工程实践|Warp 的 Loop Engineering:Agent 如何自己改进 Skill?
最近关于 Agent loop 的讨论很多,但「loop(循环)」这个词有时候容易被讲得很抽象。
Warp 创始人 Zach Lloyd 给了一个更工程化的例子:用 GitHub Issues 做一个自我改进的 Issue 分诊系统。这个项目的核心思路是:先让 Agent 按照一个 Skill 去处理新 Issue,再让另一个 Agent 定期读取人类反馈,把这些反馈整理成可复用规则,最后通过 PR 更新原来的 Skill 文件。
这样,Agent 的工作方式就不是一次写死的 prompt,而是可以随着团队反馈持续迭代进化的文件。
一套流程,两个循环

图注:Warp 的 self-improvement loops 示例。左侧是处理新 Issue 的内循环,右侧是根据反馈更新 Skill 的外循环。
上图里有两个循环。左边是 Inner loop,也就是实际干活的循环。它对应的文件是:issue-triage/SKILL.md。当一个新 Issue 创建后,分诊 Agent 会先读取 Issue 内容,再根据 Skill 的规则判断它属于哪一类。右边是 Outer loop,也就是改进 Skill 的循环。它对应的文件是:improve-issue-triage/SKILL.md,这个 Agent 不直接处理新 Issue,主要工作是查看过去的 Issue 分诊记录,读取维护者的评论、reaction 和 label 变化,再判断原来的分诊规则是否需要更新。
这里有个关键设计,就是Agent 的改进结果并不是直接写进线上流程,而是生成 PR**,让人类 review 后再合并。**这会让 Skill 的演进过程保留在 Git 历史里,也让团队可以像审查代码一样审查 Agent 的行为规则。
Inner Loop:Agent 先做 Issue 分诊
内循环(Inner Loop)的入口是 GitHub Actions。
在这个 Warp 的实践中,.github/workflows/triage-new-issues.yml 负责监听 issues 的 opened 事件。只要有新 Issue 创建,就会触发一次 Agent 的分诊任务。Workflow 会 checkout 仓库,然后调用 warpdotdev/oz-agent-action@v1,指定使用 triage-issue 这个 Skill,并把当前 Issue 编号、仓库名和 Issue 标题传给 Agent。
name: Triage new issues
on:
issues:
types: [opened]
jobs:
triage:
runs-on: ubuntu-latest
permissions:
contents: read
issues: write
steps:
- uses: actions/checkout@v6
- uses: warpdotdev/oz-agent-action@v1
with:
skill: 'triage-issue'
prompt: |
Triage issue #${{ github.event.issue.number }} in the repository ${{ github.repository }}.
图注:triage-new-issues.yml 摘录,全部 Workflow 见 GitHub 原文件。
通过这套配置,Agent 被放进了一个明确的触发器里:新 Issue 创建,Workflow 就自动启动分诊任务。就这样,Agent 不再随机等人调用,而是直接接到 GitHub Issue 的生命周期上。每次创建 Issue,就是一次自动化分诊任务的开始。
