AI Agent 记忆机制:让 Agent 真正“记住你”
从四层记忆、读写闭环到生产级 Memory Service 架构
很多人一提到 Agent 记忆,就会想到“把聊天记录存起来”。这个理解只对了一小半。真正能落地的记忆系统,不是把历史消息无限塞进上下文,而是把信息分层:哪些放在当前上下文,哪些沉淀到长期库,哪些提炼成结构化字段,哪些应该过期、删除或禁止写入。
这一章重点讲清楚三个问题:Agent 记忆分几层?工程上怎么存?什么时候取出来用?
1. 没有记忆的 Agent,本质上只是一次性问答工具
没有记忆的 Agent 每次都像第一次见你。你今天告诉它“代码要简洁,变量名用英文,少写废话注释”,明天让它继续开发,它可能又输出一堆冗长注释。不是它不听话,而是它压根没有可用的记忆。
更麻烦的是多步任务。你让它“先查资料,再生成报告”,如果没有短期状态,报告阶段就不知道前面查到了什么;如果没有长期记忆,下次遇到类似任务又要重新踩坑。

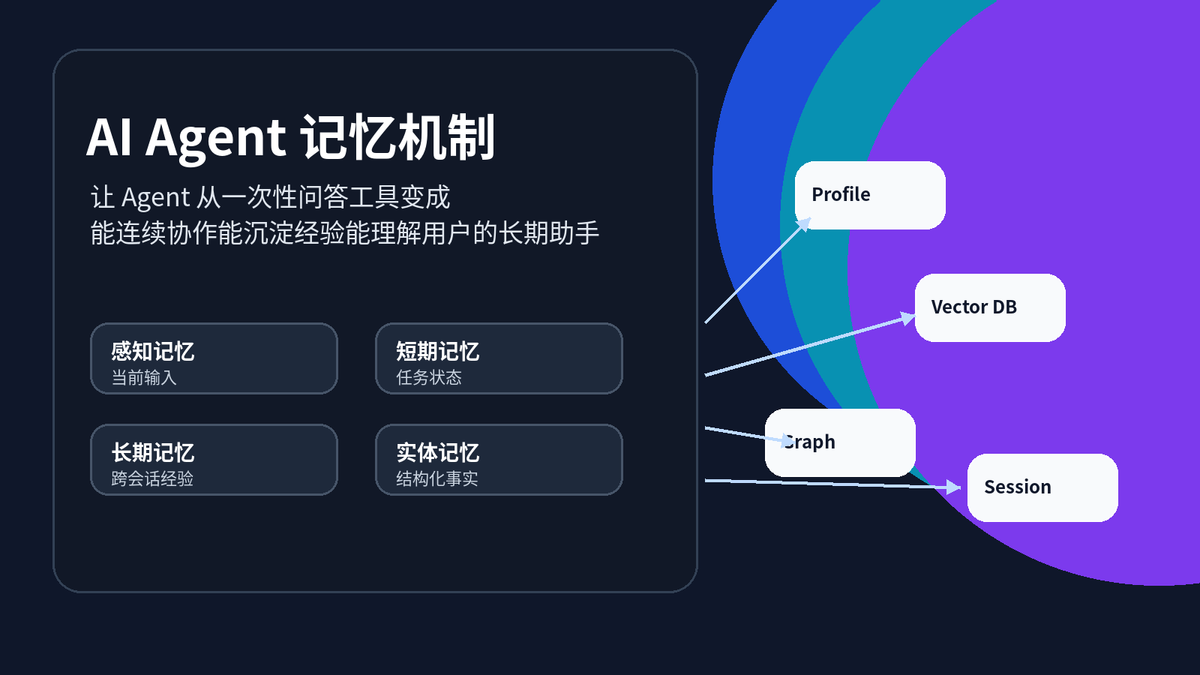
无记忆 Agent 与有记忆 Agent 的差异
2. Agent 的四层记忆:感知、短期、长期、实体
Agent 记忆可以拆成四层来看:感知记忆、短期记忆、长期记忆、实体记忆。它们不是学术上绝对严谨的心理学分类,而是工程上非常实用的分层方法。
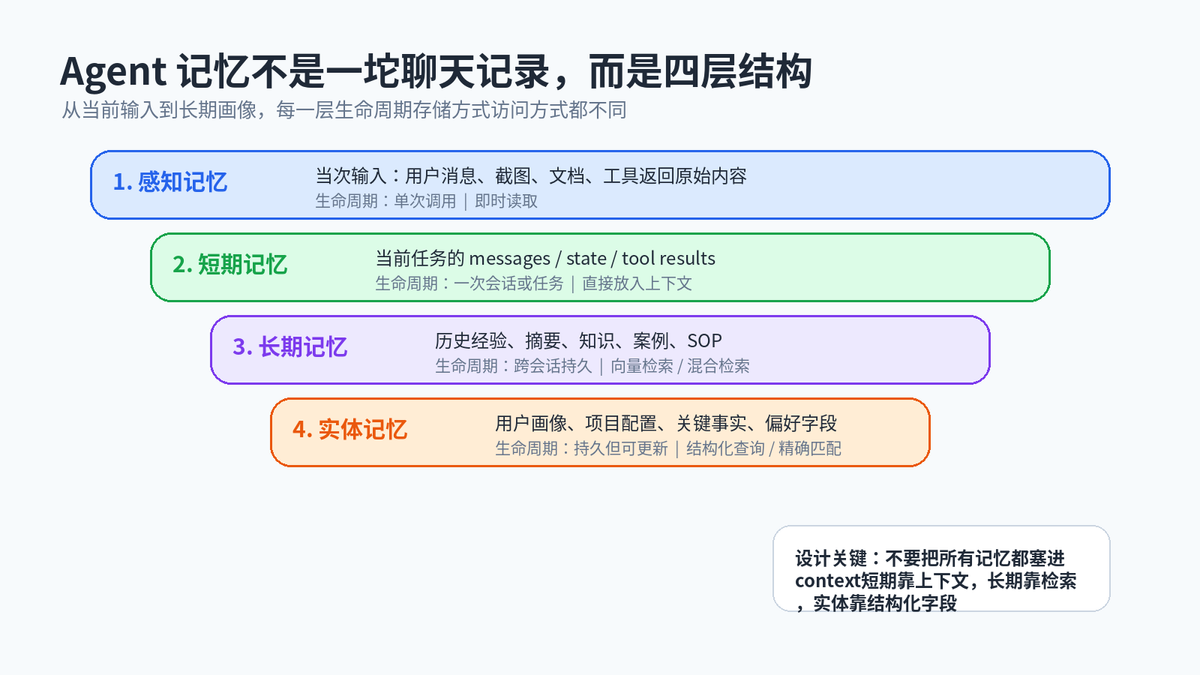
2.1 感知记忆:刚输入进来的原始材料
