用 /triage 驯服「地狱级」待办:AI 智能体时代的 Backlog 管理范式
文章目录
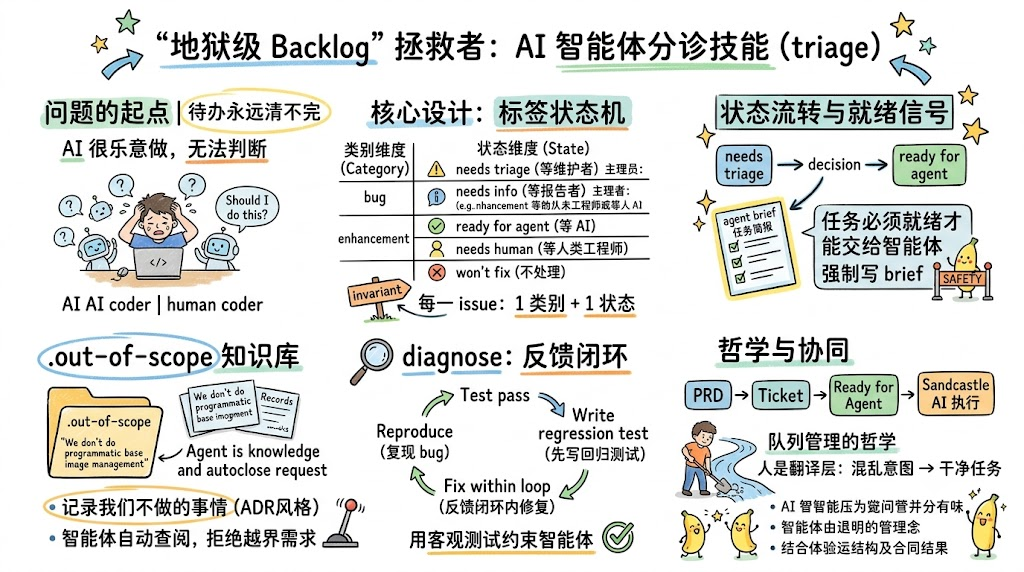
在软件团队里,真正拖垮节奏的往往不是写代码本身,而是那条永远清不完的待办队列。Issue 越积越多,分不清哪些是真 Bug、哪些是脑暴、哪些早就该关掉。当你引入 AI 智能体来分担工作量之后,这个问题非但没有消失,反而被放大了——智能体很乐意去做事,但它无法替你判断「这件事到底该不该做、现在能不能做」。
开源作者 Matt Pocock 把这套困境称作「地狱级 Backlog」,并给出了一个相当工程化的解法:一个叫 triage 的技能(skill)。它的核心思想不复杂,却切中要害——把待办的生命周期编码成一台状态机,用标签(label)作为状态的物理载体,让人与 AI 在同一套规则下协作。本文将完整拆解这套方法论:它解决了什么问题、状态机如何设计、智能体如何接管队列,以及你该如何在自己的仓库里复刻它。
一、问题的起点:单兵作战的工具,撑不起团队
大多数围绕 AI 智能体搭建的「skill 体系」都有一个隐含前提:你是个独立开发者,所有想法都从你脑子里来,你天然知道每件事的上下文和优先级。在这种场景下,skill 工作得很好——你说一句话,智能体就去执行,因为「该不该做」这个判断已经在你脑中完成了。
但团队场景会彻底打破这个前提。一旦你开始处理别人的想法、为别人构建功能、或者维护一个有外部贡献者的开源项目,事情就变了:
- 别人提的 issue,到底是不是个好主意?值不值得做?
- 这是一份 Bug 报告吗?如果是,需不需要先复现?
- 这条需求是不是早就被否决过,只是提的人不知道?
- 哪些 issue 已经「足够清晰」,可以直接丢给智能体去实现?
