RAG工程化实践方法论 - 从零实现一个基础RAG
一、简介
我们知道,大语言模型普遍存在知识滞后性、知识缺失以及幻觉等局限性。为缓解这些问题,检索增强生成(Retrieval-Augmented Generation, RAG)作为一种被广泛采用的应用架构,展现出独特的价值。可以说,在需要借助大模型回答特定私有领域知识,且知识库规模较大的场景下,除对大模型进行微调外,RAG 是一种极为有效的解决方案。
实现 RAG 的方式多种多样,既可以直接使用如 RAGFlow、Dify、FastGPT 等现成平台,也可以基于 LangFlow、LlamaIndex、LangChain、LazyLLM 等开发框架进行构建。
为便于理解其核心原理,本文将借助代码实现一个基础的 RAG 示例。
二、RAG基础实现
这里通过代码实现一个最简版的RAG系统。我们将使用医疗问答数据集,基于通义千问的Embedding模型和DeepSeek大模型。
2.1 数据准备
首先从HuggingFace下载医疗问答数据集:
https://huggingface.co/datasets/FreedomIntelligence/medical-o1-reasoning-SFT
其内容如下:

数据集包含医疗问题和专业回答,我们将使用前100条作为知识库。
2.2 代码实现
为了安全,把API的密钥放在 .env 文件中,避免泄漏。完整代码如下:
from dotenv import load_dotenv
load_dotenv()
from openai import OpenAI
import chromadb
from chromadb.config import Settings
import os
import json
import pickle
import hashlib
client = OpenAI(api_key=os.getenv("DASHSCOPE_API_KEY"), base_url="https://dashscope.aliyuncs.com/compatible-mode/v1")
with open('medical_o1_sft_Chinese.json', 'r', encoding='utf-8') as f:
cont = f.read()
data = json.loads(cont)
questions = [entry['Question'] for entry in data[0:100]]
outputs = [entry['Response'] for entry in data[0:100]]
def get_completion_deepseek(user_input, model="deepseek-chat"):
print(user_input)
messages = [{"role": "user", "content": user_input}]
deepseek_api_key = os.getenv("DEEPSEEK_API_KEY")
client = OpenAI(api_key=deepseek_api_key, base_url="https://api.deepseek.com")
response = client.chat.completions.create(
model=model,
messages=messages,
temperature=0, # 模型输出的随机性,0 表示随机性最小
)
return response.choices[0].message.content
def get_embeddings(texts, model="text-embedding-v3", batch_size=10, cache_dir="embedding_cache"):
'''封装Embedding模型接口,支持批处理和缓存'''
# 创建缓存目录
os.makedirs(cache_dir, exist_ok=True)
# 对输入文本生成唯一标识
text_hash = hashlib.md5(str(texts).encode()).hexdigest()
cache_file = os.path.join(cache_dir, f"{text_hash}_{model}.pkl")
# 检查缓存是否存在
if os.path.exists(cache_file):
print(f"Loading embeddings from cache: {cache_file}")
with open(cache_file, 'rb') as f:
return pickle.load(f)
all_embeddings = []
# 分批处理文本
for i in range(0, len(texts), batch_size):
batch_texts = texts[i:i + batch_size]
try:
# 单个查询时才打印进度
if len(texts) <= batch_size:
print(f"Processed batch {i // batch_size + 1}/{(len(texts) - 1) // batch_size + 1}")
data = client.embeddings.create(input=batch_texts, model=model).data
batch_embeddings = [x.embedding for x in data]
all_embeddings.extend(batch_embeddings)
except Exception as e:
print(f"Error processing batch {i // batch_size + 1}: {e}")
# 如果出错,可以选择重试或跳过
# 这里简单地为失败的批次添加空向量
all_embeddings.extend([[] for _ in range(len(batch_texts))])
# 向量化后的数据保存到缓存
with open(cache_file, 'wb') as f:
pickle.dump(all_embeddings, f)
return all_embeddings
class MyVectorDBConnector:
def __init__(self, collection_name, embedding_fn, persist_directory="chroma_db", cache_dir="query_cache"):
# 使用持久化存储
self.persist_directory = persist_directory
self.cache_dir = cache_dir
# 确保缓存目录存在
os.makedirs(cache_dir, exist_ok=True)
os.makedirs(persist_directory, exist_ok=True)
# 修改设置,禁止重置数据库
chroma_client = chromadb.Client(Settings(
persist_directory=persist_directory,
allow_reset=False# 修改为False,防止重置数据库
))
# 创建一个 collection
self.collection = chroma_client.get_or_create_collection(name=collection_name)
self.embedding_fn = embedding_fn
def add_documents(self, question, outputs):
'''向 collection 中添加文档与向量,如果已经处理过则跳过'''
# 确保持久化目录存在
os.makedirs(self.persist_directory, exist_ok=True)
print(f"Getting embeddings for {len(question)} documents...")
