Codex 必装的5个插件(附操作指南)
Codex 必装的 5 个科研插件与全流程配置指南
在科研和学术开发场景中,如果仅将 OpenAI Codex 当作一个基础的“代码自动补全工具”,显然无法完全发挥其潜能。
通过接入特定的插件与 MCP(Model Context Protocol,模型上下文协议)服务,Codex 能够深度融入学术工作流。
它不仅能帮你检索前沿文献、运行本地实验、清洗学术数据,甚至还能辅助你梳理审稿人意见。
本文将为你盘点 5 款实用的 Codex 科研插件,并手把手带你完成从本地环境到 API 服务的全套配置。
---
一、 5 款核心科研插件深度解析
1. Claude Scholar:科研任务的执行骨干
- 项目地址:
https://github.com/Galaxy-Dawn/claude-scholar - 适用场景:处理高重复性、结构化的科研繁琐工作。
Claude Scholar 是目前在 Codex 命令行端支持度极高的半自动化研究辅助工具。
它的设计理念非常明确:不代替研究者做方向性决策,只专注于高效执行具体任务。
该工具内置了 40 多个专门针对学术场景优化的 Skill 模块,能够辅助构建“提出假设、搜寻文献、实验分析、生成论证”的闭环。
例如,它能自动调用 SymPy 逐步验证数学公式推导,利用 OpenAlex 接口抓取数亿篇学术文献的结构化数据,或自动检查 LaTeX 文档中的引用是否与本地文献库完全对齐。

2. OneSkills:AI 与计算机科学实验的打底框架
- 项目地址:
https://github.com/onescience-ai/oneskills - 适用场景:深度学习实验流程拆解、环境配置与 Baseline 运行。
OneSkills 源自阿里 ModelScope 团队的科研模型开发经验,并将其转化为一组可直接触发的 Agent 技能。
对于从事计算机科学或人工智能方向的研究者来说,它是一个实用的“实验助手”。
