网心技术 | 小模型做 Agent:可能性、方向与未来
引言:为什么现在要关注小模型 Agent
Agent 系统正在从单体大模型调用走向多智能体协作。这一演进暴露了一个结构性矛盾:绝大多数 Agent 子任务,格式化输出、工具调用、数据提取、分类路由。本质上是重复性的模式匹配,而非开放域推理。为这些任务部署百亿乃至千亿参数的前沿模型,在延迟、成本和能耗上均不可持续。一个由五个 Agent 组成的工作流,每轮产生 15-25 次模型调用;若每次调用的延迟在秒级、成本在美分级,整个系统将无法实现实时交互,也无法规模化部署。
问题的另一面同样尖锐。金融、医疗、工业等领域的 Agent 应用对数据隐私有刚性要求,推理必须在设备或私有集群上完成;边缘场景(工业巡检、车载助手、弱网环境)要求离线可用;消费级应用(手机助手、AR 导航)对首 token 延迟的容忍以毫秒计。这些约束将模型规模从"越大越好"拉回到"多小才够"。

小语言模型(SLM,通常指 1B-12B 参数)正是对这两个问题的回应。NVIDIA 研究院 2025 年的论文 "Small Language Models are the Future of Agentic AI" 给出了系统性论证:Agentic 系统的核心工作负载是在一组专精任务上高频重复执行,SLM 在这种范式下不仅足够,而且在架构上更适配、在经济上更合理。该论文同时提出了异构 Agent 系统的设计原则——SLM 承担重复性子任务,大模型仅在需要通才推理时介入。
这一判断已经得到实证检验。2026 年 ACL Industry Track 发表的大规模研究[2]对 27 个开源 SLM 在三种部署范式(基础提示、工具增强单 Agent、协作多 Agent)下进行了评估,覆盖金融领域 20 个数据集、8 类任务。结果表明:单 Agent + 工具增强在性能和成本之间取得了最优平衡,多 Agent 协作带来的增益被协调开销抵消。
产业界的技术储备也在同步成熟。Google 的 Gemma 3n 将多模态模型压缩到 2B 有效参数,可在中端手机上运行;Qwen3-4B 的基座性能已达到上一代 Qwen2.5-72B 的水平;Microsoft 的 Phi-4-mini-reasoning 用 3.8B 参数在 AIME 2025 数学竞赛上接近 671B 参数的 DeepSeek-R1;NVIDIA 的 Nemotron 3 Nano 用混合 Mamba-Transformer MoE 架构实现了 3.3× 推理吞吐提升和 1M token 上下文窗口。
这些进展共同指向一个判断:小模型做 Agent 已经从概念论证进入工程实践。本文将从一个具体案例出发,逐层分析技术现状、开源生态、能力边界、工程策略与演进方向。
从 3B 涌现经济体到本地准前沿模型
小模型 Agent 的现实形态横跨一个很宽的谱系。一端是 3B 量级的真·端侧模型,靠工程约束在多智能体场景里跑出涌现行为;另一端是把准前沿开源模型搬到本地、用作可用工具调用 Agent 的实践。下面两个案例分别落在谱系的两端,共同界定了"小模型做 Agent"在 2026 年的可行边界。
案例一:Thousand Token Wood
—— 3B 模型驱动的多智能体经济体
2026 年 6 月,Hugging Face 举办的 Build Small Hackathon 中,一个名为 "Thousand Token Wood" 的项目引发了广泛关注。开发者 Lester Leong 用一个 Qwen2.5-3B 模型驱动了五个独立的 AI Agent,构建了一个实时运行的微型经济体:五只森林生物各自生产不同商品,用"鹅卵石"作为货币进行交易,在稀缺性压力下自发地产生了泡沫、崩盘和贫富分化。

❓️为什么:大模型的成本悖论
一个活跃的经济模拟需要多个 Agent 在每个回合进行多次思考和决策。如果使用 GPT-4 或 Claude 等前沿模型,每次 API 调用的延迟和成本都会让实时多 Agent 模拟变得不可行。在 Thousand Token Wood 中,每回合需要 5 个 Agent × 多次决策 = 至少 15-25 次模型调用。
按前沿模型的定价(~$15/M input + $60/M output),运行一个 15 回合的演示就需要数美元成本和分钟级延迟。而 3B 模型通过 vLLM 批量推理,所有 Agent 的决策可以在单次 GPU 调用中完成,成本降低两个数量级。
❓️做什么:设计稀缺性驱动的涌现行为
项目的核心发现是:小模型是可靠的格式生成器,但不可靠的推理者。3B 模型在 75 次调用中实现了 100% 的有效 JSON 输出,但其经济判断力很差,一个生产橡子的生物会试图购买橡子,这恰恰是它最不缺的东西。
更深层的发现来自系统设计。第一版经济体完全沉默,产量超过消耗,每个生物自给自足,永远没有交易动机。解决方案不是换更大的模型,而是工程化稀缺性:
-
饮食多样性:每种食物每餐只能吃一单位,生存需要购买自己不生产的食物
-
腐烂机制:易腐食品会变质,迫使盈余者在价值消失前出售
-
冬季燃料危机:每个生物每回合必须消耗柴火,需求持续上升,但只有一个生物生产柴火
引入"木材传说"(Wood Legends)机制后,项目将真实历史金融事件(郁金香泡沫、南海泡沫、1929 年银行挤兑)重新包装为森林叙事注入模拟。在一次运行中,"猫头鹰金库被掏空"的谣言触发了 Agent 自发抛售蜂蜜,蜂蜜价格从 10 暴跌至 3。没有任何剧本,3B 模型驱动的 Agent 在设计好的约束下自发重现了经典的银行挤兑动态。