感知记忆是当前这次调用刚拿到的原始输入:用户消息、截图、文件、网页内容、工具返回结果。它的生命周期很短,通常只服务当前一次处理。
2.2 短期记忆:当前任务的工作台
短期记忆通常就是 messages、state、tool results、scratchpad。它解决的是“当前任务做到哪一步”的问题。比如已经查了哪些资料、工具返回了什么、用户刚刚改了什么需求。
2.3 长期记忆:跨会话可复用的历史经验
长期记忆存在外部存储里,任务结束后也不会消失。它可以是向量库里的经验摘要,也可以是知识库里的文档,或者是历史任务的复盘结论。长期记忆又可以细分为情节记忆、语义记忆和程序记忆:
情节记忆:某一次具体经历,比如“上次做爬虫时被反爬,最后用 Playwright 解决”。
语义记忆:从多次经历中提炼出来的通用规律,比如“动态渲染页面优先考虑浏览器自动化”。
程序记忆:可复用的操作流程,比如“部署 Flask 服务的标准步骤”。
2.4 实体记忆:结构化事实和用户画像
实体记忆不是存原话,而是把对话中出现的关键事实提炼出来,存成结构化字段。例如:用户偏好 Python、项目截止日是 6 月底、客户预算是 5 万。它查询快、信息密度高,也更容易做权限控制和过期管理。
3. 存什么:不是所有内容都值得进入长期记忆
记忆写入的第一原则是价值判断:这条信息下次任务知道以后,会不会让 Agent 做得更好?会,就存;不会,就不要存。
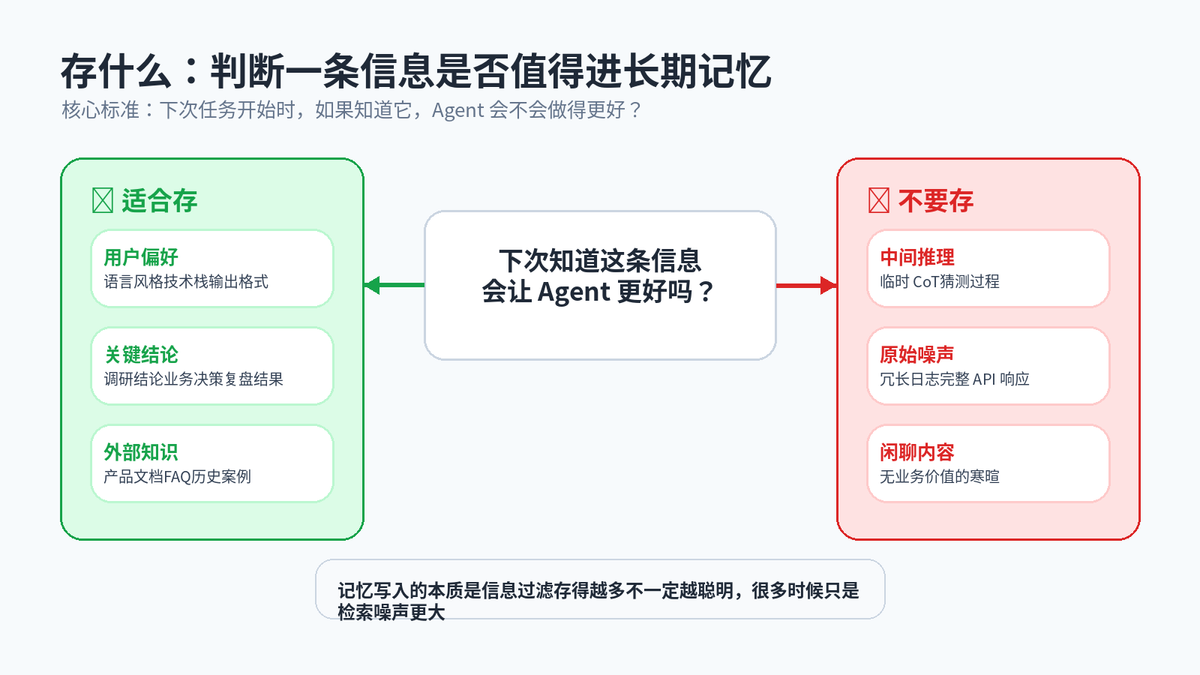