embeddings = self.embedding_fn(question)
print("Adding documents to collection...")
self.collection.add(
embeddings=embeddings, # 每个文档的向量
documents=outputs, # 文档的原文
ids=[f"id{i}"for i in range(len(outputs))] # 每个文档的 id
)
print(f"Added {self.collection.count()} documents to collection.")
def search(self, query, top_n):
'''检索向量数据库'''
# 为查询生成唯一标识
query_hash = hashlib.md5(f"{query}_{top_n}".encode()).hexdigest()
cache_file = os.path.join(self.cache_dir, f"{query_hash}.pkl")
# 检查缓存是否存在
if os.path.exists(cache_file):
print(f"Using cached results for query: {query}")
with open(cache_file, 'rb') as f:
return pickle.load(f)
# 处理查询嵌入
print(f"Processing query: {query}")
query_embeddings = self.embedding_fn([query])
results = self.collection.query(
query_embeddings=query_embeddings,
n_results=top_n
)
# 缓存结果
with open(cache_file, 'wb') as f:
pickle.dump(results, f)
return results
# 创建一个向量数据库对象
vector_db = MyVectorDBConnector("demo", get_embeddings)
# 向向量数据库中添加文档
vector_db.add_documents(questions, outputs)
class RAG_Demo:
def __init__(self, vector_db, llm_api, n_results=2):
self.vector_db = vector_db
self.llm_api = llm_api
self.n_results = n_results
def chat(self, user_query):
# 1. 检索
search_results = self.vector_db.search(user_query, self.n_results)
search_results = "".join(search_results['documents'][0])
# print(search_results)
prompt_template = f"""
你是一个专业的医疗问答助手。
你的任务是基于以下提供的已知信息(可能包含医学文献、临床指南或知识库内容)来回答用户的问题。
请严格遵守以下原则:
1. 完全依据信息:你的回答必须严格基于已知信息,不得自行编造或添加任何未经证实的内容。
2. 拒绝回答:如果已知信息不足以回答用户的问题,或者问题与已知信息无关,请直接回复:"我无法回答您的问题"。
3. 专业语气:请使用专业、严谨的医学术语,但表达方式要清晰易懂。
=======================
已知信息:
{search_results}
=======================
用户问:
{user_query}
请用中文回答用户问题。
"""
# 2. 构建 Prompt
prompt = prompt_template
# 3. 调用 LLM
response = self.llm_api(prompt)
return response
# 实例化
bot = RAG_Demo(
vector_db,
llm_api=get_completion_deepseek
)
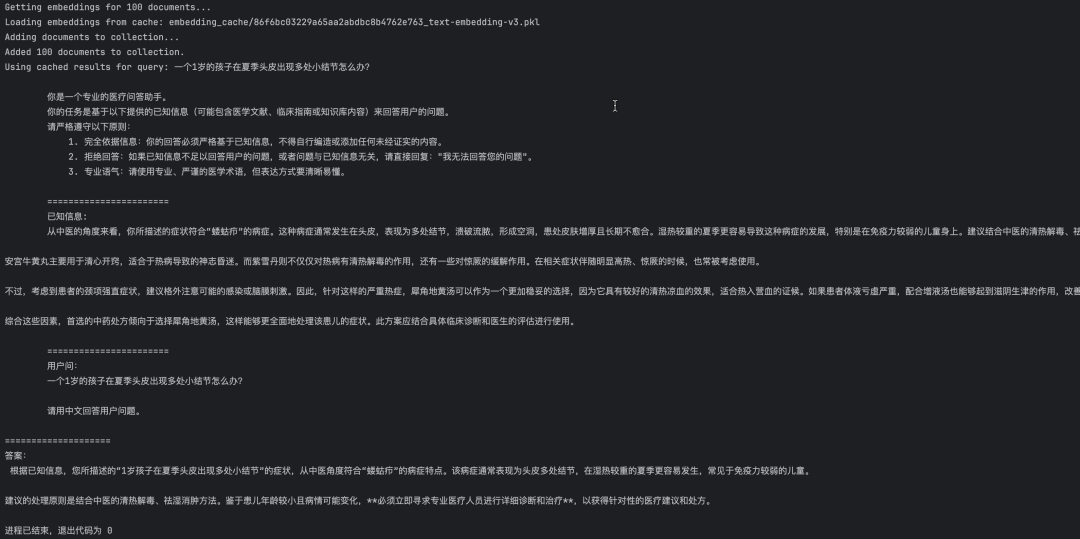
user_query = "一个1岁的孩子在夏季头皮出现多处小结节怎么办?"
