从0开始搭建AI Agent(四)
LangChain 文本嵌入模型(Embeddings)是 LangChain 框架中用于将非结构化文本转换为高维数值向量的核心组件接口,它本身不直接提供算法,而是统一封装了各类底层嵌入模型(如 OpenAI、Hugging Face、阿里云等)的调用逻辑 。
核心定义与功能
本质作用:充当“翻译官”,将人类可读的文字映射为计算机可计算的浮点数列表(向量),使机器能理解文本的语义信息 。
关键特性:遵循语义保持性,即语义相似的文本(如“猫”和“小狗”)在向量空间中的距离更近,从而支持相似度计算 。
统一接口:无论底层使用何种模型,LangChain 均通过标准方法暴露功能,便于开发者灵活切换供应商 。
文本嵌入作用
找相似的内容:让电脑搜索的时候不只找关键词,还能找到意思相近的内容;
分类文字:分类文章、商品的好评、差评;
推荐:根据用户关注的内容推荐相似的东西;
跨语言:不同国家语言,只要意思相近,都能够匹配到。
代码示例
网络文本模型
新建一个“TextEmbedded.ipynb”文件,同样,我们需要把上一章的模型加载部分代码搬过来,如下图:
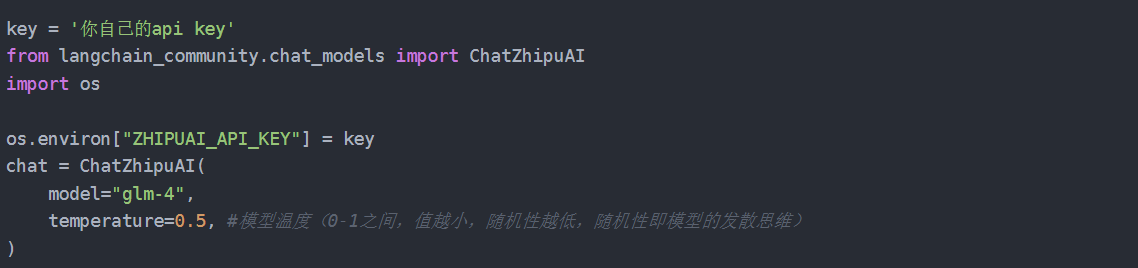
点击运行;
新建代码段
from langchain_community.embeddings import ZhipuAIEmbeddings
#加载
embeddings = ZhipuAIEmbeddings(model="embedding-2")
#评论
comments = ["这个电视很好、很清晰","这个电视很差、很卡顿"]
#转换为向量
vector = embeddings.embed_documents(comments)
print(f"向量的维度:{len(vector[0])}")
print(f"向量:{vector[0]}")直接运行会报错,提示ImportError: Could not import zhipuai python package.Please install it with `pip install zhipuai`.
需要按照提示进入我们的conda环境,执行pip install zhipuai;
注意:
有时候会发现,安装完pip install zhipuai后,还是会报“ImportError: Could not import zhipuai python package.Please install it with `pip install zhipuai`”错误,这个时候需要排查:
1.你的python是不是运行在你的conda环境里面?
2.你的conda环境是否正确安装了包?
查看方式:
conda activate 你自己的环境
#查看zhipuai版本
pip show zhipuai如果有输出版本信息,则表示已经安装
3.以上两种都排除了,但是仍然有错误,执行一下这条命令:
python -c "from zhipuai import ZhipuAI; print('zhipuai 导入成功')"
可能会出现(也可能其它包缺失):
ModuleNotFoundError: No module named 'sniffio',这样我们需要再安装一下:pip install sniffio;
这个时候我们再运行代码,应该就不会出错了,打印如下:

预测测试
安装包
pip install scikit-learn新建代码块
test_comment=['这个东西超好用!']
test_vector = embeddings.embed_documents(test_comment)
print(f"向量:{test_vector[0]}")
from sklearn.linear_model import LogisticRegression
labels = [1,0]#1好评0差评
clf = LogisticRegression().fit(vector,labels)
#预测
prediction = clf.predict(test_vector)
print("好评" if prediction[0]==1 else "差评")点击运行,可以看到,模型将我们的“这个东西超好用”,评论归类到了好评上面。
本地文本模型
有时候我们不想用网络上的模型,我们可以去下载下来,部署到我们本地使用,推荐下载地址:ModelScope 魔搭社区,进去之后,再右上角搜索:bge-small-zh-v1.5,找到后进入下载页面,如下图:
点击“下载模型”,里面包含了很多下载方式,我这边是用git下载的,下载后,模型放到工程文件夹下面,如下图:
![]()
测试
安装包:
pip install langchain_huggingface
pip install sentence-transformers 测试代码:
from langchain_huggingface import HuggingFaceEmbeddings
#加载本地模型
embeddings = HuggingFaceEmbeddings(
model_name='bge-small-zh-v1.5',
model_kwargs={'device': 'cpu'},
encode_kwargs={'normalize_embeddings': False} #提升相似度计算精度
)
#测试
query = "这个电视怎么样?"
query_vector = embeddings.embed_query(query)
print(f"向量的维度:{len(query_vector)}")
print(f"向量:{query_vector}")运行,输出下面结果:

代表我们本地的向量模型可以使用了;
一个简单的应用
下面我们以一个简单的应用来体现文本向量化的实际使用:
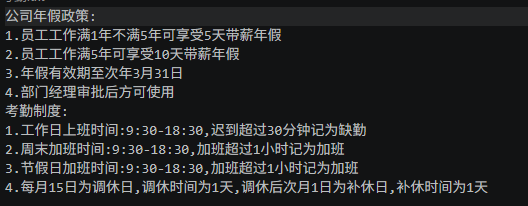
大概应用是这样:我们将一个公司考勤规定通过向量化后,并持久化保存到硬盘,然后用户可以根据自己的需求,搜索到相应的规定要求:比如:加班规定、年假规定、迟到处罚等;
1.在当前项目目录新建一个“.txt”文档,加入以下内容(也可以自己编写测试文档):
2.加载本地向量模型
from langchain_huggingface import HuggingFaceEmbeddings
#加载本地模型
embeddings = HuggingFaceEmbeddings(
model_name='bge-small-zh-v1.5',
model_kwargs={'device': 'cpu'},
encode_kwargs={'normalize_embeddings': False} #提升相似度计算精度
)3.加载文档并持久化,测试搜索
持久化需要安装一个包:
pip install chromadbfrom langchain_community.document_loaders import TextLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
#加载文件
loader = TextLoader('./公司考勤.txt', encoding='utf-8')
documents = loader.load()
#中文分块
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=50, #适合中文段落的段落大小
chunk_overlap=0, #上下误差 避免上下文缺失
separators=["\n\n", "\n", " ", ",","。"]
)
splits = text_splitter.split_documents(documents)
#print(f"分块数量:{len(splits)}")
#print(f"第一个分块内容:{splits[0].page_content}")
#数据持久化
from langchain_community.vectorstores import Chroma
db = Chroma.from_documents(
documents=splits,
embedding=embeddings,
persist_directory="./chroma_db"
)
# 语义搜索
docs = db.similarity_search("加班规定", k=2)
print(f"搜索结果:")
for doc in docs:
print(f"内容:{doc.page_content}")其中,docs = db.similarity_search("加班规定", k=2),k值代表搜索的结果,k=1,会返回最接近搜索的结果,k值越大,返回的结果就会越多(会返回和搜索相似的结果),这个需要根据实际应用去调整;
运行,打印出结果:

OK,文本嵌入模型就先讲到这里,实际应用中根据需求,加到自己的AI Agent里面;下一章继续介绍Langchain的工具封装调用......

欢迎加入 MCP 技术社区!与志同道合者携手前行,一同解锁 MCP 技术的无限可能!
更多推荐



 1
1 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)