这些判断本质上是一道翻译工序:把人类随手抛出的、模糊的、半成品的想法,翻译成结构清晰、边界明确、可被执行的任务。任何维护过一定规模项目的人都对这道工序无比熟悉,它也正是传统意义上「triage(分诊)」的含义。问题在于,当执行端从人换成 AI 智能体之后,这道翻译工序的重要性陡然上升——因为智能体不会像人那样在动手前自觉地停下来质疑任务本身。
管理 AFK(Away From Keyboard,即「离开键盘」的全自动)智能体,本质上是一门队列管理的学问。你真正在做的,是修剪一条队列,并充当人类与 AI 之间的翻译层。
triage 技能就是为这道工序而生的。
二、核心设计:把状态机编码进标签
triage 最聪明的地方,是它没有发明一套复杂的外部系统,而是直接复用了 GitHub Issue 自带的 label 机制,把一台状态机「物理地」编码进标签里。
整套标签被拆成两个正交的维度。
2.1 类别角色(Category Roles)
类别描述这条 issue「是什么」。当前只有两个,且对任何做过 triage 的人都不陌生:
- bug:缺陷报告
- enhancement:功能增强 / 新特性
这一维度刻意保持简单。它回答的是「这属于哪一类工作」,而把「现在处于什么进度」交给另一个维度。
2.2 状态角色(State Roles)
状态描述这条 issue「现在在哪一步」。它一共有五个取值,每一个都对应工作流中的一个明确节点:
| 状态 | 含义 | 谁在等待 |
|---|---|---|
| needs triage | 需要维护者看一眼,做初步判断 | 等维护者 |
| needs info | 信息不足,需要回去找报告者补充 | 等报告者 |
| ready for agent | 已完整定义,可交给全自动智能体接手 | 等 AI 智能体 |
| needs human | 需要人类亲自来实现 | 等人类工程师 |
| won’t fix | 不予处理,明确拒绝 | 终态,无人等待 |
这五个状态目前是「可商榷」的——作者也坦言未来很可能会扩展,但就当下而言已经足够好用。它们的价值在于:每一个状态都精确回答了「这件事现在卡在谁手上」,让队列的流动变得一目了然。
2.3 关键不变量:一类别 + 一状态
之所以说这是一台状态机而非简单的标签堆叠,是因为它带着一条铁律:
每一条被分诊过的 issue,必须恰好携带一个类别角色和一个状态角色。
换句话说,一条 issue 不可能同时是「ready for human」又是「needs triage」——这在逻辑上是矛盾的。这条不变量(invariant)正是状态机的灵魂:它保证了任意时刻,队列中每条任务的位置都是确定且唯一的,不存在模棱两可的中间态。
对于偏爱用状态机来约束系统行为的工程师来说,这种设计带来的好处是实打实的:你永远可以用一句简单的查询,把队列切成几个互不重叠的桶,分别交给维护者、报告者、AI 或人类工程师去处理。确定性,是把队列交给自动化的前提。
三、工作流:从混乱想法到可执行任务
有了这套标签状态机,triage 的实际用法就变得相当灵活。它至少支持三种粒度:
- 分诊单条 issue:针对某一条具体 issue,判断它的类别与状态。
- 扫描整个 Backlog:一句「把所有需要我现在关注的东西列出来」,就能把队列里真正需要决策的部分捞出来。
- 推进状态流转:比如把某条 issue 从 needs triage 推到 ready for agent。
这里有一个值得玩味的细节:把一条 issue 标记为 ready for agent 并不是一个轻量动作。因为要让它「准备好交给智能体」,你必须为接手它的智能体写一份「任务简报(agent brief)」。triage 内置了一个 agent brief 模板,引导你把这条 ticket 写得足够完整、足够清晰。
这个设计的精妙之处在于:它把「写清楚需求」这件事,变成了状态流转的强制前置条件。你不可能在没想清楚的情况下,随手把一坨模糊需求丢给智能体——状态机的规则逼着你先完成翻译工序。这也正是 AFK 智能体能可靠工作的根基:智能体只挑选那些被明确标记为 ready for agent 的任务,从而不会在那些尚未就绪的「半成品」任务上瞎折腾、浪费上下文。
四、.out-of-scope:让智能体学会「自动说不」
分诊里最耗心力的一类决策,是「拒绝」。总有一些 enhancement 听起来合理,但你早就想清楚了它不符合项目方向。如果每来一条都要你重新解释一遍为什么不做,那 triage 永远快不起来。