当你有了一个新的研究想法时,OneSkills 可以辅助拆解深度学习的实验步骤。
它能够理解你的任务意图,并帮你梳理环境配置、数据预处理以及基线模型运行的底层逻辑。

3. Zotero-MCP & Obsidian-Skills:打通本地第二大脑
- 项目地址:
https://pypi.org/project/zotero-obsidian-mcp/ - 适用场景:文献库管理与学术笔记自动化。
文献库和本地笔记是科研工作的基础。
通过 MCP 协议,你可以让 Codex 直接与本地数据库建立连接,无需手动复制粘贴 PDF 内容。
接通后,Codex 可以直接读取 Zotero 中存储的 PDF 文献,并自动将结构化总结写入 Obsidian 本地工作区中。
整个过程无需频繁切换窗口,实现了知识管理流程的无缝对接。
4. ARIS:自动化代码迭代与实验运行框架
- 项目地址:
https://github.com/wanshuiyin/Auto-claude-code-research-in-sleep - 适用场景:全自动化的代码迭代与对比实验运行。
如果你需要运行大量的对比实验,Auto-research-in-sleep (ARIS) 框架非常值得尝试。
它利用 Codex 作为底层执行工具,并结合其他大模型进行交叉审查(Cross-provider Review)。
该框架可以实现“编写代码、运行对比实验、捕获终端报错、自动修复代码”的自动化循环。
这对于需要进行大量定量研究和消融实验的项目非常实用。

5. PaperQA:集成至开发环境的证据检索工具
- 项目地址:
https://github.com/future-house/paper-qa - 适用场景:基于可信证据的文献综述与问答。
PaperQA 通过调用 Codex 的逻辑推理能力,直接从指定的 PDF 文件夹中提取关键信息。
其核心在于“基于证据的问答”。
当你在编写数据处理代码或推导数学公式时,它能自动检索关联文献并标注引用来源,减少了在论文阅读器与代码编辑器之间切换的频率。
