基于高斯过程回归的时间序列区间预测
基于高斯过程回归(GPR)的时间序列区间预测
在现代数据分析中,时间序列预测是一个非常重要且热门的话题。无论是金融市场的波动分析,还是环境科学中的气候预测,又或者是医疗健康领域的病患监测,时间序列预测都扮演着不可或缺的角色。而在时间序列预测中,仅仅预测一个点值是远远不够的,因为实际数据中总是存在噪声和不确定性。因此,提供一个置信区间或预测区间就显得尤为重要。而高斯过程回归(Gaussian Process Regression, GPR)正是一个非常适合用于时间序列区间预测的方法。
高斯过程回归简介
高斯过程回归是一种非参数化的贝叶斯方法,它通过定义一个先验分布来建模函数空间中的函数。与传统的参数化方法不同,GPR不需要预先指定函数的形式,而是通过数据来推断函数的后验分布。这种特性使得GPR在处理小样本数据和复杂非线性关系时表现尤为出色。
基于高斯过程回归(GPR)的时间序列区间预测
在数学上,高斯过程可以被看作是一个随机过程,其中任意有限个点的分布都是多元高斯分布。具体来说,假设我们有一个输入变量x,输出变量y遵循y = f(x) + ε,其中f(x)是未知的函数,ε是高斯噪声。GPR通过最大化后验概率的方式推断f(x)的后验分布,并利用这个分布来进行预测。
时间序列区间预测的挑战
时间序列数据具有时序特性和相关性,这意味着相邻时刻的观测值往往是高度相关的。这种特性使得时间序列预测比独立的回归任务更为复杂。此外,时间序列中的噪声可能受到多种因素的影响,如数据采集误差、外部干扰等,这些都会影响预测的准确性。
在时间序列预测中,区间预测的关键在于不仅要预测未来的值,还要估计预测值的不确定性。这通常涉及到对预测分布的估计,而高斯过程天然地提供了这种估计的能力,因为它可以给出预测值的均值和方差。
代码实现与分析
为了更好地理解GPR在时间序列区间预测中的应用,我们通过一个简单的例子来进行说明。这里我们使用Python的Scikit-learn库来实现GPR模型,并使用一个模拟的时间序列数据集来进行训练和预测。
数据准备
首先,我们需要生成一个具有趋势和周期性的模拟时间序列数据。我们使用numpy生成等间隔的时间点,并引入线性趋势和正弦波动,再加上高斯噪声。
import numpy as np
import matplotlib.pyplot as plt
# 设置随机种子以确保结果可重复
np.random.seed(42)
# 生成时间序列数据
n_samples = 100
time = np.linspace(0, 10, n_samples)
# 定义真实函数:线性趋势 + 正弦波动
trend = 0.5 * time
seasonality = 0.5 * np.sin(time * 3)
y = trend + seasonality + np.random.normal(0, 0.3, n_samples)
# 可视化数据
plt.figure(figsize=(10, 6))
plt.plot(time, y, 'b.', markersize=10)
plt.xlabel('Time')
plt.ylabel('Value')
plt.title('Simulated Time Series Data')
plt.grid(True)
plt.show()核心代码实现
接下来,我们使用Scikit-learn的GaussianProcessRegressor来拟合数据,并进行预测。GPR的核心在于选择合适的核函数(kernel)。这里我们选择一个径向基函数(RBF)核,因为它能够有效地捕捉时间序列中的周期性和趋势。
from sklearn.gaussian_process import GaussianProcessRegressor