值得存的通常有三类:用户偏好和习惯、任务中的关键结论和决策、外部知识和历史案例。不值得存的包括临时推理过程、冗长原始日志、一次性闲聊。存太多不是聪明,而是把检索信噪比搞低。
4. 怎么存:混合存储,而不是全部塞向量数据库
生产环境里,记忆系统通常不是一个单独的 Vector DB。更常见的是混合存储:短期状态放 Session 或 Checkpoint;结构化实体放关系库或 KV;非结构化知识放向量库;实体关系放图谱。
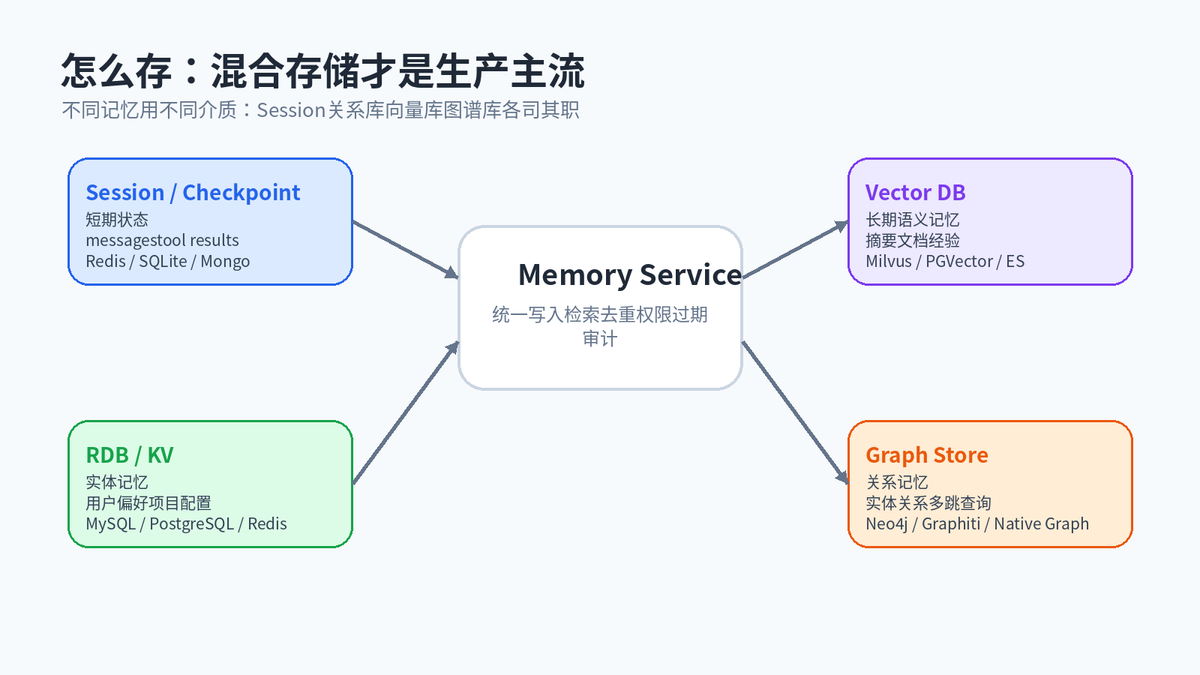
Session / Checkpoint:保存短期消息、工具结果、当前任务状态,适合恢复中断任务。
关系数据库 / KV:保存用户画像、项目配置、偏好字段,适合精确查询。
向量数据库:保存文档、摘要、历史案例,适合语义检索。
图谱存储:保存实体和关系,适合多跳推理和实体中心查询。
5. 什么时候取:主动检索 + 按需检索
记忆不是每次都全量塞进 Prompt。更好的方式是:任务开始前主动加载必要背景;执行过程中再按需调用“查记忆”工具;最终把检索结果重排、过滤、压缩后注入上下文。
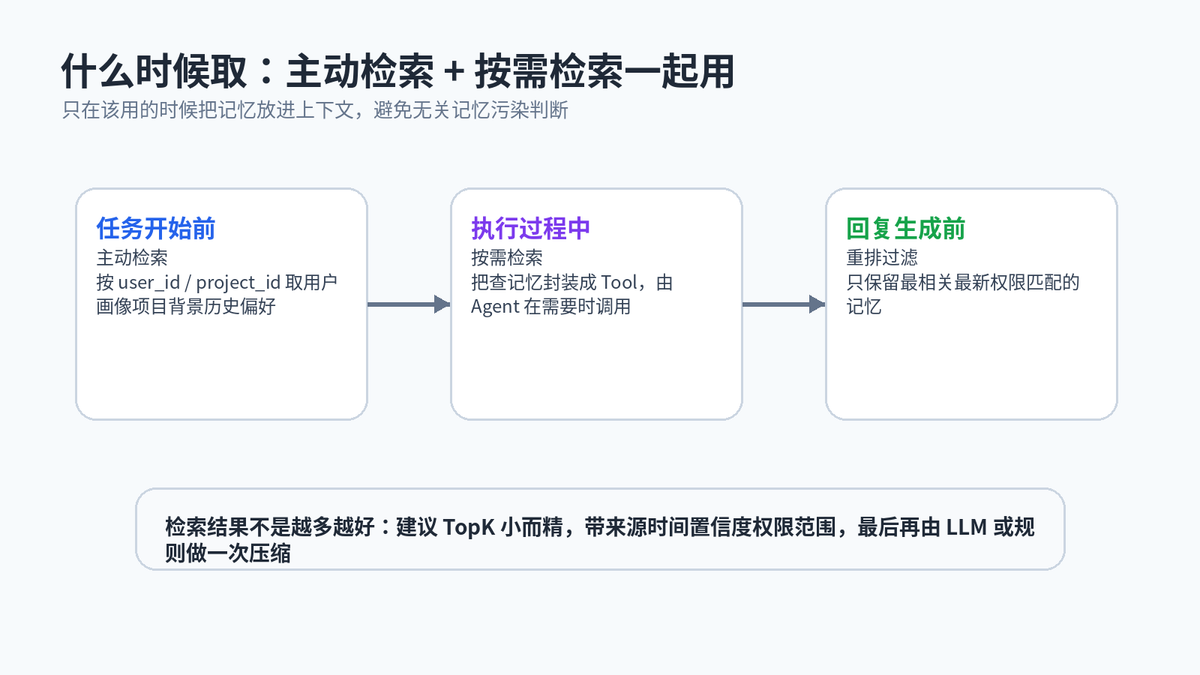
主动检索适合加载用户画像、项目背景、长期偏好;按需检索适合任务过程中临时查历史案例、接口文档、旧决策。两者结合,既能保持个性化,又不至于让无关记忆污染推理。
6. Context Window 管理:短期记忆的工作台也要清理
