让文本生成模型具备多模态能力:BLIP-2如何架起视觉与语言的桥梁
在前两节中,我们深入探讨了视觉Transformer如何将图像转化为“视觉词汇”,以及CLIP如何在共享向量空间中对齐图文语义。这些技术虽然强大,但它们本质上是理解型模型——能够判断图像与文本是否匹配,但无法生成新的文本描述。
那么,有没有一种模型,既能看懂图像,又能像ChatGPT一样开口说话?答案是肯定的,这就是本节的主角——BLIP-2。
1 BLIP-2:跨越模态鸿沟
想象一下这个场景:你给AI发了一张日落下的跑车照片,然后问它“开这辆车需要多少钱?”它不仅准确描述了画面,还给出了“100万美元”的答案(下图)。这种跨模态对话能力正是BLIP-2的拿手好戏。

1.1 从零构建多模态模型?不,我们“借力使力”
如果从头训练一个能看懂图像又会说话的多模态模型,你需要:
-
数十亿级别的图像-文本配对数据
-
海量的计算资源(GPU集群跑上几个月)
-
深厚的技术积累和工程能力
这对绝大多数团队来说都是不现实的。BLIP-2的论文作者们提出了一个巧妙的解决方案:与其重新发明轮子,不如把现有的优秀轮子连接起来。
他们的思路是:
-
保留预训练视觉编码器(如ViT)——它已经学会了提取图像特征。
-
保留预训练大语言模型(如OPT、T5)——它已经学会了理解和生成语言。
-
设计一个轻量级的桥梁模块,让视觉信息能够顺畅地传递给语言模型。
这个桥梁模块就是Q-Former(Querying Transformer),如下图所示,它是整个系统中唯一需要训练的部分。
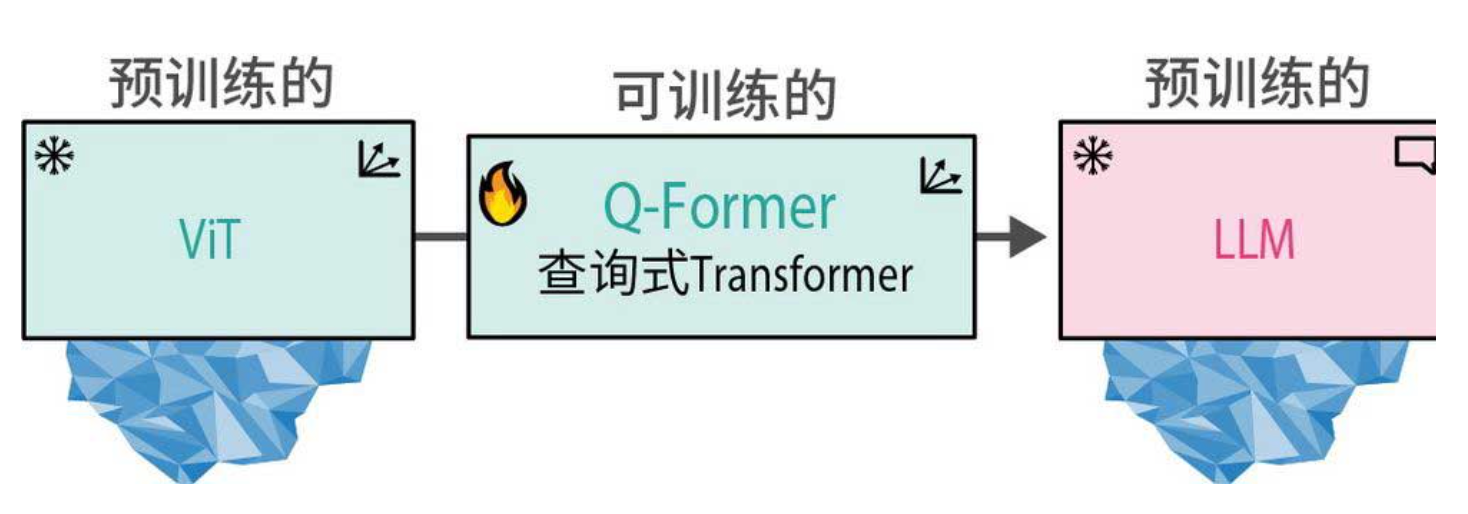
1.2 Q-Former:双Transformer的巧妙融合
Q-Former包含两个共享注意力层的子模块:
-
图像Transformer:与冻结的ViT交互,从图像中提取关键视觉特征。
-
文本Transformer:负责处理文本输入,并与后续的LLM对接。
这两个模块通过共享的自注意力层进行信息交换,使得视觉和文本信息能够在同一空间中进行交互。
1.3 两阶段训练:从对齐到生成
BLIP-2的训练分为两个阶段,如下图所示:
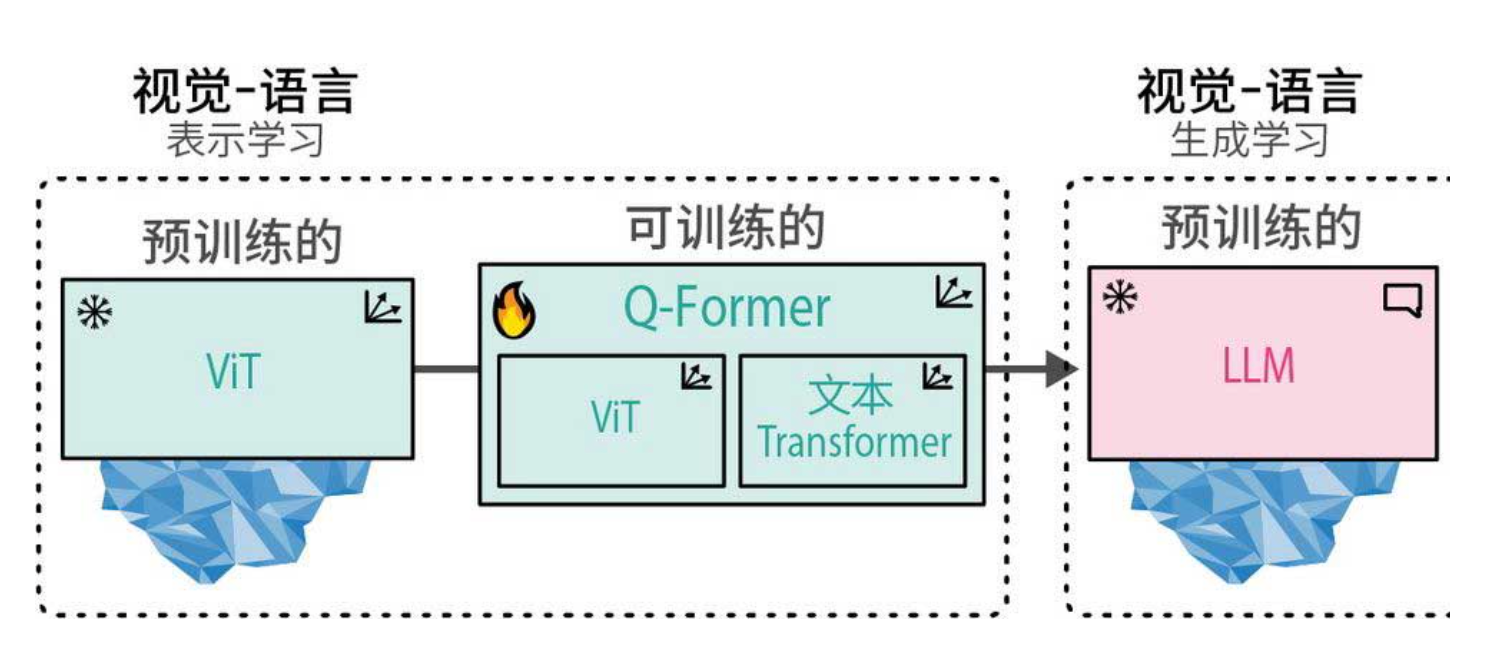
阶段一:视觉-语言表示学习
这个阶段的目标是让Q-Former学会将图像特征转化为语言模型能够理解的表示。训练数据是图像-文本对(类似CLIP使用的数据),Q-Former需要同时完成三个任务:
-