二、 模型服务与 API 配置指南
为了让上述插件正常工作,我们需要为 Codex 配置稳定的模型服务接口。
在本地开发环境配置中,除了常规的账户登录方式外,使用 OpenAI 兼容接口(OpenAI Compatible API)是更具灵活性和定制空间的方案。
本文使用 iThinkAPI 作为演示环境。
在实际配置时,你需要重点关注 API Key、Base URL 以及对应的模型名称。
请将以下配置信息写入你的环境变量或插件配置文件中:
Base URL:https://token.ithinkai.cn/v1
API Key:YOUR_API_KEY
Model:以服务文档为准,最新模型 gpt-5.5、claude-opus-4-8、
gpt-image-2 等可按文档查看;涉及图片生成时,以 0.05¥/图起、2k/4k 支持等服务文档说明为准。
为了确保接口顺利接通,请按照以下两个步骤完成模型挑选与令牌创建:
第二步:挑选模型与确定分组
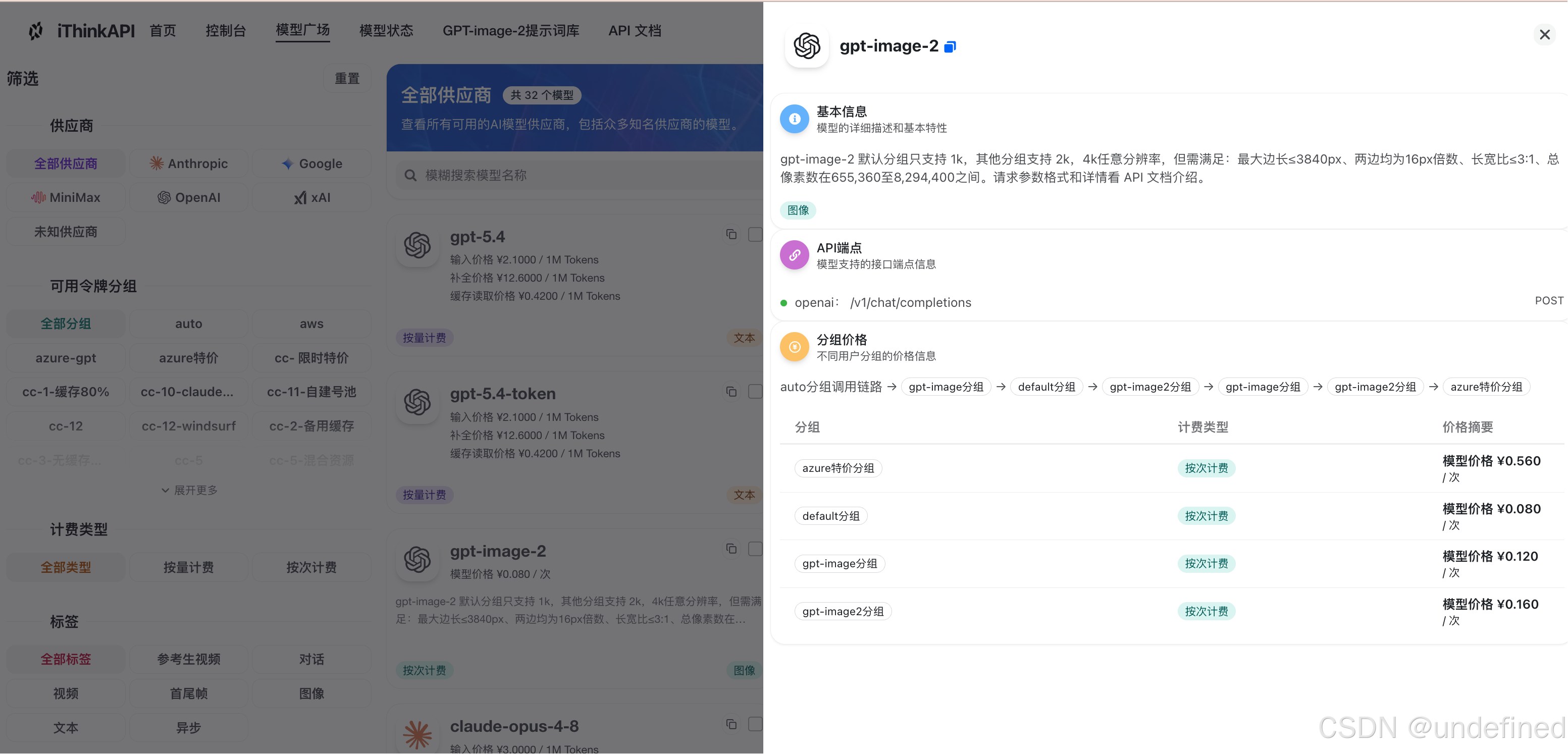
进入模型服务管理平台的“模型广场”,在搜索栏中输入 gpt、claude 或 image 等关键词,筛选出适合你科研任务的目标模型。
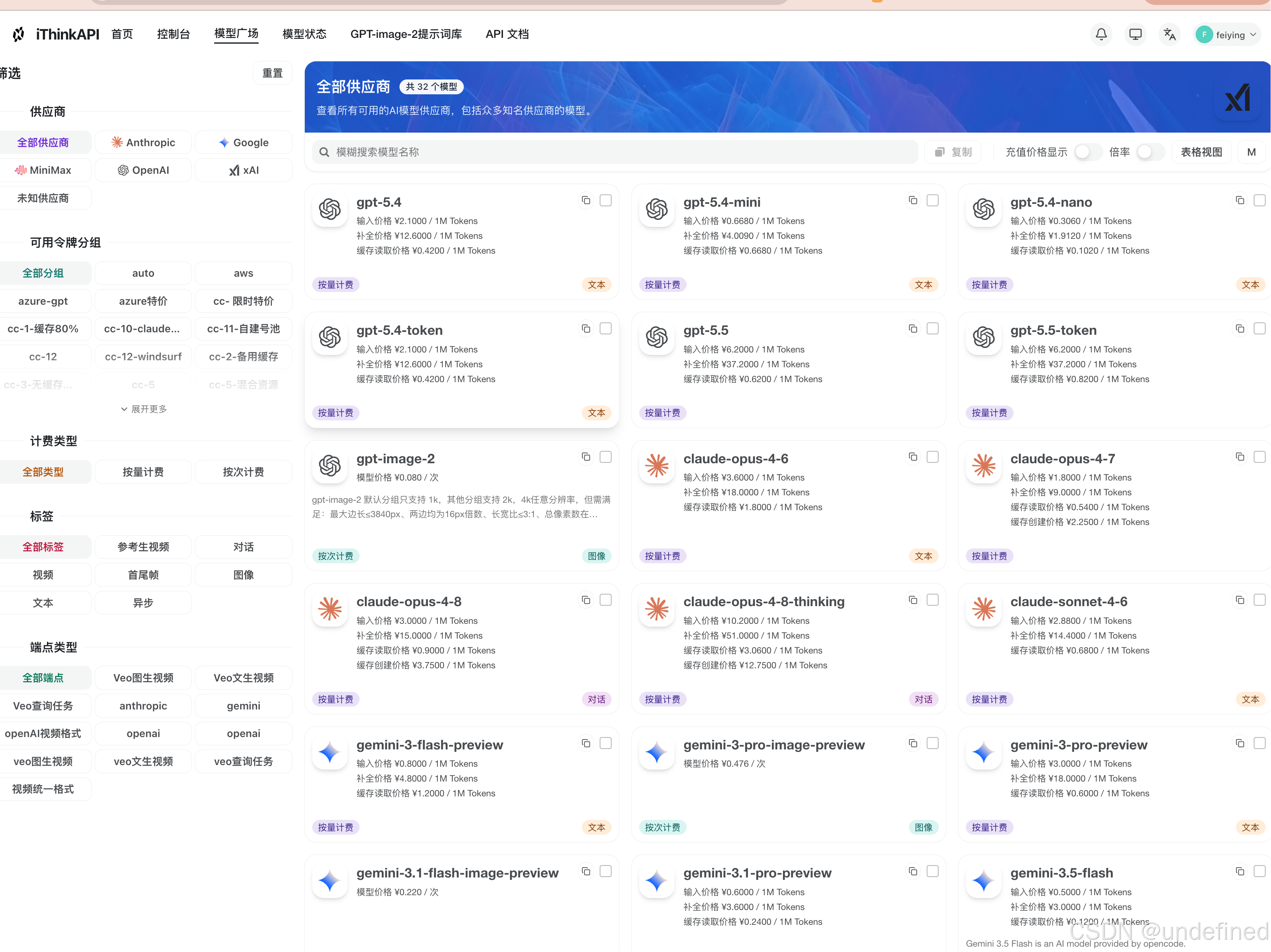
确认该模型所属的分组或线路。
需要注意的是,同一模型在不同的分组下,其调用延迟、额度消耗和可用状态可能会有所差异,具体细节请以服务文档和实时状态为准。
第三步:创建 API 令牌
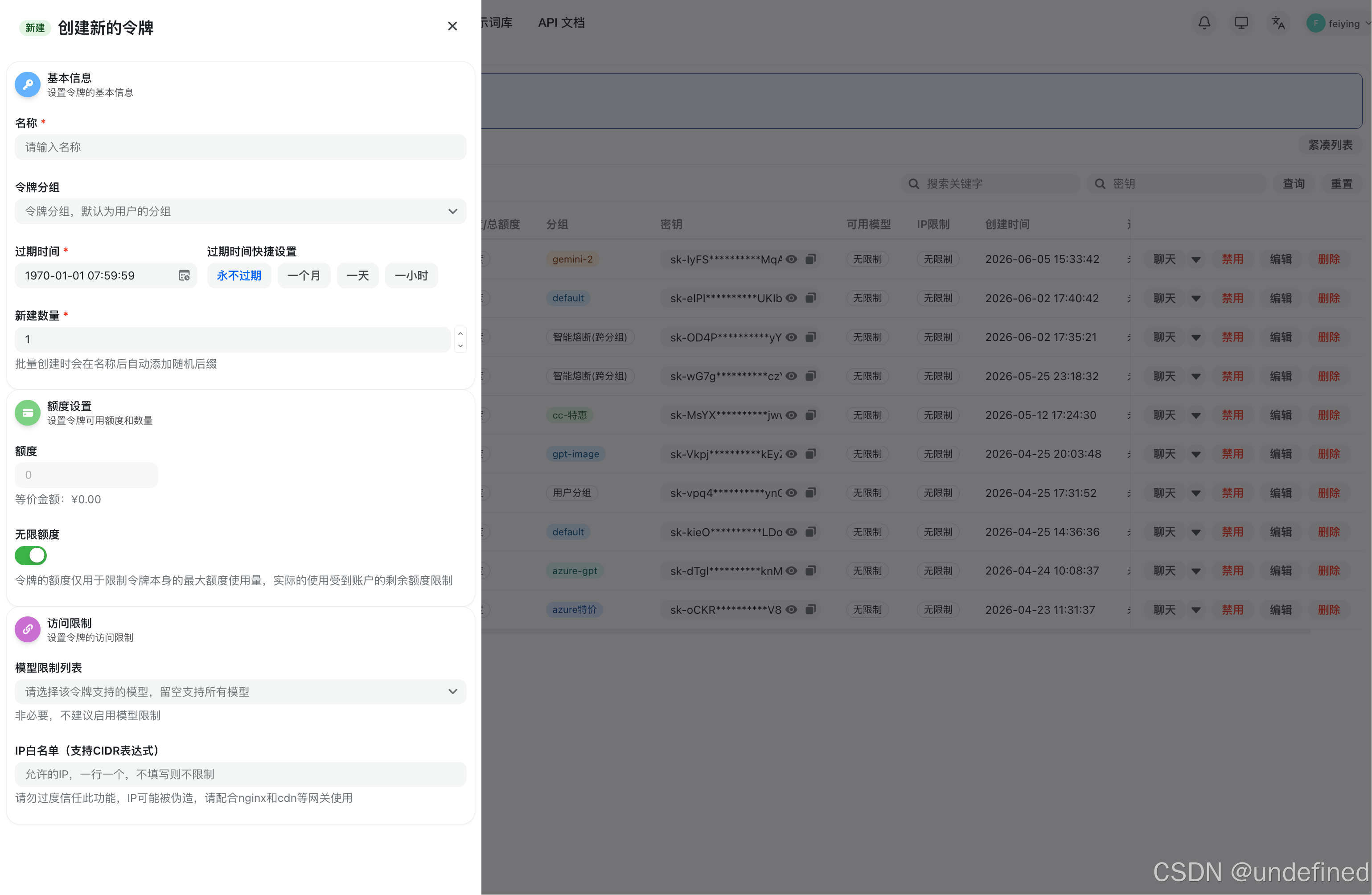
登录控制台,进入“令牌管理”页面,点击“添加令牌”按钮。
在配置项中,绑定你在上一步选中的模型分组。如果暂时不确定具体的模型限制,可以先保持默认留空。
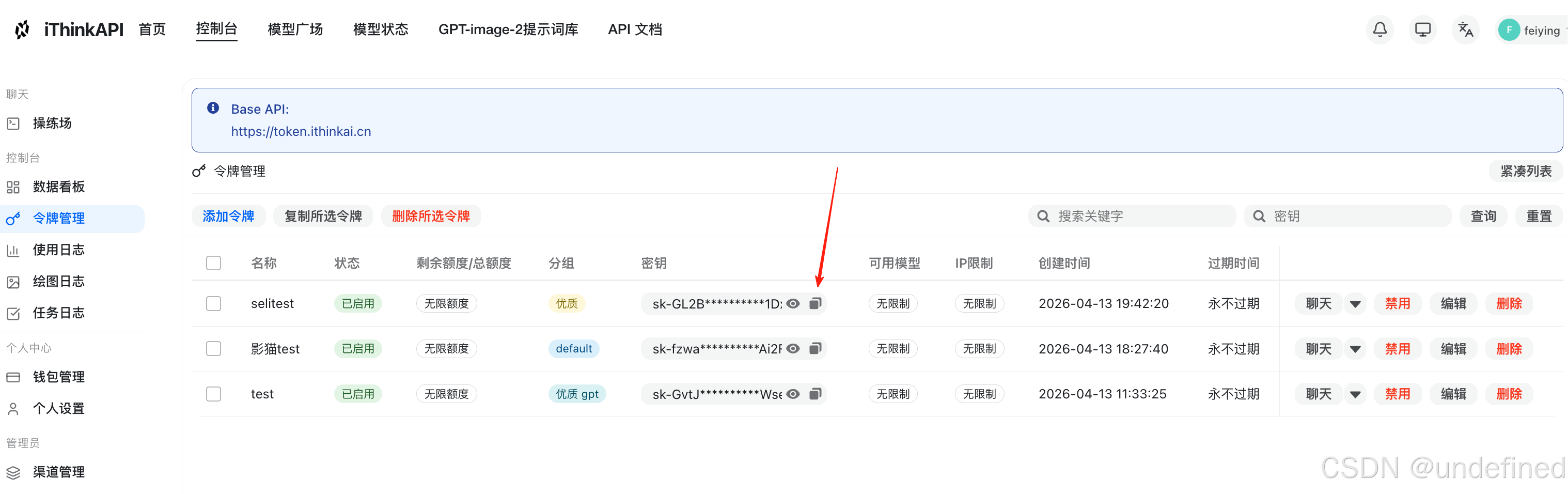
