【大模型开发进阶】提示工程与 Few-Shot 范式演进:从云端调用到本地部署的工程实践
在大语言模型(LLM)应用开发的进程中,构建安全、高效的智能系统是当前的核心技术命题。本文作为大模型开发系列实战的首篇,重点梳理环境配置、模型调用及提示工程(Prompt Engineering)的底层逻辑,并深入解析 Zero-shot 与 Few-shot 学习范式在实际工程中的落地路径。
截图与知识点来自课程:黑马程序员大模型RAG与Agent智能体项目实战教程,基于主流的LangChain技术从大模型提示词到实战项目_哔哩哔哩_bilibili
目录
一、 基础设施构建:云端调用与本地部署
1. 云端调用
在原型验证初期,可依托云端平台(如阿里云百炼)丰富的模型生态与测试额度,有效降低算力与试错成本:
在云端调用的工程实践中,凭证安全须置于首位。若将 API Key 以明文形式硬编码于业务代码中,将面临极大的泄露风险。规避该隐患的标准规范是,在操作系统层面配置如 OPENAI_API_KEY 的环境变量,使业务程序在运行时自动从系统环境变量中读取api-key,防止以明文形式出现在代码中:
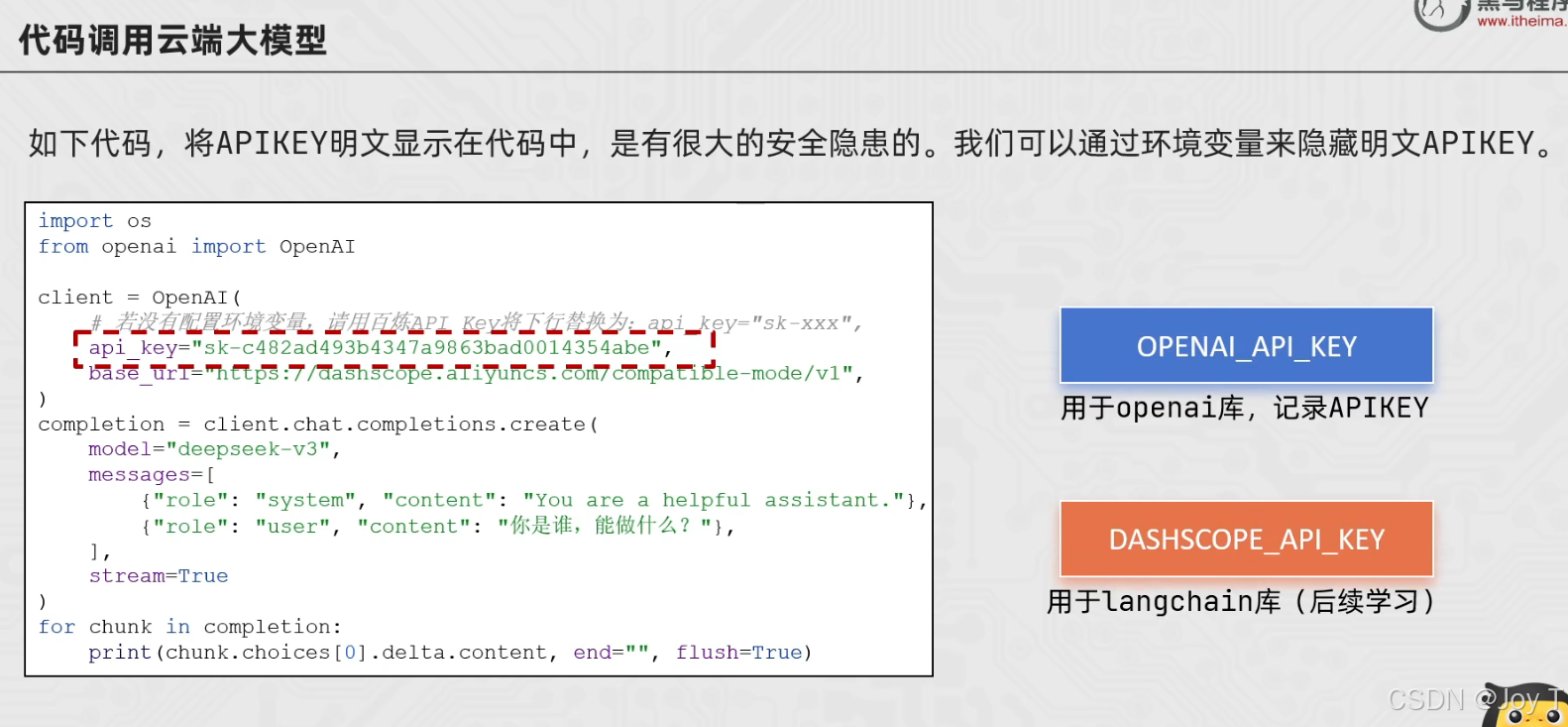
此举不仅保障了核心凭证的安全,亦提升了代码在多环境间的迁移效率。
2. Ollama本地部署
针对无网环境或高数据隐私要求的业务场景,本地化部署是关键的技术补充。借助 Ollama 等开源框架,开发者可在本地硬件算力支撑下,便捷地管理与运行各类大型语言模型。
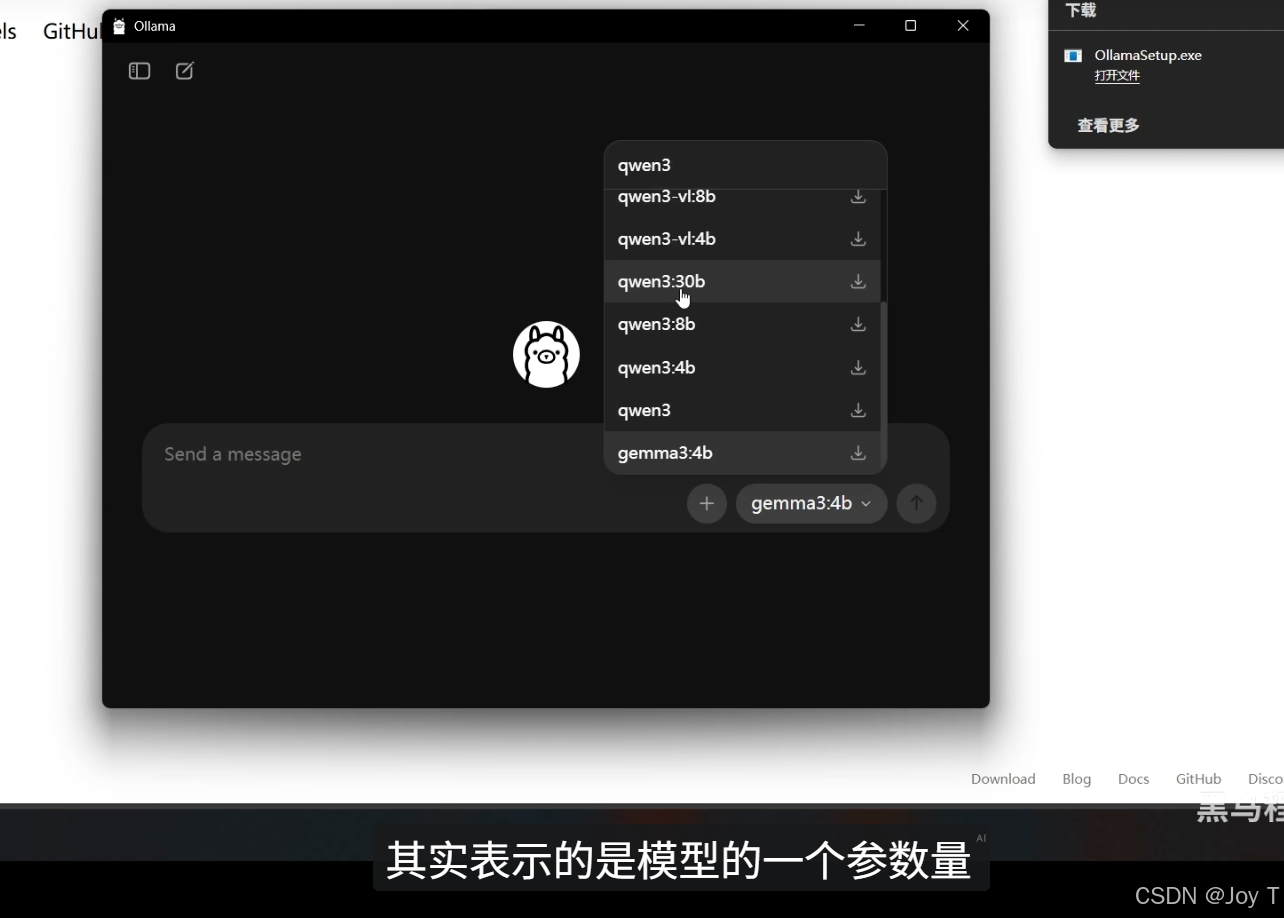
受限于常规设备的显存容量,本地运行多采用经过压缩优化的“蒸馏模型”。模型标识中的“B”(如 8B 或 30B)代表 Billion(十亿),直观反映了该模型的参数量级。
二、 模型交互中枢:参数解析与角色定义
环境初始化完成后,即进入大模型交互核心流。在标准 API 接口中,model(指定模型版本)与 messages(承载上下文信息)是最核心的调用参数。
构建 messages 数据结构时,需精准运用三类核心角色(Role)。
- System(系统角色)负责在对话初始设定全局背景、助手人设及行为边界;【身份设定,背景阐述】
