飞书开放平台二次开发落地:工业级 PDF 高精度智能结构化解析方案,打通研发项目全流程闭环
一、研发行业文档处理真实业务背景
汽车电子、航空航天、芯片设计等高合规研发企业,上下游协同交付载体基本都是 PDF 文件,普遍存在两类 PDF 解析刚需:
-
项目需求场景:主机厂下发需求文档动辄数百至 6000 页,大量扫描影印、图文混排非标 PDF,需求团队需要快速拆解为标准化条目录入项目管理;
-
合规管控场景:国标、技术规范、合同协议等法规文件,需要完成条目结构化归档,支撑企业内部合规审查。
仅依靠原生 OCR 工具处理低清晰度扫描 PDF 识别误差极大,人工逐条拆解、修正、归档效率极低,文档分发、版本追溯更是缺少统一链路。 目前多数企业以飞书项目、飞书多维表、飞书知识库作为研发协同底座,但飞书原生文件能力仅支持基础预览,缺失超长 PDF 批量结构化、自动生成工作项、原文坐标溯源能力,这也是大量企业 IT 团队提出飞书二次开发定制需求的核心背景。
二、传统 PDF 处理模式四大技术痛点
结合多个项目落地反馈,纯人工、通用 OCR 工具存在无法规避的短板:
-
识别精度不足,人工修正成本高 普通 OCR 对模糊扫描件、倾斜图文 PDF 识别错乱,文字层级、编号丢失,工程师需要花费大量时间手动修正,单份千页文档修正耗时可达数天;
-
无自动结构化能力,条目化全靠手工 无法自动区分一级、二级需求条目,不能自动区分「正式需求 Requirement」与「补充说明 Information」,全部依靠人工复制粘贴,极易出现层级错乱;
-
缺少 PDF 原文双向追溯,不满足 ASPICE 审计 解析后的需求条目无法绑定 PDF 原始坐标,审计阶段核对需求只能来回切换文档,缺少完整追溯证据链,外审时存在合规风险;
-
数据割裂,无法自动同步飞书项目流程 第三方 PDF 工具解析结果无法对接飞书 Open API,结构化内容不能自动创建飞书项目工作项、同步多维表,研发数据链路断裂,形成信息孤岛。
三、技术落地方案:高远 PDF 高精度智能解析应用
