《RAG 智能客服项目技术博客》,基于 Streamlit、FastAPI、LangChain 与 Chroma 的本地知识库问答系统实践
一、项目背景
随着大语言模型的发展,越来越多的应用开始使用 AI 来完成智能问答、客服咨询、文档检索和知识库助手等任务。普通的大模型虽然具备较强的自然语言理解和生成能力,但在实际业务场景中仍然存在几个明显问题:
1. 无法直接理解企业或个人的私有文档内容
例如商品尺码规则、公司制度、项目文档、客服 FAQ 等内容通常不在模型训练数据中。
2. 知识可能过时
大模型训练完成后,其知识并不会自动同步最新业务资料。
3. 容易产生幻觉
当模型不知道答案时,可能会生成看似合理但实际错误的内容。
4. 缺少业务可控性
对于智能客服、商品推荐、企业知识问答等场景,回答必须尽量基于已有资料,而不是完全依赖模型自由发挥。
为了解决这些问题,本项目采用了 RAG(Retrieval-Augmented Generation,检索增强生成) 技术方案。RAG 的核心思想是:
▎ 在大模型回答问题之前,先从本地知识库中检索相关资料,再把检索到的资料作为上下文交给大模型生成答案。
这样既可以利用大模型的语言理解能力,又能让回答尽量基于本地知识库内容,从而提升回答的准确性和可控性。
本项目实现的是一个 RAG 智能客服助手,支持本地文档上传、向量化存储、知识库问答、多轮对话、流式输出和 API 服务化调用。
---
二、项目概述
本项目是一个基于 Python 开发的 RAG 智能客服系统,主要功能包括:
- 支持上传本地知识库文件;
- 支持 TXT、MD、JSON、PDF、Word、Excel 等多种文件格式;
- 使用 LangChain 对文档进行加载、切片和链式编排;
- 使用 DashScope 的 Embedding 模型将文本转换为向量;
- 使用 Chroma 作为本地向量数据库;
- 使用通义千问聊天模型生成回答;
- 使用 Streamlit 搭建 Web 聊天界面;
- 使用 FastAPI 提供 HTTP API 服务;
- 支持普通聊天模式和知识库问答模式;
- 支持多会话历史记录保存;
- 支持流式输出 AI 回复。
项目整体可以看作一个较完整的本地知识库问答系统,适合作为学习 RAG 技术、LangChain 编排、大模型应用开发和智能客服项目实践的基础案例。
---
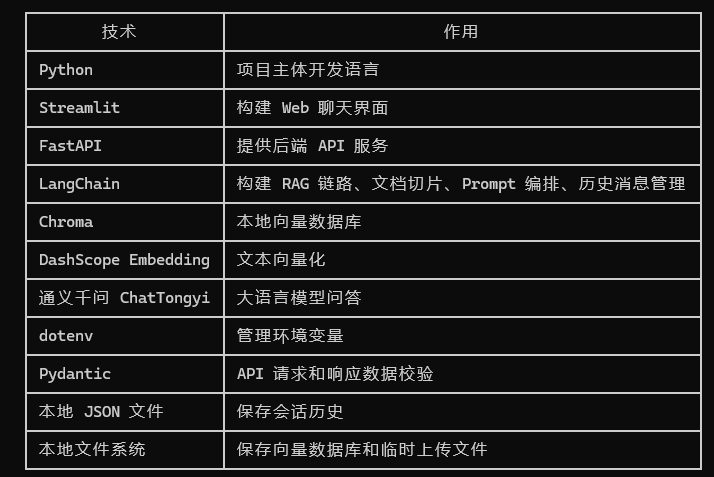
三、项目技术栈
本项目涉及的核心技术栈如下。
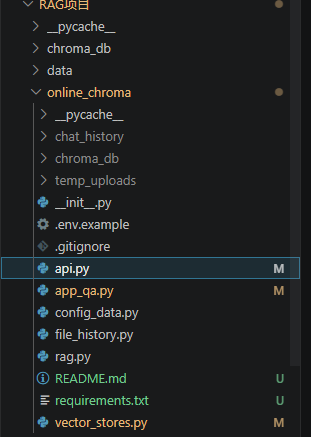
四、项目目录结构
本项目目录中既有早期知识库上传 Demo,也有较完整的 RAG 智能客服版本。其中最核心的实现位于 online_chroma 文件夹下。
RAG项目/
├── config_data.py # 早期 Demo 配置文件
├── knowledgebase.py # 早期知识库上传逻辑
├── 文件上传.py # 早期 Streamlit 文件上传页面
├── md.text # 早期 MD5 去重记录文件
├── data/
│ └── 尺码推荐.txt # 示例知识库数据
├── chroma_db/ # 根目录下的 Chroma 向量库
└── online_chroma/
├── app_qa.py # Streamlit 智能客服页面
├── api.py # FastAPI 接口服务
├── rag.py # RAG 核心问答逻辑
├── vector_stores.py # 向量库和文档加载管理
├── file_history.py # 会话历史管理
├── config_data.py # 完整版项目配置
├── requirements.txt # 项目依赖
├── .env.example # API Key 配置示例
└── README.md # 项目说明文档
---
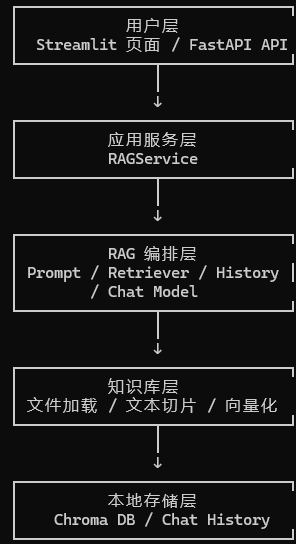
五、系统整体架构
从功能层次来看,本项目可以分为五层:
用户层
├── Streamlit Web 页面
└── FastAPI HTTP 接口
应用服务层
└── RAGService
RAG 编排层
├── Prompt 构造
├── Retriever 检索
├── Message History 历史对话
└── LLM 调用
知识库层
├── 文件加载
├── 文档切片
├── Embedding 向量化
└── Chroma 向量存储
本地存储层
├── chroma_db
└── chat_history
系统的核心流程可以概括为:
1. 用户上传知识库文件;
2. 系统解析文件内容;
3. 将文本切分成多个文档片段;
4. 使用 Embedding 模型将文档片段转换为向量;
5. 将向量和元数据存入 Chroma;
6. 用户提问时,系统先从 Chroma 中检索相关文档;
7. 将检索结果、历史对话和用户问题组合成 Prompt;
8. 调用大语言模型生成回答;
9. 将回答流式展示到页面;
10. 将本轮对话保存到本地历史文件中。
---
六、RAG 技术原理
6.1 什么是 RAG
RAG 的全称是 Retrieval-Augmented Generation,中文通常翻译为 检索增强生成。
它由两个核心部分组成:
1. Retrieval:检索
从外部知识库中找到和用户问题相关的内容。
2. Generation:生成
将检索到的内容提供给大模型,让模型基于这些内容生成答案。
普通大模型回答问题时,主要依赖自身参数中已有的知识。而 RAG 会在回答前额外加入一个“查资料”的过程。
可以简单理解为:
普通大模型:
用户问题 -> 大模型 -> 答案
RAG:
用户问题 -> 检索知识库 -> 找到相关资料 -> 大模型结合资料回答 -> 答案
6.2 RAG 为什么适合智能客服
智能客服系统通常有大量业务规则,例如:
- 商品尺码规则;
- 售后政策;
- 退换货流程;
- 用户使用手册;
- 售后政策;
- 退换货流程;
- 用户使用手册;
- 企业内部规范;
- 常见问题 FAQ。
这些知识并不是大模型天然知道的,而且会经常更新。RAG 可以把这些资料放入本地知识库中,用户提问时实时检索相关内容,再让大模型进行组织和表达。
这样做的好处是:
- 回答更贴合业务资料;
- 可以随时更新知识库;
- 减少大模型胡编乱造;
- 不需要重新训练模型;
- 适合中小型项目快速落地。
---
七、项目配置文件解析
项目的配置文件是:
online_chroma/config_data.py
核心代码如下:
import os
from dotenv import load_dotenv
load_dotenv()
MD5_FILE_PATH = "./md.text"
collections_name = "rag"
persist_directory = "./chroma_db"
chunk_size = 1000
chunk_overlap = 100
separators = ["\n\n", "\n", "!", "。", ",", ",", "."]
max_split_char_number = 1000
similarity_threshold = 2
