FRoM-W1:用自然语言驱动人形机器人全身运动的开源框架
1. 引言:人形机器人为什么需要"听懂人话"
当前的人形机器人,无论是 Unitree H1、G1 还是 Fourier GR1T1,已经能够完成打招呼、跳舞甚至后空翻等动作。但这些能力大多依赖硬编码轨迹或针对特定任务训练的强化学习策略,往往还需要手柄遥控。这意味着机器人并不真正"理解"人类的意图——它只是在执行预设的程序。如果我们希望人形机器人能够像人类同事一样,听到一句"帮我把桌上的杯子递过来"就自主完成动作,那就必须解决一个根本性问题:如何让机器人从一句自然语言指令出发,生成包含手部精细操作在内的全身协调运动,并在真实物理环境中稳定执行。
这正是复旦大学与上海创智学院团队提出 FRoM-W1 框架所要回答的核心问题。FRoM-W1 的全称是 “Foundational Humanoid Robot Model – Whole-Body Control, Version 1”,它是一个完全开源的系统,目标是建立一条从自然语言到真机全身动作的完整闭环。论文链接:https://arxiv.org/pdf/2601.12799,项目主页:https://openmoss.github.io/FRoM-W1/
2. 核心挑战:两道绕不过去的坎
在深入技术细节之前,有必要先理解这个问题为什么困难。FRoM-W1 直面的是两个相互关联但性质不同的挑战。
第一个挑战在于语言与动作之间的语义鸿沟。当用户说"扮演一头大象"时,这句话本身不包含任何关于关节角度、运动轨迹或时序结构的信息。系统需要将这种高度抽象的语义意图,拆解为具体的、带时间顺序的全身运动原语——不仅包括躯干和四肢的大幅度运动,还要涵盖手指的精细动作。现有的大规模人形机器人动作数据集极度匮乏,直接收集"语言-机器人动作"配对数据的成本高得不切实际。
第二个挑战在于仿真到真机的落地鸿沟。即便在仿真环境中生成了看起来合理的动作序列,直接将其部署到双足人形机器人上,几乎必然导致失稳和摔倒。真实世界中的重力扰动、关节限位、地面摩擦力变化等因素,都会让仿真中"完美"的动作在真机上变得不可执行。这不是简单的参数调优能解决的问题,而是需要一套系统性的从仿真到现实(sim-to-real)的迁移方案。
3. 整体架构:两阶段流水线设计

FRoM-W1 的设计哲学可以用一句话概括:先让模型"会生成"人体动作,再让机器人"站得稳"地执行。整个系统被拆分为两个阶段,分别对应两个核心模块。
第一阶段是 H-GPT(Human-GPT),负责将自然语言指令转化为人体全身动作序列。这里的关键洞察是:虽然大规模的"语言-机器人动作"配对数据不存在,但"语言-人体动作"的配对数据是有的——来自动作捕捉和视频数据集(如 HumanML3D、Motion-X、AMASS)。人形机器人与人体在形态上的相似性,使得"先生成人体动作,再迁移到机器人"成为一条可行的技术路线。
第二阶段是 H-ACT(Human-ACTion),负责将 H-GPT 生成的人体动作迁移到具体的机器人平台上,并通过强化学习训练的控制策略确保动作在真实物理环境中稳定执行。H-ACT 包含三个子模块:运动重定向(retargeting)、基于强化学习的运动控制器(预训练+微调)、以及模块化的 sim-to-real 部署框架。
用数学语言表达,整个流水线可以写成:
Π ( I ) = A H-ACT ( G H-GPT ( I ) ) \Pi(I) = \mathcal{A}_{\text{H-ACT}}(\mathcal{G}_{\text{H-GPT}}(I)) Π(I)=AH-ACT(GH-GPT(I))
其中 I I I 是自然语言指令, G H-GPT \mathcal{G}_{\text{H-GPT}} GH-GPT 将指令映射为人体动作序列 M h M_h Mh, A H-ACT \mathcal{A}_{\text{H-ACT}} AH-ACT 再将人体动作映射为机器人可执行的动作 A r A_r Ar。
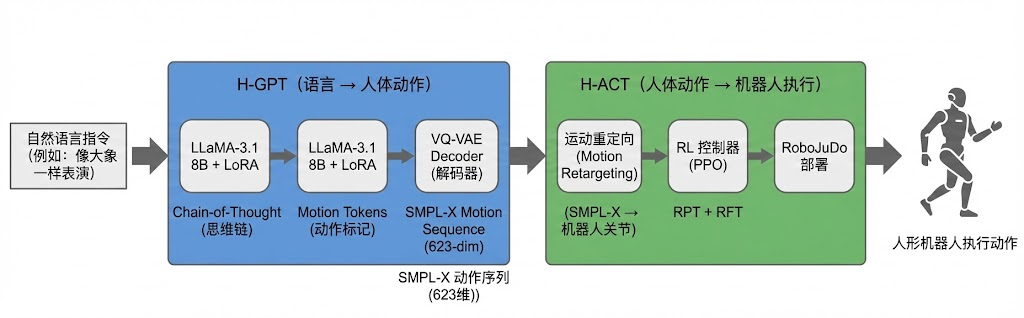
4. H-GPT:从语言到全身动作的生成模型
4.1 数据增强:用 CoT 弥合语义鸿沟