response = bot.chat(user_query)
print("=" * 20)
print("答案:\n", response)2.3 运行结果
可以看到,最终生成的问题回答结果与RAG系统检索出的上下文内容高度吻合,二者在语义和事实上保持了完全一致:
三、关键点扩展
3.1 文档加载
数据源可能包含多种格式的文件,如文本文档、Markdown、PDF 等,因此需要首先对各类格式的文件进行处理。本章节将基于 LangChain 对文档处理进行介绍。LangChain 实现并集成了大量文档加载器,支持从不同格式的文件中加载数据。所有集成的文档加载器可参见官方文档:https://docs.langchain.com/oss/python/integrations/document_loaders
LangChain 中的所有文档加载器均实现了 BaseLoader 接口,该接口提供了通用的 load 方法(一次性加载所有文档)与 lazy_load 方法(以延迟方式加载文档),用于从数据源加载数据并将其转换为 Document 对象。
LangChain 通过 Document 抽象表示文本单元及其相关元数据,包含以下三个属性:
-
page_content:表示文本内容的字符串。
-
metadata:包含元数据的字典,例如文档来源等信息。
-
id:可选字段,用于标识文档的唯一标识符。
3.1.1 加载TXT
使用 LangChain 处理TXT文档:
# pip install langchain_community
from langchain_community.document_loaders import TextLoader
docs = TextLoader(
file_path="documents/sample.txt", # 文件路径
encoding="utf-8", # 文件编码方式
).load()
print(docs)
# [Document(metadata={'source': 'asset/sample.txt'}, page_content='...')]3.1.2 加载CSV
使用 LangChain 处理CSV文档:
# pip install langchain_community
from langchain_community.document_loaders.csv_loader import CSVLoader
# 加载所有列
docs = CSVLoader(
file_path="documents/sample.csv", # 文件路径
).load() # 返回List[Document]
print(docs)
# 加载部分列
docs = CSVLoader(
file_path="documents/sample.csv", # 文件路径
metadata_columns=["title", "author"], # 将指定列作为元数据
content_columns=["content"], # 将指定列作为内容
).load()
print(docs)3.1.3 加载JSON
LangChain 提供了 JSONLoader,用于将 JSON 和 JSONL 格式的数据转换为 LangChain 的文档对象。该加载器通过指定的 jq 模式解析 JSON 文件,从而将特定字段提取为 LangChain 文档的内容和元数据。
若需从 JSON Lines 文件中加载文档,需设置参数 json_lines=True。
常用的 jq schema 示例如下:
JSON -> [{"text": ...}, {"text": ...}, {"text": ...}]
jq_schema -> ".[].text"
JSON -> {"key": [{"text": ...}, {"text": ...}, {"text": ...}]}
jq_schema -> ".key[].text"
JSON -> ["...", "...", "..."]
