AI Agent到底是什么?从“聊天”到“做事”
1.1 一句话说清楚
先来个最直白的对比:
-
传统LLM(如ChatGPT) :你问一句,它答一句。像个“超级大脑”,但只有大脑,没有手和脚。
-
AI Agent:不仅有大脑(LLM),还有手和脚(工具调用)、有记忆(Memory)、会自己规划(Planning)。它不只是回答问题,而是帮你完成目标。
工业界有一个公认的定义,来自OpenAI的Lilian Weng:
Agent = LLM + 规划 + 记忆 + 工具使用
你可以把单独的LLM想象成一个智商极高、但被关在没有窗户、没有网络、没有笔记本的房间里的天才——你推门问一句,他答一句;关上门再进来,他已经忘了刚才聊过什么。
而AI Agent,就是给这个天才装上眼睛、双手、笔记本和日程表。
1.2 核心特征:四个关键词
一个真正的AI Agent具备四个核心特征:
| 特征 | 什么意思 | 举个例子 |
|---|---|---|
| 自主性 | 不用你每一步都指挥 | 你说“帮我订机票”,它自己会去比价、下单 |
| 工具调用 | 能调用外部API/插件 | 调用支付接口、查天气API、操作数据库 |
| 记忆机制 | 能记住之前的事 | 短期记对话,长期记用户偏好 |
| 目标导向 | 所有行动围绕目标展开 | 把“策划团建”拆成查日历、订场地、发邀请 |
1.3 一句话总结
传统AI是“回答工具”,AI Agent是“行动者”。
二、内部架构长什么样?四大模块拆给你看
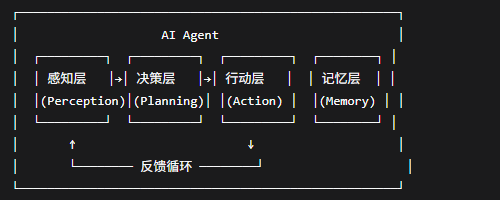
2.1 感知层(Perception)——“感官系统”
负责接收和理解用户的输入。不只是文本,还可以是语音、图像等。
比如你说“帮我看看这张发票对不对”,感知层会识别图片里的文字信息,然后传给大脑处理。
2.2 决策层(Planning)——“大脑引擎”
这是Agent最核心的部分,由LLM驱动。它负责三件事:
-
目标分解:把大目标拆成小步骤。比如“策划团建” → 查日历 → 找场地 → 发邀请 → 统计人数
-
工具选择:决定用什么工具来完成每一步
-
策略制定:规划做事的先后顺序
2.3 行动层(Action)——“执行手臂”
负责真正“干活”。可以调用三类工具:
-
内置工具:计算器、代码解释器
-
插件/API:支付接口、日历API、数据库
-
RPA机器人:模拟人操作软件界面
2.4 记忆层(Memory)——“笔记本”
-
短期记忆:当前对话的上下文,类似人的“工作记忆”
-
长期记忆:存在向量数据库里,跨会话保留
有了记忆,Agent才不会“转身就忘”——你昨天跟它说过的事,今天它还记得。
三、核心工作模式:ReAct循环——Agent的“呼吸节奏”
理解了架构,还得知道Agent是怎么“思考”的。目前最主流的模式叫 ReAct(Reasoning + Acting) 。
3.1 什么是ReAct?
ReAct就是一个循环:思考 → 行动 → 观察 → 再思考 → 再行动…… 直到任务完成。
用大白话翻译:
-
Thought(思考) :Agent在心里想“我现在该干嘛?”
-
Action(行动) :Agent动手去做(比如查个API)
-
Observation(观察) :Agent看看结果怎么样
-
然后回到第一步,继续想下一步
这就像你做饭:先想“要做番茄炒蛋”,然后去打蛋、切番茄(行动),看看火候怎么样(观察),再决定要不要加点盐(再思考)。
3.2 一个具体例子
用户问:“北京今天天气怎么样?适合穿什么?”

3.3 为什么ReAct这么重要?
ReAct让LLM从“只动嘴”变成了“边想边做”。它模拟了人类的内心独白,把推理(Chain-of-Thought)和工具使用结合起来,让Agent能动态应对各种情况。
简单说:没有ReAct,Agent就是个只会说不会做的花瓶。
四、用户使用时为什么“感觉没那么神”?
好,现在进入正题——为什么理论上很完美的Agent,用起来却经常差强人意?