图像-文本对比学习:拉近匹配图文对的嵌入距离,推远不匹配对的嵌入距离(与CLIP类似)。
-
图像-文本匹配:二分类任务,判断给定图文对是否匹配。
-
基于图像的文本生成:给定图像,生成对应的文本描述(例如,“一只在雪地里玩耍的小狗”)。
这三个任务联合优化,迫使Q-Former从冻结的ViT中提取出与语言最相关的视觉信息,同时将这些信息映射到语言模型的表示空间中。
阶段二:视觉-语言生成学习
第二阶段的目标是让Q-Former学会生成能够引导LLM的“软视觉提示词”。此时,冻结的LLM被引入,Q-Former的输出经过一个线性投影层后,作为前缀提示词输入LLM(下图)。
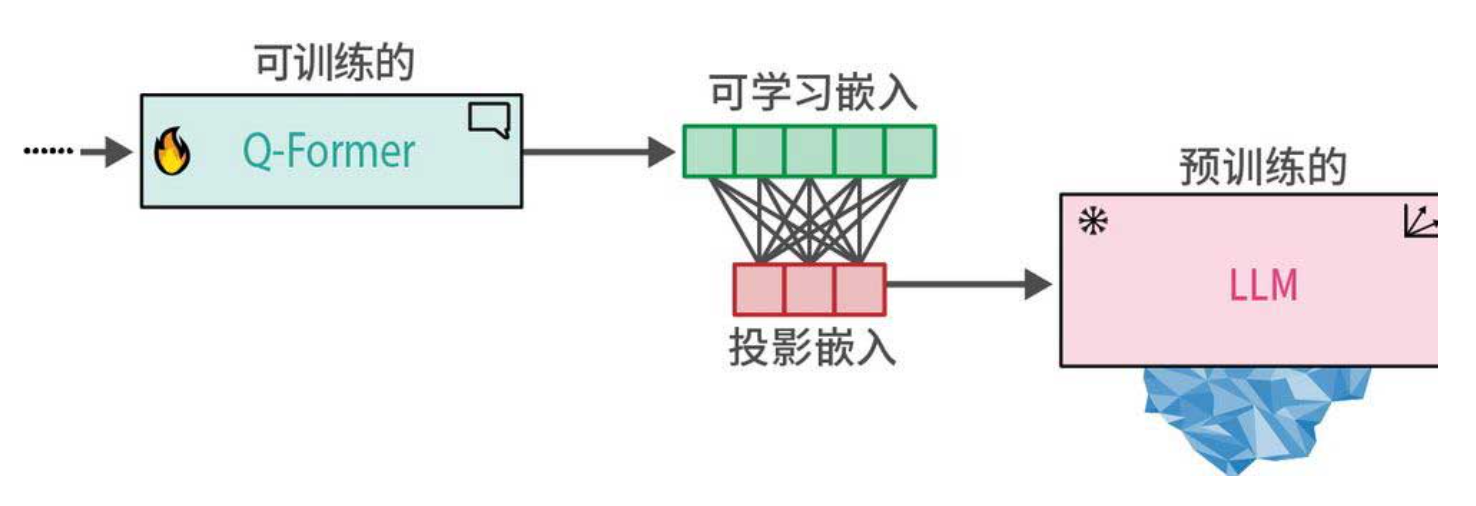
为什么叫“软视觉提示词”?因为传统的提示词是离散的文本词元,而这里的提示词是连续的向量,它们由图像内容动态生成,能够引导LLM关注图像中的关键信息。
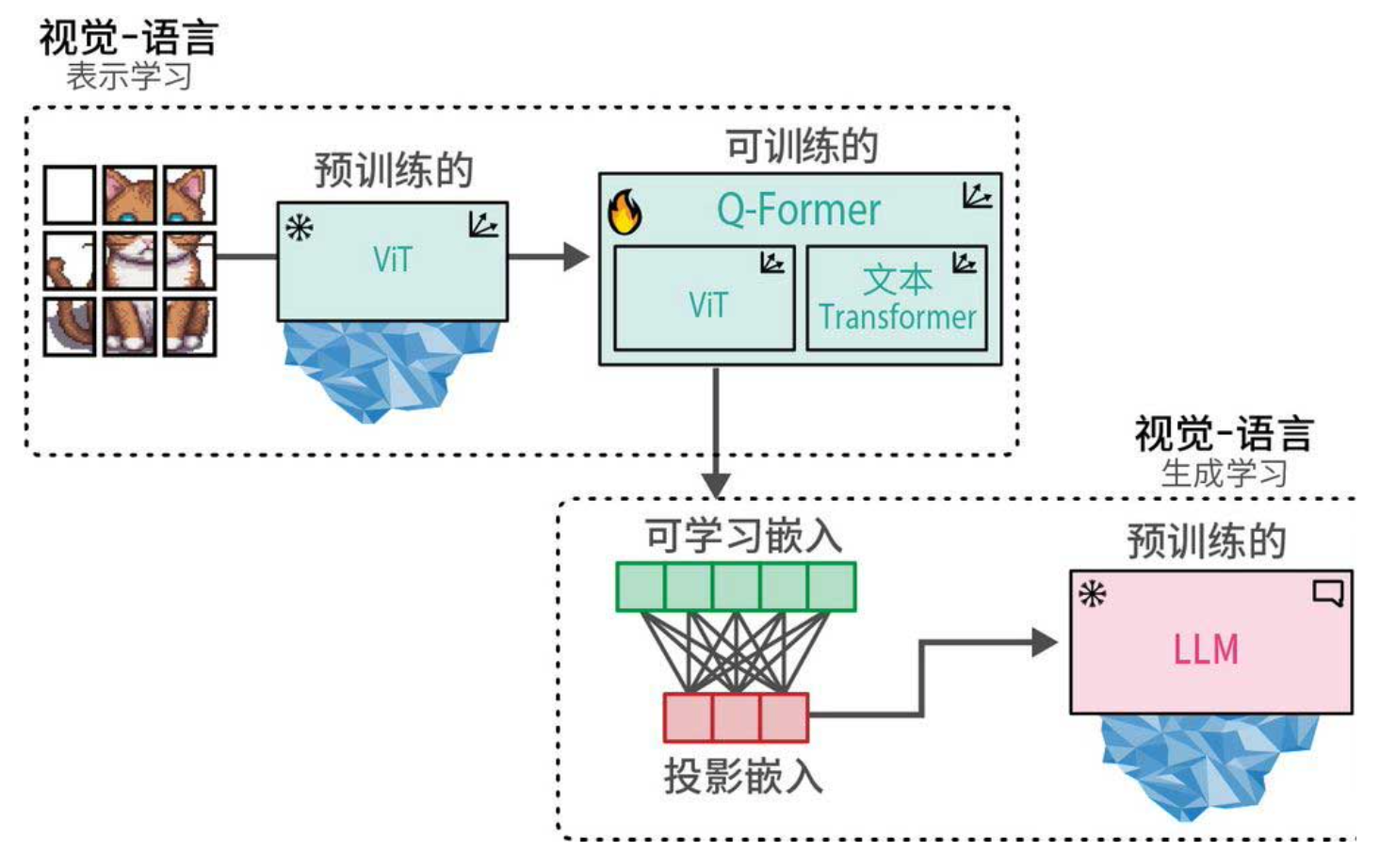
经过这两个阶段的训练,BLIP-2就能像下图那样完整工作了:图像经过ViT和Q-Former,生成视觉提示词,然后与文本提示词一起输入LLM,最终生成符合图像内容的文本回复。
2 动手实践:使用BLIP-2进行图像描述和视觉问答
理论讲完了,让我们用代码亲身体验BLIP-2的强大。我们将使用Hugging Face的Transformers库加载BLIP-2模型,并完成两个典型任务:图像描述和视觉问答。
2.1 环境准备与模型加载
python
from transformers import AutoProcessor, Blip2ForConditionalGeneration
import torch
from PIL import Image
import urllib.request
# 加载处理器和模型
blip_processor = AutoProcessor.from_pretrained("Salesforce/blip2-opt-2.7b")
model = Blip2ForConditionalGeneration.from_pretrained(
"Salesforce/blip2-opt-2.7b",
torch_dtype=torch.float16
)
# 将模型移至GPU(如果可用)
device = "cuda" if torch.cuda.is_available() else "cpu"
model.to(device)
2.2 图像预处理:从原始图像到模型输入
