从 0 到 1 搭建企业级 RAG 知识库系统(基于 RAGFlow 框架)
从 0 到 1 搭建企业级 RAG 知识库系统(基于 RAGFlow 框架)
2026 最新实战:RAGFlow v0.25.6 已从纯 RAG 引擎进化为 Agentic RAG 平台。本文从架构到落地,完整走通企业级知识库搭建全流程。
一、为什么选 RAGFlow?
2026 年的 RAG 开源格局中,RAGFlow 是唯一在"文档深度理解"和"Agent 编排"两个维度同时做到生产级水准的项目。
| 对比维度 | RAGFlow | Dify | LangChain |
|---|---|---|---|
| 文档解析 | 10+ 种智能模板,不依赖 OCR | 基础解析 | 需自行集成 |
| 分块策略 | 自适应 + 父子分块 | 固定长度 | 完全手动 |
| Agent | 画布编排 + MCP + 沙盒执行 | 画布编排 | 纯代码 |
| 检索模式 | 混合检索 + GraphRAG + Ψ-RAG | 向量检索 | 自由组合 |
| 部署门槛 | Docker 一行命令 | Docker 一行命令 | 需大量开发 |
| 核心语言 | Python | Python | Python/JS |
选型结论:如果你的文档格式复杂(PDF/Word/PPT/扫描件)、需要企业级权限和审计、或者想一句话查询数据库——RAGFlow 是 2026 年最成熟的开源选择。
二、核心架构一览
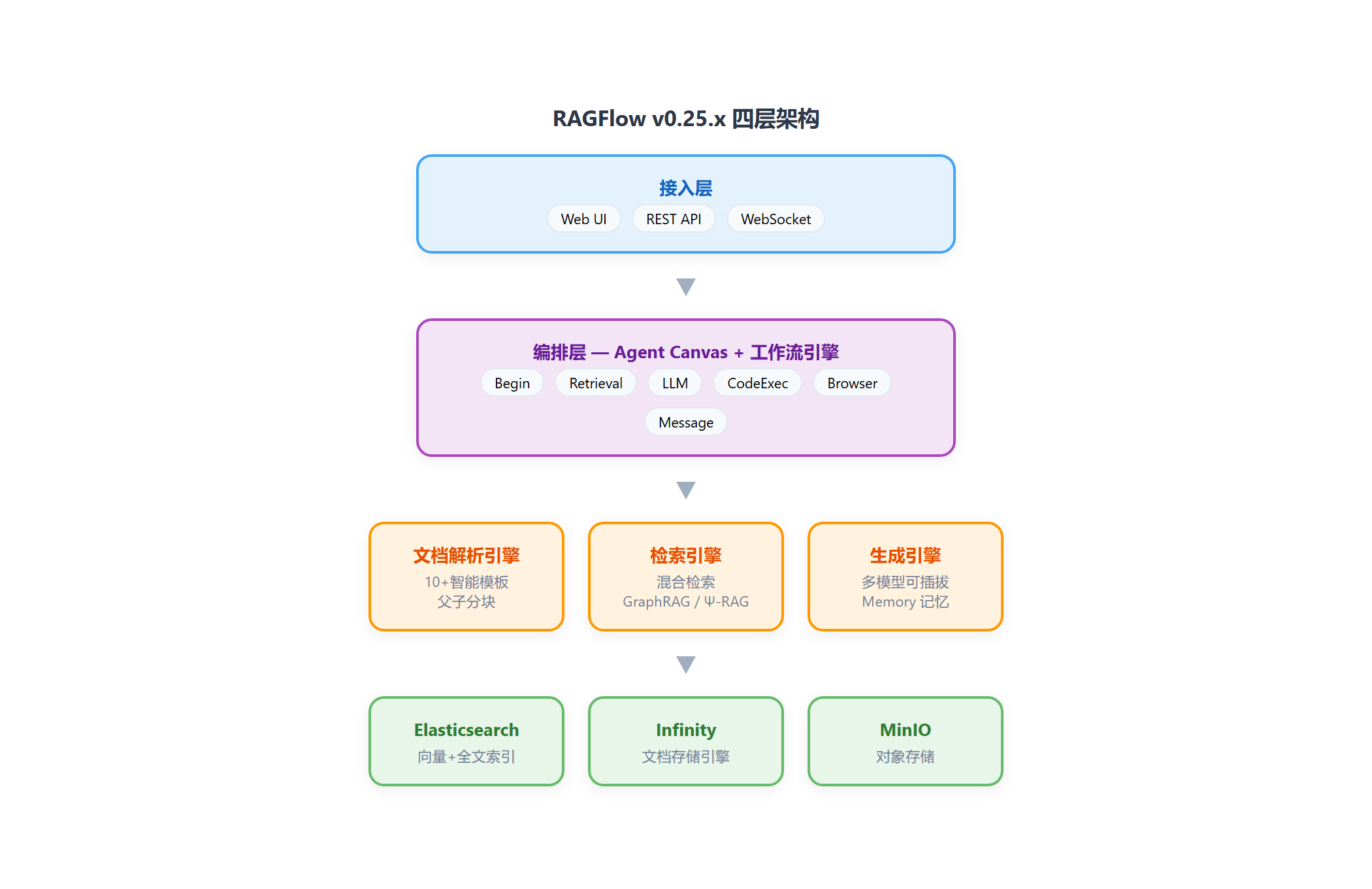
RAGFlow v0.25.x 架构分为四层:
| 层级 | 组件 | 职责 |
|---|---|---|
| 接入层 | Web UI + REST API + WebSocket | 用户交互、API 调用 |
| 编排层 | Agent Canvas + 工作流引擎 | 可视化编排检索-生成链路 |
| 引擎层 | 文档解析引擎 + 检索引擎 + 生成引擎 | 核心 RAG 能力 |