jq_schema -> ".[]"详细用法可参考 https://jqlang.org/manual/#basic-filters
如下示例,提取JSON中所有字段:
# pip install langchain_community jq
from langchain_community.document_loaders import JSONLoader
# 提取所有字段
docs = JSONLoader(
file_path="documents/sample.json", # 文件路径
jq_schema=".", # 提取所有字段
text_content=False, # 提取内容是否为字符串格式
).load()
print(docs)如下示例,提取JSON指定字段中的内容:
# pip install langchain_community jq
from langchain_community.document_loaders import JSONLoader
# 提取指定字段中的内容
docs = JSONLoader(
file_path="documents/sample.json", # 文件路径
jq_schema=".data.items[]", # 提取data.items中的数据
text_content=False, # 提取内容是否为字符串格式
).load()
print(docs)
docs = JSONLoader(
file_path="documents/sample.json", # 文件路径
jq_schema=".data.items[].content", # 提取data.items[].content中的数据
).load()
print(docs)
docs = JSONLoader(
file_path="documents/sample.json", # 文件路径
jq_schema="""
.data.items[] | {
author,
created_at,
content: (.title + "\n" + .content)
}
""", # 提取data.items中指定字段的数据
text_content=False, # 提取内容是否为字符串格式
).load()
print(docs)3.1.4 加载HTML
使用 LangChain 处理HTML文档:
# pip install langchain_community beautifulsoup4
import bs4
from langchain_community.document_loaders import WebBaseLoader
docs = WebBaseLoader(
web_paths=("https://domain.com/index.html",),
# 传给 BeautifulSoup 的解析参数,parse_only 表示只提取指定标签的元素
bs_kwargs={"parse_only": bs4.SoupStrainer(class_="J-lemma-content")},
).load()
print(docs)3.1.5 加载Markdown
在 LangChain 中,可以使用 Unstructured 文档加载器中的 UnstructuredMarkdownLoader 来加载 Markdown 文件:
# pip install langchain_community unstructured[md]
from langchain_community.document_loaders import UnstructuredMarkdownLoader
docs = UnstructuredMarkdownLoader(
file_path="documents/sample.md",
mode="elements", # 模式: single 返回单个Document对象,elements 按标题等元素切分文档
).load()
print(docs)3.1.6 加载Doc/Docx
使用 LangChain 处理Doc/Docx文档:
# pip install langchain_community unstructured[docx]
from langchain_community.document_loaders import UnstructuredWordDocumentLoader
docs = UnstructuredWordDocumentLoader(
file_path="documents/sample.docx",
mode="single", # 模式: single 返回单个Document对象,elements 按标题等元素切分文档
).load()
print(docs)3.1.7 加载PDF
PDF 文件来源广泛,格式多样,主要可分为扫描版(即图片型 PDF)、电子文本版以及混合型版本。同时,其布局形式也千差万别,包括单栏、双栏乃至竖排文本等,且通常包含段落、标题、页眉页脚、表格、数学公式、化学式、特殊符号、图片等多种元素。因此,PDF 的解析面临诸多挑战。对于结构复杂的 PDF,通常需要进行文本提取、布局检测、表格解析、公式识别等多重处理。
在 LangChain 中,可通过以下方式对 PDF 文档进行处理:
-
PyPDFLoader
# pip install langchain_community from langchain_community.document_loaders import PyPDFLoader docs = PyPDFLoader( file_path="documents/sample.pdf", extraction_mode="plain", # 模式:plain 提取文本,layout 按布局提取 ).load() print(docs)
2. UnstructuredPDFLoader
