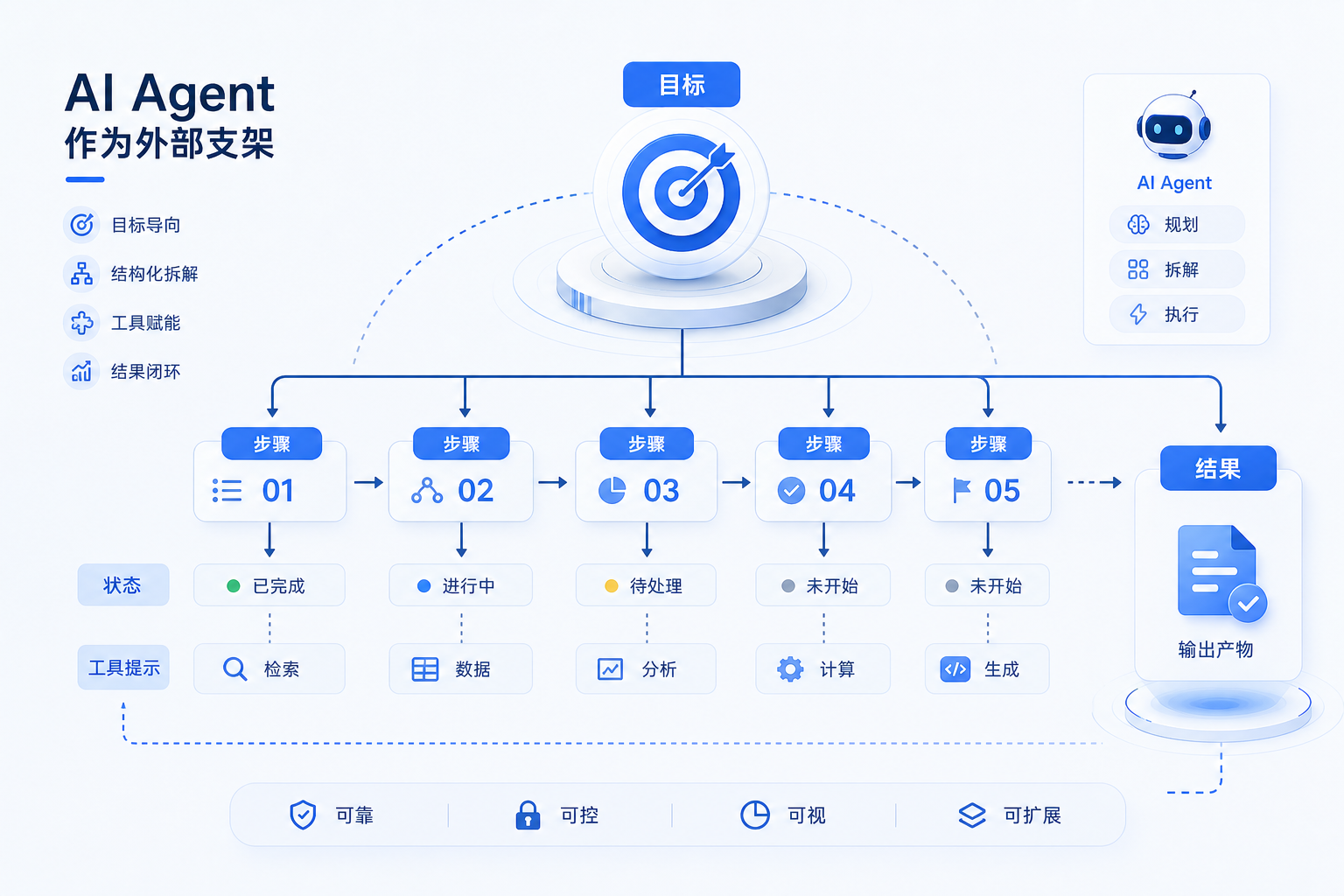
把书稿里的模型压缩成伪代码,大致是这样:
@dataclass class Plan: strategy: StrategyType goal: str steps: list[PlanStep] current_step: int = 0 is_complete: bool = False reflection: str = "" def next_step(self): for step in self.steps: if step.status == PENDING: return step def mark_step_complete(self, index, result): steps[index].status = COMPLETED steps[index].result = result current_step = index + 1 if all(step.status in (COMPLETED, SKIPPED) for step in steps): is_complete = True def mark_step_failed(self, index, error): steps[index].status = FAILED steps[index].result = error
这个结构允许部分成功。Agent 可能已经完成资料收集,但报告还没写完;可能已经改了代码,但测试没有全部通过。状态如果只有 success/failure,下一轮只能重新猜测已经发生了什么。
计划粒度也不能走极端。“修复测试失败”太粗;“打开第 37 行把变量名改成 x”又太细,因为失败点还没确认。更合适的是:先获取证据,再定位模块,再修改,再验证。
上下文注入
计划如何影响模型?