| 存储层 | Elasticsearch + Infinity/Infinity + MinIO | 向量/全文索引、文档存储 |
深度文档理解 — RAGFlow 的护城河
RAG 系统效果 70% 取决于文档解析质量。RAGFlow 的 rag 模块从 PDF/docx 中提取的不是单纯的文本,而是 结构化知识单元:
- 标题层级:自动识别 H1-H6,构建文档目录树
- 表格语义:"第三行第二列的数值是 42.5"级别的理解
- 图片关联:图文混排时,图片说明与正文对齐
- 元数据提取:作者、创建时间、关键词自动标注
v0.25.0 新增了 Lazy-load 图片支持(DOCX/Excel),大文档解析性能提升明显。
三、环境准备
硬件要求
| 场景 | CPU | 内存 | 存储 |
|---|---|---|---|
| 开发测试 | 4 核 | 16GB | 50GB |
| 生产环境 | 8 核+ | 32GB+ | NVMe 200GB+ |
| 大规模生产 | 16 核+ | 64GB+ | 500GB+ |
关键提醒:内存是硬门槛。低于 16GB Elasticsearch 可能起不来,RAG 流程直接卡死。
软件要求
# 系统推荐 Ubuntu 22.04 LTS
# Docker ≥ 24.0.0
docker --version # 需要 24.0+
docker compose version # 需要 v2.26.1+
四、快速部署(Docker Compose)
Step 1:内核参数
# 必须!否则 ES 启动失败
sudo sysctl -w vm.max_map_count=262144
echo "vm.max_map_count=262144" | sudo tee -a /etc/sysctl.conf
Step 2:克隆并启动
cd /opt
git clone https://github.com/infiniflow/ragflow.git
cd ragflow/docker
git checkout -f v0.25.6 # 2026-05-26 最新稳定版