- User(用户角色)承载具体的业务指令、查询问题或原始数据;【用户提问】
- Assistant(助手角色)则存储大模型基于前序上下文生成的阶段性回复。【AI回复】
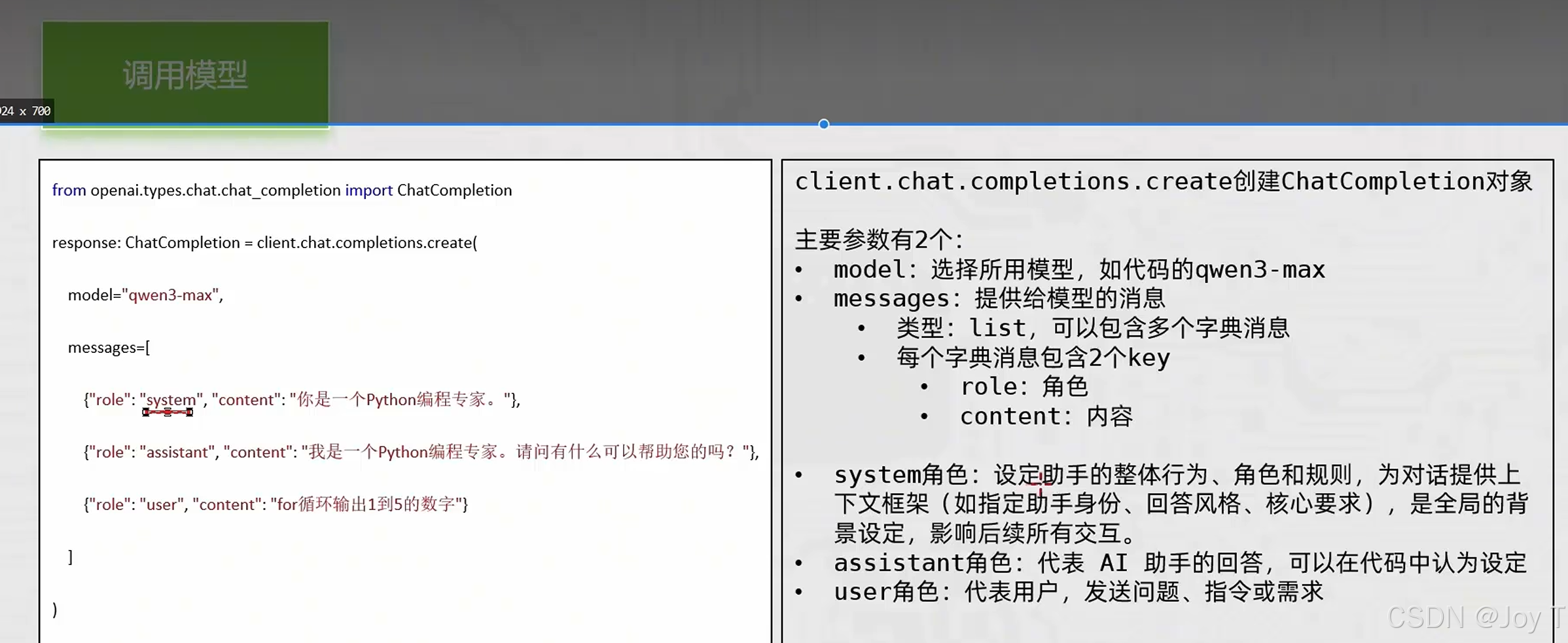
通过这三类角色的结构化交织,程序能够在代码层面精准复刻复杂的自然人机多轮对话场景。
三、 提示工程进阶:从零样本到少样本的知识迁移
提示工程的核心机制,是在不更新模型底层权重的前提下,通过优化自然语言交互模式,精准引导模型输出预期结果。
在这一技术领域,传统机器学习的样本训练思想被赋予了全新的语义级应用。
1. 零样本学习 Zero-shot learning
当向模型输入其在预训练阶段未曾明确处理过的新任务时,模型能够依托底层的prompt语义理解、逻辑推理及预训练知识的泛化迁移,对新的类别进行识别,并直接生成结果。此过程即零样本学习(Zero-shot learning),充分展现了大模型卓越的泛化推理能力。

2. 少样本学习 Few-shot learning
在面对格式规范严格或垂直领域知识密集的复杂任务时,零样本学习的输出稳定性往往欠佳。此时,引入少样本学习(Few-shot learning)范式尤为关键。