❓️怎么做:工程约束弥补推理缺陷
核心工程策略可以总结为一句话:"不要要求模型更聪明,要让问题更简单。"
1、格式约束:所有 Agent 输出强制为 JSON,配以容错的 parse-and-repair 层,畸形响应降级为 no-op 而非崩溃
2、知识注入:在 prompt 中明确告知每个 Agent "你生产什么、绝对不能买什么、你缺什么",加一个完整的决策示例
3、状态保护:将"幸福感"从累积器改为均值回归的情绪值,避免小模型的次优决策导致死亡螺旋
4、价格漂移:引入残余供需驱动的参考价格漂移机制,打破 Agent 鹦鹉学舌式地重复参考价的倾向
关键启示: Thousand Token Wood 证明了一个重要原则,小模型的 Agent 应用不是在做"缩小版的大模型",而是一种完全不同的工程范式。工程师的角色从"调用 API 获取答案"转变为"设计约束使模型行为可预测"。模型的可靠格式输出能力是基础设施,不可靠的推理能力则由外部逻辑和规则来补偿。
案例二:antirez 的 DS4 / DwarfStar
—— 把准前沿模型搬进本地
谱系的另一端,是把一个准前沿开源模型完整搬上个人硬件。
Redis 作者 Salvatore Sanfilippo(antirez)写了 DS4 / DwarfStar,一个专为 DeepSeek V4 打造的本地推理引擎,约一周做出,迅速流行。它刻意做窄——只把一个模型端到端打磨到"完成品"的程度,而不是做通用 GGUF 加载器:官方 logits 校验、长上下文测试、外加足够的 agent 集成来判断模型是否真的可用。
关键在于它跑起来的硬件成本。借助 DeepSeek V4 的压缩 KV cache 与 2/8-bit 非对称量化,96–128GB 内存就足以运行:一台 M5 Max 128GB 笔记本以 2-bit 跑 V4 Flash,prefill 约 500 t/s、decode 约 35–40 t/s,配置价约 $6–7k;一台 Mac Studio M3 Ultra 512GB 则能跑更大的 V4 Pro,prefill 150 t/s、decode 10–13 t/s,整机约 $12k。antirez 给出的判断很直接:这是他第一次用本地模型做平时只会交给 Claude / GPT 的正经活,如果把"小而好的本地模型"记作 A、"在线前沿模型"记作 B,那么 DS4 明显更接近 B 而非 A。
这个案例与 Thousand Token Wood 形成互补:后者回答"3B 模型在多智能体协作里能做什么",前者回答"一个准前沿开源模型跑在本地、配上工具调用时能做什么"。它同时印证了几点与本文主题直接相关的工程判断:
✅ 本地部署是价值主张,而非妥协。
在自己的机器上跑准前沿模型,直接回应了数据隐私、离线可用与长期成本三个诉求,且能力不再是"凑合的小模型"。
✅ KV cache 是"一等磁盘公民"。
DS4 把压缩 KV cache 与现代 SSD 的高速流式读取结合,主张 KV cache 不必常驻内存。这把"模型能否塞进内存"从一个硬门槛,变成了一条随可用内存平滑变化的速度谱——内存只决定快慢,不再决定能不能跑。
✅ 工具调用要被验证,而非假设。
项目自带 ds4-agent 与 HTTP API,目标是用真实 agent 集成确认模型能"可靠地调用工具",而非只看它能否生成。模型槽位还会随时间替换为"实际够快的最佳开源模型",antirez 甚至设想了 ds4-coding、ds4-legal 这类按需加载的专精变体。
这个案例是通向下一节的自然过渡。antirez 用的 DeepSeek V4 远超 1–12B 端侧区间,而它今天就能跑在一台笔记本上,本身说明:随着模型结构(压缩 KV、稀疏 MoE)与本地硬件(统一内存、SSD 流式)的协同演进,"能在端侧运行"的模型体积正在持续上移。下一节的 DeepSeek-V4-Flash 正是这一趋势最清晰的代表。
antirez 还留下一条前向线索:他把 LLM ensemble(arxiv.org/abs/2502.18036)视为被低估的方向,让两个模型在不共享任何状态的前提下并行,按更低的 perplexity 选择续写、或直接合并 logits,"像一个路由隐式化的双专家 MoE",效果往往优于单模型独跑。多个模型各带视角、组合出更可靠的输出,这一思路在第 4.5 节会以另一种形态再次出现。
开源小模型 Agent 能力全景(2025-2026)
过去一年间,主要 AI 厂商密集发布了面向 Agent 场景的小模型。以下是截至 2026 年中的关键模型及其 Agent 能力对比:
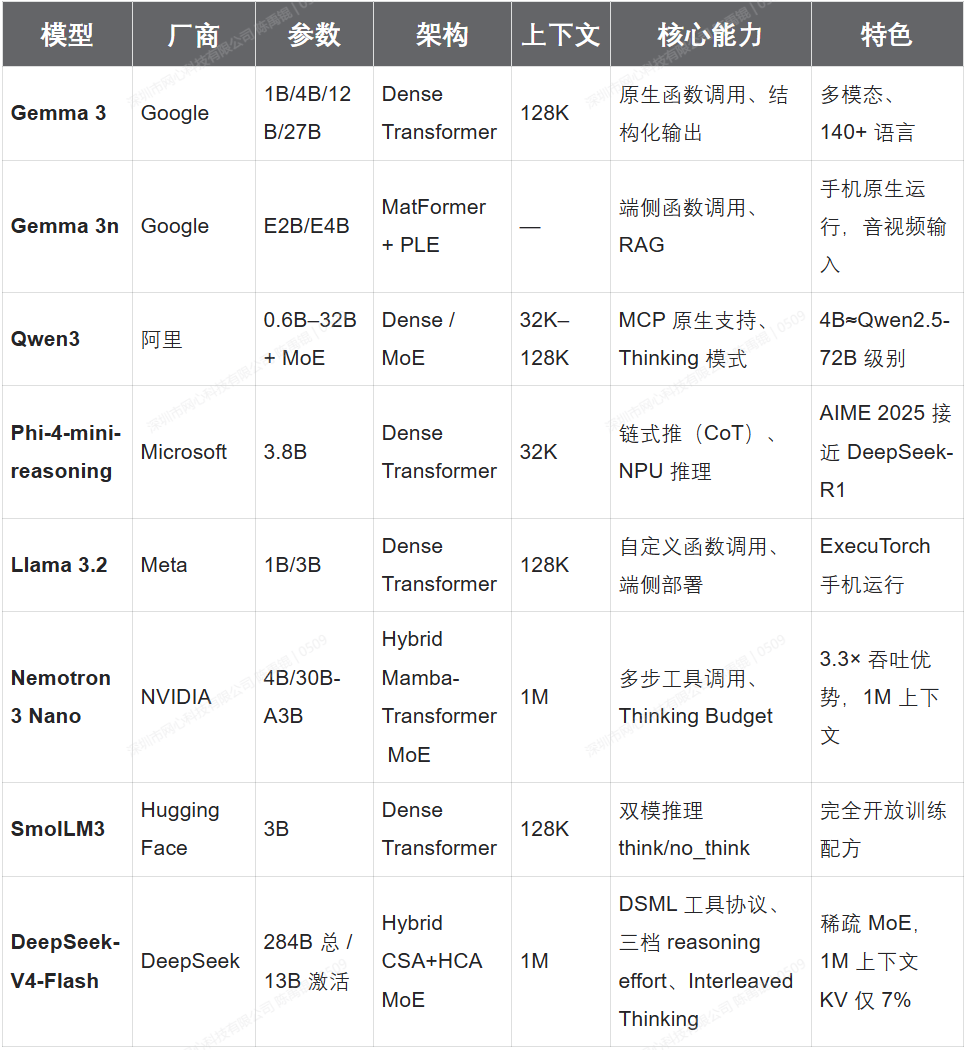
表中参数列对 MoE 模型标注「总参数量 / 激活参数量」:MoE 的推理成本由激活参数决定,知识容量由总参数决定,二者解耦正是下文成本讨论的核心。
✅ Google Gemma 系列:从云到端的全栈覆盖
Gemma 3(2025 年 3 月)是 Google 基于 Gemini 2.0 技术构建的轻量级开放模型家族,从 270M 到 27B 覆盖了从单板计算机到服务器的全部场景。其 Agent 能力的关键进展在于原生函数调用支持,模型在训练阶段就学习了工具调用的格式和语义,而非仅靠 prompt engineering。