我们以一张AI生成的跑车图像为例(下图风格类似):

python
car_url = "https://raw.githubusercontent.com/HandsOnLLM/Hands-On-Large-Language-Models/main/chapter09/images/car.png"
image = Image.open(urllib.request.urlopen(car_url)).convert("RGB")
# 预处理图像
inputs = blip_processor(image, return_tensors="pt").to(device, torch.float16)
print(inputs["pixel_values"].shape) # torch.Size([1, 3, 224, 224])
处理器会自动将任意尺寸的图像调整为224×224的正方形,同时保持RGB三通道。
2.3 用例1:图像描述
让模型用一句话描述图像内容:
python
# 生成图像描述 generated_ids = model.generate(**inputs, max_new_tokens=20) generated_text = blip_processor.batch_decode(generated_ids, skip_special_tokens=True)[0].strip() print(generated_text)
输出:
text
an orange supercar driving on the road at sunset
完美!模型准确地捕捉到了“橙色超跑”、“日落”、“行驶”等关键元素。
尝试其他图像:你也可以用罗夏墨迹测验的图像(下图)试试:
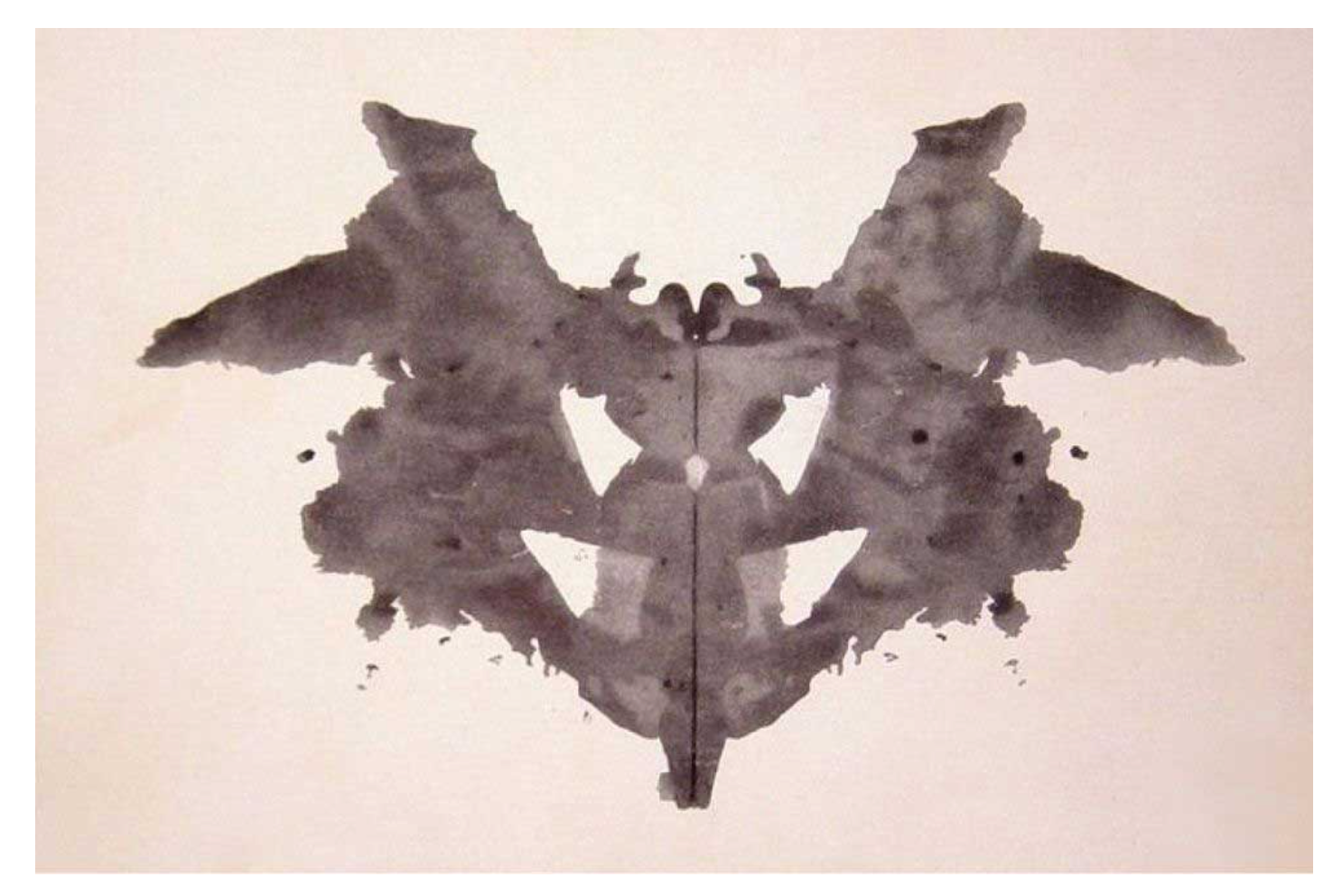
python
url = "https://upload.wikimedia.org/wikipedia/commons/7/70/Rorschach_blot_01.jpg"
image = Image.open(urllib.request.urlopen(url)).convert("RGB")
inputs = blip_processor(image, return_tensors="pt").to(device, torch.float16)
generated_ids = model.generate(**inputs, max_new_tokens=20)
