Transformer进化史:从原始架构到Llama 3,这些改进让LLM飞起来!
在上篇中,我们拆解了Transformer LLM的基础流程:分词→嵌入→堆叠的Transformer块→语言建模头→采样输出。你也明白了自注意力如何让词元“窃窃私语”交换信息,前馈网络如何存储知识。但你可能要问:现在的LLM(比如GPT-4、Llama 3)动辄上千亿参数,处理超长上下文,如果还用原始的Transformer,早就卡死了。
没错,学术界和工业界在原始Transformer上做了大量手术级优化。今天我们就来看看这些改进——它们让模型更快、更省内存、更能捕捉长距离依赖,同时也催生了像Llama 2/3这样的明星模型。
一、更高效的注意力机制:从“全连接”到“精准打击”
自注意力层是Transformer的计算瓶颈——每个词元都要和前面所有词元做点积,复杂度是O(n²)(n为序列长度)。当上下文长度达到4K、32K甚至1M时,计算量爆炸。于是,各路大神开始对注意力“动刀”。
1.1 稀疏注意力:只看该看的
想象一下:你在读一篇长文,真的需要把每个词和前面所有词都关联一遍吗?不一定。很多时候,一个词只和附近的一些词,或者特定句法结构的词相关。稀疏注意力正是基于这个直觉,限制每个词元只能关注一部分前序词元(如下图)。