2026 年 6 月发布的 Gemma 3n 更具突破性。这是 Google 首个基于下一代 Gemini Nano 共享架构的开放模型,专为手机、平板和笔记本设计。其创新之处在于:
1、Per Layer Embeddings(PLE):大幅降低内存占用,E2B 变体仅需 2GB 内存即可运行;
2、MatFormer 架构:支持动态计算灵活性,可在质量和延迟间平滑权衡;
3、MobileNet-V5 视觉编码器:在 Edge TPU 上实现 13× 量化加速,比 Gemma 3 的 SoViT 精度更高、参数少 46%;
4、端侧函数调用库:Google AI Edge 提供了完整的函数注册、响应解析和调用执行工具链。
✅ Qwen3:MoE 架构的成本革命
阿里的 Qwen3 系列(2025 年 4 月)在小模型 Agent 能力上取得了两个重要突破。首先,Qwen3-4B 的基座模型性能已经媲美 Qwen2.5-72B-Instruct,在 STEM 和编程任务上甚至超越了后者,这意味着"小模型"的能力边界在快速上移。其次,Qwen3-30B-A3B 这种 MoE 架构(总参数 30B,激活参数仅 3B)可以在单张消费级 GPU 上运行,同时具备工具调用、推理和足够的上下文处理能力。
Qwen3 的 Agent 生态围绕 Qwen-Agent 框架构建,原生支持 MCP(Model Context Protocol)、代码解释器和 RAG。框架内部封装了工具调用模板和解析器,开发者只需定义工具描述即可获得完整的 Agent 能力。Thinking 模式(类似 CoT)允许模型在复杂任务上"深思",non-thinking 模式则提供低延迟的即时响应。
✅ Microsoft Phi-4:推理密度的极致追求
Microsoft 的 Phi 系列一直追求在小参数量上最大化推理能力。Phi-4-reasoning(14B)和 Phi-4-mini-reasoning(3.8B)在 2025 年 4 月发布,采用了从 o3-mini 蒸馏 CoT 推理链 + 强化学习的训练范式。3.8B 的 Phi-4-mini 在 AIME 2025(美国数学奥林匹克预选赛)上接近了 671B 参数的 DeepSeek-R1 的表现,这是小模型推理能力的里程碑。
更值得关注的是 Phi-4 的端侧部署路径:经过 ONNX 优化后可在 Snapdragon NPU 上运行,将推理时计算的功耗大幅降低。这为"手机上运行推理型 Agent"提供了现实路径。
✅ NVIDIA Nemotron 3 Nano:为 Agent 量身定制的混合架构
Nemotron 3 Nano 是目前技术栈最复杂也最有针对性的小模型 Agent 方案。30B-A3B 变体使用了 Mamba-Transformer 混合 MoE 架构,在 25 万亿 token 上预训练,支持最长 1M token 的上下文窗口。
其 Agent 能力训练尤其系统化:通过 Workplace Assistant(包含 5 个数据库、26 个工具、690 个任务的多步骤可验证工具调用环境)和多轮对话银行客服环境(~1K 任务的信用卡解封、账户争议等场景),使用 GRPO 在多环境上同步强化学习。NVIDIA 还引入了 Thinking Budget 控制机制,允许开发者精确调节模型的"思考量"以平衡精度和延迟。
✅ DeepSeek-V4-Flash:稀疏 MoE 把端侧能力的天花板抬高
DeepSeek-V4 以双路线发布:DeepSeek-V4-Pro 为 1.6T 总参 / 49B 激活;DeepSeek-V4-Flash 为 284B 总参 / 13B 激活,两者都原生支持 1M token 上下文。Flash 变体在本文的语境里值得单独讨论:它的激活成本落在小模型量级,能力却来自一个万亿级知识容量的稀疏 MoE。
1、结构与成本
V4-Flash 有 43 层 Transformer,hidden dimension 为 4096。前两层使用纯 sliding window attention,其后交替使用压缩注意力 CSA(压缩率 m=4)与混合压缩注意力 HCA(压缩率 m=128)。每层 MoE 由 1 个 shared expert 和 256 个 routed experts 构成,每个 token 仅激活 6 个 routed expert,对应 13B 激活参数。
这套混合注意力把长上下文的开销压到很低:在 1M context 下,V4-Flash 的单 token 推理 FLOPs 只有 DeepSeek-V3.2 的 10%,KV cache 只有 7%。配合 RoPE 维度用 BF16、其余维度用 FP8 的混合 KV 存储,以及 lightning indexer 的 FP4 计算,1M 上下文的 KV cache 甚至可压到常见 BF16 GQA8 基线的约 2%。
2、为什么把它算作一种"广义小模型"
按 1–12B 的端侧定义,284B 总参的 V4-Flash 显然在区间之外。真正决定它能否落到本地的,是激活成本与缓存占用,而非总参数量:13B 激活参数、加上 KV 压缩与 FP4/FP8 混合精度,让它具备在大内存 PC 上运行的现实条件。