generated_text = blip_processor.batch_decode(generated_ids, skip_special_tokens=True)[0].strip()
print(generated_text)
输出:
text
a black and white ink drawing of a bat
模型将墨迹解读为“蝙蝠”,这恰好是常见的心理学解释之一。
2.4 用例2:视觉问答(VQA)
图像描述只是基础,我们更想要的是与图像相关的对话。这需要同时输入图像和问题文本。
python
# 定义问题和图像 prompt = "Question: Write down what you see in this picture. Answer:" inputs = blip_processor(image, text=prompt, return_tensors="pt").to(device, torch.float16) generated_ids = model.generate(**inputs, max_new_tokens=30) generated_text = blip_processor.batch_decode(generated_ids, skip_special_tokens=True)[0].strip() print(generated_text)
输出:
text
A sports car driving on the road at sunset
模型准确回答了问题。接下来我们可以进行多轮对话:
python
# 包含历史对话的提示
prompt = ("Question: Write down what you see in this picture. Answer: A sports car driving on the road at sunset. "
"Question: What would it cost me to drive that car? Answer:")
inputs = blip_processor(image, text=prompt, return_tensors="pt").to(device, torch.float16)
generated_ids = model.generate(**inputs, max_new_tokens=30)
generated_text = blip_processor.batch_decode(generated_ids, skip_special_tokens=True)[0].strip()