embedding_model_name = "text-embedding-v4"
chat_model_name = "qwen3-max"
DASHSCOPE_API_KEY = os.getenv("DASHSCOPE_API_KEY", "")
7.1 配置说明
1. 向量库集合名称
collections_name = "rag"
这个配置表示 Chroma 中的 collection 名称。可以理解为向量数据库中的一个表或集合。
2. 向量库持久化目录
persist_directory = "./chroma_db"
Chroma 会把向量数据存储到本地 chroma_db 文件夹中。这样即使程序关闭,下次启动后仍然可以继续使用已有知识库。
3. 文档切片大小
chunk_size = 1000
chunk_overlap = 100
chunk_size 表示每个文档片段的最大长度。
chunk_overlap 表示相邻片段之间保留 100 个字符的重叠部分。
文档切片非常重要。如果切片太大,检索不够精准;如果切片太小,语义可能不完整。本项目设置为 1000 字符,并保留 100 字符重叠,是一种比较常见的基础配置。
4. 切片分隔符
separators = ["\n\n", "\n", "!", "。", ",", ",", "."]
该配置表示切片时优先按照自然段、换行和标点符号进行分割,尽量避免把一句话从中间切断。
5. 检索数量
similarity_threshold = 2
虽然变量名叫 similarity_threshold,但在代码中它实际作为 Retriever 的 k 参数使用,也就是每次返回最相似的 2 个文档片段。
6. 模型配置
embedding_model_name = "text-embedding-v4"
chat_model_name = "qwen3-max"
本项目使用:
- text-embedding-v4 作为文本向量模型;
- qwen3-max 作为聊天生成模型。
---
八、知识库构建流程
知识库构建是 RAG 系统的第一步,对应的核心文件是:
online_chroma/vector_stores.py
该文件中定义了 VectorStoreService 类,负责文档加载、文本切片、向量化和写入 Chroma。
---
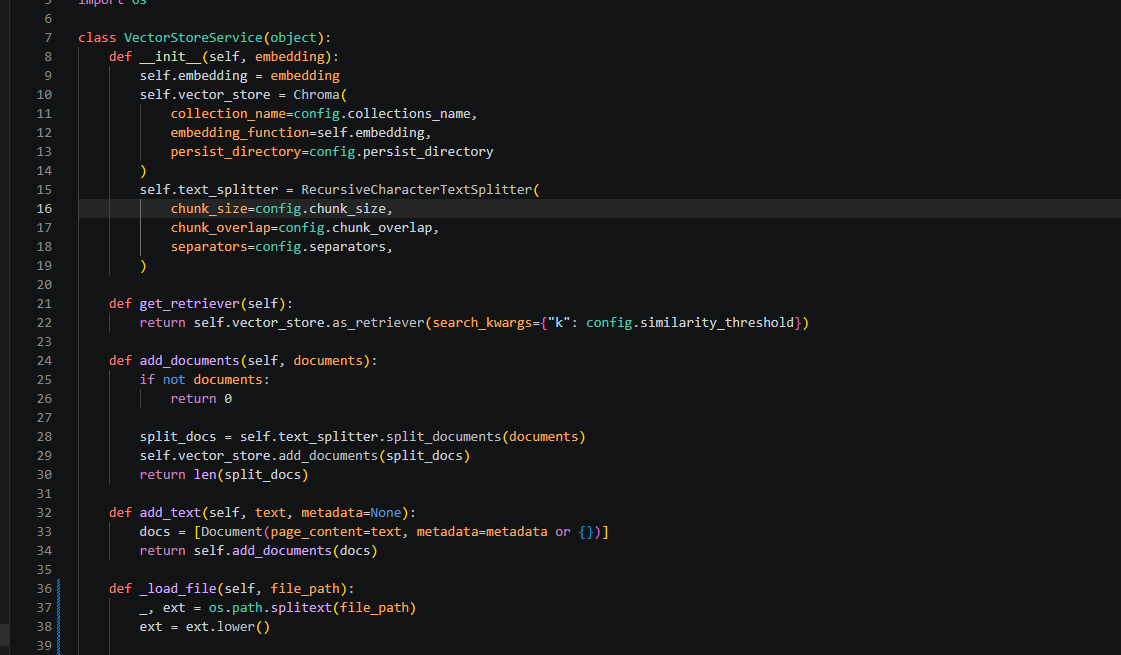
8.1 初始化向量库
核心代码如下:
class VectorStoreService(object):
def __init__(self, embedding):
self.embedding = embedding
self.vector_store = Chroma(
collection_name=config.collections_name,
embedding_function=self.embedding,
persist_directory=config.persist_directory
)
self.text_splitter = RecursiveCharacterTextSplitter(
chunk_size=config.chunk_size,
chunk_overlap=config.chunk_overlap,
separators=config.separators,
)
这段代码完成了两个重要初始化:
1. 初始化 Chroma 向量库;
2. 初始化文本切片器。
其中:
embedding_function=self.embedding
表示 Chroma 在添加文档时,会使用传入的 Embedding 模型将文本转换为向量。
persist_directory=config.persist_directory
表示向量库会持久化保存到本地目录中。
8.2 获取检索器
def get_retriever(self):
return self.vector_store.as_retriever(
search_kwargs={"k": config.similarity_threshold}
)
这段代码将 Chroma 向量库转换为 LangChain 的 Retriever。
Retriever 的作用是:
▎ 输入一个用户问题,返回与问题最相似的若干个文档片段。
这里的 k=2,表示每次检索返回最相关的 2 个片段。
---
8.3 添加文档
def add_documents(self, documents):
if not documents:
return 0
split_docs = self.text_splitter.split_documents(documents)
self.vector_store.add_documents(split_docs)
return len(split_docs)
这段代码是知识库入库的关键逻辑。
流程如下:
1. 判断文档是否为空;
2. 使用 text_splitter 对文档进行切片;
3. 将切片后的文档写入 Chroma;
4. 返回添加的文档片段数量。
其中:
split_docs = self.text_splitter.split_documents(documents)
会将原始大文档拆成多个小片段。
self.vector_store.add_documents(split_docs)
会完成两个动作:
- 调用 Embedding 模型生成向量;
- 将向量和文档内容写入 Chroma。
---
8.4 支持多种文件格式
项目支持 TXT、MD、JSON、PDF、Word、Excel 等文件格式,核心判断逻辑如下:
def _load_file(self, file_path):
_, ext = os.path.splitext(file_path)
ext = ext.lower()
if ext == ".pdf":
return self._load_pdf_langchain(file_path)
elif ext == ".docx":
return self._load_docx_langchain(file_path)
elif ext in [".xlsx", ".xls"]:
return self._load_excel_langchain(file_path)
elif ext in [".txt", ".md", ".json"]:
return self._load_text_file(file_path)
else:
raise ValueError(f"不支持的文件格式: {ext}")
这段代码根据文件扩展名选择不同的加载方式。
例如:
- .pdf 文件使用 PDF Loader;
- .docx 文件使用 Word Loader;
- .xlsx 文件使用 Excel Loader;
- .txt、.md、.json 文件按普通文本读取。
这使得系统的知识库来源更加灵活,不局限于纯文本文件。
【重点说明】
在真实业务系统中,知识库文件格式通常比较复杂,不同部门可能提供 Word、PDF、Excel 等格式。本项目在文件解析上做了兼容处理,能够支持更丰富的文档来源。
---
8.5 PDF 文件加载