这背后是一个更长期的判断——随着本地硬件与模型结构的协同演进,"能在端侧运行"的模型体积会持续上移。今天需要一台大内存工作站,明天可能就是一台高配笔记本。这类"体积稍大、能力强很多"的模型,代表了端侧 Agent 的演进方向,而 V4-Flash 本身还会继续迭代。
3、Agent 原生设计
V4-Flash 的另一重价值,是把 Agent 能力做进了模型契约,而不是留给外部框架用 prompt 拼接。几个关键设计:
-
DSML 工具调用协议:引入特殊 token `|DSML|`,采用 XML 风格的工具调用格式,直接缓解自由文本生成里常见的转义错误,降低 tool-call 失败率。工具调用格式本身成为训练目标的一部分。
-
三档 reasoning effort:模型支持 Non-think(快速直觉响应)、Think High(更慢更准的逻辑分析)、Think Max(最大推理努力)三种模式,通过 <think>...</think> 整合进统一模型,并与不同长度惩罚、不同上下文窗口绑定。简单的工具选择走低档,复杂的搜索规划走高档。
-
Interleaved Thinking:在工具调用场景中完整保留推理历史,包括跨 user message 边界,避免模型每轮重建求解状态;普通对话场景仍丢弃旧推理以保持上下文简洁。
-
Quick Instruction:把"要不要搜网页、属于哪个领域"这类前置判断内收进主模型,用特殊 token 附到输入序列里复用已有 KV cache 并行完成,省掉维护额外小模型的工程负担,也降低首 token 延迟。
-
两阶段 post-train:先独立训练数学、代码、Agent、指令跟随等领域专家(SFT + GRPO),再通过 multi-teacher OPD(on-policy distillation)合并成统一模型;对难以验证的 Agent 过程性失败,用 rubric 引导的 Generative Reward Model(GRM)评审轨迹,而非压成一个 scalar 分数。
这些设计回应的正是第五节将讨论的小模型缺陷:DSML 与 GRM 针对工具调用可靠性与过程性失败,Interleaved Thinking 与 1M 上下文针对多步规划的长程一致性,三档 reasoning effort 则把推理时计算变成可调的旋钮。
小模型做 Agent 的可能性与当前方向
4.1 工具调用已成为标配能力
截至 2026 年中,主流小模型(3B+)的工具调用能力已经从"实验性支持"进入"生产可用"阶段。Qwen3 的 BFCL v3(Berkeley Function Calling Leaderboard)得分已经与大模型持平;Gemma 3 原生支持函数调用和结构化输出;Nemotron 3 Nano 在多步工具调用的准确率上超过了同尺寸的所有开源模型。
关键进展在于训练方法论的转变:从单纯的 SFT 格式训练转向环境内强化学习。Nemotron 3 Nano 使用真实数据库状态验证工具调用的正确性,而非仅仅检查格式;Qwen3 在 Thinking 模式下可以先推理"为什么要调用这个工具",再输出调用指令。
4.2 结构化输出:小模型的核心竞争力
Thousand Token Wood 的 100% JSON 有效率不是个案。结构化输出(JSON、XML、函数签名)是小模型做 Agent 最可靠的能力维度。原因在于:格式遵循本质上是一个模式匹配任务(pattern matching),而非开放域推理,这正是小模型的强项。结合约束解码(constrained decoding)和 JSON schema 验证,结构化输出的可靠性可以接近 100%。
4.3 MoE 架构重定义成本方程
MoE(Mixture of Experts)架构对小模型 Agent 的经济性具有决定性意义。Qwen3-30B-A3B 的总参数量为 30B(等同于一个中型模型的知识容量),但每次前向传播仅激活 3B 参数(等同于一个小模型的推理成本)。这意味着:
-
知识容量:30B 参数存储的世界知识远超 3B Dense 模型,减少了知识密集型任务上的幻觉
-
推理成本:实际激活 3B 参数,推理延迟和显存占用与 3B Dense 模型相当
-
运行环境:可在单张 RTX 4090 上运行,使用 FP8 无需额外量化
NVIDIA 的 Nemotron 3 Nano 30B-A3B 进一步将 MoE 与 Mamba 线性注意力结合,实现了比同尺寸 Dense 模型 3.3× 的推理吞吐。对于 Agent 应用中高频、低延迟的工具调用场景,吞吐量比单次推理精度更关键。
DeepSeek-V4-Flash 把这条曲线推到了高知识密度的一端。它的 284B 总参提供了远超中型 Dense 模型的世界知识,13B 激活参数把推理成本压回小模型量级,再叠加 CSA/HCA 把 1M 上下文的 KV cache 降到 7%。这意味着"知识容量"和"推理成本"两个维度可以独立调节。一个 Agent 既能在长上下文里调用海量参数化知识减少幻觉,又不必为此付出与总参数量成正比的推理代价。对于需要长对话历史、丰富工具调用记录的多步 Agent 任务,这种解耦比单纯把模型做小或做大都更有价值。
4.4 端侧部署:隐私与离线的刚需
端侧 Agent 不是大模型的"缩小版部署",而是一个独立的价值主张:
-
数据隐私:金融、医疗、企业内部等场景的数据不能离开设备
-
离线可用:工业巡检、户外作业、弱网环境下的 Agent 必须不依赖网络