# CPU 环境
docker compose -f docker-compose.yml up -d
# GPU 环境(在 .env 中先设置 DEVICE=gpu)
docker compose -f docker-compose-gpu.yml up -d
Step 3:验证
docker logs -f docker-ragflow-server-1
# 看到 RAGFlow ASCII 大 Logo 即启动成功
浏览器访问 http://服务器IP:80,首次进入直接注册管理员。
端口和配置
修改 .env 文件调整端口:
SVR_WEB_HTTP_PORT=8080 # 默认 80
SVR_WEB_HTTPS_PORT=8443
修改后 docker compose down && docker compose up -d 重启生效。
五、模型接入
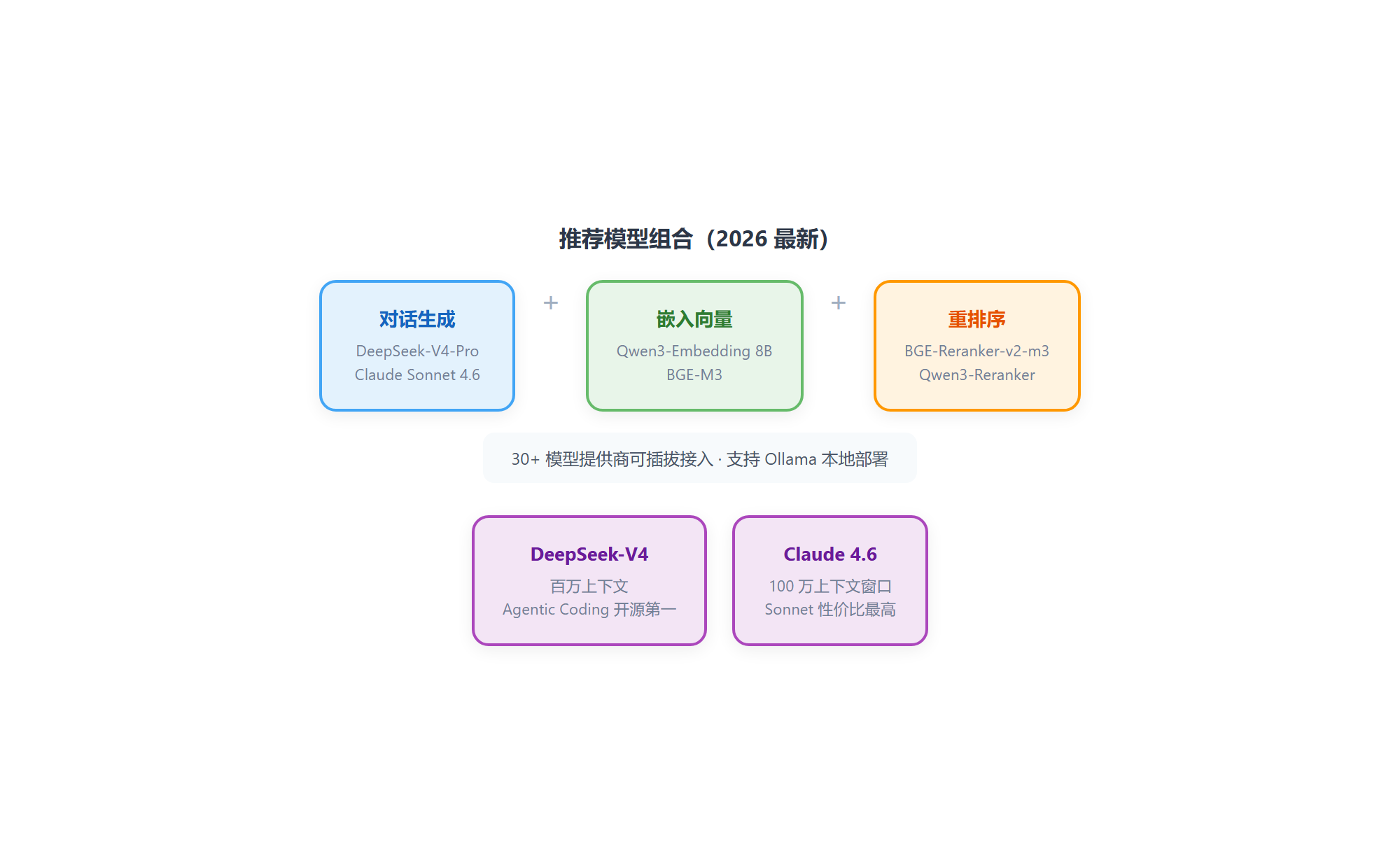
RAGFlow 的模型层是 可插拔架构,v0.25.x 支持的模型提供商超过 30 家。
推荐模型组合(2026 最新)
| 用途 | 首选 | 备选 | 选型理由 |
|---|---|---|---|
| 对话生成 | DeepSeek-V4-Pro | Claude Opus 4.6 / Sonnet 4.6 | V4 百万上下文,Agentic Coding 开源第一 |
| 嵌入向量 | Qwen3-Embedding 8B | BGE-M3 | Qwen3 MTEB 多语言榜首;BGE-M3 混合检索成熟 |
| 重排序 | BGE-Reranker-v2-m3 | Qwen3-Reranker 8B | BGE 中文生态成熟;Qwen3 多语言最强 |
| 语音 | 内置 ASR/TTS | — | v0.25.x 已集成中英混合识别 |
模型选型详解
对话模型:
DeepSeek-V4 于 2026 年 4 月发布,分 V4-Pro(1.6T MoE / 49B 激活)和 V4-Flash(284B / 13B 激活),均支持 100 万 tokens 上下文。V4-Pro 在 Agentic Coding 评测中开源第一,LiveCodeBench 得分 93.5 Pass@1,超过 Gemini 3.1 Pro(91.7)。API 输入 $1.74/百万 tokens。
Claude Opus 4.6 / Sonnet 4.6(2026 年 2 月发布)同样支持 100 万上下文窗口。Sonnet 4.6 在 SWE-bench 上得分 79.6%,价格仅为 Opus 的 60%($3/$15 每百万 tokens),日常使用性价比最高。
嵌入模型:
2026 年中文 RAG 嵌入模型格局已变——Qwen3-Embedding 8B 以 70.58 分登顶 MTEB 多语言排行榜,支持 32K 上下文和可变维度(32-4096)。但在实际生产环境中,BGE-M3(568M 参数)凭借独特的"密集 + 稀疏(BM25) + 多向量(ColBERT)"三合一混合检索能力,仍是中文 RAG 最成熟的选择。两者选型建议:
- 追求极致精度,有 A100 显卡 → Qwen3-Embedding 8B
- 中文场景、资源有限、需要混合检索 → BGE-M3
- 纯中文短文本、最轻量 → bge-large-zh-v1.5
重排序模型:
BGE-Reranker-v2-m3 是当前生产环境的事实标准(568M,MIRACL 69.32 分)。Qwen3-Reranker 8B 在 MTEB 多语言基准上更强,但参数大 14 倍,部署成本更高。一般场景 BGE-Reranker-v2-m3 足够。
配置步骤
- 控制台 → 右上角头像 → 模型提供商
- 选择对应厂商,填入 API Key
- 设置系统默认模型
如果使用本地 Ollama:
ollama pull qwen3:8b # 对话模型
ollama pull bge-m3 # 嵌入模型(推荐)
ollama pull bge-large-zh-v1.5 # 嵌入模型(轻量备选)
然后在 RAGFlow 中配置 Ollama 地址:http://宿主机IP:11434