项目优先使用 LangChain 的 PDF Loader,如果依赖不存在或解析失败,则尝试使用备用方案。
def _load_pdf_langchain(self, file_path):
try:
from langchain_community.document_loaders import PyPDFLoader
loader = PyPDFLoader(file_path)
docs = loader.load()
return docs
except ImportError:
try:
from langchain_community.document_loaders import PDFMinerLoader
loader = PDFMinerLoader(file_path)
return loader.load()
except ImportError:
return self._load_pdf_fallback(file_path)
except Exception as e:
return self._load_pdf_fallback(file_path)
这种写法体现了一个比较实用的工程思路:
▎ 优先使用标准组件,如果失败,再使用备用方案,提升系统兼容性。
---
8.6 Word 文件加载
def _load_docx_langchain(self, file_path):
try:
from langchain_community.document_loaders import Docx2txtLoader
loader = Docx2txtLoader(file_path)
return loader.load()
except ImportError:
try:
from langchain_community.document_loaders import UnstructuredWordDocumentLoader
loader = UnstructuredWordDocumentLoader(file_path)
return loader.load()
except ImportError:
return self._load_docx_fallback(file_path)
Word 文件同样采用多级 fallback 方案:
1. 优先使用 Docx2txtLoader;
2. 如果不可用,尝试 UnstructuredWordDocumentLoader;
3. 如果仍不可用,再使用 python-docx 自己提取段落文本。
---
8.7 Excel 文件加载
def _load_excel_fallback(self, file_path):
try:
import pandas as pd
df = pd.read_excel(file_path)
text = df.to_string(index=False)
return [Document(page_content=text.strip(), metadata={"source": file_path})]
except ImportError:
raise ValueError(
"无法解析Excel文件。请安装:\n"
"pip install pandas openpyxl xlrd"
)
except Exception as e:
raise ValueError(f"Excel文档解析失败: {str(e)}")
Excel 文件最终会被转换成字符串,然后包装成 LangChain 的 Document 对象。
这说明在 RAG 系统中,不管原始数据是什么格式,最终都需要统一转换成类似这样的结构:
Document(
page_content="文本内容",
metadata={"source": "文件路径"}
)
---
九、RAG 核心问答链路
项目最核心的文件是:
online_chroma/rag.py
该文件定义了 RAGService 类,负责初始化模型、构建 RAG 链路、普通聊天链路、文档入库以及知识库管理。
---
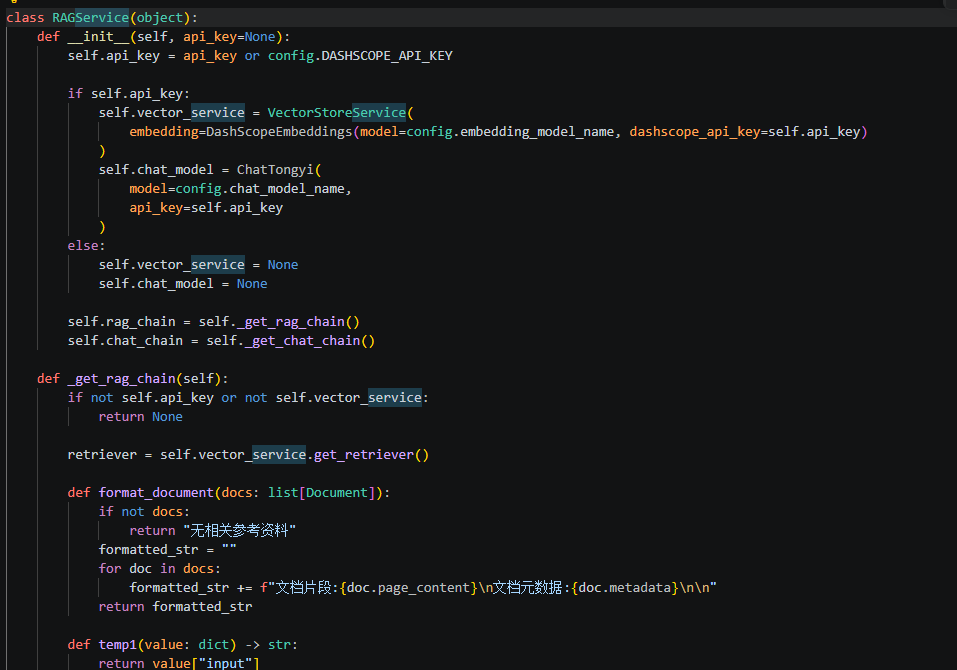
9.1 初始化 RAGService
核心代码如下:
class RAGService(object):
def __init__(self, api_key=None):
self.api_key = api_key or config.DASHSCOPE_API_KEY
if self.api_key:
self.vector_service = VectorStoreService(
embedding=DashScopeEmbeddings(
model=config.embedding_model_name,
dashscope_api_key=self.api_key
)
)
self.chat_model = ChatTongyi(
model=config.chat_model_name,
api_key=self.api_key
)
else:
self.vector_service = None
self.chat_model = None
self.rag_chain = self._get_rag_chain()
self.chat_chain = self._get_chat_chain()
这段代码主要完成四件事:
1. 读取 API Key;
2. 初始化 Embedding 模型;
3. 初始化聊天模型;
4. 构建 RAG Chain 和普通 Chat Chain。
其中:
DashScopeEmbeddings(model=config.embedding_model_name)
用于将文本转换为向量。
ChatTongyi(model=config.chat_model_name)
用于调用通义千问聊天模型生成回答。
9.2 RAG Chain 构建
RAG 链路的核心代码如下:
def _get_rag_chain(self):
if not self.api_key or not self.vector_service:
return None
retriever = self.vector_service.get_retriever()
def format_document(docs: list[Document]):
if not docs:
return "无相关参考资料"
formatted_str = ""
for doc in docs:
formatted_str += f"文档片段:{doc.page_content}\n文档元数据:{doc.metadata}\n\n"
return formatted_str
def temp1(value: dict) -> str:
return value["input"]
def temp2(value):
new_value = {}
new_value["input"] = value["input"]["input"]
new_value["context"] = value["context"]
new_value["history"] = value["input"]["history"]
return new_value
chain = (
{