-
延迟敏感:实时交互式 Agent(语音助手、AR 导航)无法容忍网络往返延迟
-
成本结构:百万用户级应用的每次 API 调用成本累积后远超端侧推理的一次性硬件成本
Gemma 3n 的 PLE 技术将 E2B 变体的内存占用降至 2GB,已经可以在中端手机上运行。Meta 的 Llama 3.2 1B/3B 通过 ExecuTorch 框架优化后可在 Android 设备上以 Vulkan GPU 加速推理。Google AI Edge 提供了端侧 RAG 和函数调用的完整工具链。端侧 Agent 的技术栈正在从"概念验证"向"开发者生态"演进。
值得强调的是,"端侧"并不是一条固定在 1–12B 的红线,而是一个随硬件上移的能力天花板。手机端今天能跑 Gemma 3n E2B、Llama 3.2 3B 这类真·端侧模型;大内存 PC 与工作站则已经能够承载 DeepSeek-V4-Flash 这类 13B 激活、KV 高度压缩的稀疏 MoE。二者构成一个梯度:底端是无处不在的轻量模型,上端是逐步下沉到本地的高能力模型。随着统一内存容量增长、量化与缓存压缩技术成熟,这个梯度的上界会持续抬高,“广义端侧 Agent"的能力也会随之水涨船高”。
4.5 异构 Agent 系统:让合适的模型做合适的事
NVIDIA 的论文中提出的异构 Agent 系统概念正在成为行业共识。核心思路是:
-
路由层:一个轻量分类器或规则引擎判断任务复杂度
-
SLM 处理:格式化输出、简单工具调用、数据提取、分类等重复性子任务
-
LLM 回退:复杂推理、开放域对话、多步规划等需要通才能力的任务
这种架构的经济逻辑非常清晰:如果 80% 的 Agent 调用是格式化和简单工具调用(SLM 完全胜任),只有 20% 需要复杂推理(LLM 介入),那么混合系统的成本仅为全部使用 LLM 的 20-30%,而用户体验几乎无损。
异构系统不止停留在理念层面,已经有了可指认的工程实现。这里要区分两种互补的模式。本节开头讲的路由是由分类器在 SLM 与 LLM 之间挑一个来处理。OpenRouter 的 Fusion 则代表另一条路:并行集成 + 裁判。它的官方定位就是"多模型分析 + 一个裁判模型"(multi-model analysis with a judge model)。机制上,一组模型(panel)并行回答同一个 prompt,每个模型都带 web_search 与 web_fetch;随后一个 judge 模型收下所有回答,比较而非合并,输出结构化 JSON:共识(多数模型一致的点,视为更高置信)、矛盾、覆盖差异、独特洞见。它适用于研究、专家评审等"出错代价高于多跑几次补全代价"的场景,对短平快的任务则没有必要。
Fusion 对 SLM Agent 的意义在于:panel 不必都用大模型。用多个便宜的小模型组成专家组、再配一个稍强的 judge,可以用集成的稳健性逼近单个昂贵模型的质量。这与案例二里 antirez 提到的 LLM ensemble 是同一思想的两种形态:一个发生在 logits 层(按 perplexity 选续写或合并分布),一个发生在响应层(多份完整回答交给裁判比较)。两者共同给出一条对成本敏感的工程路径:多个小模型加一个裁判,在高风险任务上可以胜过一个大模型独跑。 这一思路在 7.3 节的端云协同里会进一步展开。
小模型做 Agent 的核心缺陷
5.1 推理能力的硬天花板
Thousand Token Wood 最诚实的教训是:3B 模型不会"思考"经济策略。一个生产橡子的生物会试图购买橡子——这不是 prompt 写得不好,而是 3B 参数量根本无法可靠地建立"供给-需求-决策"的推理链。ACL 2026 的实证研究进一步量化了这个问题。在金融领域的 8 类任务中,<10B 模型在需要多步推理的任务上(如因果分析、趋势预测)与大模型的差距最大,且增加 Agent 工具并不能弥补推理缺陷,工具帮助的是信息获取,而非逻辑推理。
5.2 幻觉问题更加严重
2025-2026 年的多项研究一致表明:小模型的幻觉率显著高于大模型。EMNLP 2025 的结果表明,在多语言和多模态推理任务中,小模型的事实性错误率远高于前沿模型,且语言效应差异巨大,规模不是万能药。
对 Agent 应用而言,幻觉问题尤其致命。一个幻觉的工具调用参数可能触发不可逆的操作(如发送错误金额的转账)。2026 年的研究 "Always-Search Policy" 发现,SLM 在搜索增强型 Agent 中倾向于过度依赖有限的参数知识,跳过搜索直接生成推测性答案——即使在 Agent 框架中提供了搜索工具,小模型也经常"懒得用"。
5.3 微调引发知识遗忘
微调是小模型适应特定 Agent 任务的主要手段,但 2026 年的研究揭示了一个被忽视的问题:SFT 会诱导幻觉。微调新领域知识时,模型会遗忘预训练阶段获取的基础事实知识(factual forgetting),遗忘率可达 ~15%。这对 Agent 尤其危险:一个在工具调用上微调得很好的模型,可能在基础常识上退化,导致不可预测的推理错误。
根本原因是语义表示的局部干扰(localized interference),新旧知识共享重叠的参数空间,新知识的写入覆盖了旧知识。对于参数量有限的 SLM,这种干扰效应比大模型更加严重。
5.4 多步规划与长程依赖的困境