triage 的解法是在仓库顶层维护一个 .out-of-scope 目录。每当你决定「这个我们不做」,就在这里留下一条记录。它的形态非常接近架构决策记录(ADR,Architecture Decision Record),只不过专门用来记录那些我们明确不会实现的特性。
举一个具体例子:Sandcastle(作者的项目)在这里写明——「Sandcastle 不提供用于组合 Dockerfile 或以编程方式管理基础镜像的抽象层」。
这条记录的威力在于:当智能体在分诊一条 enhancement 时,它会去翻这些 out-of-scope 记录。一旦发现新提的需求正好命中某条「我们不做」的决策,它就能直接关闭这条 issue,根本不需要打扰你。
本质上,.out-of-scope 把你过去做过的判断沉淀成了智能体可读的知识。你只需要把「不做」的理由写一次,之后所有撞上同一面墙的需求,都会被自动挡掉。这是一种典型的「用文档换决策带宽」的杠杆。
五、实战拆解:在真实仓库里跑一遍
光讲规则太抽象,下面用作者在 Sandcastle 仓库里的真实演示,把整条链路走一遍。
5.1 起手:批量初筛
打开仓库时,issue 列表是一片混沌:有些已经 ready for agent 并进了 PR,有些 needs triage 等着复看,有些完全没打标签,还有些标着 won’t fix。
第一步,在仓库里开一个新的 Claude 会话,敲下 triage,并补一句:「只给我那些我还没分诊过的 open issue。」智能体随即开始探索仓库,识别出项目使用 GitHub Issues,并很快报告:有 9 条未分诊的 open issue。
接着是一句很自然的指令:「能不能逐条过一遍,给它们都打上基础标签?做个初筛就好,让我少做点决策。」智能体便逐条扫过,把它们分别标成 bug 或 enhancement,并统一标上 needs triage。
这一步的意义在于:初筛是最廉价、也最适合交给 AI 的环节。它不需要深度判断,只需要把混沌的列表整理成结构化的、带标签的队列,为后续的精细决策铺好路。
5.2 深入:从分诊到诊断
初筛完成后,从 bug 开始处理通常更容易上手。作者挑了编号 477 这条:「先从 477 开始。」
智能体返回的建议是:确认为 bug,且推荐直接推到 ready for agent——理由是这条 issue 已经有相当充分的分诊笔记,定位到了确切的根因,还附带了可复现的堆栈跟踪。
但这里出现了一个值得所有人警惕的瞬间:智能体对报告者提供的信息「太轻信」了。报告写得头头是道,不代表结论就是对的。于是作者没有照单全收,而是调用了另一个技能——diagnose(诊断),要求智能体「自己动手复现并尝试修复」,而不是直接采信别人给的诊断。
5.3 diagnose:先写回归测试,再修
diagnose 技能的内部逻辑,与作者的 TDD(测试驱动开发)技能一脉相承,走的是一条严格的反馈闭环:
- 先复现:智能体在同一个会话里动手复现这个 bug。很快它确认了根因——某几个变量里包含了字面量形式的 task ID,这种特定写法如果用户没有传入对应值,就会直接报错。修复方向是把这些写法换成不会触发错误的占位符模式。
- 先写回归测试,再修复:在动手改代码之前,智能体先搭好一个单元测试脚手架,断言「最终生成的
prompt.md中不再包含任何未解析的 task ID」。这就是 TDD 的精髓——先用一个失败的测试把 bug 钉死,再在这个反馈闭环里把它修绿。 - 在闭环内完成修复:测试、类型检查一路跑通,修复水到渠成。
这套流程的价值远不止「修好了一个 bug」。它把「智能体容易轻信、容易跑偏」这个固有风险,用一个可执行的、客观的反馈信号(测试是否通过)锁死了。智能体可以自主推进,但它的每一步都必须经得起测试的检验。
5.4 收尾:推主干、关 issue
修复完成后,智能体加上了 changeset 和补丁。收尾有两条路:
- 直接把改动推到 main,并关闭原 issue;
- 或者创建一个 PR,让 PR 引用原 issue,这样在合并 PR 时会自动关闭对应 issue——这是更规范、也更可追溯的做法。
值得一提的是,作者透露这条 bug 的修复方案是事先经过人工核对的——演示里有一点「电影魔法」的成分。这恰恰是一种诚实且重要的态度:AI 负责把流程跑顺、把脏活干完,但关键判断仍然需要人来把关。
六、AFK 智能体与「软件工厂」:队列管理的哲学
把上面所有环节串起来,你会看到一个更大的图景。triage 真正服务的对象,是 AFK 智能体——那些你离开键盘后仍在后台自动干活的智能体。而要让这样的智能体可靠运转,前提是:必须有一条它能随时取用的、高质量的任务队列。