当前 echo-agent 的做法不是让规划器直接发起工具调用,而是在 ContextStage 创建计划后,把计划转成 prompt,追加到最后一条用户消息里:
if planner and tool_defs: plan = await planner.create_plan( query=user_text, tools=tool_defs, context=retrieval, token_estimate=len(user_text) // 4, ) if plan and plan.steps: messages[-1]["content"] += "\n\n[Plan]\n" + plan.to_prompt()
Plan.to_prompt() 会把策略、目标、步骤状态和已有结果格式化出来。于是模型在下一轮推理时,不只看到用户请求和工具定义,还看到一条明确的任务主线。
这种设计有两个好处。第一,侵入性低,原来的工具调用协议仍然可用,InferenceStage 不需要马上改造成复杂的计划执行器。第二,计划成为模型注意力的外部支架,把目标分解、依赖顺序和终止条件显式摆出来,降低遗漏步骤、重复探索和过早回答的概率。
它的不足也很清楚:计划不是强制约束。模型仍可能偏离计划,某一步失败后也不会自动进入完整搜索树回退。后续如果要增强,就需要让 execute_step 更深地接入 InferenceStage,由 StepAction 决定工具调用、回应、重规划或回退。
当前 echo-agent 的规划层更像任务脚手架:它帮助模型组织执行,但还没有把主循环完全变成 planner-driven execution。
策略选择
规划策略不是越复杂越好。
AgentPlanner 会注册四类策略:REACT、PLAN_EXECUTE、TREE_OF_THOUGHT 和 LATS。如果配置没有强制指定策略,它会根据输入长度和工具数量做轻量选择:短输入、少工具走 ReAct;工具很多或输入很长时走 Plan-Execute。