Agent 应用中最有价值的场景往往涉及多步规划:分析需求 → 搜索信息 → 整合结果 → 生成方案 → 验证输出。小模型在单步执行上可能表现不错,但在多步骤的连贯性和一致性上迅速退化。ACL 2026 的研究发现,多 Agent 系统试图通过多个模型的协作来弥补这一缺陷,但结果是协调开销超过了性能增益。模型间的消息传递引入了额外的错误传播路径。
5.5 少样本学习能力不足
大模型可以通过 prompt 中的几个示例快速适应新任务(few-shot learning),但小模型在这方面的可靠性显著降低。对于 Agent 应用,这意味着每遇到一个新的工具或任务格式,都可能需要额外的微调而非简单的 prompt 调整,增加了维护成本和部署复杂度。
工程补偿策略:用系统设计弥补模型能力
Thousand Token Wood 和 NVIDIA 的论文共同揭示了一个核心原则:小模型 Agent 的工程重心不在模型本身,而在系统设计。以下是经过验证的关键补偿策略。
6.1 检索增强生成(RAG):用工具替代记忆
RAG 是对抗小模型知识不足和幻觉的最有效手段。Always-Search Policy 研究提出了一种针对 SLM 的蒸馏训练范式,强制模型在每次回答前都执行搜索,彻底禁止依赖参数知识的推测性回答。实验表明,这种策略在多跳问答任务上将 SLM 的性能提升了 30%+ 以上。
TinyAgent-SLM 项目(基于 Llama 3.2 3B,在 4GB VRAM 的 RTX 3050 上运行)展示了一个完整的端侧 RAG Agent 实现:查询扩展 → 多路检索 → RRF 融合 → 交叉编码器重排序 → 相关性判断 → 回退 Wikipedia API → 确定性护栏验证。整个管线在本地 GPU 上运行,数据不离设备。
6.2 约束解码与格式工程
Thousand Token Wood 的 100% JSON 成功率依赖于两层保障:prompt 中的格式约束 + 容错的 JSON 解析修复层。在生产环境中,这可以进一步强化:
-
JSON Schema 约束解码:在推理时直接修改 token 概率分布,使输出强制符合预定义的 schema
-
Hermes 风格工具调用模板:Qwen3 和 Nemotron 3 Nano 都采用了结构化的工具调用模板,将函数调用从自由文本生成转化为半结构化填空
-
降级策略:畸形输出降级为 no-op(无操作),而非错误或重试,确保 Agent 循环不中断
6.3 微调策略:LoRA + 自蒸馏
针对微调引发知识遗忘的问题,2026 年的研究提出了以下缓解策略:
-
自蒸馏 SFT:在微调时同时用预训练模型的输出分布作为正则化约束,将知识遗忘从 ~15% 降低到 ~3%
-
选择性参数冻结:当不需要学习新事实知识时(如仅学习工具调用格式),冻结 FFN 层(事实知识的主要存储位置),仅训练注意力参数,在保持任务性能的同时几乎消除知识遗忘
-
QLoRA + DPO:TinyAgent-SLM 的实践表明,在消费级硬件上使用 QLoRA 进行领域适配,再用 DPO 进行行为对齐,是 SLM Agent 微调的实用组合
6.4 单 Agent > 多 Agent
ACL 2026 的实证结论对 Agent 架构设计有重要指导意义:在资源约束环境下,装备了工具的单 Agent 系统优于多 Agent 协作系统。多 Agent 系统的额外协调通信不仅增加了延迟和成本,还引入了错误传播的新路径。对于小模型而言,每一次模型间的消息传递都是一次潜在的格式错误或语义漂移的来源。
推荐的架构是单 Agent + 丰富工具集:一个 SLM 作为决策中枢,通过工具调用访问搜索引擎、数据库、计算器、代码解释器等外部能力,将推理负担分散到确定性工具中。
未来方向:从"勉强能用"到"生产就绪"
7.1 推理时计算(Inference-time Compute)
Phi-4-reasoning 和 Qwen3 的 Thinking 模式代表了小模型推理能力的最有希望的提升路径:在推理时投入更多计算来换取更高质量的输出。模型生成详细的内部推理链(<think> block),然后基于推理过程生成最终答案。Phi-4-reasoning-plus 的实验表明,RL 训练后模型平均使用 1.5× 更多的 token 但显著提升了数学推理精度。这是一个可控的精度-延迟权衡。
Nemotron 3 Nano 的 Thinking Budget 将这个概念产品化:开发者可以为每个任务设置不同的"思考预算",简单的工具调用用零预算(即时响应),复杂的规划任务分配高预算(深度推理)。这使得单个模型可以适配 Agent 管线中截然不同的延迟需求。
DeepSeek-V4-Flash 的三档 reasoning effort(Non-think / Think High / Think Max)是同一思路的另一种实现。它在 specialist 训练阶段就用不同的 reasoning effort RL 配置培养出三种模式,并通过 <think> 格式整合进统一模型,与不同的长度惩罚和上下文窗口绑定。Agent 管线由此可以按子任务分配算力:轻量决策走 Non-think,复杂软件工程与搜索规划走 Think High 或 Think Max。Thinking Budget 与 reasoning effort 共同说明,推理时计算正在从"模型固有属性"变为"开发者可调的旋钮"。
7.2 专业化蒸馏:从大模型到小 Agent