六、知识库构建全流程
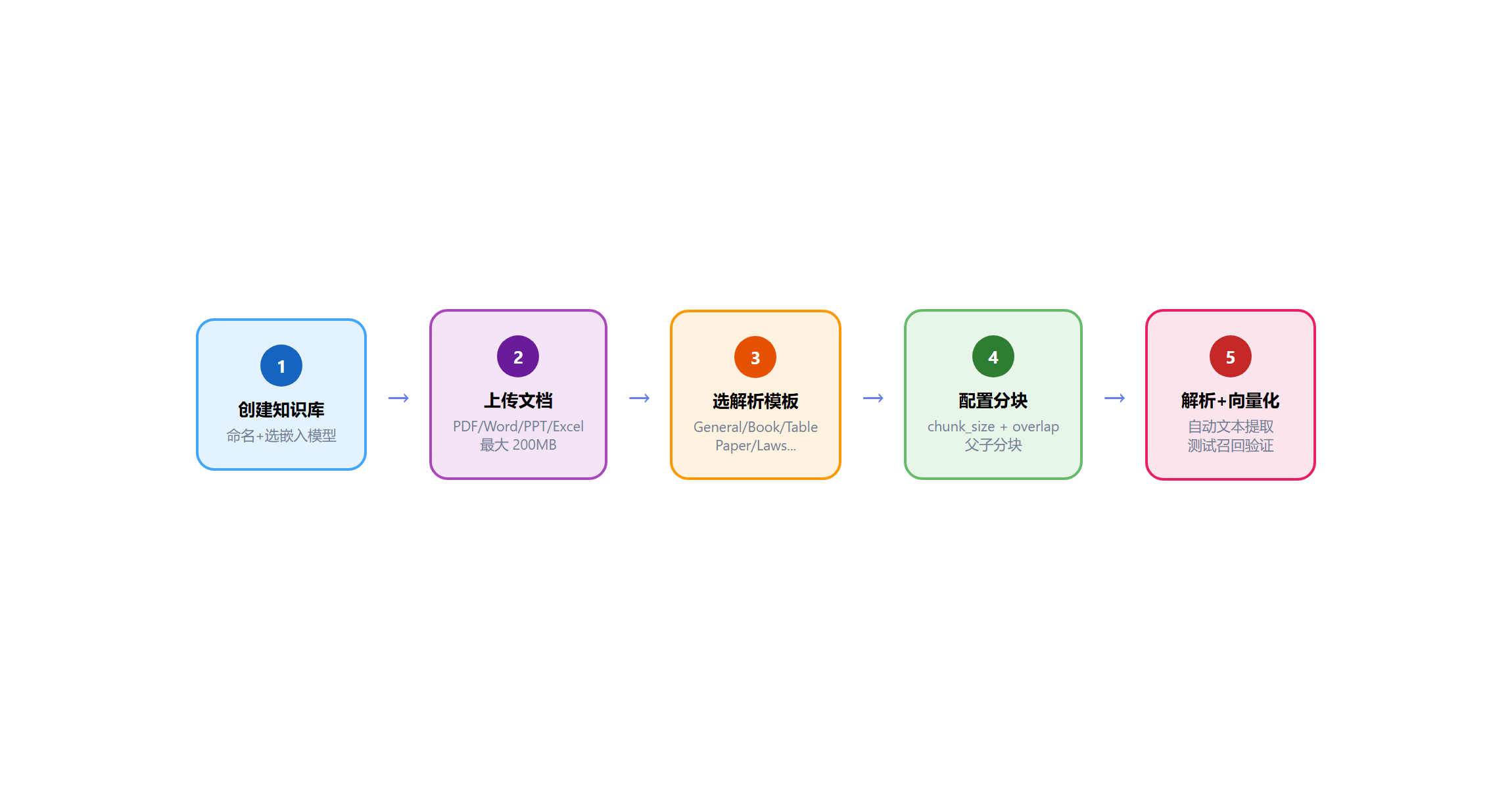
1. 创建知识库
知识库 → 新建知识库,命名、选择默认嵌入模型。
2. 上传文档
支持格式:PDF、Word、Excel、PPT、Markdown、HTML、图片(OCR)、邮件(IMAP 直连)、TXT。
v0.25.x 最大单文件支持 200MB(Infinity 引擎 v0.6.15)
3. 选择解析模板 — 这是最关键的一步
| 模板 | 适用场景 | 核心能力 |
|---|---|---|
| General | 通用文档 | 自动识别标题、段落、列表 |
| Q&A | FAQ 文档 | 自动识别问答对 |
| Table | 表格为主 | 保留行列结构 |
| Paper | 学术论文 | 识别章节、摘要、参考文献 |
| Book | 书籍/手册 | 章节级解析 + 目录树 |
| Laws | 法律合同 | 条款层级编号 |
| Manual | 技术手册 | 保留代码片段完整性 |
| Resume | 简历 | 结构化信息提取 |
| One | 短文档 | 整文档作为一个块 |
4. 分块策略
技术文档: chunk_size=1024, overlap=200
法律合同: chunk_size=256, overlap=64
通用文档: chunk_size=512, overlap=128
论文文献: chunk_size=768, overlap=150
v0.23.0 引入的 父子分块(Parent-Child Chunking):父块捕获章节上下文,子块用于精确检索。检索时先匹配子块,再带上父块扩充上下文。
5. 开始解析
点击 开始解析,系统自动完成:文本提取 → 分块 → 向量化 → 索引。解析完成后可 测试召回 验证效果。
混合检索配置
RAGFlow 默认开启混合检索(向量 + BM25 关键词):
{
"vector_similarity_weight": 0.3
}