这正是标签状态机的终极用途。作者的 AFK 智能体软件——他称之为 Sandcastle,一个「软件工厂」式的系统——其调度逻辑(plan prompt)只做一件事:扫描带有 ready for agent 标签的 issue,并且只碰那些被明确标记过的。
这套机制带来的体验非常直观:你看着自己的 Backlog 里,一个个「ready for agent」的小标记慢慢填满,而你心里清楚,这些任务都会被自动实现。标签不再只是分类工具,它变成了人类向自动化系统下达的、可信赖的执行信号。
而专门为每个状态设计标签的意义也在此凸显:它确保智能体不会在那些尚未就绪的烂任务上瞎撞。队列里只有打了「ready for agent」的,才会进入执行通道——这是一道至关重要的安全闸门。
回到那句点睛之言:管理 AI、管理 AFK 智能体,归根结底就是队列管理。你扮演的是人类与 AI 之间的翻译层,把混乱的人类意图,修剪、打磨成一条干净、有序、可被机器消费的任务流。
七、与 PRD / Ticket 体系的协同
triage 并不是一座孤岛,它能和既有的产出物体系顺滑地咬合。
- PRD(产品需求文档):你可以在仓库里写 PRD,比如一份关于「工作树锁定(work tree locking),防止多个智能体并发访问」的 PRD,并把它标记为
ready for agent。智能体会看到它、接手它。 - 基于 PRD 的 Ticket:你还能为 PRD 派生出具体的 ticket,让 ticket 通过父子关系挂在 PRD 之下,同样标记为
ready for agent,进入智能体的执行视野。
这意味着,从高层的需求文档(PRD)→ 拆解后的具体任务(ticket)→ 标记就绪(ready for agent)→ 智能体执行,整条链路是连贯的。triage 的标签状态机,恰好是把这条链路各个环节「焊接」起来的那层胶水。
八、如何在自己的项目里复刻
如果你也想把这套范式落地,下面是一份提炼出来的实操清单:
8.1 设计你的标签状态机
- 先定义类别维度:最简可以就是
bug和enhancement两个。 - 再定义状态维度:参考
needs triage/needs info/ready for agent/needs human/won't fix五态,按团队实际情况增删。 - 守住不变量:每条分诊过的 issue 恰好一个类别 + 一个状态。这条规则是整个系统能否自动化的命门,务必在流程(甚至 CI 校验)层面强制执行。
8.2 建立 .out-of-scope 知识库
- 在仓库顶层维护一个目录,把每一个「我们不做」的决策写成 ADR 风格的记录。
- 内容要写清楚边界:哪些能力明确不在项目范围内。
- 让分诊智能体在处理 enhancement 时优先查阅它,从而自动拒绝越界需求。
8.3 沉淀 agent brief 模板
- 准备一份任务简报模板,把「交给智能体前必须写清楚的信息」结构化。
- 把「写好 brief」设为流转到
ready for agent的硬性前提,倒逼需求在进入执行队列前就被想清楚。
8.4 用反馈闭环约束智能体
- 对 bug,坚持「先复现、先写回归测试、再修复」的 TDD 式流程。
- 不要让智能体轻信报告者的诊断;用可执行的客观信号(测试通过与否)替代主观判断。
8.5 让执行端只认就绪信号
- 你的自动化调度逻辑,应当只扫描并执行带有就绪标签的任务。
- 这样即便队列里混入了未就绪的任务,也不会被误执行,安全闸门始终在线。
九、结语:协作的形态正在改变
triage 表面上是一个管理 GitHub issue 的小技能,但它背后折射的,是 AI 智能体时代软件协作形态的一次深刻转变。
过去,待办队列的两端都是人:人提需求,人来实现。现在,执行端正在被智能体接管,而人的角色被推向了更上游——做判断、定边界、写清楚、把好关。我们不再是流水线上的工人,而更像是流水线的调度员和质检员。
这套方法论里真正普适的,不是那五个标签的具体名字,而是几条底层原则:
- 用状态机给混乱的队列注入确定性;
- 用强制前置条件逼迫需求在执行前被想清楚;
- 用可沉淀的知识(out-of-scope、brief 模板)把一次性判断变成可复用的自动化资产;
- 用客观反馈闭环约束智能体的自由度,让它既能自主又不至于跑偏。
说到底,把 AI 用好的关键,从来不是让它做更多,而是先把「该做什么」想得足够清楚。当你把队列修剪干净、把规则定义明确,那些原本压得人喘不过气的「地狱级 Backlog」,才真正有机会被自动化的洪流冲刷干净。


欢迎加入 MCP 技术社区!与志同道合者携手前行,一同解锁 MCP 技术的无限可能!
更多推荐
 5
5 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)