"input": RunnablePassthrough(),
"context": RunnableLambda(temp1) | retriever | format_document
} | RunnableLambda(temp2) | self.prompt_template | print_prompt | self.chat_model | StrOutputParser()
)
conversation_chain = RunnableWithMessageHistory(
chain,
get_history,
input_messages_key="input",
history_messages_key="history"
)
return conversation_chain
这段代码是整个项目最重要的部分。
---
9.3 链路拆解
RAG Chain 可以拆解成以下流程:
用户问题
↓
RunnablePassthrough 保留原始输入
↓
RunnableLambda 提取 input
↓
Retriever 检索知识库
↓
format_document 格式化检索结果
↓
组合 input、context、history
↓
PromptTemplate 构造提示词
↓
ChatTongyi 调用大模型
↓
StrOutputParser 转成字符串
↓
RunnableWithMessageHistory 保存历史
其中最关键的是这段:
{
"input": RunnablePassthrough(),
"context": RunnableLambda(temp1) | retriever | format_document
}
它表示同一个用户输入会被分成两路:
1. 一路作为原始问题继续向后传递;
2. 另一路进入 Retriever,从知识库中检索相关资料。
然后再把检索到的资料作为 context 放入 Prompt 中。
---
9.4 检索结果格式化
def format_document(docs: list[Document]):
if not docs:
return "无相关参考资料"
formatted_str = ""
for doc in docs:
formatted_str += f"文档片段:{doc.page_content}\n文档元数据:{doc.metadata}\n\n"
return formatted_str
这段代码把检索到的 Document 列表转换成字符串。
最终格式类似:
文档片段: 用户体重 180 斤时建议选择 XXL 尺码
文档元数据: {'source': '尺码推荐.txt'}
文档片段: 身高 175cm 到 180cm 的用户推荐 XL 或 XXL
文档元数据: {'source': '尺码推荐.txt'}
这些内容会被放进 Prompt,供大模型参考。
---
9.5 Prompt 模板设计
项目中的 RAG Prompt 如下:
@property
def prompt_template(self):
return ChatPromptTemplate.from_messages(
[
("system", "以我提供的资料为主简洁和专业的回答用户问题.参考资料:{context}"),
("system", "并且以我提供的用户对话为历史记录,如下:"),
MessagesPlaceholder("history"),
("user", "请回答用户提问{input}")
]
)
这个 Prompt 包含三部分信息:
1. 参考资料 context
来自 Chroma 检索结果。
2. 历史对话 history
来自本地会话历史文件。
3. 当前用户问题 input
用户本轮输入的问题。
Prompt 的作用是告诉模型:
▎ 回答时优先参考我提供的资料,同时结合历史对话,回答用户当前的问题。
【重点说明】
Prompt 是 RAG 系统中非常关键的一环。检索结果再准确,如果 Prompt 没有明确告诉模型如何使用资料,模型仍然可能忽略知识库内容。
---
9.6 普通聊天链路
除了 RAG 模式,项目还支持普通聊天模式。
def _get_chat_chain(self):
if not self.api_key or not self.chat_model:
return None
chat_prompt = ChatPromptTemplate.from_messages(
[
("system", "你是一个智能助手,请根据历史对话和用户提问提供友好、专业的回答。"),
MessagesPlaceholder("history"),
("user", "{input}")
]
)
chain = chat_prompt | self.chat_model | StrOutputParser()
conversation_chain = RunnableWithMessageHistory(
chain,
get_history,
input_messages_key="input",
history_messages_key="history"
)
return conversation_chain
普通聊天模式不检索知识库,只使用历史对话和当前用户输入。
两种模式对比如下:
9.7 同步问答与流式问答
项目提供了两个聊天方法:
def chat(self, prompt, session_config, use_rag=True):
if not self.api_key:
return "请先配置 API Key"
if use_rag and self.rag_chain:
return self.rag_chain.stream({"input": prompt}, session_config)
elif self.chat_chain:
return self.chat_chain.stream({"input": prompt}, session_config)
else:
return "模型初始化失败,请检查 API Key"
chat() 方法使用 .stream(),返回流式输出结果。
def chat_sync(self, prompt, session_config, use_rag=True):
if not self.api_key:
return "请先配置 API Key"
if use_rag and self.rag_chain:
return self.rag_chain.invoke({"input": prompt}, session_config)
elif self.chat_chain:
return self.chat_chain.invoke({"input": prompt}, session_config)
else:
return "模型初始化失败,请检查 API Key"
chat_sync() 方法使用 .invoke(),一次性返回完整回答。
这两个方法分别服务于不同场景:
- Streamlit 页面更适合流式输出;
- API 同步接口更适合一次性返回完整结果。
---
十、会话历史管理
本项目支持多轮对话,并且会将历史消息保存到本地文件中。对应文件是:
online_chroma/file_history.py
---
10.1 获取历史对象
def get_history(session_id):
return FileChatMessageHistory(session_id, "./chat_history")
每个用户会话都有一个 session_id,系统会根据这个 ID 创建或读取对应的历史文件。
---
10.2 FileChatMessageHistory 类
class FileChatMessageHistory(BaseChatMessageHistory):
def __init__(self, session_id, storage_path):
self.session_id = session_id
self.storage_path = storage_path
self.file_path = os.path.join(storage_path, session_id)
os.makedirs(self.storage_path, exist_ok=True)
初始化时,系统会将会话历史保存路径设置为:
./chat_history/{session_id}
例如:
./chat_history/user_001
这样每个会话都可以单独保存自己的聊天记录。
---
10.3 添加消息
def add_message(self, message: Sequence[BaseMessage]) -> None:
all_messages = list(self.messages)
all_messages.append(message)
new_messages = [message_to_dict(m) for m in all_messages]
with open(self.file_path, 'w', encoding='utf-8') as f:
json.dump(new_messages, f, ensure_ascii=False)
这段代码会:
1. 读取原有历史消息;
2. 追加新消息;
3. 将消息转换为字典;
4. 写回 JSON 文件。
LangChain 中的消息对象不能直接写入 JSON,因此需要使用:
message_to_dict()
将消息转换为可序列化结构。
---
10.4 读取消息
@property
def messages(self) -> list[BaseMessage]:
try:
with open(self.file_path, 'r', encoding='utf-8') as f:
messages_data = json.load(f)
return messages_from_dict(messages_data)
except FileNotFoundError:
return []
读取时使用:
messages_from_dict()
将 JSON 数据还原为 LangChain 的消息对象。
【重点说明】
这个模块解决了多轮对话中的“记忆”问题。用户刷新页面或切换会话后,系统仍然可以恢复之前的聊天记录。
---
十一、Streamlit 前端页面实现
项目的 Web 页面入口是:
online_chroma/app_qa.py
该文件使用 Streamlit 实现了智能客服界面。
---
11.1 页面初始化
st.set_page_config(page_title="智能客服", page_icon="🤖", layout="wide")
st.title("🤖 智能客服")
st.divider()
这段代码设置了页面标题、图标和布局。
---
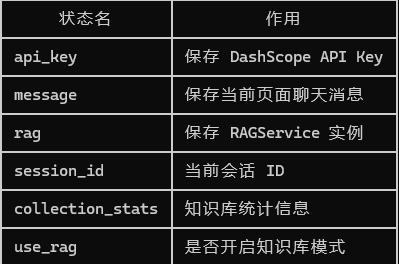
11.2 Session State 状态管理
Streamlit 每次交互都会重新执行脚本,因此需要使用 st.session_state 保存状态。
if "api_key" not in st.session_state:
st.session_state["api_key"] = config.DASHSCOPE_API_KEY
if "message" not in st.session_state:
st.session_state["message"] = [{"role": "assistant", "content": "你好!有什么可以帮助你的吗?"}]
if "rag" not in st.session_state:
st.session_state["rag"] = None
if "session_id" not in st.session_state:
st.session_state["session_id"] = "user_001"
if "collection_stats" not in st.session_state:
st.session_state["collection_stats"] = None
if "use_rag" not in st.session_state:
st.session_state["use_rag"] = True
这些状态分别表示:
11.3 初始化 RAG 服务
def init_rag_service():
if st.session_state["api_key"] and not st.session_state["rag"]:
st.session_state["rag"] = RAGService(api_key=st.session_state["api_key"])
return st.session_state["rag"]
该函数用于根据 API Key 初始化 RAGService。
如果用户没有输入 API Key,RAG 服务无法正常调用 Embedding 和聊天模型。
---
11.4 侧边栏设置
项目在侧边栏中提供了多个功能模块:
with st.sidebar:
st.header("⚙️ 设置")
1. API Key 输入
api_key_input = st.text_input(
"DashScope API Key",
value=st.session_state["api_key"],
type="password",
placeholder="请输入您的 DashScope API Key"
)
用户可以在页面中输入自己的 DashScope API Key。
2. 知识库文件上传
uploaded_files = st.file_uploader(
"📁 选择要上传的文件",
type=["txt", "md", "json", "pdf", "docx", "xlsx", "xls"],
accept_multiple_files=True,
help="支持:txt, md, json, pdf, docx, xlsx, xls",
key="file_uploader"
)
这里支持多文件上传,并限制了可上传的文件类型。

---
11.5 上传文件到知识库
当用户点击“上传到知识库”按钮后,系统会执行以下逻辑:
if st.button("上传到知识库"):
if not st.session_state["api_key"]:
st.error("请先配置 API Key!")