短期记忆存在上下文窗口里,而上下文窗口一定有成本。即使模型支持超长上下文,把所有历史都塞进去也会带来延迟、成本和注意力分散。

常见方案有三种:滑动窗口、摘要压缩、长期卸载。滑动窗口简单但可能丢关键早期信息;摘要压缩节省 token 但会有摘要漂移;长期卸载能降低上下文噪声,但依赖后续召回能力。
7. 知识图谱:让记忆之间产生关系
向量检索擅长“找意思相近的文本”,但它不擅长关系推理。比如“用户 A 是公司 B 的 CTO”和“公司 B 做云计算”是两条不同记忆,单靠相似度不一定能把它们连起来。知识图谱适合把实体和关系组织起来,支持多跳查询。
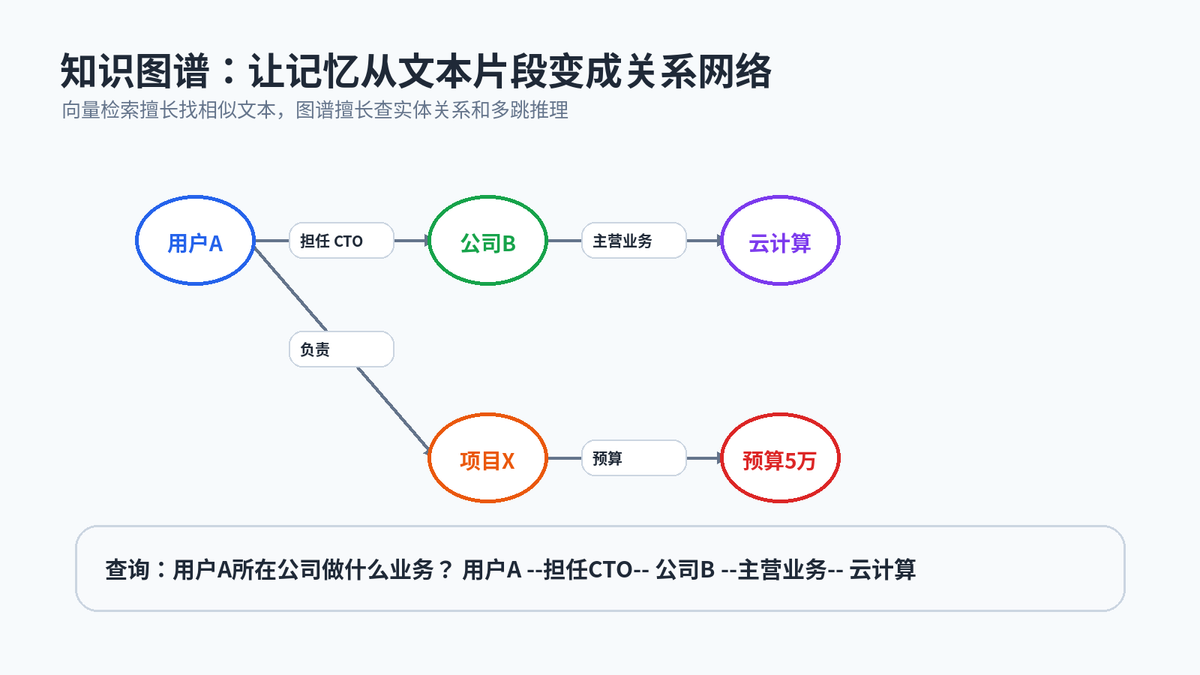
实体关系与多跳查询示意图
工程上可以把向量检索和图谱检索结合:先用向量库拿到候选记忆,再用图谱补充关联实体和关系,最后合并成一段干净的上下文给 Agent 使用。
8. 记忆整合:长期记忆要越用越精炼
长期记忆如果只写不整理,迟早会变成垃圾堆。同一个偏好可能被存很多遍,旧事实可能已经失效,甚至不同记忆之间会互相矛盾。
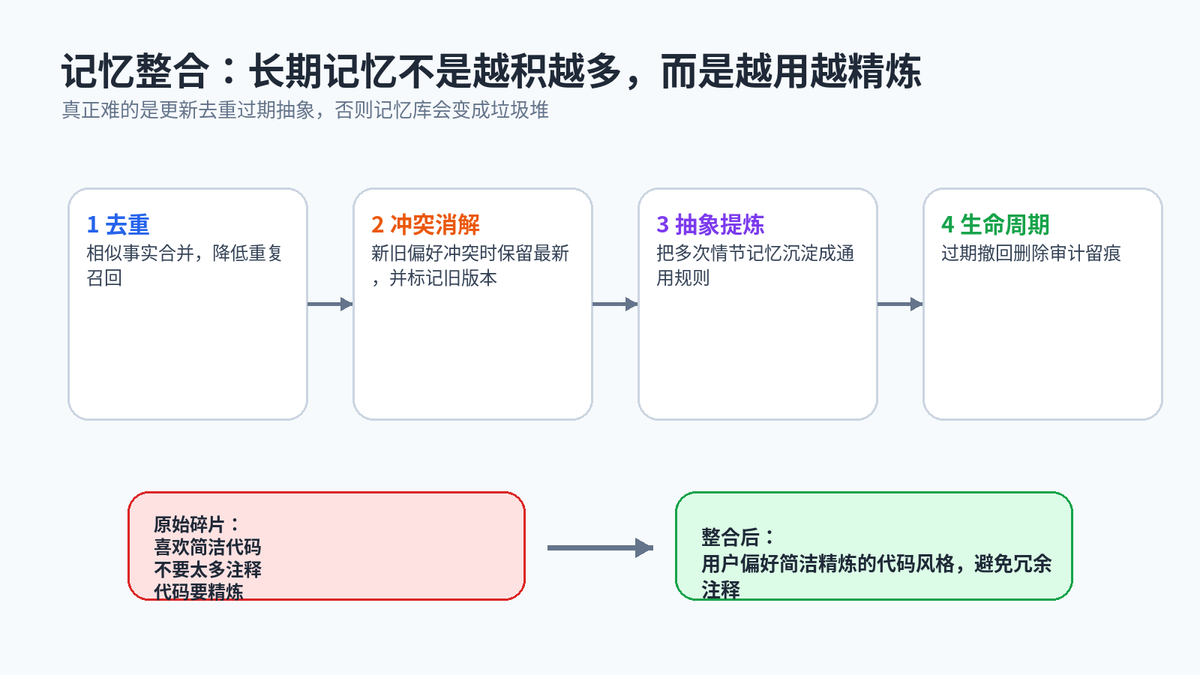
记忆整合的四个关键动作
去重:把表达相同意思的多条记忆合并。
冲突消解:新旧事实冲突时保留最新版本,旧版本标记为过期。
抽象提炼:从多次情节记忆中总结出稳定规律,形成语义记忆。
生命周期管理:设置有效期、可撤回、可删除、可审计。
9. 完整记忆闭环:读、用、写
一个完整的 Agent 记忆模块,可以用三个字概括:读、用、写。开始前读记忆,执行中用记忆,结束后写记忆。