这背后的判断很现实:规划有成本。生成计划需要额外模型调用,复杂策略会增加延迟和 token 消耗。对一个简单问题强行使用复杂规划,可能不会更可靠,只会更慢。
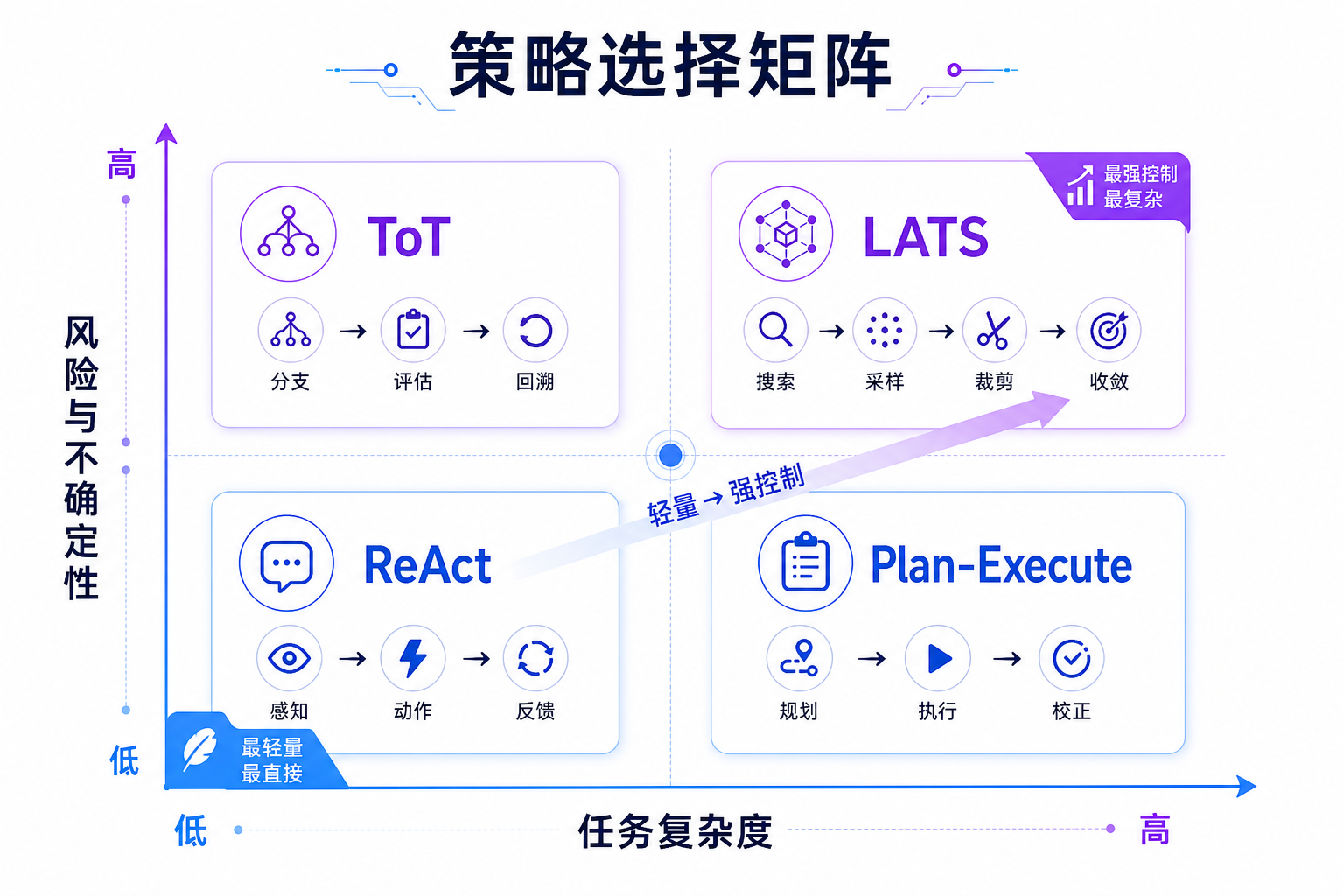
四种策略的边界可以这样理解:
| 策略 | 适用任务 | 优势 | 代价 |
|---|---|---|---|
| ReAct | 短任务、探索性任务 | 灵活,边观察边行动 | 全局结构弱 |
| Plan-Execute | 目标清楚、多步骤任务 | 先拆分再执行,结构清晰 | 初始计划可能被错误假设影响 |
| Tree-of-Thought | 多方案选择 | 降低第一条思路错误的风险 | 额外候选生成成本 |
| LATS | 需要回退和重规划 | 把失败反馈纳入下一步 | 当前实现只是轻量接口,不是完整搜索树 |
这里必须避免夸大。书稿里明确说明,Tree-of-Thought 当前是轻量版本:生成三个候选计划后,选择步骤最少的计划。LATS 也不是完整的蒙特卡洛树搜索实现,而是复用 Plan-Execute 创建计划,并在前一步失败时返回 replan 动作。
工程上这很常见:先稳定行动类型、失败状态、重规划入口和反馈格式,后面再增强搜索算法。关键是文档和代码要诚实描述当前能力。
反思信号
反思模块最容易被写虚。
如果只是让模型在回答末尾写一句“我应该更仔细”,它对系统没有价值。真正有用的反思应该变成可操作信号:目标是否完成,哪个步骤失败,是否应该重试、换工具、请求澄清、保存经验或重新规划。
echo-agent 的 ReflectionModule 要求模型调用 critique 工具,返回结构化字段:
Feedback( score=0.0_to_1.0, should_replan=True_or_False, critique="...", suggestions=[...], )
执行时,它会把 plan.to_prompt() 和每一步结果拼成输入,交给模型评估。调用成功就返回模型给出的字段;失败则返回默认反馈,例如 score=0.5、critique="Reflection unavailable"。
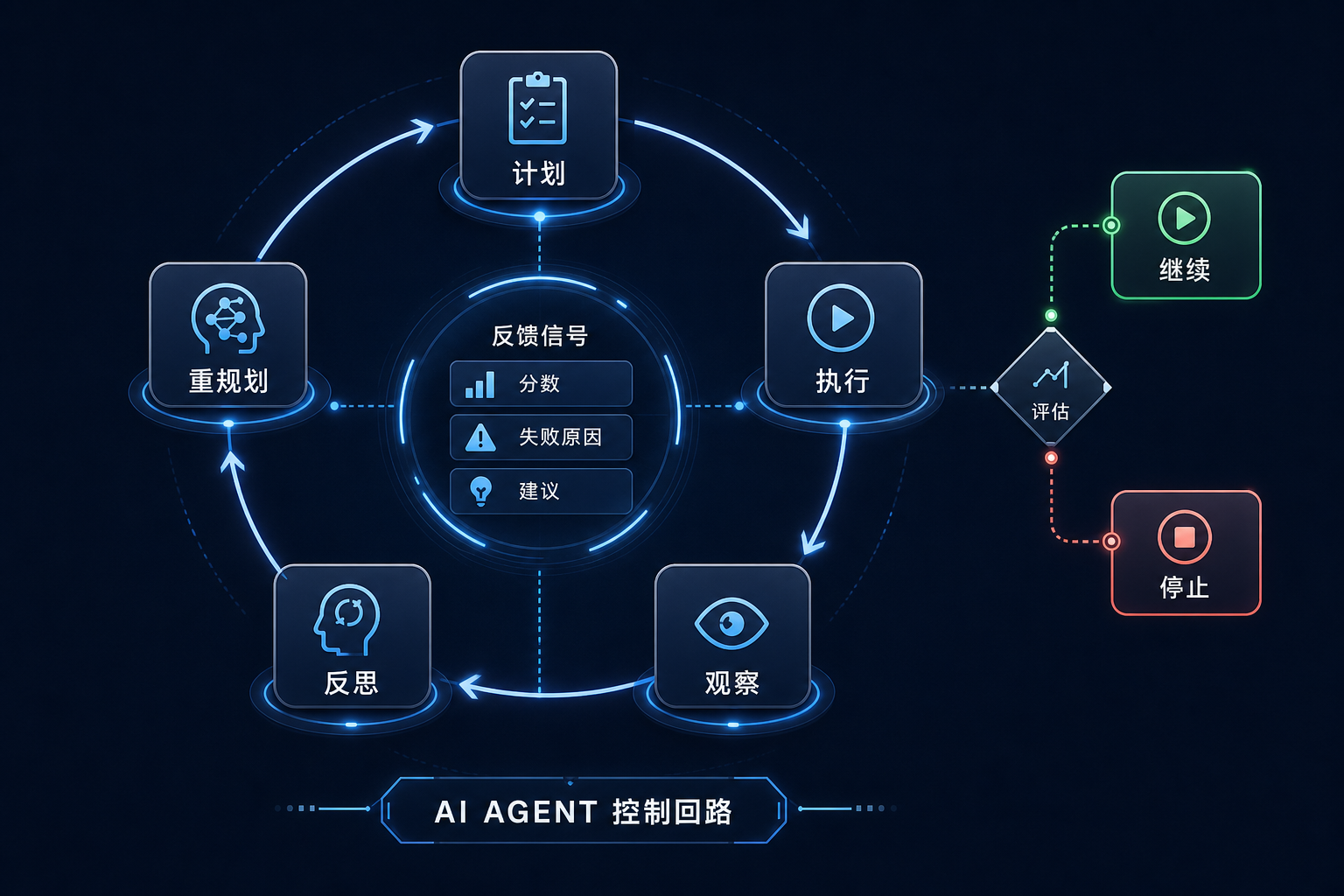
反思的关键不是“模型怎么看自己”,而是系统能不能消费结果。should_replan 可以触发重规划,score 可以进入评估,suggestions 可以成为技能复盘或记忆复盘的输入。
当然,反思也不能越权。模型认为某个动作安全,不代表可以跳过 ApprovalGate;模型认为某条经验重要,也不代表可以无条件写入长期记忆。反思是建议,不是授权。
安全边界
规划不能替代安全边界。
一个看似合理的计划,仍然可能包含不可接受的行动。比如删除旧文件、联网搜索、安装依赖,都可能触碰用户授权、网络策略或项目环境边界。
所以计划只是意图结构,不是权限许可。每个具体行动仍要经过工具策略、路径策略、网络策略和审批节点。
判断一个规划与反思层是否接近生产可用,可以看这些项:
| 检查项 | 可检验标准 |
|---|---|
| 结构化计划 | 每个步骤有状态、结果、当前进度,而不是纯文本清单 |
| 工具关联 | 步骤能表达 tool_hint,并能和真实工具定义对齐 |
| 状态回写 | 工具结果会更新步骤状态,失败不会被最终回答掩盖 |
| 反思结构 | 输出 score、should_replan、critique、suggestions 等字段 |
| 审批隔离 | 计划不能绕过只读、低风险写、高风险写工具的权限边界 |