elif not uploaded_files:
st.warning("请先选择要上传的文件!")
else:
rag = init_rag_service()
if rag:
with st.spinner("正在处理文件..."):
temp_dir = "./temp_uploads"
os.makedirs(temp_dir, exist_ok=True)
上传流程包括:
1. 检查 API Key;
2. 检查是否选择文件;
3. 初始化 RAG 服务;
4. 创建临时上传目录;
5. 保存上传文件;
6. 调用 rag.add_files(file_paths);
7. 删除临时文件;
8. 显示上传结果。
核心调用如下:
result = rag.add_files(file_paths)
这会进入 RAGService.add_files(),再进入 VectorStoreService.add_file(),最终完成文件解析、切片、向量化和入库。
---
11.6 知识库统计
if st.session_state["collection_stats"]:
stats = st.session_state["collection_stats"]
if stats["success"]:
st.metric("文档片段数", stats["document_count"])
这里会显示当前知识库中已有多少个文档片段。
这对于用户判断知识库是否成功构建非常有帮助。
---
11.7 历史会话管理
项目支持展示历史会话:
def get_history_sessions():
history_dir = "./chat_history"
sessions = []
if os.path.exists(history_dir):
for filename in os.listdir(history_dir):
file_path = os.path.join(history_dir, filename)
if os.path.isfile(file_path):
...
sessions.append({
'id': filename,
'preview': preview,
'mtime': os.path.getmtime(file_path)
})
sessions.sort(key=lambda x: x['mtime'], reverse=True)
return sessions
这段代码会扫描 chat_history 目录,把已有会话按照修改时间排序展示出来。
用户可以:
- 查看历史会话;
- 切换到指定会话;
- 创建新会话;
- 清空当前对话。
---
11.8 知识库模式开关
rag_mode = st.toggle(
"📚 知识库模式",
value=st.session_state["use_rag"],
help="开启时使用知识库回答,关闭时使用普通聊天"
)
st.session_state["use_rag"] = rag_mode
这个开关用于控制当前对话是否使用 RAG。
如果开启:
rag.chat(prompt, session_config, use_rag=True)
如果关闭:
rag.chat(prompt, session_config, use_rag=False)
这样用户可以很方便地对比知识库模式和普通聊天模式的区别。
---
11.9 流式输出回答
主区域聊天逻辑如下:
prompt = st.chat_input("请输入你的问题...")
if prompt:
...
res = rag.chat(prompt, session_config, use_rag=st.session_state["use_rag"])
def capture(generator, cache_list):
for chunk in generator:
cache_list.append(chunk)
yield chunk
with st.chat_message("assistant"):
st.write_stream(capture(res, ai_res_list))
st.session_state["message"].append(
{"role": "assistant", "content": "".join(ai_res_list)}
)
这段代码实现了流式输出效果。
其中:
st.write_stream()
会让 AI 回复像打字一样逐步显示,提高交互体验。
capture() 函数一边把流式内容显示出来,一边保存到 ai_res_list 中,最后再合并为完整回答,写入当前页面的消息列表。
十二、FastAPI 接口服务
除了 Web 页面,本项目还提供了 API 服务,方便被其他系统调用。
对应文件是:
online_chroma/api.py
---
12.1 FastAPI 应用初始化
app = FastAPI(
title="智能客服 API",
description="基于 RAG 的智能客服服务",
version="1.0.0"
)
这段代码定义了 FastAPI 应用的标题、描述和版本。
---
12.2 跨域配置
app.add_middleware(
CORSMiddleware,
allow_origins=["*"],
allow_credentials=True,
allow_methods=["*"],
allow_headers=["*"],
)
这段代码允许跨域请求,方便前端页面或其他系统调用 API。
---
12.3 请求数据模型
class ChatRequest(BaseModel):
message: str
session_id: str = "user_001"
use_rag: bool = True
api_key: str = None
该模型定义了聊天接口需要接收的字段:

12.4 响应数据模型
class ChatResponse(BaseModel):
response: str
session_id: str
use_rag: bool
接口返回内容包括:
- 模型回答;
- 当前会话 ID;
- 是否使用 RAG 模式。
---
12.5 同步聊天接口
@app.post("/chat", response_model=ChatResponse, summary="同步聊天接口")
async def chat(request: ChatRequest):
try:
api_key = request.api_key or config.DASHSCOPE_API_KEY
if not api_key:
raise HTTPException(status_code=400, detail="API Key 未配置")
if request.session_id not in rag_services:
rag_services[request.session_id] = RAGService(api_key=api_key)
service = rag_services[request.session_id]
service.api_key = api_key
session_config = {
"configurable": {
"session_id": request.session_id
}
}
response = service.chat_sync(
request.message,
session_config,
use_rag=request.use_rag
)
return ChatResponse(
response=response,
session_id=request.session_id,
use_rag=request.use_rag
)