UnstructuredPDFLoader 是对 unstructured 库的封装,支持布局识别以及通过 OCR 提取文字。
使用 UnstructuredPDFLoader 需要预先安装 Poppler 和 Tesseract OCR。
-
Poppler 是一个开源的 PDF 文档处理库,用于渲染、解析和操作 PDF 文件。下载并解压后,需将其安装路径下的
.../poppler-24.08.0/Library/bin添加至系统环境变量Path中。 -
Tesseract OCR 用于识别并提取图片中的文字。在安装过程中,需选择 “Additional language data (download)” 以添加所需的中文语言包
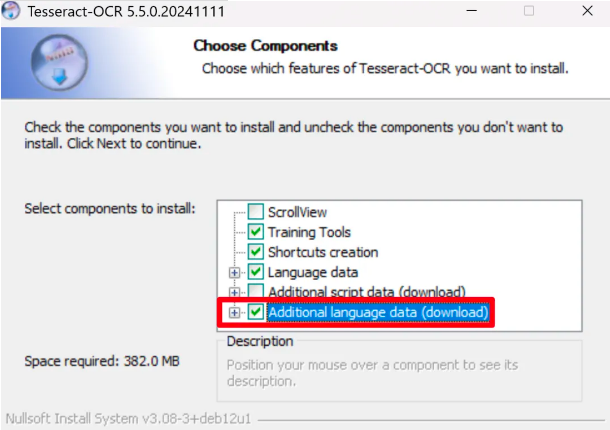
安装完成后,需将安装时指定的安装目录添加到系统环境变量 Path 中。
代码举例:
# pip install unstructured[local-inference]
from langchain_community.document_loaders import UnstructuredPDFLoader
docs = UnstructuredPDFLoader(
file_path="documents/sample.pdf", # 文件路径
mode="elements", # 模式: single 返回单个Document对象,elements 按标题等元素切分
# 加载策略:
# fast: pdfminer 提取并处理文本
# ocr_only: 转换为图片并进行 OCR
# hi_res: 识别文档布局,将OCR 输出与 pdfminer 输出融合
strategy="hi_res",
# 推断表格结构:仅 hi_res 下起效,如果为 True 则会在表格元素的元数据中添加 text_as_html
infer_table_structure=True,
# OCR 使用的语言: eng 英文,chi_sim 中文简体。语言列表参考 https://github.com/tesseract-ocr/langdata
languages=["eng", "chi_sim"],
# 更多参数详见 https://github.com/Unstructured-IO/unstructured/blob/main/unstructured/partition/pdf.py
).load()
print(docs)3. MinerU
除上述方式外,也可以借助 MinerU 提取 PDF 文档内容。MinerU 支持对 PDF、Word、PPT、图片等多种文件格式进行解析,具备图像提取、OCR识别、公式及表格解析等功能。
通过调用在线服务接口(接口文档详见:https://mineru.net/apiManage/docs),可实现本地批量文件上传与解析,并接收返回的解析结果。示例代码如下:
import os
import requests
def upload_files(file_paths: list[str]) -> str:
"""批量上传文件"""
url = "https://mineru.net/api/v4/file-urls/batch"
api_key = os.getenv("MINERU_API_KEY")
header = {
"Content-Type": "application/json",
"Authorization": f"Bearer {api_key}",
}
files_info = [
{
"name": os.path.basename(file_path), # 文件名
"is_ocr": True, # 是否启用 ocr
"data_id": f"file_{i}", # 文件对应唯一标识 id
}
for i, file_path in enumerate(file_paths)
] # 动态生成文件信息
data = {
"enable_formula": True, # 是否开启公式识别
"enable_table": True, # 是否开启表格识别
"language": "ch", # 文档语言
"files": files_info,
}
try:
response = requests.post(url, headers=header, json=data)
if response.status_code == 200:
result = response.json()
print("response success. result:{}".format(result))
if result["code"] == 0:
batch_id = result["data"]["batch_id"]
urls = result["data"]["file_urls"]
print("batch_id:{}\nurls:{}".format(batch_id, urls))
for i in range(0, len(urls)):
with open(file_paths[i], "rb") as f:
res_upload = requests.put(urls[i], data=f)
if res_upload.status_code == 200:
print(f"{urls[i]} upload success")
else:
print(f"{urls[i]} upload failed")