向量权重 0.3 意味着关键词匹配占 70%。中文场景关键词检索往往比纯向量更准,建议保持默认。
七、构建智能问答助手
基础配置
- 聊天 → 新建助理
- 关联知识库
- 选择对话模型
- 配置 System Prompt(系统提示词):
你是一个企业知识库助手。严格遵循以下规则:
1. 仅基于知识库提供的文档内容回答问题
2. 如果知识库中没有相关信息,明确回答"该问题暂未收录"
3. 回答时引用具体文档名称和段落
4. 不要编造任何知识库中没有的数据、日期或结论
- 开启重排序(Rerank):检索结果二次筛选,Top-5 中有效片段命中率提升 20-40%
效果验证清单
- 上传 5-10 份典型文档,跑一轮完整问答
- 检查检索召回:关键问题是否命中正确文档
- 检查回答准确性:回答是否引用了正确来源
- 边界测试:问知识库外的问题,是否正确拒绝
八、Agentic RAG — RAGFlow 2026 最强能力
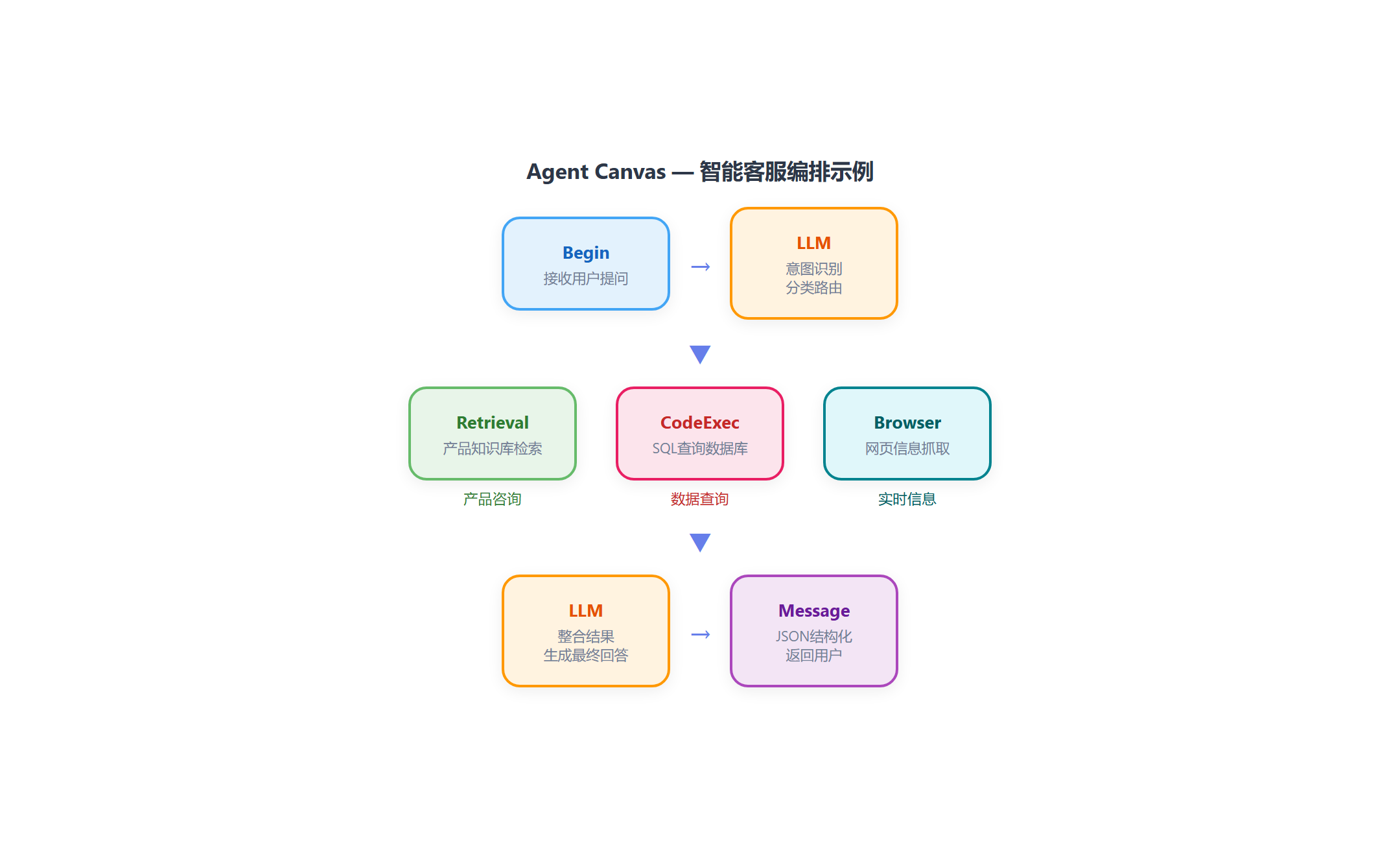
v0.25.x 的 Agent 已经是一个完整的智能体平台,不是 RAG 的附属功能。
Agent Canvas 画布
拖拽式编排,核心组件:
| 组件 | 功能 |
|---|---|
| Begin | 触发器,接收用户输入 |
| Retrieval | 知识库检索,可配置多个数据源 |
| LLM | 大模型推理,支持工具调用 |
| CodeExec | 沙盒代码执行(v0.25.x 新增) |
| Browser | 浏览器自动化(v0.25.6 新增) |
| Message | 输出结果,支持 JSON 结构化 |
实战场景:智能客服 Agent
用户提问 → Begin
├── [意图识别] LLM 判断问题类型
├── [产品咨询] Retrieval → LLM → Message
├── [数据查询] CodeExec(SQL) → LLM → Message
└── [人工转接] Message("正在为您转接...")
Memory 系统(v0.24.x+)