针对上述行业痛点,我们基于飞书开放平台定制开发工业级 PDF 智能解析插件,采用大模型 + 行业专用小模型多层调优算法,搭建完整自动化链路: PDF 上传 → AI 多模态解析 → 文档结构化切片 → 自动创建飞书项目工作项,全流程内嵌飞书工作台,无需切换第三方系统,支持公有云、私有化飞书两种部署环境。
3.1 核心技术能力
-
超大容量多格式兼容 无页数上限,实测稳定解析 6000 页超长主机厂 PDF;兼容纯文字 PDF、低清晰度扫描件、图文混排、无原生大纲非标文档,针对汽车行业技术图纸配套 PDF 做专项模型优化;
-
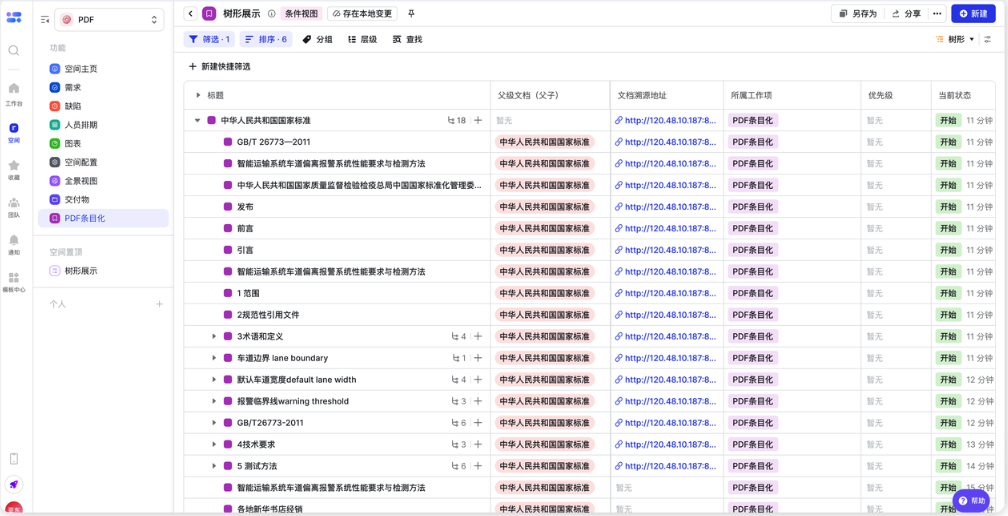
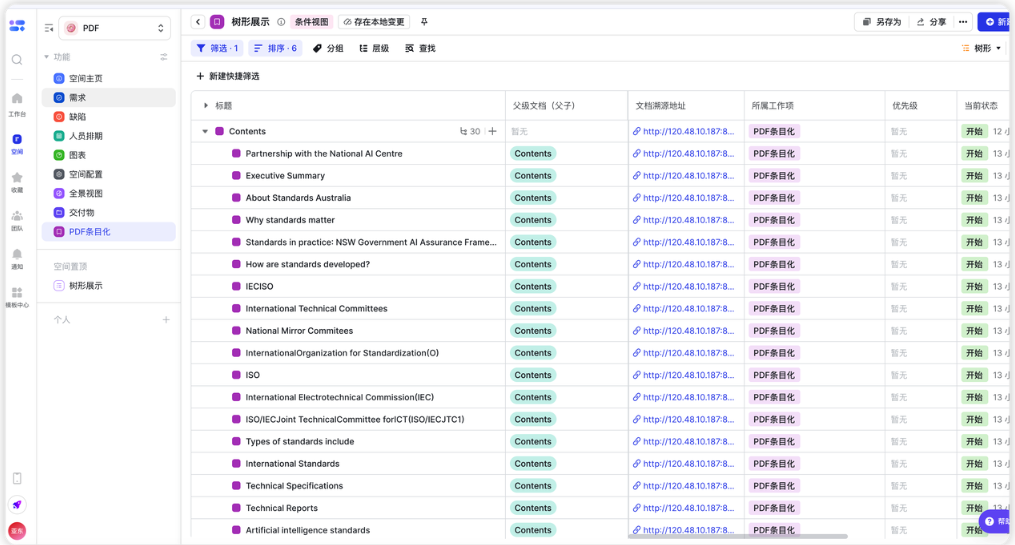
AI 智能分层打标,自动结构化切片 算法自动识别文档层级编号(1、1.1、1.1.1),智能区分需求条目与辅助说明文本,输出标准化结构化数据,字段可自定义适配企业研发台账;

-
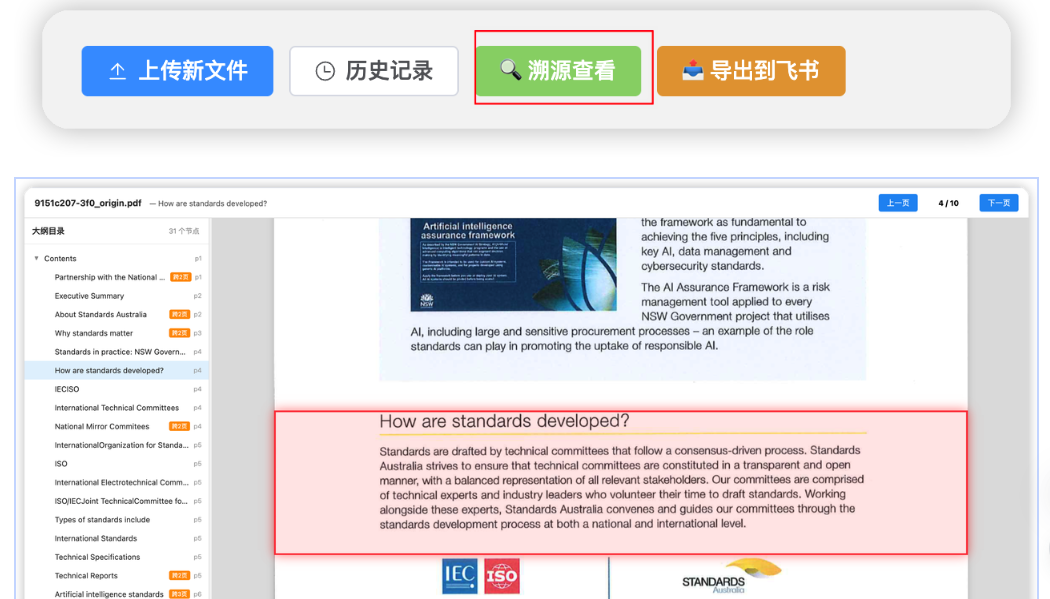
原文坐标绑定,全链路合规追溯 每一条解析完成的需求自动记录 PDF 页面、段落坐标,点击飞书项目内条目可一键跳转原文并高亮对应段落,全程留存操作日志,完整满足 ASPICE 审计追溯硬性要求;
-
飞书 API 深度打通,流程自动化闭环 解析完成后结构化数据可通过回调接口自动创建飞书项目工作项、同步至飞书多维表、归档至飞书知识库,打通需求录入、评审、变更、测试全研发流程,消除数据孤岛。
3.2 简易对接开发流程
-
企业飞书管理员后台开通自建应用权限、文件读取回调 API、项目工作项写入权限;
-
配置文件分片上传网关,适配 6000 页超大 PDF 分片传输解析;
-
自定义字段映射规则,匹配企业现有飞书研发流程字段;
-
工作台嵌入 PDF 解析应用,全员免登录使用,统一账号体系,无需额外权限配置。
四、落地量化收益
-
效率层面:6000 页 PDF 人工拆解需要 3 人 2 天,AI 解析压缩至 15 分钟完成,彻底解决项目前期文档卡点;
-
人力成本:释放需求分析师、文档工程师重复搬运工作,核心研发人员聚焦需求研判、风险管控等高价值工作;
-