return batch_id
else:
print("apply upload url failed,reason:{}".format(result.msg))
else:
print(
"response not success. status:{} ,result:{}".format(
response.status_code, response
)
)
except Exception as err:
print(err)
def download_files(batch_id):
"""批量获取任务结果"""
os.makedirs("parsed_files", exist_ok=True)
url = f"https://mineru.net/api/v4/extract-results/batch/{batch_id}"
api_key = os.getenv("MINERU_API_KEY")
header = {
"Content-Type": "application/json",
"Authorization": f"Bearer {api_key}",
}
res = requests.get(url, headers=header)
extract_results = res.json()["data"]["extract_result"]
failed_files = set() # 失败文件集合
done_files = set() # 完成文件集合
whileTrue:
for result in extract_results:
if result["state"] == "failed":
failed_files.add(str(result))
elif result["state"] == "done":
done_files.add(str(result))
full_zip_url = result["full_zip_url"]
res_download = requests.get(full_zip_url, stream=True)
with open(
f"parsed_files/{result['file_name']}_{result['data_id']}.zip", "wb"
) as f:
for chunk in res_download.iter_content(chunk_size=1024):
f.write(chunk)
if len(failed_files) + len(done_files) == len(extract_results):
break
for i in failed_files:
print(i)
for i in done_files:
print(i)
file_paths = ["documents/sample.pdf"]
batch_id = upload_files(file_paths)
download_files(batch_id)3.2 切分策略
3.2.1 为什么需要切分
在获取文本对象后,需要将其切分为若干 Chunk(数据块)。之所以进行切分,主要基于以下考虑:
-
在后续检索中,需要根据用户提问从文本中召回相关内容并放入 Prompt。如果答案恰好位于某一完整的 Document 对象中,直接将整个 Document 放入 Prompt 并非最佳选择,因为其中可能包含大量无关信息,这些噪声内容会干扰大模型的生成质量。
-
大模型对输入内容有最大 Token 限制。若某个 Document 体积过大,输入时可能会被截断,导致关键信息缺失。
因此,一种有效的方法是将完整文档进行分块处理(Chunking),将其切分为多个小的文本块(Chunk)。无论是存储还是检索环节,都将以这些 Chunk 为基本单元,从而有效减少内容噪声干扰,并避免超出 Token 限制的问题。
3.2.2 切分策略
常见的切分策略主要包括以下几种:
-
语义切分
-
按段落切分
-
按句子切分
-
按固定字符数或 Token 数切分
-
按固定字符数 + 滑动窗口切分
-
递归使用多个分隔符进行切分,同时尽量控制字符数或 Token 数不超过预设限制
有关上述切分策略的直观效果,可访问 https://chunkviz.up.railway.app 进行查看和对比。

目前使用较多的切分方式主要包括按固定字符加滑动窗口切分和递归切分。下面将以 LangChain 中的递归切分策略为例进行介绍。
3.2.3 递归切分
在 LangChain 中,递归切分主要借助 RecursiveCharacterTextSplitter(递归字符文本切分器)来实现。该方法是 LangChain 特有的递归切分与滑块切分相结合的实现方式。
RecursiveCharacterTextSplitter 是最常用的切分器,其核心机制是通过一个字符列表作为分隔符依据。默认列表为 ["\n\n", "\n", " ", ""],切分时会按顺序尝试使用这些字符进行分割,直到每个文本块的大小符合预设要求。这种设计旨在尽可能保持段落、句子乃至单词的完整性,因为这些层级通常代表了语义上最相关的文本片段。
此外,为确保各文本块之间的语义连贯,可以在切分时设置一定的重叠区域,使得相邻块之间共享部分内容。
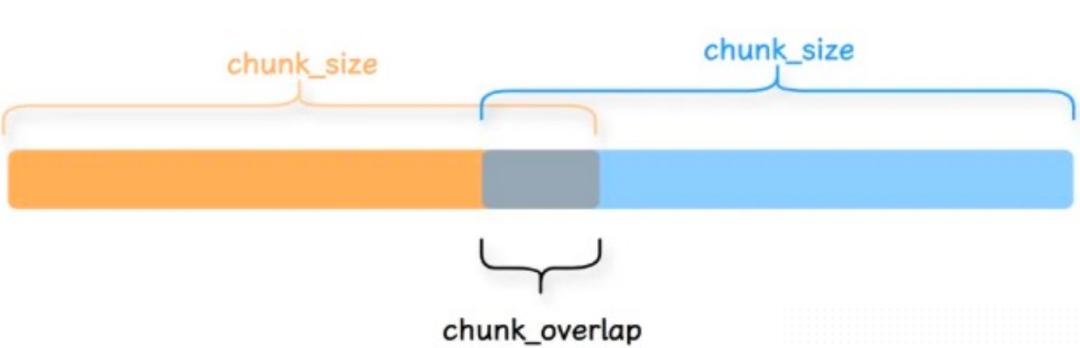
实现代码如下:
# pip install langchain-text-splitters
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langchain_community.document_loaders import UnstructuredWordDocumentLoader