2026 年的趋势表明,训练小模型 Agent 最有效的方式不是从头训练,而是从大模型蒸馏专精能力。Phi-4 从 o3-mini 蒸馏 CoT 推理链,Nemotron 3 Nano 从 GPT-OSS 120B 和 DeepSeek-R1 蒸馏数学和代码推理。关键的创新在于工具集成推理轨迹(tool-integrated reasoning traces)的蒸馏,不仅蒸馏模型的推理过程,还包括模型在推理过程中如何决定和使用工具。
NVIDIA 在 Nemotron 3 Nano 的 Agentic 训练中使用了可验证环境内强化学习:Agent 在沙箱环境中执行工具调用,结果与真实数据库状态比对来判断奖励。这将"Agent 能力"从模仿文本模式提升到了真正理解工具语义和因果关系的层次。
7.3 端云协同:动态路由与级联推理
未来的 Agent 架构不会是纯端侧或纯云端,而是端云协同的动态系统:
-
端侧 SLM:处理隐私敏感数据、提供即时响应、执行简单工具调用
-
云端 LLM:处理复杂推理、长上下文分析、不确定性高的决策
-
路由层:基于任务复杂度、隐私要求、网络状态和端侧负载动态选择处理路径
-
级联推理:端侧 SLM 先尝试,置信度不足时透明地升级到云端 LLM
Gemma 3n + Gemini API 的组合已经提供了这种架构的早期实现:端侧使用 Gemma 3n 做实时理解和简单交互,复杂任务通过 Gemini API 回退到云端。Google AI Edge 的 RAG 和函数调用库则提供了端侧工具增强的标准化接口。
在纯云端一侧,OpenRouter Fusion(见 4.5 节)给出了级联的另一种终点:不是再做一次路由,而是用"专家组 + 裁判"对高风险问题做多视角交叉验证。把它接到端云链路的末端,就构成一条完整的级联,端侧 SLM 先尝试,置信度足够就地返回;遇到高风险、高不确定的问题,再升级到云端的 Fusion 层,由一组模型并行作答、一个裁判比较出共识与矛盾。对用户而言始终是一个入口,算力与多视角校验只在真正需要时才投入。
7.4 MCP 生态:Agent 工具互操作的标准化
Model Context Protocol(MCP)正在成为 Agent 工具集成的事实标准。2026 年 7 月的 MCP 规范候选版本将协议完全无状态化,每个请求自包含,支持标准 HTTP 负载均衡,无需 sticky session。这对小模型 Agent 尤其重要:无状态协议使得端侧 SLM 可以像调用 REST API 一样调用远程工具,无需维护复杂的连接状态。
Qwen3 已经原生支持 MCP 配置;Nemotron 3 Nano 在 MCP 兼容的工具调用格式上做了针对性训练。随着 MCP 生态的成熟,小模型的工具集将从"几个硬编码函数"扩展到"整个互联网服务的统一接口",这将从根本上改变小模型 Agent 的能力边界。
MCP 解决的是工具接口在 Agent 之间的互操作,DeepSeek-V4 的 DSML 协议则代表了一个互补的方向:把工具调用格式上升为模型自身的契约。V4 用特殊 token |DSML| 和 XML 风格的调用格式,在训练阶段就把工具调用作为目标的一部分,而非在 serving 层用 prompt 临时拼接。两条路线并不冲突。MCP 负责"模型如何接入外部世界的工具",模型原生的工具协议负责"模型如何稳定地生成工具调用"。一个理想的小模型 Agent,应当在模型契约层有可靠的结构化调用能力,在生态层接入 MCP 这样的标准化工具网络。
7.5 混合架构创新
Nemotron 3 Nano 的 Mamba-Transformer 混合架构代表了一个重要的技术方向。Mamba 的线性注意力在长序列上的计算复杂度远低于标准 Transformer 的二次复杂度,这使得 1M 上下文窗口在小模型上成为可能。对 Agent 应用而言,长上下文意味着更长的对话历史、更丰富的工具调用记录和更完整的任务状态。这些都是多步骤 Agent 任务成功的关键。
未来可以预期更多的混合架构创新:
-
Mamba + Transformer + MoE:在效率、推理质量和知识容量间取得最优平衡
-
动态深度:根据任务复杂度动态选择使用多少 Transformer 层,简单任务提前退出
-
嵌套子模型:Gemma 3n 的 E4B 内嵌 E2B 子模型的设计,允许根据运行时资源动态调整模型规模
结论
小模型做 Agent 已经从技术可能性论证进入工程实践阶段。Thousand Token Wood 用一个 3B 模型证明了多智能体涌现行为的可行性;NVIDIA 的论文和 ACL 2026 的实证研究从理论和数据上论证了 SLM 在 Agentic 系统中的经济合理性和架构适配性;Google、阿里、Microsoft、Meta 和 NVIDIA 的密集产品发布则提供了从云到端的完整技术栈。
但必须清醒地认识到当前的边界:
-
可靠的格式输出 ≠ 可靠的推理。小模型可以完美地生成 JSON,但不能可靠地决定 JSON 里应该填什么
-
工具增强 ≠ 推理增强。工具帮助获取信息,但不帮助理解信息之间的因果关系
-
多 Agent ≠ 更好的 Agent。在小模型场景下,单 Agent + 丰富工具集优于多个小模型的协作
未来 12-18 个月的关键看点是:
-
推理时计算(Thinking Budget) 能否将 3-4B 模型的推理能力提升到 14B 级别?