创建完成后,复制生成的 API Key,并将其填入 Codex 或 VS Code 的配置文件中,完成接入稳定性测试。
三、 在 Codex CLI 中部署科研工作流
完成 API 配置后,我们开始在 Codex 命令行中部署这些科研插件。
1. 进入插件中心
打开终端,启动 Codex 命令行工具,并输入以下指令:
/plugins这会调出 Codex 的 CLI 插件目录,你可以在这里管理官方插件和第三方组件。
2. 安装 Claude Scholar 插件
在命令行中输入以下指令,从 Marketplace 拉取并安装插件:
codex plugin marketplace add Galaxy-Dawn/claude-scholar
codex plugin install claude-scholar(注意:安装 OneSkills 的步骤相同,只需将仓库源替换为 onescience-ai/oneskills 即可。)
3. 连接本地 Zotero 文献库
为了让 Codex 能够读取你电脑中的文献,请执行以下操作:
- 确保 Zotero 客户端已在后台运行。
- 在 Codex 的
/plugins界面中搜索zotero-mcp并点击安装。 - 首次调用时,Codex 会弹窗请求本地文件夹的读取权限,点击“允许”即可。
4. 运行测试指令
尝试在项目终端中输入以下指令,验证工作流是否跑通:
@arxiv-metadata 帮我检索 5 篇近期关于 Agent Reasoning 的会议论文,并结合我本地 Zotero 中的相关文献,对比它们在方法论上的异同,最后在当前目录下生成一份 Markdown 格式的对比报告。---
四、 在 VS Code IDE 环境中进行集成
如果你更习惯在 VS Code 中进行开发,可以按照以下步骤完成环境对齐。
1. 准备 Python 虚拟环境
确保本地已安装 Python 3.10 或更高版本。建议在项目根目录下创建独立的虚拟环境:
# 创建虚拟环境
python -m venv research_env
# 激活虚拟环境 (Linux/macOS)
source research_env/bin/activate
# 激活虚拟环境 (Windows)
research_env\Scripts\activate2. 配置环境变量
在系统或当前终端中配置你的 API 密钥和自定义 Base URL:
# Linux/macOS
export OPENAI_API_KEY="你的_API_KEY"
export OPENAI_API_BASE="https://token.ithinkai.cn/v1"
# Windows (Command Prompt)
set OPENAI_API_KEY=你的_API_KEY
set OPENAI_API_BASE=https://token.ithinkai.cn/v13. 插件安装与初始化
- 打开 VS Code 的 Extensions(插件)侧边栏,搜索并安装
Claude Scholar或OneSkills对应的扩展。 - 若使用
Zotero-MCP,需要按下Ctrl+Shift+P(macOS 上为Cmd+Shift+P)打开指令面板,搜索并打开settings.json。 - 在配置文件中添加 Zotero 的数据存放路径:
{
"research.zotero.path": "/Users/yourname/Zotero",
"research.auto_save_log": true
}开启 "research.auto_save_log": true 可以确保 AI 辅助生成的代码修改和实验记录都有迹可循,防止在进行大规模实验时因意外中断而丢失数据。
---
五、 常见报错与排查方法
在配置和使用过程中,你可能会遇到以下问题,可以参考对应的排查思路进行解决:
1. MCP 协议连接超时 (Connection Timeout)