4.1 问题一:规划能力不足——“想得太简单”
Agent的核心是LLM,而LLM本质上是“下一个词预测器”,不是真正的“规划器”。
什么意思?就是它看起来在规划,实际上是在模仿人类规划的样子,但缺乏真正的因果推理能力。
典型表现:
-
把复杂任务拆解得过于简单,漏掉关键步骤
-
遇到意外情况就懵了,不知道调整计划
-
在多步骤任务中“迷失方向”
有研究指出,Agent规划失败的两个关键因素是:约束条件的作用有限和问题的影响力递减。翻译成人话就是:Agent不太会考虑“如果A不行该怎么办”,而且越往后执行越容易忘记最初的目标。
4.2 问题二:记忆能力薄弱——“记性不好”
Agent的记忆主要靠LLM的上下文窗口。窗口再大也有上限(虽然现在有些模型支持百万token,但成本极高)。
典型表现:
-
对话一长,前面的内容就“忘”了
-
跨会话完全不记得你
-
长期任务中信息丢失,导致前后矛盾
特斯拉AI前成员Andrej Karpathy直言:“现在的AI无法记住和用户的每一次互动,当关掉对话窗口后,它就会忘掉。”
4.3 问题三:幻觉问题——“瞎编乱造”
LLM本来就爱“ hallucinate”(幻觉),Agent继承了这个问题。
典型表现:
-
调用工具后,对结果进行错误解读
-
工具调用失败时,自己“脑补”一个答案
-
把不相关的信息强行关联起来
4.4 问题四:多工具协同困难——“手忙脚乱”
当任务需要调用多个工具时(比如同时操作文件、邮件、数据库),很多Agent就“掉链子”了。
典型表现:
-
工具之间信息传递出错
-
执行顺序混乱
-
卡在某个步骤无法继续
有用户反馈,Manus在处理涉及多个工具的任务时,常常在执行中卡住、步骤结果传递错误,或耗时超过一小时。
4.5 问题五:成本失控——“太贵了”
ReAct模式需要多轮LLM调用。每多一轮就多一笔token费用。
典型表现:
-
简单任务被过度复杂化,浪费token
-
任务失败后重复尝试,成本飙升
-
用户发现还不如直接问ChatGPT划算
有报道称,某AI工具“一周烧1000美元,修不好bug还顺手删库”。
五、官方和业界怎么解决?
问题不少,但解决方案也在快速演进。
5.1 解决方案一:自我反思(Self-Reflection)——“学会检查自己”
核心思想:让Agent在执行过程中停下来,检查一下自己做得对不对。
具体做法是让Agent在每步行动后问自己三个问题:
-
“我这一步做得对吗?”
-
“有没有更好的做法?”
-
“我是不是跑偏了?”
代表技术:
-
Reflexion(2023年提出):用语言反馈来防止重复犯错
-
Self-Refine:让模型自己生成反馈并改进
-
MIRROR:多Agent互相检查,既有“自我反思”也有“互相反思”
5.2 解决方案二:增强规划(Enhanced Planning)——“先想好再动手”
核心思想:别让Agent“边想边做”那么冲动,先花点时间好好规划。
典型做法是 “先做多步规划,再结合ReAct执行” 。就像你出门旅行前先做好攻略,而不是走到哪儿算哪儿。
5.3 解决方案三:MCP协议——“标准化工具箱”
核心思想:让工具调用变得标准化、可插拔。
2024年底,Anthropic发布了 MCP(Model Context Protocol) 。你可以把它理解成 “AI的USB接口” ——不管什么工具,只要符合MCP标准,Agent就能直接插上用,不用每个工具单独写适配代码。
这让Agent的工具调用从“定制化”走向了“标准化”,大大降低了开发成本和出错概率。
5.4 解决方案四:记忆系统升级——“好记性不如烂笔头”
核心思想:用外部存储来解决LLM上下文窗口的限制。
-
向量数据库:把历史信息存成向量,需要时语义检索
-
MemGPT:动态管理记忆,突破上下文窗口限制
-
Graph-RAG:把知识存成实体关系图,支持多跳推理
5.5 解决方案五:多Agent协作——“三个臭皮匠”
核心思想:不让一个Agent单打独斗,而是多个Agent分工合作。
比如一个Agent负责规划、一个负责执行、一个负责检查。互相监督、互相补充,降低单个Agent犯错的风险。
5.6 解决方案六:工程化落地——Anthropic的三条原则
Anthropic在2025年分享了构建有效Agent的三个核心原则:
-
选择性使用:不是所有场景都需要Agent,简单任务用普通LLM就够了
-
保持简单:架构越复杂越容易出问题
-