print(generated_text)
输出:
text
$1,000,000
模型给出了一个具体的数字——100万美元!虽然这个答案可能源于训练数据中的某种关联,但足以展示模型具备多轮对话的潜力。
2.5 进阶:构建一个简单的多模态聊天机器人
利用ipywidgets,我们可以快速搭建一个交互式聊天界面:
python
from IPython.display import HTML, display
import ipywidgets as widgets
def text_eventhandler(change):
question = change["new"]
if not question:
return
change["owner"].value = ""
# 构造带历史对话的提示
if not memory:
prompt = f"Question: {question} Answer:"
else:
history = " ".join([f"Question: {q} Answer: {a}." for q, a in memory])
prompt = history + f" Question: {question} Answer:"
inputs = blip_processor(image, text=prompt, return_tensors="pt").to(device, torch.float16)
generated_ids = model.generate(**inputs, max_new_tokens=100)
generated_text = blip_processor.batch_decode(generated_ids, skip_special_tokens=True)[0].strip()
# 截取第一个回答(可能包含后续问题)
answer = generated_text.split("Question")[0].strip()
memory.append((question, answer))
with output:
display(HTML(f"<b>USER:</b> {question}"))
display(HTML(f"<b>BLIP-2:</b> {answer}"))
display(HTML("<br>"))
# 初始化
memory = []