| Trace 证据 | 每次计划创建、工具调用、失败、重规划都有可追踪记录 |
| 持久化能力 | 长任务能恢复部分成功状态,而不是重启后从头猜 |
| 回归评估 | 失败任务能沉淀为测试样本,约束后续版本退化 |
这里的核心判断很简单:计划负责降低复杂度,反思负责解释偏差,安全系统负责裁决行动。三者不能互相替代。
低风险短任务可以只用 ReAct。高风险自动化任务,例如自动发布、批量修改数据、跨系统写操作,计划就不能只是上下文提示;每个 StepAction 都要经过审批、执行、记录和反思。
小结
规划与反思层让 Agent 从“回答问题”走向“执行任务”。计划把复杂目标变成可讨论、可更新、可验证的中间表示;反思把执行偏差变成系统可消费的反馈信号。
echo-agent 当前没有把规划器包装成无所不能的控制中心。它先把计划注入上下文,让模型在工具循环中有一条任务主线;再用步骤状态和反思模块为后续增强留下接口。
对工程师来说,真正值得带走的不是某个策略名字,而是一条设计原则:不要把复杂任务交给模型在一次输出里自由发挥,也不要把计划写成僵硬脚本。好的 Agent 计划应该像一份可更新的工作契约,说明目标、步骤、约束、反馈和终止条件。
当计划能被执行记录校验,反思能进入控制回路,Agent 才真正从“会说下一步”走向“能沿着下一步把事情做完”。
(全篇完)
本文为 echo-agent 设计笔记系列第 11 篇。项目源码已开源至 GitHub。如果你对工业级 Agent 的工程落地感兴趣,欢迎加入技术交流群参与日常讨论。下一篇我们将探讨 《Agent 的上下文压缩:让长会话持续运行》,敬请期待。

欢迎加入 MCP 技术社区!与志同道合者携手前行,一同解锁 MCP 技术的无限可能!
更多推荐


 0
0 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)