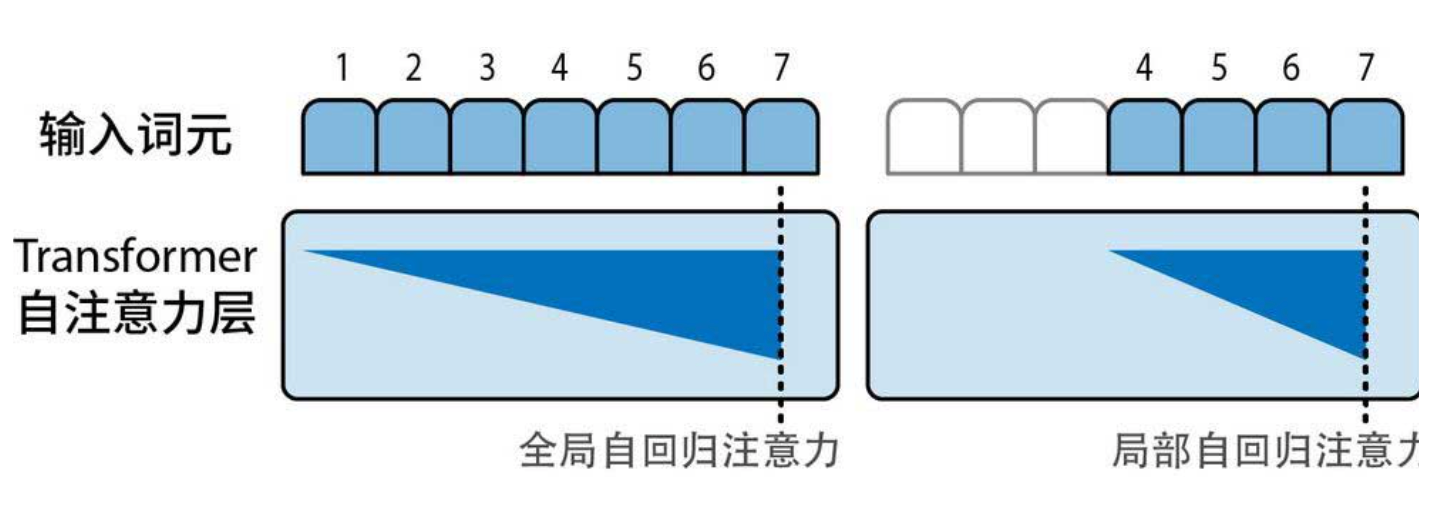
- 固定窗口注意力:只关注前后k个词元(滑动窗口)。
- 跳跃式注意力:每隔几个词元关注一个,像跳格子一样。
但完全稀疏会丢失全局信息,所以GPT-3采用了混合策略:部分Transformer块用全注意力(保持全局视野),部分用稀疏注意力(降低计算量),两者交替排列。这样既保证了质量,又提升了速度。
下图展示了不同稀疏模式的对比:全注意力是实心三角,稀疏注意力则是稀疏的点阵。颜色深浅代表能关注的词元范围。注意:在解码器(自回归模型)中,每个词元只能看到它前面的词元,不能看后面的(这是因果掩码),所以图中的可关注区域始终是左下方的三角形。

1.2 多查询注意力与分组查询注意力:共享键值,减少内存
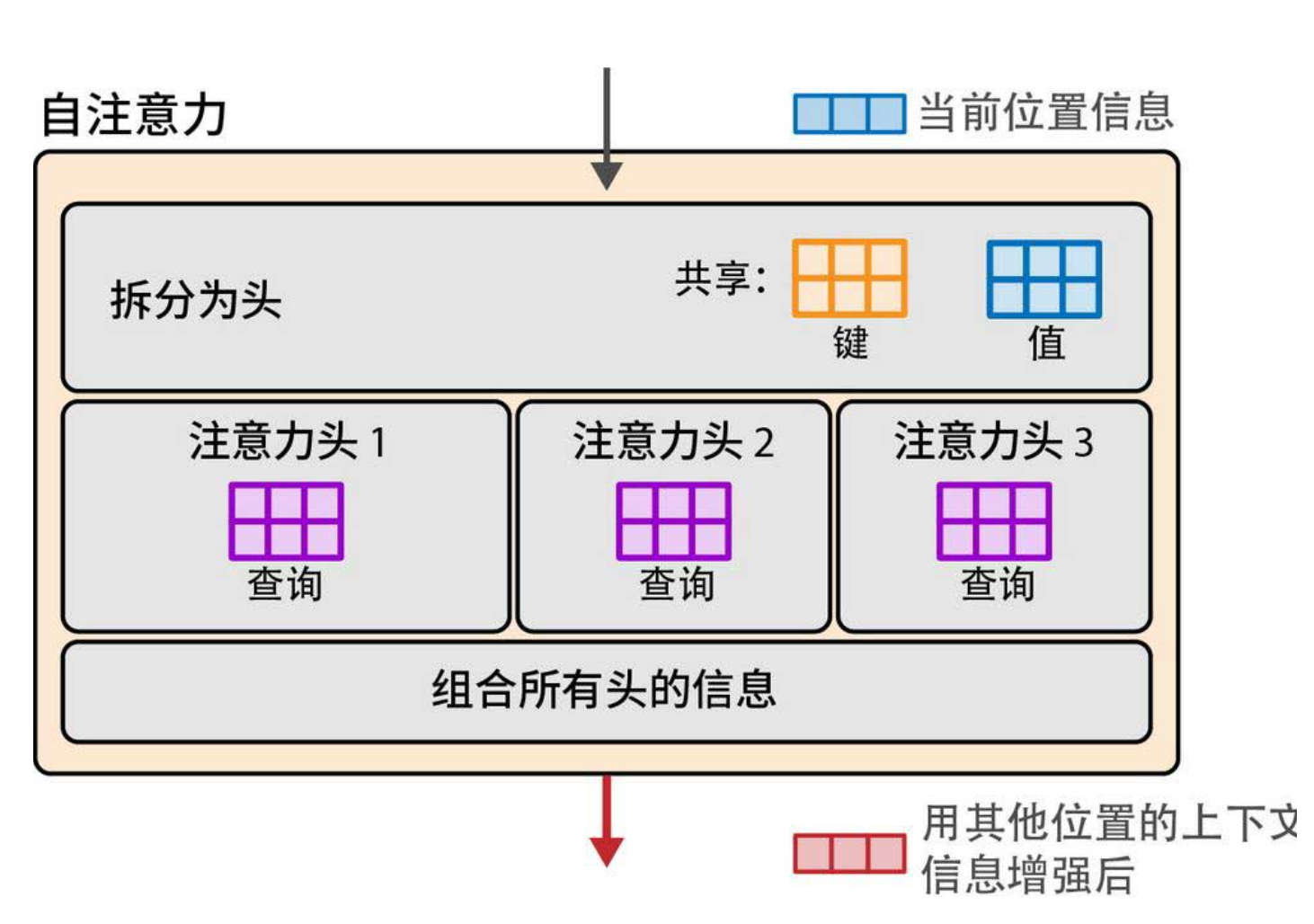
还记得多头注意力吗?每个头都有自己独立的查询(Q)、键(K)、值(V)矩阵。这导致K和V的矩阵数量等于头数,内存占用巨大,推理时带宽压力山大。