from sklearn.gaussian_process.kernels import RBF, ConstantKernel
# 定义核函数
kernel = ConstantKernel(0.5) * RBF(length_scale=1)
# 实例化GPR模型
gpr = GaussianProcessRegressor(kernel=kernel, alpha=0.3, n_restarts_optimizer=10)
# 拟合模型
gpr.fit(time.reshape(-1, 1), y)
# 生成预测
time_predict = np.linspace(0, 10, 500).reshape(-1, 1)
y_predict, std = gpr.predict(time_predict, return_std=True)
# 构建预测区间
confidence = 0.95
z = 1.96 # 对应95%置信区间
lower = y_predict - z * std
upper = y_predict + z * std可视化结果
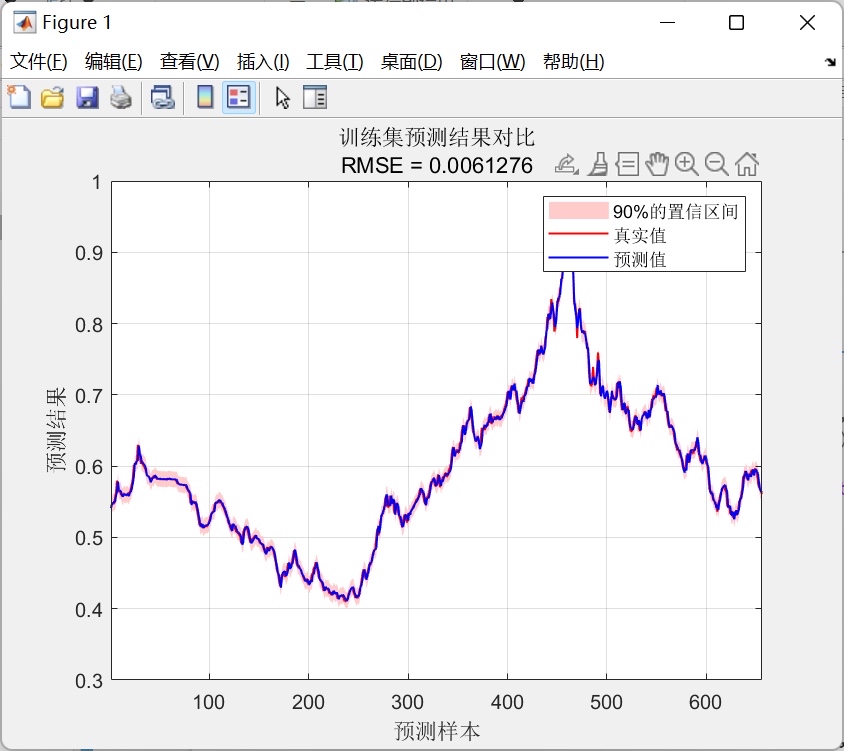
最后,我们来可视化拟合结果和预测区间。
# 绘制实际数据和预测曲线
plt.figure(figsize=(10, 6))
plt.plot(time, y, 'b.', markersize=10, label='Observations')
plt.plot(time_predict, y_predict, 'r-', label='Prediction')
plt.fill_between(time_predict.flatten(), lower, upper, color='gray', alpha=0.2, label=f'{confidence*100}% Confidence Interval')
plt.xlabel('Time')
plt.ylabel('Value')
plt.title('GPR for Time Series Interval Prediction')
plt.legend()
plt.grid(True)
plt.show()分析与讨论
从上述代码和结果来看,GPR在时间序列区间预测中表现良好。具体来说:
- 核函数的选择:在这里我们使用了径向基函数(RBF)核,它能够很好地捕捉时间序列中的周期性和趋势。核函数的选择在GPR中非常重要,不同的核函数适用于不同的数据特征。
- 超参数优化:在GPR中,模型的性能高度依赖于核函数的参数。通过
nrestartsoptimizer参数,我们可以让模型多次优化这些参数,以找到全局最优解。
- 置信区间:GPR不仅给出了预测值的均值,还给出了预测值的标准差。基于正态分布的性质,我们可以通过标准差构建置信区间。在代码中,我们选择了95%的置信水平,对应的z值为1.96。
- 计算复杂度:GPR的时间复杂度为O(n³),其中n是数据点的数量。这对于大数据集来说是一个挑战,但在本例中数据量较小,因此GPR表现良好。
总结
基于高斯过程回归的时间序列区间预测是一种强大的方法,它不仅能够提供点预测,还能给出预测值的不确定性范围。通过选择合适的核函数和优化超参数,GPR能够在复杂的时间序列数据中表现出色。然而,需要注意的是,GPR的计算复杂度较高,这在处理大数据集时可能成为一个瓶颈。此外,GPR对先验假设(如核函数的选择)有一定的依赖性,如果核函数选择不当,可能会影响预测效果。因此,在实际应用中,需要结合具体问题进行模型选择和优化。

欢迎加入 MCP 技术社区!与志同道合者携手前行,一同解锁 MCP 技术的无限可能!
更多推荐
 2
2 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)