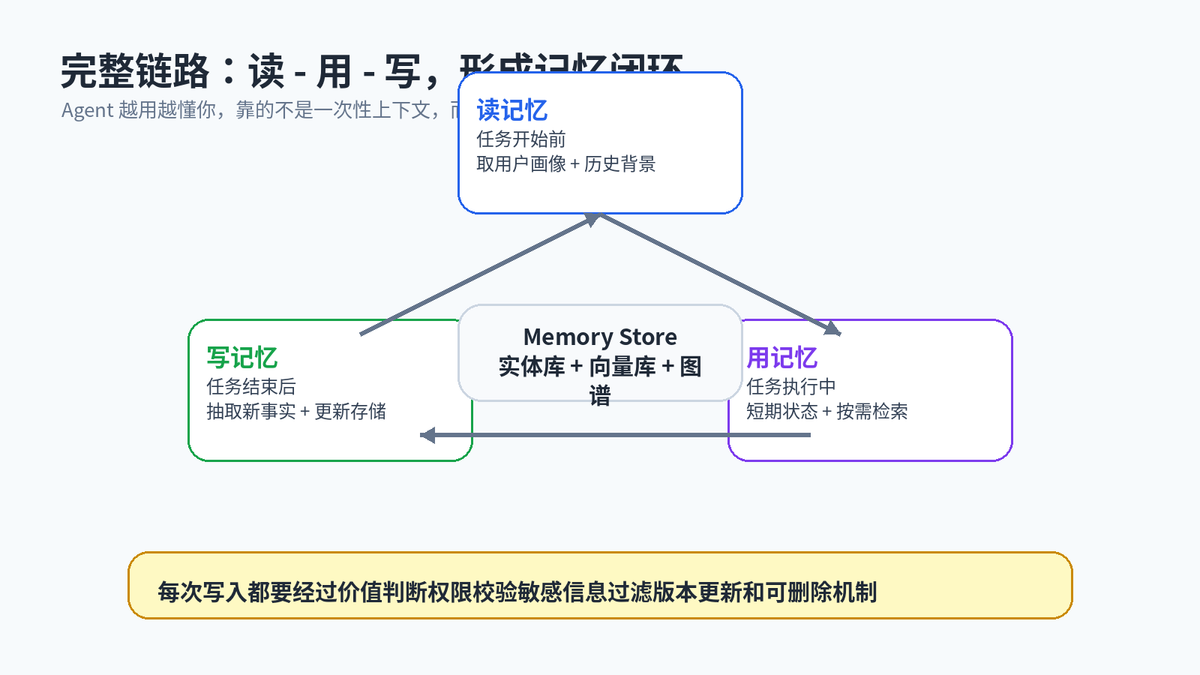
读记忆时要做权限过滤和相关性重排;用记忆时要控制注入长度,避免噪声;写记忆时要做价值判断、敏感信息过滤、版本管理和审计。这样 Agent 才能在长期使用中越来越了解用户,而不是越记越乱。
10. 代码示例:一个最小可落地的 Memory 结构
记忆记录不能只存 content。至少要带上作用域、类型、来源、时间、置信度、有效期和审计字段。否则后续无法做删除、回滚、权限隔离和冲突消解。
from dataclasses import dataclass
from datetime import datetime
from typing import Literal, Optional
MemoryType = Literal["profile", "episodic", "semantic", "procedural", "entity"]
@dataclass
class MemoryRecord:
id: str
user_id: str
tenant_id: str
memory_type: MemoryType
content: str
source: str # conversation / tool / document / human
confidence: float # 0.0 - 1.0
created_at: datetime
updated_at: datetime