质量管控:AI 标准化解析消除人工漏项、层级错乱问题,文档整改失误率降至 0;
-
合规层面:内置完整追溯日志,无需手动整理审计证据,直接通过第三方 ASPICE 评估核验。
五、适配落地的企业与技术场景
-
行业场景:汽车电子、整车制造、芯片设计、航空航天,常态化接收主机厂大批量 PDF 需求、法规文件;
-
协同底座:企业全域使用飞书搭建研发项目、知识库、变更管理流程;
-
合规需求:正在推进 ASPICE 体系落地,缺少文档自动结构化、追溯工具链;
-
技术现状:内部 IT 团队无自研多模态 PDF 解析模型能力,需要成熟飞书对接方案快速落地。
六、飞书 PDF 二次开发踩坑总结
-
飞书公有云原生文件接口对 10M 以上大文件有限流限制,超长 PDF 必须配置分片上传、异步解析接口;
-
低清晰度扫描 PDF 仅依靠通用 OCR 识别率不足 60%,必须搭配行业训练小模型提升识别精度;
-
ASPICE 审计场景必须持久化存储解析坐标、操作日志,否则无法提供完整追溯证据;
-
独立第三方 PDF 工具无法打通飞书项目数据,后期同步、维护成本极高,优先选择飞书原生二次开发方案。
七、技术资料领取
整理整套飞书 PDF 解析落地配套技术资料,企业 IT、飞书开发人员可直接复用:
-
飞书文件 AI 解析 API 对接文档;
-
ASPICE 文档追溯日志配置规范;
-
飞书工作台应用私有化部署手册;
-
多行业 PDF 解析落地案例集。
获取方式:CSDN 私信回复关键词【飞书 PDF 开发】,免费打包全套资料,可对接企业飞书环境免费测试工具适配性。
结语
飞书生态二次开发核心价值是补齐行业专属能力短板,而非重构企业现有数字化体系。针对汽车、芯片等高合规研发行业,PDF 超长文档结构化、需求双向追溯是通用高频痛点,标准化 AI 解析插件可快速嵌入现有飞书流程,大幅降低企业自研成本与文档管理人力消耗。

欢迎加入 MCP 技术社区!与志同道合者携手前行,一同解锁 MCP 技术的无限可能!
更多推荐
 5
5 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)