H-GPT 面临的第一个问题是训练数据中指令空间的狭窄。现有数据集中的文本描述大多是简单直白的动作描述,比如"向前走"、“举起双手”。但真实场景中的指令往往是抽象的、开放的,比如"扮演一头大象"或"表演一段太极拳"。
为了弥合这个差距,研究团队引入了链式思考(Chain-of-Thought, CoT)机制。具体做法是:利用 GPT-4o 对原始数据集中的每条指令生成一段结构化的"动作分镜"——将抽象指令拆解为带时间顺序的具体动作描述。例如,“扮演一头大象"可能被拆解为"先弯腰前倾,然后缓慢摆动双臂模拟象鼻,同时迈出沉重的步伐”。
这样,原始的二元组数据 ( I , M h ) (I, M_h) (I,Mh) 被扩展为三元组 ( I , CoT , M h ) (I, \text{CoT}, M_h) (I,CoT,Mh)。在训练时,模型学习的是联合分布:
p ( M h , CoT ∣ I ) = p ( M h ∣ I , CoT ) ⋅ p ( CoT ∣ I ) p(M_h, \text{CoT} \mid I) = p(M_h \mid I, \text{CoT}) \cdot p(\text{CoT} \mid I) p(Mh,CoT∣I)=p(Mh∣I,CoT)⋅p(CoT∣I)
推理时,模型先根据指令生成 CoT,再根据 CoT 生成动作序列。CoT 充当了语言与动作之间的"语义中间层",让模型能够处理训练集中从未见过的抽象指令。
4.2 动作 Token 化:让动作像文字一样可建模
H-GPT 的第二个核心设计是将连续的人体动作序列离散化为"动作 token",使其能够与语言 token 在同一个序列模型中统一建模。这一步通过 VQ-VAE(向量量化变分自编码器)实现。
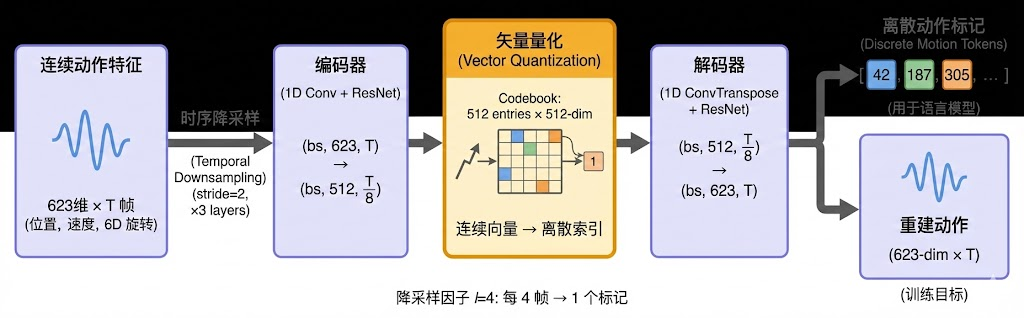
在 FRoM-W1 的代码实现中,VQ-VAE 的结构如下:
class VQVae(nn.Module):
def __init__(self, nfeats, quantizer, code_num, code_dim,
output_emb_width, down_t, stride_t, width,
depth, dilation_growth_rate, norm, activation, **kwargs):
super().__init__()
self.code_dim = code_dim
# 编码器:将连续动作特征下采样为潜在表示
self.encoder = Encoder(nfeats, output_emb_width, down_t, stride_t,
width, depth, dilation_growth_rate,
activation=activation, norm=norm)
# 解码器:从量化后的潜在表示重建动作序列
self.decoder = Decoder(nfeats, output_emb_width, down_t, stride_t,
width, depth, dilation_growth_rate,
activation=activation, norm=norm)
# 量化器:将连续向量映射到离散码本
if quantizer == "ema_reset":
self.quantizer = QuantizeEMAReset(code_num, code_dim, mu=0.99)
elif quantizer == "orig":
self.quantizer = Quantizer(code_num, code_dim, beta=1.0)
def forward(self, features):
x_in = self.preprocess(features) # (bs, T, D) -> (bs, D, T)
x_encoder = self.encoder(x_in) # 编码
x_quantized, loss, perplexity = self.quantizer(x_encoder) # 量化
x_decoder = self.decoder(x_quantized) # 解码