多查询注意力(Multi-Query Attention, MQA) 提出一个大胆的想法:让所有头共享同一套K和V矩阵,每个头只保留自己的Q矩阵(下图)。这样一来,K、V矩阵的总量从“头数”降为1,显存占用和访存开销骤降。但代价是模型表达能力可能下降,因为所有头都从相同的K、V中提取信息,缺少多样性。
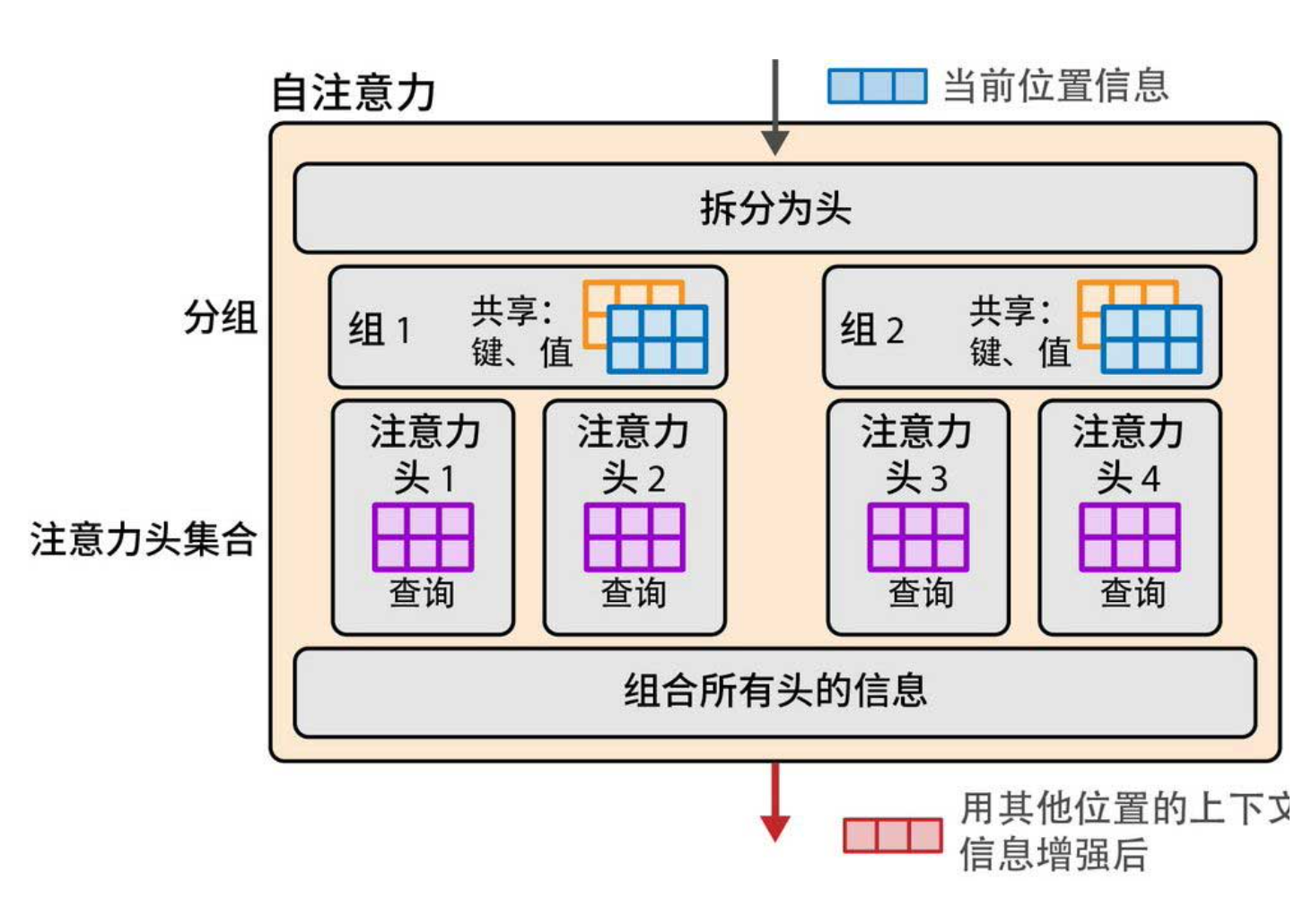
为了在效率和效果之间取得平衡,分组查询注意力(Grouped-Query Attention, GQA) 横空出世(下图)。它将头分成若干组,每组内共享一套K和V,组间独立。比如32个头分成8组,每组4个头共享K、V,那么K、V总数就是8,远小于32,又保留了足够的多样性。Llama 2和Llama 3都采用了GQA,这也是它们能高效处理长上下文的原因之一。
1.3 Flash Attention:让GPU“少搬砖,多计算”
如果你用过GPU编程,就知道显存有不同层级:HBM(高带宽内存) 容量大但速度慢,SRAM(共享内存) 容量小但极快。常规注意力计算需要频繁在HBM和SRAM之间搬运数据,大部分时间都花在了“搬砖”上。