1. 检查 Zotero 是否正常运行,且其 HTTP 服务端口(默认通常为 23119)未被其他软件占用。 2. 检查系统设置中的“安全性与隐私”,确保终端或 VS Code 拥有目标文件夹的读取权限。
- 原因分析:通常是由于本地端口冲突,或者系统安全策略阻止了 Codex 读取本地文件夹。
- 排查步骤:
2. 接口鉴权失败 (401 Unauthorized / Invalid API Key)
1. 在终端中运行 echo $OPENAI_API_KEY,确认变量已正确输出。 2. 检查 Base URL 后方是否多写或漏写了 /v1。部分插件会自动拼接路径,请根据插件文档的要求进行微调。
- 原因分析:API Key 填写错误,或者环境变量未生效。
- 排查步骤:
3. Python 虚拟环境路径不匹配
1. 在 VS Code 中按下 Ctrl+Shift+P,输入 Python: Select Interpreter。 2. 手动选择当前项目目录下的 research_env/bin/python。
- 原因分析:VS Code 默认的解释器未指向你创建的
research_env。 - 排查步骤:
---
六、 科研场景下的使用建议
- Token 消耗分析:在进行大规模文献检索或自动代码迭代时,上下文的累积会导致 Token 消耗增加。建议在实验前合理设置最大上下文长度(Max Tokens),并定期在控制台查看 Token 消耗分析,做好调用成本管理。
- 数据隐私边界:如果你的研究涉及未发表的专利代码或敏感的涉密数据,建议在本地配置文件中设置过滤规则,避免将核心隐私数据上传至云端模型进行处理。
- 双重验证原则:虽然 Codex 能够辅助验证数学推导和编写实验代码,但对于其生成的公式和关键算法,研究者仍需进行人工复核,确保学术严谨性。

欢迎加入 MCP 技术社区!与志同道合者携手前行,一同解锁 MCP 技术的无限可能!
更多推荐
 6
6 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)