in_text = widgets.Text(placeholder="Ask something about the image...")
in_text.continuous_update = False
in_text.observe(text_eventhandler, "value")
output = widgets.Output()
display(widgets.VBox([output, in_text]))
运行后,你可以像下面这样与模型对话:
-
USER: Write down what you see in this picture.
-
BLIP-2: A sports car driving on the road at sunset.
-
USER: What would it cost me to drive that car?
-
BLIP-2: $1,000,000.
-
USER: Why that much money?
-
BLIP-2: Because it's a sports car.
-
USER: Why are sports cars expensive?
-
BLIP-2: Because they're fast.
虽然模型的回答有时略显简单,但它的确展现出了基于图像内容的连续对话能力。
3 小结
本章系统探讨了多模态大语言模型的核心技术与实现路径:
-
视觉Transformer(ViT)通过将图像分割为图像块并线性投影,实现了与文本Transformer统一的架构,为多模态处理奠定了基础。
-
CLIP利用对比学习在共享向量空间中对齐图像与文本,支持零样本分类、跨模态检索等任务,成为多模态理解的基石。
-
BLIP-2通过创新的Q-Former模块,巧妙连接冻结的视觉编码器和语言模型,仅需训练少量参数即可实现跨模态对话,大大降低了多模态模型的构建门槛。
从图像描述到视觉问答,再到多轮对话,BLIP-2展示了多模态LLM的巨大潜力。未来,随着更多模态(音频、视频)的加入和模型能力的提升,我们有望看到真正能够像人类一样“眼观六路、耳听八方”的通用智能助手。
本文参考:图解大模型:生成式AI原理与实战
书籍pdf免费下载地址:https://pan.baidu.com/s/1mTaUQ5czcfGpBM8KvJuS2g?pwd=un44

欢迎加入 MCP 技术社区!与志同道合者携手前行,一同解锁 MCP 技术的无限可能!
更多推荐



 10
10 0
0- 0



 已为社区贡献26条内容
已为社区贡献26条内容

所有评论(0)