通过在提示词中嵌入少量标准问答示例,模型能够迅速提取并对齐新类别的特征模式。若仅提供单个精准示例,则特化为单样本学习(One-shot learning)。

本质而言,提示词优化可以视为LLM领域中用自然语言训练模型的方法,所以Zero-shot 或者 Few-shot 都可以从模型训练领域迁移至提示词工程(PE)领域。
四、 代码落地:上下文组装与格式化输出策略
1. 结构化组装
在工程代码中实现 Few-shot 学习,实质上是结构化组装历史对话记录的过程。

开发者需严格按照 System、User、Assistant 的角色次序,将预设的优质示例拼装为完整的上下文列表。当模型摄入这段富含规则示例的 messages 时,即可自动对齐后续输出的逻辑路径与文本格式。

2. JSON数据格式
针对结构化信息抽取场景,JSON 是主流的数据交换格式。为确保模型生成的 JSON 数据具备良好的跨语言兼容性,必须在提示词中严格约束模型仅使用双引号包裹键值对。

在 Python 开发生态中,通常借助内置库完成数据转换:调用 json.dumps() 方法将内存数据结构序列化为 JSON 字符串,并利用 json.loads() 将模型返回的标准化 JSON 文本反序列化为可编程的数据字典或列表。
3. 核心代码
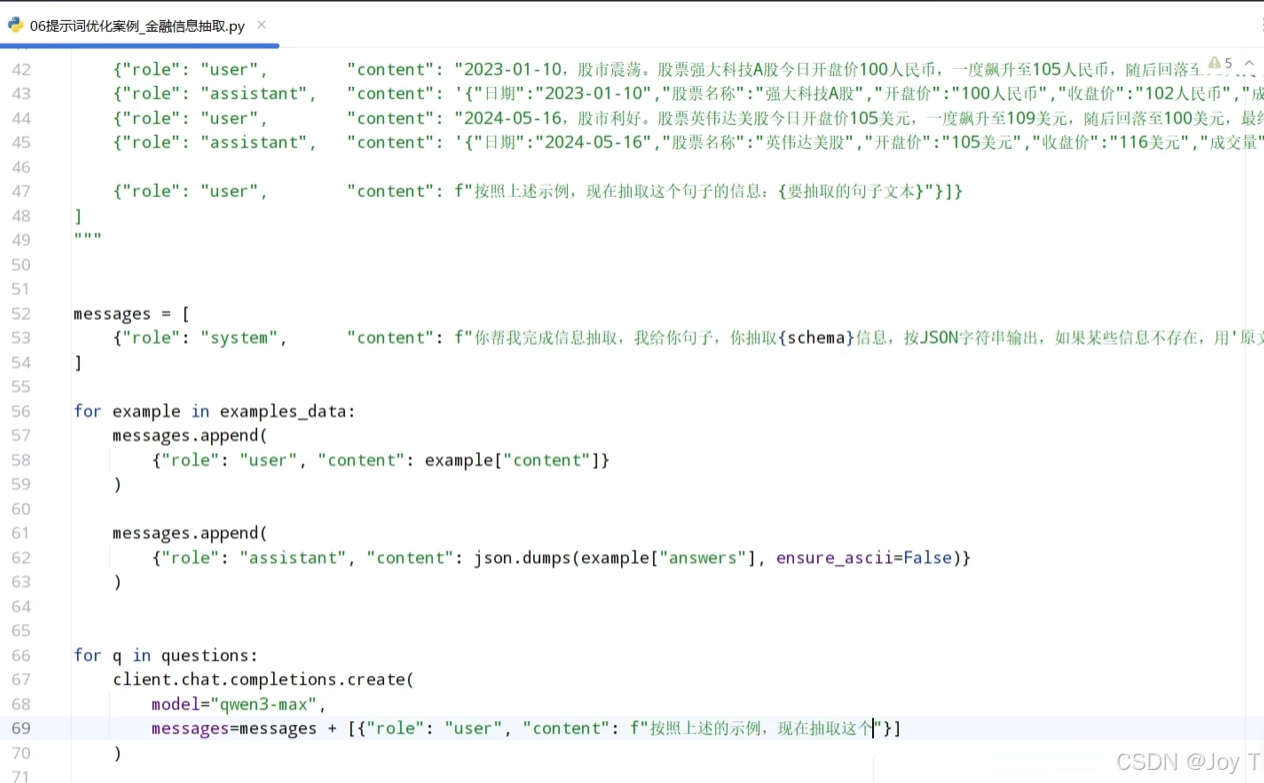
构建一条工业级的交互消息需遵循标准范式:
首先确立清晰的系统角色定义;其次运用特定符号(如方括号、反引号等)进行文本物理分割,确保指令边界的精准识别;最后嵌入高质量的 Few-shot 示例。践行该套方法论,可最大限度地激发大模型的业务处理潜能。

随着业务复杂度的提升,管理长文本交互、接入外部私域知识库并赋予模型长期记忆,对纯底层的 API 调用提出了巨大挑战。在后续的内容中,我们将基于当前提示工程的理论基础,深入剖析 LangChain 框架的组件生态及其在 RAG(检索增强生成)架构中的工程实现。

欢迎加入 MCP 技术社区!与志同道合者携手前行,一同解锁 MCP 技术的无限可能!
更多推荐


 10
10 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)