Flash Attention 的核心思想是:分块计算,尽量让中间结果留在SRAM中,减少HBM读写。它通过重新组织计算顺序,把Q、K、V切成小块,在SRAM内完成小块的注意力,再写回HBM。同时,它利用softmax的在线归一化技巧,避免存储整个注意力矩阵。结果就是:2~4倍的速度提升,且内存占用随序列长度线性增长(而不是平方)。现在主流LLM训练和推理都离不开Flash Attention。
二、Transformer块的“装修升级”
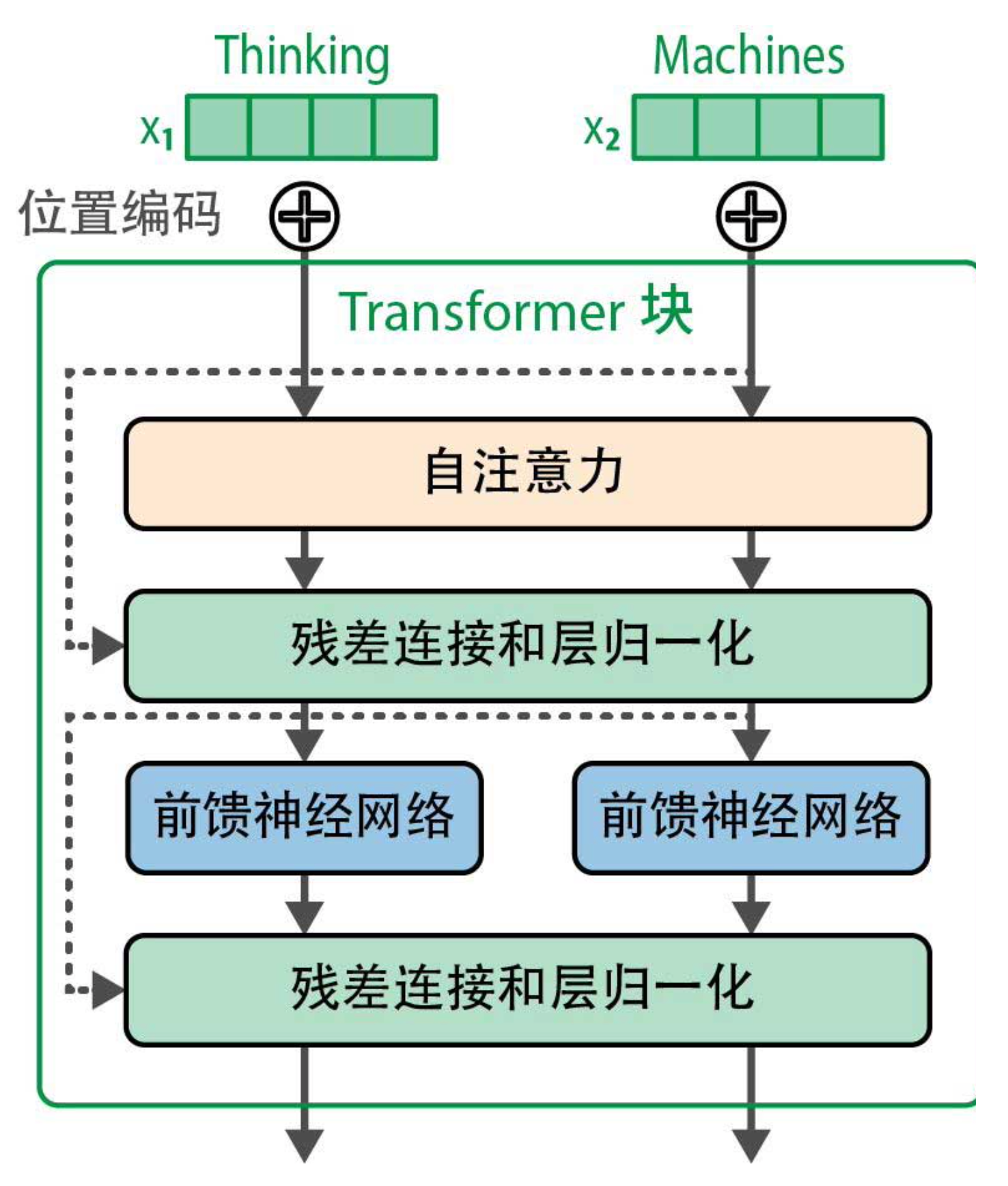
除了注意力机制,Transformer块内部的“装修风格”也变了。对比原始论文(下图1)和2024年的典型结构(下图2),你会发现三大变化:
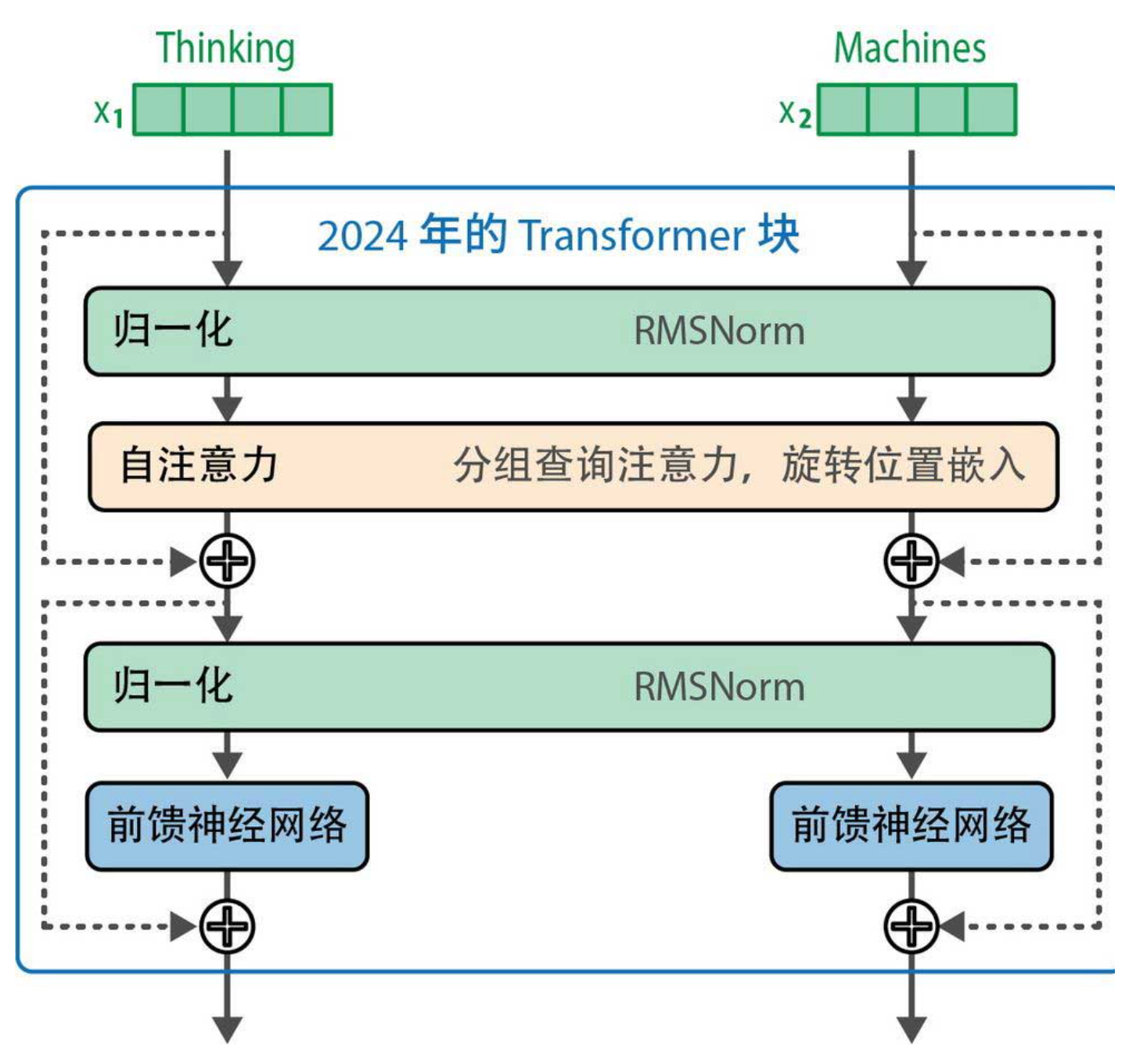
2.1 预归一化(Pre-Norm) + RMSNorm
原始Transformer采用后归一化:先做注意力/前馈,再加残差,最后归一化。后来发现这会导致训练不稳定,尤其是深层模型。于是大家改成预归一化:先归一化,再送入子层,最后加残差。这有助于梯度流动,加速收敛。