接着就是分诊 Skill,它写得很具体: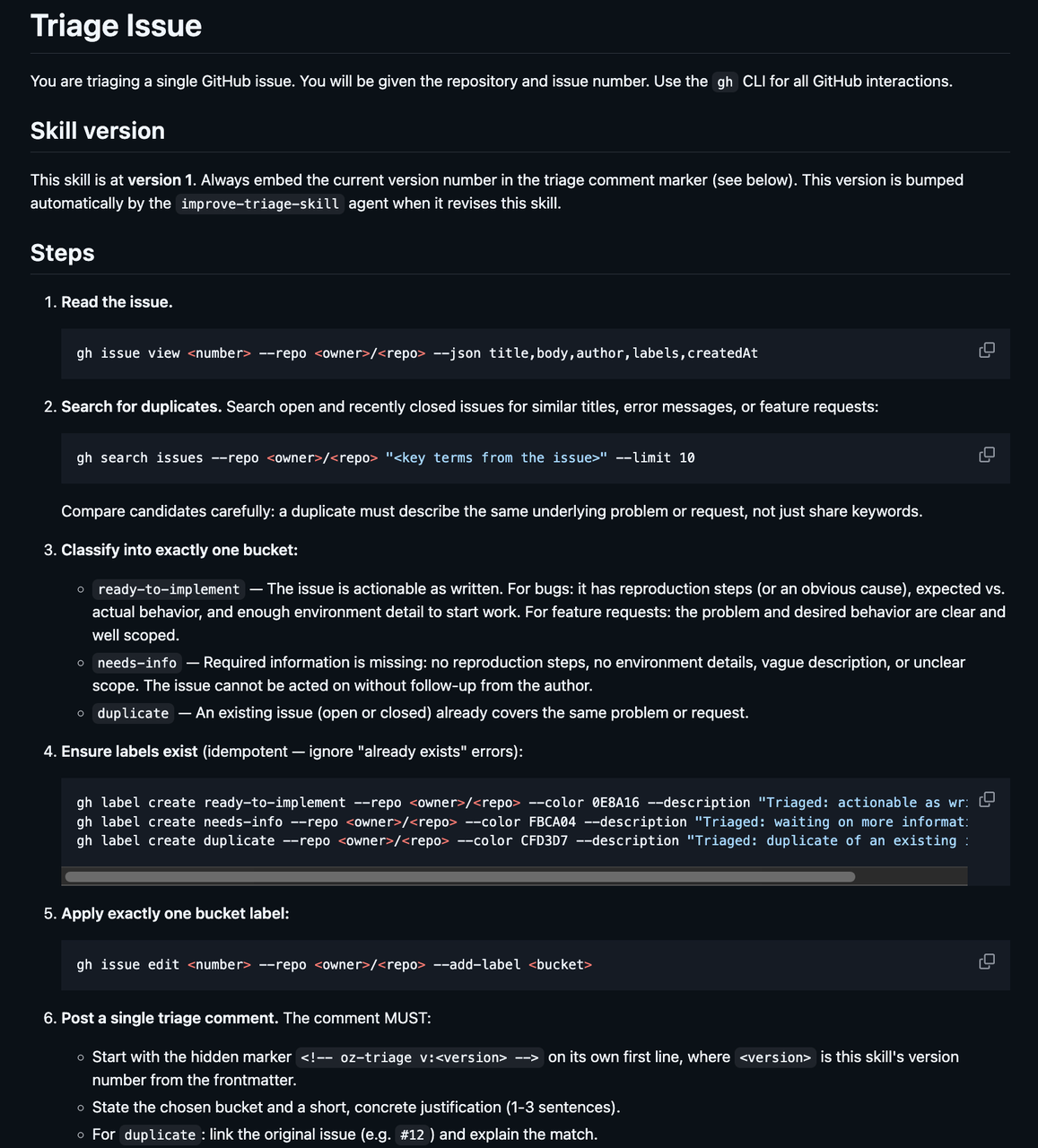
它要求 Agent 先读取 Issue,再搜索相似 Issue,然后再把当前 Issue 归到三个分类中的一个:ready-to-implement、needs-info、duplicate。这里讲解下这三个分类:
-
ready-to-implement:Issue 已经足够明确,可以开始处理。比如 bug 有复现步骤、预期行为、实际行为和环境信息;feature request 的问题和目标行为也比较清楚。 -
needs-info:Issue 缺少必要信息。比如没有复现步骤、没有环境细节、描述含糊,或者范围不清楚。 -
duplicate:已有 open 或 recently closed 的 Issue 覆盖了同一个问题或需求。
要注意一件事,这里的 Skill 不是只让 Agent「判断一下」。它还要求 Agent 创建必要的 labels、给 Issue 打上且只打上一个 bucket label,并发布一条分诊评论。
评论里还必须带一个隐藏标记:<!-- oz-triage v:<version> -->(上图 step 6)。这个标记会记录当前分诊来自哪个 Skill 版本。后面的改进 Agent 就依赖它来回溯历史分诊记录。
从分诊反馈到 Skill 更新
如果只有内循环,这套系统更像一个自动化分诊机器人。让它进入自我改进循环的,是后面的人类反馈。
在分诊评论的末尾,Skill 会提示维护者给出反馈:如果判断正确,可以给正向 reaction;如果判断不准确,可以用另一个 reaction,或者直接回复纠正。维护者可以手动修改 label,比如把 Agent 标成 ready-to-implement 的 Issue 改成 needs-info。这些操作都会成为外循环(Outer Loop)的输入信号。
仓库 README 里提到,这个 loop 能成立,靠的是几个设计:分诊评论里的 marker 和版本号,可以让改进 Agent 追溯到具体 Skill 版本;维护者改 label 是强信号;改进 Agent 只沉淀可泛化的规则;所有 Skill 修改都通过 PR 进入主分支。这样,人类反馈不会停留在评论和 review 里,而是会被重新写回 Skill,成为下一次分诊时可以读取的团队经验。
Outer Loop:把反馈整理成规则
外循环(Outer Loop)的核心文件在improve-triage-skill/SKILL.md。
这个 Skill 是 Issue 分诊循环里的「自我改进部分」。它的任务是研究维护者和 Issue 作者如何回应过去的自动分诊,从中提取可泛化经验,并通过 PR 修改 triage-issue Skill。
外循环的流程很清晰:
-
找到最近 14 天内被更新过、并且带有
<!-- oz-triage v:<N> -->标记的 Issue。这个标记告诉它:这条分诊评论来自哪个版本的 Skill。 -
收集反馈信号。包括分诊评论上的 reaction、人类在评论后的纠正回复、当前 label 和 Agent 当初打的分类是否发生变化,以及维护者是否认可 Agent 对「重复 Issue」的判断。Skill 里还明确写到:维护者替换分类 label,可以视为 Agent 判断错误的人工确认信号。
-
把这些信号整理成少量可泛化经验。这里的重点是「泛化」。举个例子,某类 crash report 经常因为缺少 OS / version 信息被维护者改成