expires_at: Optional[datetime]
embedding_id: Optional[str]
entity_keys: list[str]
metadata: dict写入流程建议拆成五步:抽取候选事实、判断是否值得存、做敏感信息过滤、选择存储介质、写入索引并记录审计日志。
class MemoryService:
def write_after_task(self, user_id: str, messages: list[dict], task_result: str):
candidates = self.extract_candidates(messages, task_result)
for item in candidates:
if not self.is_worth_remembering(item):
continue
if self.contains_sensitive_data(item):
continue
item = self.resolve_conflict_and_deduplicate(user_id, item)
if item.type in ["profile", "entity"]:
self.profile_store.upsert(user_id, item)
elif item.type in ["episodic", "semantic", "procedural"]:
self.vector_store.upsert(user_id, item)
self.audit_log.record(user_id=user_id, action="memory_write", memory=item)
def retrieve_for_task(self, user_id: str, query: str) -> list[str]:
profile = self.profile_store.get_user_profile(user_id)
candidates = self.vector_store.search(user_id=user_id, query=query, top_k=20)
reranked = self.reranker.rank(query, candidates)[:5]
return self.compress_for_prompt(profile, reranked)11. 生产级架构:把 Memory 做成独立服务层
如果 Agent 只是 Demo,把记忆逻辑写在业务代码里问题不大。但一旦涉及多用户、多租户、多模型、多工具调用,Memory 最好独立成服务层。
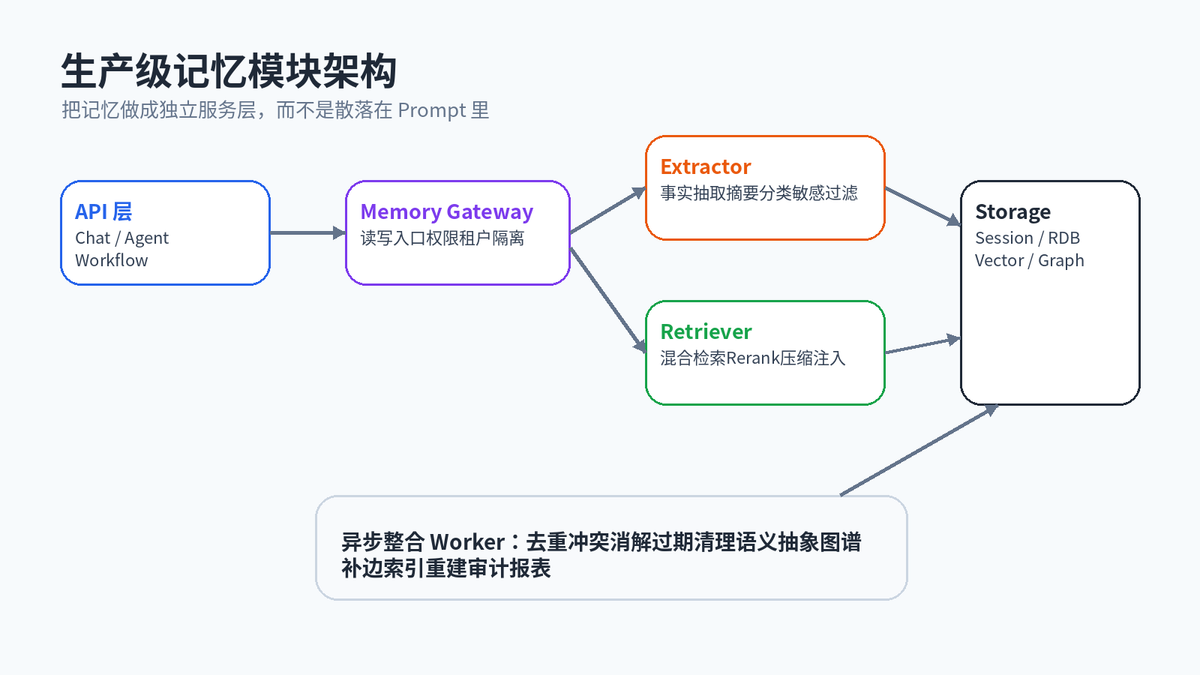
Memory Gateway 负责统一读写入口、权限校验、租户隔离;Extractor 负责抽取事实、摘要、实体、敏感信息过滤;Retriever 负责混合检索、重排、压缩注入;Storage 负责 Session、RDB、Vector、Graph 的统一适配;Worker 负责异步去重、冲突消解和定期整理。