从Agent的视角思考:站在Agent的角度设计,而不是从开发者角度
六、VSCode代码解析:手把手看一个Agent怎么工作
光说不练假把式。下面我们用一段实际代码来看看Agent到底是怎么工作的。
6.1 完整代码示例
以下代码基于LangChain框架,构建一个能查天气和搜索信息的简单Agent
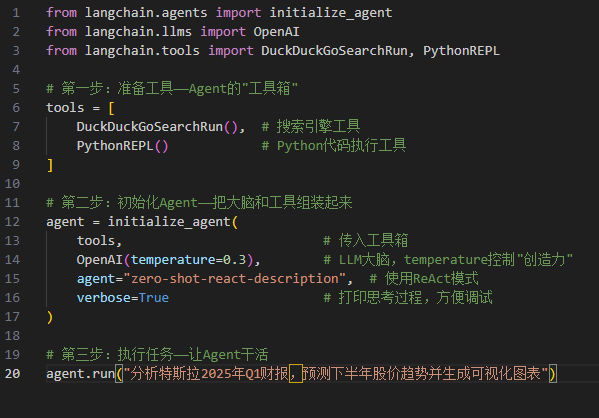
6.2 逐行深度解析
第一段:准备工具
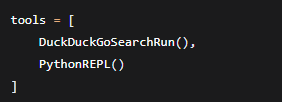
这步在干嘛? 给Agent配“装备”。
-
DuckDuckGoSearchRun():让Agent能上网搜索。相当于给了它一个浏览器。 -
PythonREPL():让Agent能执行Python代码。相当于给了它一个计算器+代码编辑器。
为什么需要工具? LLM的知识是训练时“记住”的,有截止日期(比如2024年1月)。要查最新信息(比如特斯拉2025年Q1财报),必须靠搜索工具。
第二段:初始化Agent
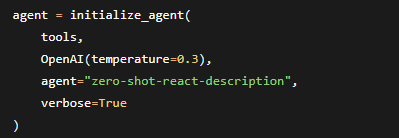
参数逐个解释:
| 参数 | 作用 | 白话翻译 |
|---|---|---|
tools |
传入工具箱 | “给你这些工具,你看着用” |
OpenAI(temperature=0.3) |
选择LLM大脑,temperature控制随机性 | temperature越低越“冷静”越准确,越高越“有创意”但可能胡说 |
agent="zero-shot-react-description" |
使用ReAct模式 | “你要边想边做,边做边看” |
verbose=True |
打印详细过程 | “把你心里想啥都告诉我” |
什么是"zero-shot-react-description"? 这是一种Agent类型,意思是“不用提前训练,直接根据工具描述就知道怎么用”。LLM会读取每个工具的描述文字,然后自己判断什么时候该用什么工具。
第三段:执行任务
![]()
执行时内部发生了什么? 这就是ReAct循环在跑:
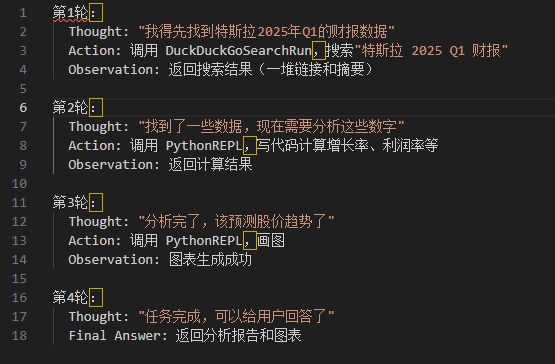
verbose=True 会把上面这些“内心独白”全部打印出来,你可以亲眼看到Agent是怎么一步步思考和行动的。
6.3 这段代码的局限性
这个例子看起来很酷,但实际用起来可能会遇到我们前面说的那些问题:
-
搜索可能失败:如果搜不到准确数据,Agent可能瞎编
-
分析可能出错:Python代码写错了怎么办?Agent不会自己debug
-
多步骤可能乱套:如果任务再复杂一点(比如还要对比竞争对手),Agent可能搞混顺序
-
成本不低:每一轮都要调用LLM,token消耗很快
所以,Demo很酷,生产环境要谨慎——这恰恰印证了我们前面讨论的问题。
七、总结与展望
7.1 核心 takeaways
| 你想知道的 | 答案 |
|---|---|
| Agent是什么 | LLM + 规划 + 记忆 + 工具使用 |
| 怎么工作的 | 感知→规划→行动→观察,循环往复 |
| 核心模式 | ReAct(思考-行动-观察循环) |
| 为什么不够好 | 规划弱、记忆差、爱幻觉、多工具协同难、成本高 |
| 怎么解决 | 自我反思、增强规划、MCP协议、记忆升级、多Agent协作 |
7.2 一句话总结
AI Agent的本质是用LLM当大脑,通过ReAct循环不断思考、行动、观察,直到完成任务。它很强大,但远非完美——规划能力不足、记忆有限、爱幻觉、多工具协同困难,这些都是当前亟待解决的问题。官方和学术界正在通过自我反思、增强规划、MCP标准化、记忆升级和多Agent协作等方式逐步攻克这些难题。
小编建议
-
别迷信“万能Agent” ——垂直场景比通用场景更容易成功
-
简单任务别用Agent ——能用普通LLM解决的问题,别上Agent
-
做好容错 ——Agent一定会犯错,设计好降级方案
-
关注成本 ——ReAct模式token消耗大,做好预算控制
-
重视记忆 ——没有好记忆的Agent,用户体验一定差
AI Agent还在快速进化中,还需要一个阶段性的时间!

欢迎加入 MCP 技术社区!与志同道合者携手前行,一同解锁 MCP 技术的无限可能!
更多推荐

 6
6 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)