needs-info,那么新的规则应该是:crash report 必须包含环境背景信息。这种可以规避重复性作业的规则,就应该写入 Skill。但如果只是「第 14 号 Issue 标错了」,这种一次性修正就不应该写进去。 -
修改原来的
triage-issue/SKILL.md。如果有足够强的证据,改进 Agent 会把新规则追加到## Learned guidelines下面,或者调整原有分类定义,同时提升 Skill 版本号。 -
开 PR。Skill 明确要求不要直接把 PR 提交到默认分支,而是创建一个
skill-improvement/<YYYY-MM-DD>分支,再提交 PR。PR 里需要包含被审查的 Issue 摘要、观察到的反馈、判断结论、学到的规则,以及具体修改了哪些 guideline。最后,再由人类 review 和 merge。
持续迭代的 Agent
这套流程的重点在于,把 Agent 的工作规则变成一套可以持续维护的 SOP。初版 Skill 可以很朴素,只包含基础分类规则。随着 Agent 处理越来越多的真实 Issue,团队的偏好和判断标准会慢慢浮现出来:
-
什么样的 bug report 可以直接开始修;
-
什么样的 feature request 需要先问清楚边界;
-
哪些重复 Issue 只是关键词相似,实际问题并不一样;
-
哪些信息缺失会阻碍后续开发;
这些经验如果只靠人记,很容易散落在评论区和社群里。写回 Skill 后,它们就变成了下一轮 Agent 可以执行的规则。更重要的是,这套机制没有绕开人类判断,让维护者对项目背景、团队习惯和历史讨论的理解继续参与 Skill 的演进。
虽然外循环 Agent 可以提议修改 Skill,但它不能直接改主分支。团队仍然要 review PR,确认这些经验真的值得沉淀。这样一来,Agent 的「学习」不会变成黑盒参数更新,而是变成一组可以审查、可以回滚、可以追踪版本的文本规则。
从 Issue 分诊开始落地
Issue 分诊很适合作为 self-improvement loop 的实践起点。现在,大多数研发团队每天都要处理大量 Issue,其中既有重复问题,也有背景信息不完整、复现步骤不清楚的情况。Warp 选择的 Issue 分诊场景比较容易复用,风险也相对可控:如果 Agent 分错了 label,维护者可以直接改回来,或者在评论里补充纠正说明。
同时,Issue 分诊天然会留下反馈记录。reaction、回复、label 变化、重复 Issue 判断是否被认可,都能成为外循环读取的信号。这样,Agent 每次做完分诊后,不只留下一个结果,也留下了可以被复盘的上下文。
如果要落地,起步可以很小:先选一个边界清楚的任务,比如只处理新 Issue 分诊;再写一份初版 Skill,写清楚任务目标、输入来源、操作步骤、分类标准、输出格式,以及需要向维护者请求什么反馈。
接下来,把 Skill 接入真实工作流。Warp 项目中就用了 GitHub Actions 在 Issue opened 时触发分诊 Agent,外循环则定期读取历史分诊和人类反馈,生成对 Skill 的修改建议。
最后,保留 PR review 这一步。外循环 Agent 可以整理规律、生成 diff、提交 PR,但规则是否写进 Skill,仍然由维护者确认。这样,Skill 的更新会留在 Git 历史里,团队也能持续检查 Agent 的行为规则是怎么变化的。
目前,这套流程已经放在 GitHub 上。

欢迎加入 MCP 技术社区!与志同道合者携手前行,一同解锁 MCP 技术的无限可能!
更多推荐


 4
4 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)