except Exception as e:
raise HTTPException(status_code=500, detail=str(e))
这个接口的处理流程是:
1. 获取 API Key;
2. 检查 API Key 是否存在;
3. 根据 session_id 获取或创建 RAGService;
4. 构造 LangChain 所需的 session_config;
5. 调用 chat_sync() 获取完整回答;
6. 返回结构化响应。
---
12.6 健康检查接口
@app.get("/health", summary="健康检查")
async def health_check():
return {"status": "healthy", "service": "RAG Chat Service"}
该接口用于判断服务是否正常运行。
访问:
GET /health
返回:
{
"status": "healthy",
"service": "RAG Chat Service"
}
---
12.7 删除会话接口
@app.delete("/session/{session_id}", summary="删除会话")
async def delete_session(session_id: str):
if session_id in rag_services:
del rag_services[session_id]
return {"message": f"会话 {session_id} 已删除"}
else:
raise HTTPException(status_code=404, detail="会话不存在")
该接口用于删除内存中的 RAGService 实例。
需要注意的是,这里删除的是内存中的服务实例,不一定会删除本地 chat_history 文件。
---
十三、早期知识库 Demo 说明
项目根目录下还有两个早期版本文件:
knowledgebase.py
文件上传.py
它们可以看作完整 RAG 系统之前的知识库上传 Demo。
---
13.1 knowledgebase.py
该文件主要实现了:
- 字符串 MD5 计算;
- 内容重复检测;
- 文本切片;
- 写入 Chroma 向量库。
核心代码如下:
def get_string_md5(input_str: str, encoding="utf-8"):
str_bytes = input_str.encode(encoding=encoding)
md5_obj = hashlib.md5()
md5_obj.update(str_bytes)
md5_hex = md5_obj.hexdigest()
return md5_hex
这段代码用于计算文本内容的 MD5 值。
上传文本时,通过 MD5 判断内容是否已经存在:
md5_hex = get_string_md5(data)
if check_md5(md5_hex):
return "[跳过]内容已存在知识库中"
这是一种简单的去重方案。
---
13.2 文件上传.py
该文件是一个简单的 Streamlit 上传页面:
uploaded_file = st.file_uploader(
"上传文件",
type=["csv", "xlsx", "txt"],
accept_multiple_files=False
)
用户上传文件后,系统读取文本内容并调用:
reslut = st.session_state["service"].upload_by_str(text, file_name)
将内容写入知识库。
这个早期版本功能比较简单,但它体现了项目的演进过程:
早期 Demo:
文件上传 -> 文本切片 -> 向量库
完整版本:
多格式上传 -> 文档解析 -> 文本切片 -> 向量库 -> RAG 问答 -> 会话历史 -> Web/API 服务
---
十四、完整问答流程示例
以“尺码推荐”为例,完整流程如下。
14.1 知识库准备
假设知识库中有一个文件:
data/尺码推荐.txt
其中包含类似规则:
体重 180 斤的用户,建议选择 XXL 尺码。
身高 175cm 至 180cm 的用户,可以优先考虑 XL 或 XXL。
如果喜欢宽松版型,可以选择大一码。
用户通过 Streamlit 页面上传该文件。
系统执行:
文件上传
↓
临时保存
↓
文件解析
↓
文本切片
↓
Embedding 向量化
↓
写入 Chroma
14.2 用户提问
用户输入:
我体重180斤,应该穿什么尺码?
14.3 系统检索
系统将用户问题转换为向量,在 Chroma 中检索相关片段。
可能检索到:
体重 180 斤的用户,建议选择 XXL 尺码。
14.4 Prompt 构造
系统构造类似这样的 Prompt:
以我提供的资料为主简洁和专业的回答用户问题。
参考资料:
文档片段:体重 180 斤的用户,建议选择 XXL 尺码。
文档元数据:{'source': '尺码推荐.txt'}
并且以我提供的用户对话为历史记录,如下:
历史对话:...
请回答用户提问:
我体重180斤,应该穿什么尺码?
14.5 模型回答
模型最终可能回答:
根据知识库中的尺码推荐规则,你的体重是 180 斤,建议选择 XXL 尺码。如果你更喜欢宽松穿着,可以优先选择 XXL;如果衣服版型偏宽松,也可以结合身高再进一步判断。
---
十五、项目亮点
15.1 功能完整
本项目不仅实现了最基础的 RAG 问答,还包含:
- 知识库上传;
- 多格式文件解析;
- 本地向量库;
- 多轮对话;
- 流式输出;
- Web 页面;
- API 服务。
这使它比简单的 RAG Demo 更接近真实应用。
---
15.2 架构清晰
项目将不同功能拆分到了不同文件中:
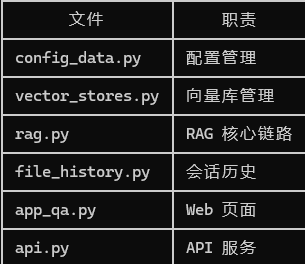
这种结构便于后续维护和扩展。
---
15.3 支持两种使用方式
项目既支持 Streamlit 页面,也支持 FastAPI 接口:
- Streamlit 适合演示和交互;
- FastAPI 适合对外提供服务能力。
这让系统既可以作为本地工具使用,也可以集成到其他系统中。
---
15.4 支持多会话
通过 session_id 和本地 JSON 文件,系统实现了多会话历史管理。
用户可以创建不同会话,每个会话保留独立上下文。
---
15.5 支持流式输出
通过 LangChain 的 .stream() 和 Streamlit 的 st.write_stream(),系统可以实时展示 AI 生成内容,用户体验更好。
---
十六、项目可优化方向
虽然本项目已经完成了一个基础但较完整的 RAG 智能客服系统,但仍有一些可以继续优化的方向。
---
16.1 Prompt 可以进一步增强
当前 Prompt 是:
("system", "以我提供的资料为主简洁和专业的回答用户问题.参考资料:{context}")
可以优化为:
你是一个专业的智能客服助手。请严格基于参考资料回答用户问题。
如果参考资料中没有相关信息,请明确说明“知识库中没有找到相关内容”,不要编造答案。
回答时尽量简洁、准确、结构清晰。
这样可以进一步减少模型幻觉。
---
16.2 检索参数命名可以更准确
当前配置中:
similarity_threshold = 2
但它实际表示返回 Top K 文档数量,而不是相似度阈值。
建议改成:
retrieval_top_k = 2
这样更符合语义。
---
16.3 流式 API 可以使用 StreamingResponse
当前 FastAPI 的 /chat/stream 接口直接返回 generator:
return generate()
更规范的写法是使用:
from fastapi.responses import StreamingResponse