# 加载文档
docs = UnstructuredWordDocumentLoader(
file_path="documents/sample.docx", mode="single"
).load()
# 切分为文本块
chunks = RecursiveCharacterTextSplitter(
separators=["\n\n", "\n", "。", "!", "?", "……", ",", ""], # 分隔符列表
chunk_size=400, # 每个块的最大长度
chunk_overlap=50, # 每个块重叠的长度
length_function=len, # 可选:计算文本长度,默认为字符串长度,可自定义函数来实现按 token 数切分
add_start_index=True, # 可选:块的元数据中添加此块起始索引
).split_documents(docs)
print(chunks)3.3 文档向量化
使用向量模型生成文档的嵌入向量,在后续检索过程中用于与查询的嵌入向量进行相似度计算。常用的向量模型如下:
|
模型 |
描述 |
|---|---|
|
beg-large-zh |
开源,向量维度1024,序列长度512 |
|
beg-base-zh |
开源,向量维度768,序列长度512 |
|
beg-small-zh |
开源,向量维度512,序列长度512 |
|
beg-m3 |
开源,多语言,向量维度1024,序列长度8192 |
|
text-embedding-3-small |
多语言,向量维度1536,序列长度8192 |
|
text-embedding-3-large |
多语言,向量维度3071,序列长度8192 |
使用方法示例:
# pip install sentence-transformers langchain_huggingface
import os
from langchain_huggingface import HuggingFaceEmbeddings
# 加载嵌入模型
embed_model = HuggingFaceEmbeddings(
model_name=os.path.expanduser("~/models/bge-base-zh-v1.5")
)
# 单文本嵌入
query = "2026年美国主动向伊朗开战"
print(embed_model.embed_query(query))
# 多文本嵌入
docs = ["2026年美国主动向伊朗开战", "伊朗做了全面反击"]
print(embed_model.embed_documents(docs))3.4 向量存储介质
向量存储介质主要是指用于存储和检索向量数据的各类数据库系统,其中向量数据库因其高效的相似性搜索能力而成为主流选择。常见的向量数据库包括以下几类:
|
向量数据库 |
类型 |
场景 |
特征 |
|---|---|---|---|
|
Pinecone |
全托管云服务 |
适用于追求快速上线、不愿自建运维的团队,尤其适合需要高级数据管理功能的实时AI应用 |
1. 重复检测与去重:自动识别和删除重复数据,保持数据集纯净。 |
|
Milvus |
开源可自托管 |
适合处理超大规模向量数据(如百亿级以上)的企业,需要GPU加速或复杂部署架构的场景 |
1. 万亿级向量毫秒检索:专为海量向量设计,查询延迟极低。 |
|
Chroma |
开源嵌入式 |
主要用于本地开发、原型验证及中小规模RAG应用,尤其适合AI研究者与初创团队 |
1. 功能丰富:内置查询、过滤、密度估计等功能,使用便捷。 |
|
Faiss |
开源相似性搜索库 |
适用于需要底层自定义向量搜索算法的研究机构或高性能计算场景,通常作为核心组件嵌入其他系统 |
1. 多邻近距离检索:支持返回第k近的多个邻居,而不仅是最近邻。 |
|
Weaviate |
开源/托管可选 |
适合需要结合语义与关键词搜索的知识库、推荐系统及智能问答应用 |
1. 混合搜索:结合向量检索与关键词匹配,提升结果相关性。 |
|
Qdrant |
开源 |
适用于对性能要求苛刻的实时应用,如聊天机器人、个性化推荐等 |
1.云原生架构:使用Rust编写,具备高性能与内存安全。 2.高级过滤:支持复杂条件过滤,精准定位向量数据。 3.实时更新:支持动态数据增删,适用于实时推荐等场景。 |
|
PgVector |
PostgreSQL扩展 |
适合已有PostgreSQL生态的中小规模AI应用,尤其需要强事务支持的场景 |
1. 无缝集成:在PostgreSQL中添加向量检索能力,无需迁移数据。 |
|
OpenSearch |
开源搜索引擎 |
适用于企业级AI搜索应用,需要严格数据治理与合规性的场景 |
1. k-NN插件:支持高效的近似最近邻搜索。 |
|
Elasticsearch |
搜索引擎扩展 |
适合已有Elasticsearch技术栈的企业,用于日志分析、商品搜索等场景的AI升级 |
1. 功能全面:成熟的全文本搜索生态。 |
|
Redis (向量模块) |
内存数据库扩展 |
适用于实时竞价、在线游戏匹配、推荐系统等需要极低延迟的场景 |
1. 微秒级延迟:基于内存存储,查询速度极快。 |
四、总结
通过以上内容,我们从零实现了一个基础RAG系统,并深入了解了文档加载、切分、向量化、存储等核心环节。这为构建更复杂的RAG应用打下了坚实基础。在实际工程中,还需要考虑性能优化、检索质量评估、多路召回等进阶问题。

欢迎加入 MCP 技术社区!与志同道合者携手前行,一同解锁 MCP 技术的无限可能!
更多推荐
 0
0 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)