12. 记忆安全:越会记,越要守规矩
记忆系统会放大 Agent 的能力,也会放大风险。错误记忆会让 Agent 持续犯错;过期记忆会误导决策;越权记忆会造成严重隐私问题。
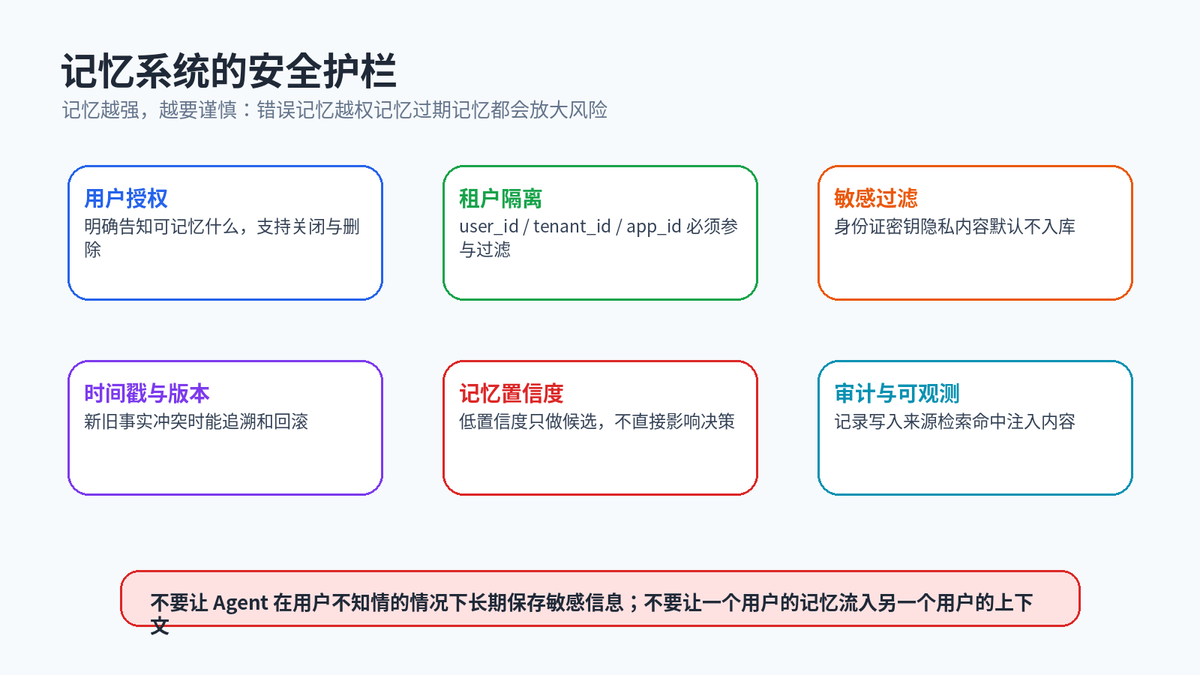
默认最小化写入:只存对未来任务有明确价值的信息。
明确作用域:每条记忆都必须绑定 user_id、tenant_id、app_id 或 project_id。
敏感信息默认不入库:密钥、证件号、隐私内容需要脱敏或禁止写入。
支持删除和过期:用户应能要求删除记忆,系统也要能处理过期事实。
检索结果可观测:记录命中了哪些记忆、为什么注入上下文。
13. 总结
回答 Agent 记忆机制,别只说“短期记忆和长期记忆”。更完整的回答应该是:四层分类 + 三个工程问题 + 一条读用写闭环。
四层分类:感知记忆、短期记忆、长期记忆、实体记忆。
三个问题:存什么、怎么存、什么时候取。
一条闭环:任务开始读记忆,任务执行用记忆,任务结束写记忆。
生产原则:混合存储、按需检索、定期整合、权限隔离、安全可删。
真正的 Agent 记忆不是“无限上下文”,而是“可管理的信息资产”。把它设计好,Agent 才能从一次性工具变成长期协作伙伴。

欢迎加入 MCP 技术社区!与志同道合者携手前行,一同解锁 MCP 技术的无限可能!
更多推荐



 0
0 0
0- 0



 已为社区贡献37条内容
已为社区贡献37条内容

所有评论(0)