x_out = self.postprocess(x_decoder) # (bs, D, T) -> (bs, T, D)
return x_out, loss, perplexity
def encode(self, features):
"""将连续动作编码为离散 token 索引"""
N, T, _ = features.shape
x_in = self.preprocess(features)
x_encoder = self.encoder(x_in)
x_encoder = self.postprocess(x_encoder)
x_encoder = x_encoder.contiguous().view(-1, x_encoder.shape[-1])
code_idx = self.quantizer.quantize(x_encoder)
code_idx = code_idx.view(N, -1)
return code_idx, None
def decode(self, z):
"""将离散 token 索引解码回连续动作序列"""
x_d = self.quantizer.dequantize(z)
x_d = x_d.view(1, -1, self.code_dim).permute(0, 2, 1).contiguous()
x_decoder = self.decoder(x_d)
x_out = self.postprocess(x_decoder)
return x_out
这段代码揭示了动作 token 化的完整流程:编码器对输入的 623 维全身动作特征(包含位置、速度和 6D 旋转表示)进行时空下采样,量化器将连续的潜在向量映射到一个包含 512 个码字的离散码本中,解码器则负责从离散 token 重建原始动作。时间下采样因子 l = 4 l=4 l=4,意味着每 4 帧动作被压缩为 1 个 token。
这里使用 SMPL-X 格式表示全身动作,这是一种包含身体和手部的标准人体参数化模型。相比只有身体的 SMPL 格式,SMPL-X 额外编码了手指的精细运动,使得生成的动作不仅是"腿在走",而是"全身在表演"。
4.3 语言模型:基于 LLaMA 的自回归动作生成器
有了离散的动作 token,下一步就是训练一个能够根据文本指令自回归生成这些 token 的语言模型。H-GPT 的生成器基于 LLaMA-3.1 8B 模型,通过扩展词表将动作 token 纳入语言模型的建模范围。
从代码中可以看到模型如何加载和配置:
class MLM(nn.Module):
def __init__(self, model_path, model_type, stage, new_token_type,
motion_codebook_size, framerate, down_t, predict_ratio,
inbetween_ratio, max_length, lora, quota_ratio, **kwargs):
super().__init__()
self.m_codebook_size = motion_codebook_size
# 加载预训练语言模型
self.tokenizer = AutoTokenizer.from_pretrained(model_path, legacy=True)
if model_type == "llama":
self.language_model = AutoModelForCausalLM.from_pretrained(
model_path, trust_remote_code=True)
self.lm_type = 'dec'
# 扩展词表:添加动作 token(motion_id_0 到 motion_id_511)
# 使语言 token 和动作 token 在同一序列中统一建模
扩展后的词表 V = V text ∪ V motion V = V_{\text{text}} \cup V_{\text{motion}} V=Vtext∪Vmotion,其中 V text V_{\text{text}} Vtext 是原始文本词表, V motion V_{\text{motion}} Vmotion 是 512 个新增的动作 token。训练时,模型处理的序列结构为:
[指令] I [链式思考] CoT [动作Token] C_hat
整个序列使用标准的语言建模目标(next-token prediction)进行训练。为了高效适配,模型采用 LoRA(Low-Rank Adaptation)微调策略,rank=32,scaling factor=16,dropout=0.05,仅在注意力层的线性投影上注入适配器,而 embedding 层和语言建模头保持全量可训练。
训练损失函数的实现体现了不同阶段的设计:
# 文件:H-GPT/hGPT/losses/hgpt.py
class GPTLosses(BaseLosses):
def __init__(self, cfg, stage, num_joints, **kwargs):
self.stage = stage
losses = []
params = {}
if stage == "vae":
# VQ-VAE 阶段:重建损失 + 速度损失 + 码本承诺损失
losses.append("recons_feature")
params['recons_feature'] = cfg.LOSS.LAMBDA_FEATURE
losses.append("recons_velocity")
params['recons_velocity'] = cfg.LOSS.LAMBDA_VELOCITY
losses.append("vq_commit")
params['vq_commit'] = cfg.LOSS.LAMBDA_COMMIT
elif stage in ["lm_pretrain", "lm_instruct"]:
# 语言模型阶段:直接使用 HuggingFace 的交叉熵损失
losses.append("gpt_loss")
params['gpt_loss'] = cfg.LOSS.LAMBDA_CLS
这段代码清晰地展示了 H-GPT 的三阶段训练策略:第一阶段训练 VQ-VAE 动作分词器,使用重建损失(L1/L2/SmoothL1 可选)、速度一致性损失和码本承诺损失的加权组合;第二阶段冻结 VQ-VAE,在动作 token 上预训练语言模型;第三阶段加入 CoT 数据进行指令微调。
推理时的流程在主模型中实现:
# 文件:H-GPT/hGPT/models/hgpt.py
class HumanoidGPT(BaseModel):
@torch.no_grad()
def val_t2m_forward(self, batch):
texts = batch["text"]
lengths = batch["m_length"]
# 第一步:语言模型自回归生成 CoT + 动作 token
outputs, cleaned_text = self.lm.generate_conditional(
texts, lengths=lengths, stage='test', cot=cot_ref, tasks=tasks)
# 第二步:将动作 token 通过 VQ-VAE 解码器还原为连续动作
for i in range(len(texts)):
outputs[i] = torch.clamp(outputs[i], 0,
self.hparams.codebook_size - 1)
if len(outputs[i]) > 1:
motion = self.vae.decode(outputs[i])
整个 H-GPT 的数据流可以概括为:自然语言指令输入 -> LLaMA 生成 CoT 文本 -> LLaMA 继续生成动作 token 序列 -> VQ-VAE 解码器将 token 还原为 623 维连续动作特征 -> 输出全身动作序列。
…详情请参照古月居

欢迎加入 MCP 技术社区!与志同道合者携手前行,一同解锁 MCP 技术的无限可能!
更多推荐

 3
3 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)