归一化层本身也升级了。原始的LayerNorm需要计算均值和方差,涉及多次归约操作。RMSNorm(均方根归一化)简化了计算:只对输入除以均方根,不减去均值。实验证明效果几乎一样,但速度更快。现在的模型(如Llama)普遍用RMSNorm。
2.2 激活函数:从ReLU到SwiGLU
原始Transformer的前馈网络用了ReLU激活,但ReLU在负区间梯度为0,可能导致神经元“死亡”。后来的研究表明,更平滑的激活函数如GELU、SwiGLU能提升模型质量。SwiGLU其实是GLU(门控线性单元)的变体,结合了Swish激活。它把前馈网络改成两个线性变换的逐元素乘积,其中一个经过Swish激活,显著增强了模型的表达能力。Llama 2/3都采用SwiGLU。
三、位置嵌入:让模型理解“词序”的新姿势
词序是语言的生命线。“狗咬人”和“人咬狗”完全不同。原始Transformer用绝对位置编码(正弦波或可学习向量)加到词嵌入上。但这种方法在处理长文档打包训练时遇到了麻烦。
3.1 打包训练带来的位置困惑
为了充分利用上下文长度,训练时常把多个短文档拼成一个序列(下图)。比如把文档1、分隔符、文档2、分隔符…塞进4K上下文。如果使用绝对位置编码,文档2的第一个词元会被赋予一个很大的绝对位置(比如500),模型会误以为它前面还有500个词,但实际上前面是另一个文档,应该被忽略。这会让模型学偏。

