Spring AI 上线前,先把 ChatClient 调用链看清楚
很多 Java 项目接入大模型时,第一版 Demo 跑通得很快:引入 Spring AI,注入 ChatClient.Builder,写一个 Controller,问题就能返回答案。
但真正上线时,问题会变得很具体:一次调用慢在模型、Advisor、工具调用,还是网络?一次用户提问消耗了多少 token?RAG、Memory、Tool Calling 加进去之后,怎么知道是哪一段拖慢了响应?
Spring AI 的价值不只是把大模型 API 封装成 Java 风格调用,更重要的是把 AI 调用纳入 Spring 工程体系。对后端项目来说,这意味着:AI 调用也应该像 HTTP、Redis、MySQL 一样可观测。
不要只看“接口成功率”
传统接口上线,我们至少会关心 QPS、耗时、错误率、日志和链路追踪。AI 接口也一样,只是多了几个新指标:
| 关注点 | 普通后端接口 | AI 调用 |
|---|---|---|
| 耗时 | Controller、DB、RPC | ChatClient、ChatModel、Advisor、Tool |
| 成本 | 机器、带宽、存储 | input token、output token、模型单价 |
| 错误 | 4xx、5xx、超时 | 模型限流、上下文过长、工具调用失败 |
| 安全 | 参数、权限、脱敏 | prompt、completion、tool 参数、检索结果 |
| 排查 | traceId 串联调用链 | traceId 串联业务请求和模型调用 |
Spring AI 官方文档中,Observability 已经覆盖 ChatClient、Advisor、ChatModel、EmbeddingModel、ImageModel 和 VectorStore。这件事很关键:你不用从零开始埋点,只要把 Micrometer、Actuator、Tracing 接好,就能看到不少 AI 相关指标。
最小接入:别绕过自动配置
Spring AI 文档里有一个容易被忽略的提醒:如果你在多模型场景里直接用 ChatClient.create(chatModel) 或 ChatClient.builder(chatModel),可能会绕过自动配置的 ChatClient.Builder,导致 observability 和自定义器没有生效。
所以普通 Spring Boot 项目里,优先注入自动配置的 ChatClient.Builder:
@Service
public class AiReplyService {
private final ChatClient chatClient;
public AiReplyService(ChatClient.Builder builder) {
this.chatClient = builder
.defaultSystem("你是一个严谨的 Java 后端技术助手,回答要简洁、可验证。")
.build();
}
public String reply(String question) {
return chatClient.prompt()
.user(question)
.call()
.content();
}
}这段代码看起来普通,但它保留了 Spring Boot 自动配置带来的能力:统一配置、统一观测、统一扩展。很多“为什么本地有指标,线上某个 ChatClient 没指标”的问题,最后都和自己手动 new / create 客户端有关。
依赖可以从这个最小组合开始:
<dependencies>
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-starter-model-openai</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-actuator</artifactId>
</dependency>
<dependency>
<groupId>io.micrometer</groupId>
<artifactId>micrometer-registry-prometheus</artifactId>
</dependency>
</dependencies>如果项目还要接分布式链路追踪,再按当前 Spring Boot 版本选择 OpenTelemetry 或 Zipkin 相关依赖。具体依赖名在 Spring Boot 3.x、4.x 之间可能有差异,实际项目应以官方文档为准。
配置里先做两件事
第一件事是打开 Actuator 的指标暴露:
spring:
ai:
openai:
api-key: ${OPENAI_API_KEY}
chat:
model: gpt-5-mini
temperature: 0.2
management:
endpoints:
web:
exposure:
include: health,info,metrics,prometheus
endpoint:
health:
show-details: when_authorized第二件事是控制 prompt 和 completion 日志。
Spring AI 支持记录 prompt、completion、tool 参数、vector store 返回内容等信息,但官方默认不导出这些内容,原因很现实:它们可能包含用户隐私、业务数据、内部知识库片段、工具调用参数。
开发环境可以短时间打开:
spring:
ai:
chat:
client:
observations:
log-prompt: true
log-completion: true生产环境不建议这样做。更合理的方式是只记录 traceId、conversationId、模型名、token、耗时、错误类型,以及脱敏后的业务 requestId。真正需要回放问题时,再通过受控开关、短时间窗口和审计流程处理。
一次调用应该能被拆开看
一个带 Advisor 和 Tool Calling 的 AI 请求,链路大概是这样:
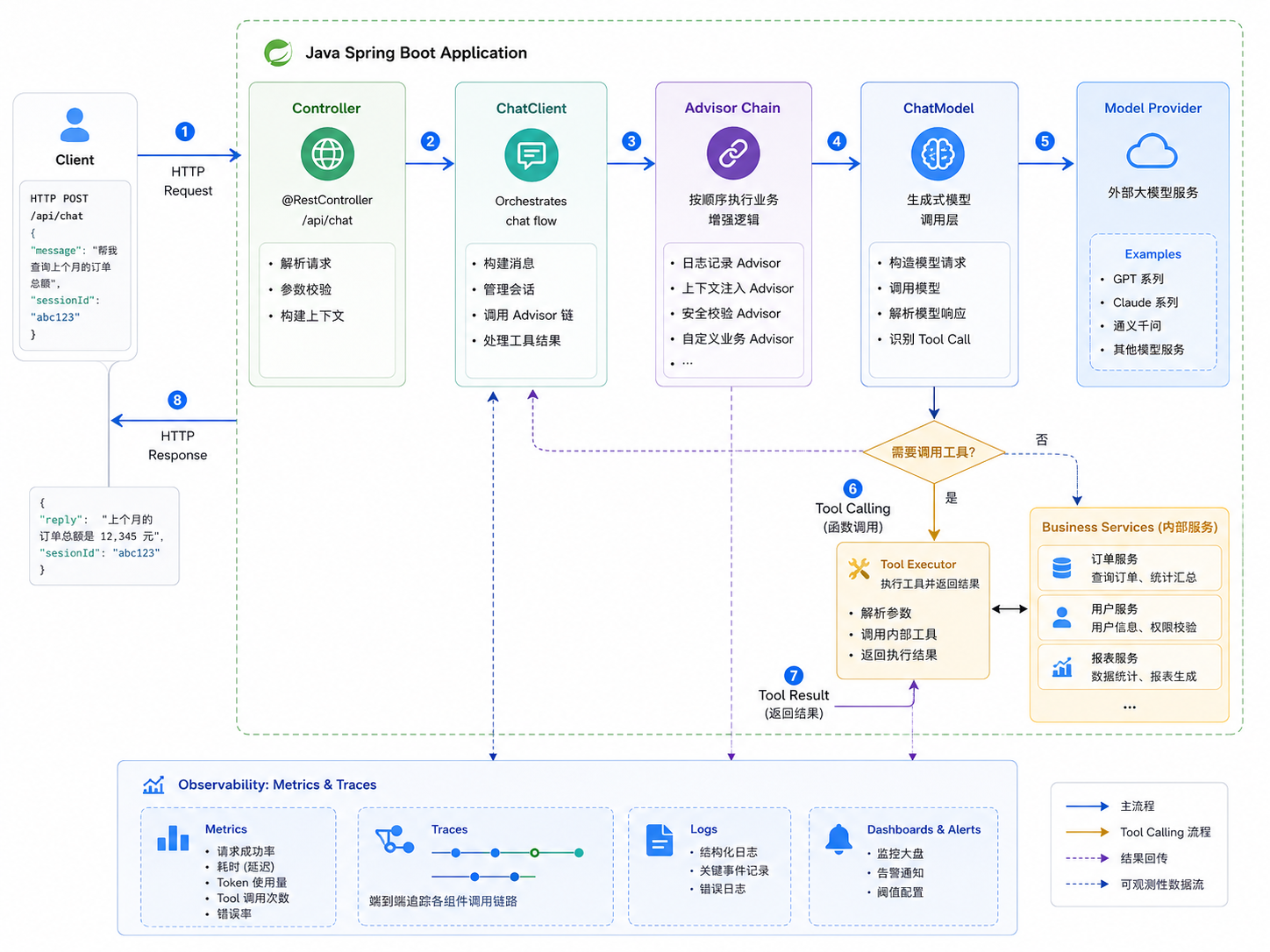
排查时不要只盯着最终响应时间。假设一次 /ai/ask 请求耗时 8 秒,至少要拆成几段:
- HTTP 接口本身耗时多少;
- ChatClient 调用耗时多少;
- Advisor 链里是否有 Memory、RAG、日志 Advisor;
- ChatModel 调用模型耗时多少;
- Tool Calling 是否访问了内部服务;
- input token 和 output token 是否异常;
- 是否发生重试、限流或超时。
Spring AI 的观测数据里,ChatClient 会记录 call() 或 stream() 调用耗时;ChatModel 会记录模型调用相关 observation;token 使用量可以通过 gen_ai.client.token.usage 观察;Tool Calling 也有独立 observation。
这就给 Java 后端一个很熟悉的排查方式:不要问“模型怎么这么慢”,而是先把链路拆开,看慢在哪一段。
我会优先盯这 5 个指标
第一,ChatClient 平均耗时和最大耗时。
这代表业务层感知到的一次 AI 调用耗时。如果它高,但模型层不高,可能是 Advisor、工具调用或本地处理拖慢。
第二,ChatModel 调用耗时。
这更接近模型供应商、网关或推理服务本身的耗时。同步调用和流式调用在观测上可能存在差异,尤其流式链路要结合前端首 token 时间一起看。
第三,token 使用量。
token 不是账单里的抽象数字,它会直接影响成本、延迟和上下文失败概率。提示词模板、历史对话、RAG 文档塞得太多,都会反映在 input token 上。
第四,Advisor 耗时。
如果用了 Memory、RAG、日志、重写类 Advisor,Advisor 链路会越来越长。一个常见坑是把太多“智能逻辑”塞进 Advisor,最后排查时不知道答案到底被谁改过。
第五,Tool Calling 耗时和失败率。
模型调用工具之后,真正慢的可能是内部 HTTP、数据库、权限系统。工具不是魔法,本质上还是后端调用链的一部分。
给上线前的一张检查清单
上线 Spring AI 功能前,我建议至少做这几件事:
- 是否使用自动配置的 ChatClient.Builder;
- 是否能在 /actuator/prometheus 或监控系统里看到 AI 相关指标;
- 是否能用 traceId 串起 Controller、ChatClient、ChatModel、Tool;
- 是否记录模型名、业务场景、调用结果状态;
- 是否能统计 input token、output token 和总 token;
- 是否关闭生产环境 prompt、completion、tool 参数明文日志;
- 是否给模型调用设置超时、重试和降级策略;
- 是否能区分模型失败、工具失败、检索失败和业务校验失败。
这些不是“高级工程化”,而是 AI 应用变成线上服务后的基本要求。Spring AI 已经把一部分基础设施接到了 Spring 生态里,剩下的工作是把这些信号接进你的监控、告警和排查流程。
AI 功能最怕的是“看起来能用,但出了问题没人知道慢在哪、贵在哪、错在哪”。对 Java 后端来说,Spring AI 的正确打开方式不是先堆 Agent、RAG、MCP,而是先把一次 ChatClient 调用当成正式生产链路来治理。

欢迎加入 MCP 技术社区!与志同道合者携手前行,一同解锁 MCP 技术的无限可能!
更多推荐

 3
3 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)