然后返回:
return StreamingResponse(generate(), media_type="text/event-stream")
这样更符合 FastAPI 流式响应规范。
---
16.4 知识库可以增加来源引用
当前回答没有明确展示引用来源。后续可以让模型回答时附带:
参考来源:尺码推荐.txt
这样可以提高回答可信度。
---
16.5 可以增加文件去重机制
早期 Demo 中有 MD5 去重逻辑,但完整版本中上传文件时主要按当前上传批次的文件名去重。
后续可以结合 MD5,对已入库文件做更完整的去重,避免重复文档影响检索结果。
---
16.6 可以增加用户权限和安全控制
当前 FastAPI 允许所有跨域请求:
allow_origins=["*"]
在生产环境中应限制允许访问的域名,并增加身份认证机制。
---
16.7 可以增加前端知识库管理功能
后续可以增加:
- 查看已上传文件列表;
- 删除指定文件;
- 按文件重建向量;
- 查看某条检索结果;
- 导出知识库统计信息。
这样系统会更接近生产级知识库管理平台。
---
十七、项目运行方式
17.1 安装依赖
进入 online_chroma 目录后执行:
pip install -r requirements.txt
依赖文件如下:
streamlit>=1.32.0
fastapi>=0.104.0
uvicorn>=0.24.0
langchain>=0.1.10
langchain-community>=0.0.25
langchain-core>=0.1.0
dashscope>=1.14.0
chromadb>=0.4.22
python-dotenv>=1.0.0
pydantic>=2.5.0
click>=8.1.0
jieba>=0.42.1
tiktoken>=0.5.0
requests>=2.31.0
numpy>=1.24.0
---
17.2 配置 API Key
在项目目录下创建 .env 文件:
DASHSCOPE_API_KEY=你的阿里云百炼API Key
程序会通过 dotenv 自动读取该配置。
---
17.3 启动 Streamlit 页面
streamlit run app_qa.py
访问:
http://localhost:8501
---
17.4 启动 FastAPI 服务
python api.py
接口文档地址:
http://localhost:8000/docs
---
十八、核心代码总结
本项目最关键的代码可以归纳为三部分。
---
18.1 文档入库
split_docs = self.text_splitter.split_documents documents)
self.vector_store.add_documents(split_docs)
这部分负责将原始文档切片并写入向量库。
准确写法应为:
split_docs = self.text_splitter.split_documents(documents)
self.vector_store.add_documents(split_docs)
---
18.2 检索增强生成
chain = (
{
"input": RunnablePassthrough(),
"context": RunnableLambda(temp1) | retriever | format_document
} | RunnableLambda(temp2) | self.prompt_template | print_prompt | self.chat_model | StrOutputParser()
)
这部分是 RAG 的核心。它实现了:
用户问题 -> 检索知识库 -> 构造 Prompt -> 调用大模型 -> 输出答案
---
18.3 会话历史绑定
conversation_chain = RunnableWithMessageHistory(
chain,
get_history,
input_messages_key="input",
history_messages_key="history"
)
这部分让 RAG 链路具备多轮对话记忆能力。
只要传入:
session_config = {
"configurable": {
"session_id": "user_001"
}
}
LangChain 就会自动根据 session_id 读取和写入历史消息。
二十、总结
本项目实现了一个基于 RAG 技术的智能客服问答系统。它通过 LangChain 完成 RAG 链路编排,使用 DashScope Embedding 模型进行文本向量化,使用 Chroma 作为本地向量数据库,并结合通义千问聊天模型生成自然语言回答。
从整体功能来看,系统已经具备一个基础智能客服应用的主要能力:
- 可以上传知识库文件;
- 可以自动完成文本解析、切片和向量化;
- 可以基于知识库回答用户问题;
- 可以支持多轮对话;
- 可以保存历史会话;
- 可以通过 Web 页面使用;
- 可以通过 API 接口调用。
对于学习大模型应用开发的人来说,这个项目覆盖了 RAG 系统开发中的核心流程,包括文档加载、文本切片、向量存储、相似度检索、Prompt 构造、大模型调用、流式输出和会话管理。
从工程实践角度看,这个项目虽然还可以继续增强,例如优化 Prompt、增加引用来源、完善流式 API、增加权限控制和知识库管理功能,但它已经形成了一个比较完整的 RAG 应用闭环。
因此,本项目不仅适合作为 RAG 技术学习案例,也可以作为后续开发企业知识库问答、智能客服、商品推荐助手、文档问答助手等系统的基础框架。
---
附录:博客中可重点强调的技术点
1. RAG 的核心价值
RAG 不是让大模型凭空回答,而是让模型先查资料,再根据资料回答。这可以明显提升回答的准确性和业务可控性。
---
2. 文本切片的重要性
文档不能直接整篇放入向量库。合理切片可以提升检索精度,也能避免上下文过长。
---
3. 向量数据库的作用
Chroma 存储的不是普通文本索引,而是文本对应的语义向量。用户问题也会被转成向量,然后通过向量相似度找到相关内容。
---
4. Prompt 决定模型如何使用知识库
RAG 系统不仅要能检索,还要通过 Prompt 告诉模型如何使用检索结果。Prompt 设计不好,模型可能忽略资料或产生幻觉。
---
5. RunnableWithMessageHistory 实现多轮对话
LangChain 的 RunnableWithMessageHistory 可以将链路与历史消息绑定,让系统支持多轮上下文。
---
6. Streamlit 适合快速做 AI 应用原型
通过 Streamlit,可以用较少代码快速构建一个可交互的 AI 问答界面,适合项目演示和原型开发。
---
7. FastAPI 让 RAG 能力服务化
通过 FastAPI,可以把 RAG 问答能力封装成 HTTP 接口,方便其他系统集成调用。
---
附录:可直接放入 Word 的项目流程图
用户上传文件
↓
临时保存文件
↓
根据文件类型解析内容
↓
转换为 Document 对象
↓
RecursiveCharacterTextSplitter 文本切片
↓
DashScope Embedding 向量化
↓
写入 Chroma 向量数据库
↓
用户输入问题
↓
Retriever 检索相关文档片段
↓
组合 context + history + input
↓
ChatTongyi 生成回答
↓
Streamlit 流式展示
↓
保存会话历史

欢迎加入 MCP 技术社区!与志同道合者携手前行,一同解锁 MCP 技术的无限可能!
更多推荐
 15
15 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)