3.2 旋转位置嵌入(RoPE)——相对位置的优雅解法
RoPE(旋转位置嵌入)彻底改变了位置信息的注入方式。它不像传统方法那样在输入层加一个位置向量,而是在注意力计算时,将位置信息旋转进查询和键向量中(下图1、下图2)。具体来说,它用旋转矩阵对Q和K进行变换,使得Q和K的点积结果天然包含相对位置信息——两个词元距离越远,点积中衰减越明显。这样模型直接感知的是“相对距离”,而不是绝对位置。
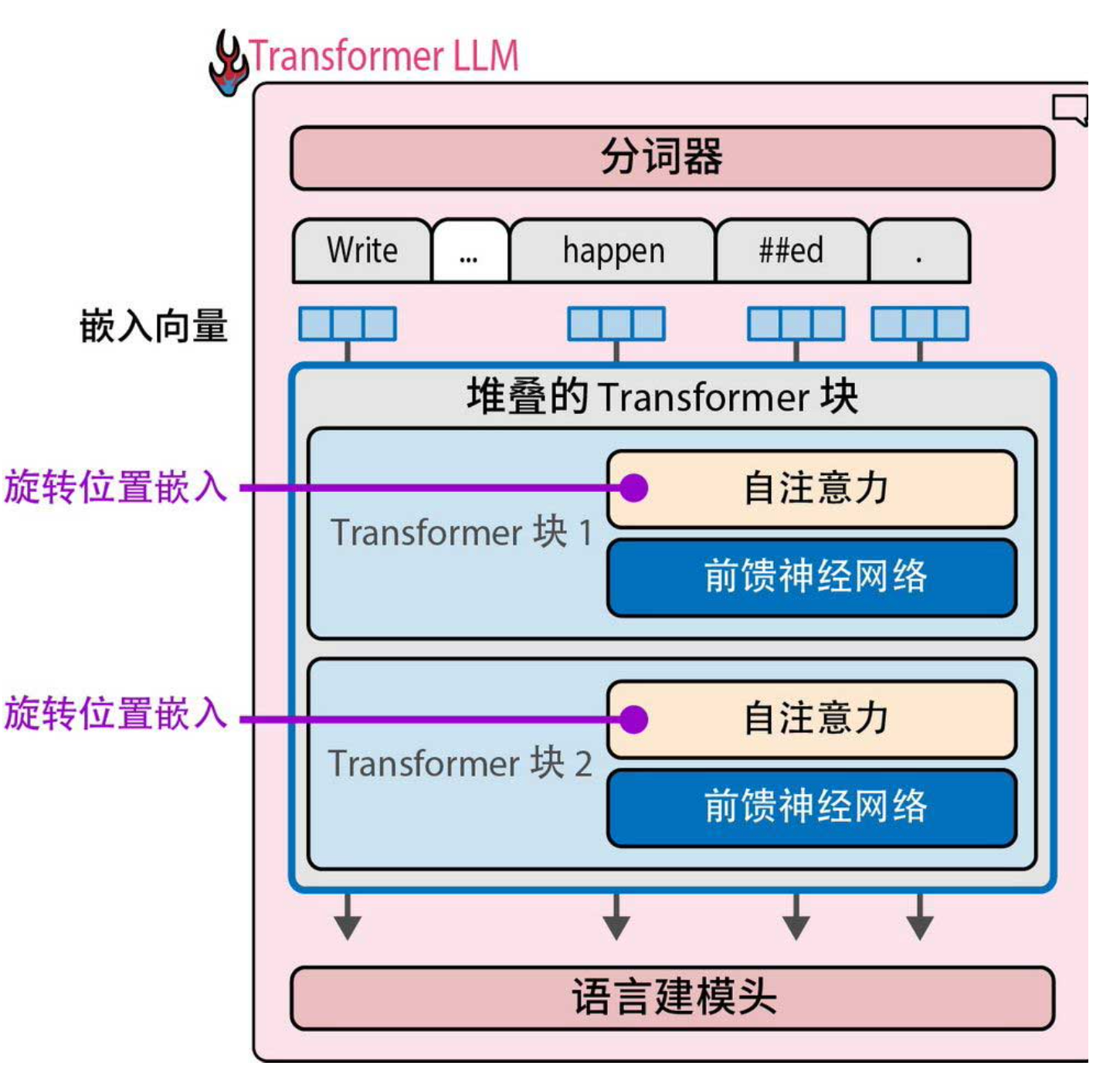
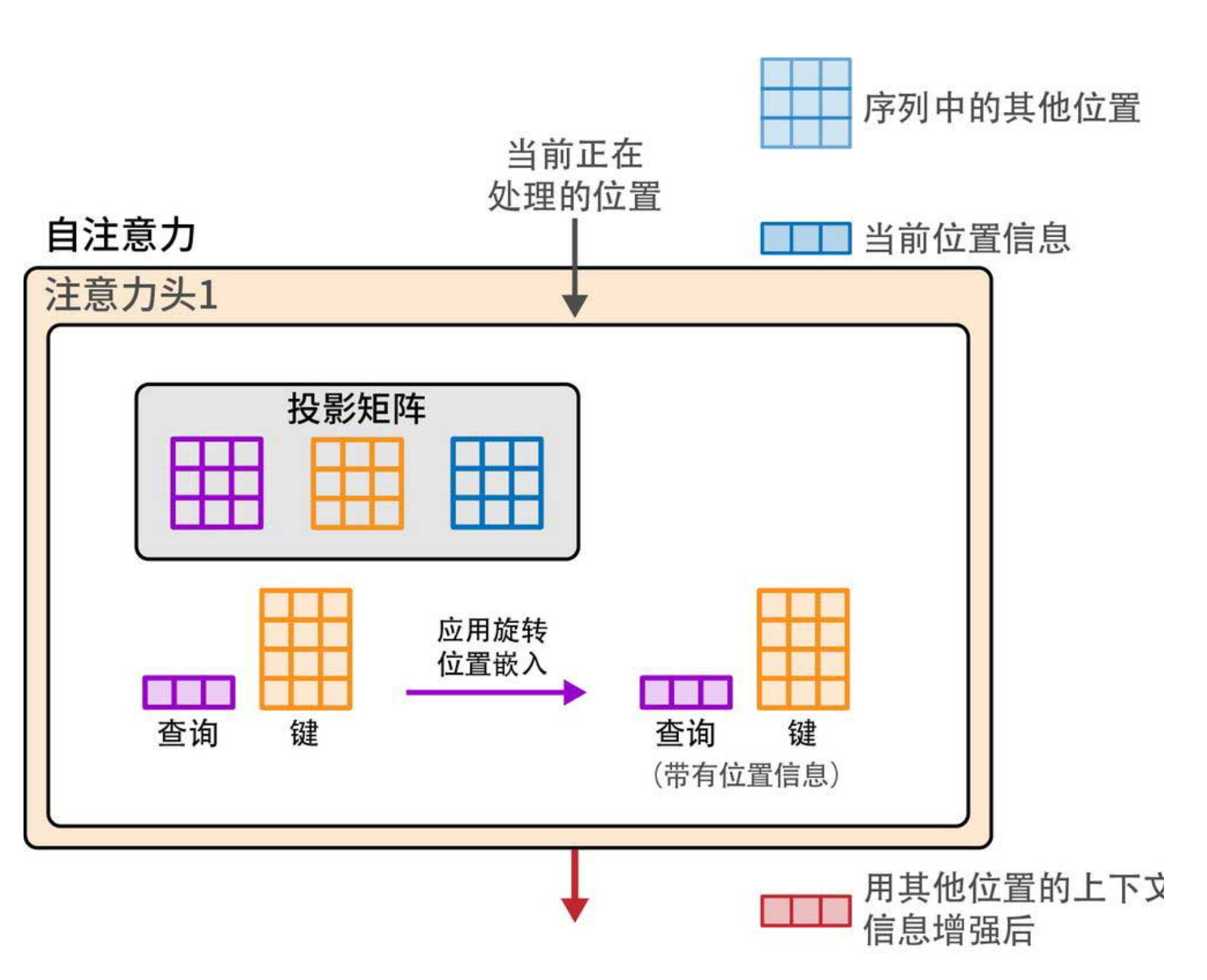
RoPE的优势:
- 对序列长度外推性更好(即使训练时只有4K,测试时也能处理8K)。
- 完美适应打包训练:因为相对位置只关心同一文档内部的词元,跨文档的注意力自然被分隔符切断,不会混淆。
- 实现简单,兼容现有注意力计算。
现在,RoPE几乎是所有先进LLM(包括GPT-4、Llama、PaLM)的标配。
四、其他方向的探索
Transformer的改进远不止这些。研究者还在尝试:
- 混合专家模型(MoE):把前馈网络换成多个“专家”,每次只激活其中几个,大幅增加参数量而不增加计算量(如Mixtral 8x7B)。
- 线性注意力:用核方法把O(n²)降到O(n),但效果尚未全面超越标准注意力。
- 跨领域应用:Transformer早已跳出NLP,在计算机视觉(ViT)、机器人(RT-X)、时间序列预测等领域开花结果。
五、小结:一张图记住Transformer的“进化基因”
现在,我们可以把现代LLM(比如Llama 3)的内部结构更新为:
- 分词器 → 嵌入(可学习)
- 堆叠的Transformer块(每个块内):
- RMSNorm(预归一化)
- 分组查询注意力(含RoPE位置编码)
- 残差连接
- RMSNorm(预归一化)
- SwiGLU前馈网络
- 残差连接
- 语言建模头(线性层 + softmax)
- KV缓存 + Flash Attention 加速推理
这些改进并非孤立,它们共同作用,让模型在更大规模、更长上下文中依然保持高效和高质量。下次你使用ChatGPT时,可以想象每个词元都在这些精心设计的层中穿梭,既看到局部细节,又把握全局脉络——这就是现代LLM的魔法。
关键概念速览
|
概念 |
一句话解释 |
|
稀疏注意力 |
只让词元关注部分前序词元,减少计算量。 |
|
分组查询注意力(GQA) |
多个注意力头共享一组键值,平衡效率与效果。 |
|
Flash Attention |
利用GPU高速缓存分块计算注意力,大幅提速。 |
|
预归一化 |
先归一化再子层,训练更稳定。 |
|
RMSNorm |
简化版LayerNorm,更快且效果相当。 |
|
SwiGLU |
新型激活函数,提升前馈网络表达能力。 |
|
旋转位置嵌入(RoPE) |
将位置信息旋转进查询和键,使注意力天然感知相对距离,便于长上下文外推。 |
在下一章,我们将走出模型内部,看看如何把这些强大的LLM应用到实际任务中——从文本分类到对话系统,让你真正“用起来”!
本文参考:图解大模型:生成式AI原理与实战
书籍pdf免费下载地址:https://pan.baidu.com/s/1mTaUQ5czcfGpBM8KvJuS2g?pwd=un44

欢迎加入 MCP 技术社区!与志同道合者携手前行,一同解锁 MCP 技术的无限可能!
更多推荐


 1
1 0
0- 0



 已为社区贡献46条内容
已为社区贡献46条内容

所有评论(0)