-
MoE + 混合架构 能否在保持 3B 激活成本的同时达到 30B+ 的知识容量?
-
MCP 生态 能否像 REST API 一样普及,让小模型 Agent 即插即用地接入数千种工具?
-
端云协同路由 能否做到对用户透明、对开发者简单?
小模型做 Agent 的本质不是"用小模型替代大模型",而是用系统设计将模型的可靠能力(格式输出、工具调用)放大,将模型的不可靠能力(推理、规划)通过外部逻辑和工具来补偿。这是一种全新的工程范式,也是 AI 应用从实验室走向大规模部署的必经之路。
一句话总结: 小模型是可靠的双手,大模型是聪明的大脑——未来的 Agent 系统需要二者的协同,而非取舍。
参考文献
1. Belcak, P. et al. (2025). Small Language Models are the Future of Agentic AI. NVIDIA Research. arXiv:2506.02153
2. ACL Industry Track (2026). Rethinking Scale: Deployment Trade-offs of Small Language Models under Agent Paradigms. arXiv:2604.19299
3. Leong, L. (2026). Thousand Token Wood: shipping a multi-agent economy on a 3B model. Hugging Face Build Small Hackathon.
4. Google DeepMind (2025). Gemma 3 Technical Report. arXiv:2503.19786
5. Google DeepMind (2026). Gemma 3n: Powerful, Efficient, Mobile-First AI.
6. Qwen Team (2025). Qwen3 Technical Report. arXiv:2505.09388
7. Microsoft Research (2025). Phi-4-reasoning Technical Report. arXiv:2504.21318
8. NVIDIA (2025/2026). Nemotron 3 Nano Technical Report. arXiv:2512.20848
9. Hugging Face (2025). SmolLM3: smol, multilingual, long-context reasoner.
10. Meta AI (2024). Llama 3.2: Revolutionizing Edge AI and Vision with Open, Customizable Models.
11. arXiv (2026). Always-Search Policy for SLM Agents. arXiv:2604.04651
12. arXiv (2026). Why Fine-Tuning Encourages Hallucinations and How to Fix It. arXiv:2604.15574
13. BentoML (2026). The Best Open-Source Small Language Models (SLMs) in 2026.
14. Google Developers Blog (2025). Introducing Gemma 3 270M: The compact model for hyper-efficient AI.
15. DeepSeek-AI (2026). DeepSeek-V4 Technical Report.(DeepSeek-V4-Pro 与 DeepSeek-V4-Flash 双路线、CSA/HCA 混合注意力、DSML 工具协议、三档 reasoning effort、Interleaved Thinking、Quick Instruction、multi-teacher OPD 与 GRM)
16. Sanfilippo, S. (antirez) (2026). Distributing LLM inference in DwarfStar 与 A few words on DS4. https://antirez.com/news/167 、 https://antirez.com/news/165 ;代码 https://github.com/antirez/ds4
17. OpenRouter (2026). Fusion: Multi-model AI Analysis(多模型专家组 + 裁判模型). https://openrouter.ai/docs/guides/features/plugins/fusion
18. Chen, Z. et al. (2025). Harnessing Multiple Large Language Models: A Survey on LLM Ensemble. arXiv:2502.18036

欢迎加入 MCP 技术社区!与志同道合者携手前行,一同解锁 MCP 技术的无限可能!
更多推荐

 7
7 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)