RAGFlow 支持 用户级记忆存储:
- L1 缓存:高频上下文片段,毫秒级访问
- L2 存储:完整对话历史,持久化保存
长对话场景检索效率提升 3 倍,内存占用降低 45%。
MCP 工具集成
支持 Model Context Protocol,Agent 可调用外部工具:
- 控制台 → MCP 服务器 → 添加端点
- 支持 SSE 和 Streamable-HTTP 协议
- Agent 画布中直接拖入 MCP 组件即可调用
九、高级检索:GraphRAG 与 Ψ-RAG
GraphRAG — 知识图谱增强检索
RAGFlow 自动从文档中抽取实体和关系,构建知识图谱:
- 实体类型:人物、组织、地点、产品、时间
- 关系类型:属于、创建、位于、依赖、导致
- 多跳推理:“谁负责了该项目中与某客户相关的部分?”
v0.25.x 优化了 GraphRAG 的批量嵌入,嵌入调用从 O(n) 优化为批处理(每批 16 个实体)。
Ψ-RAG(AHC 模式)
基于层次聚类的文档结构构建,从文档级语义扩展到数据集级语义。在 Recall@5 和平均 F1 上 超过传统 RAPTOR。
十、生产环境最佳实践
架构部署建议
| 组件 | 建议 |
|---|---|
| 负载均衡 | Nginx 反向代理 RAGFlow 多实例 |
| 向量数据库 | 大规模用 Milvus 替换内置 ES |
| 对象存储 | MinIO 持久化文档文件 |
| 日志监控 | Prometheus + Grafana |
| 备份 | 每日自动备份 ES 索引 + 文档存储 |
性能优化清单
- 单文档 ≤ 50MB,大文件拆分为多个小文件
- 开启重排序,Top-K 设置为 5-10
- 调整
vector_similarity_weight:中文场景建议 0.2-0.3 - 不同文档类型使用对应解析模板,不要全用 General
- 父子分块开启后,子块 512 tokens + 父块 2048 tokens 是最优配比
- 对话生成的相似度阈值设为 0.3,低于阈值走关键词检索兜底
常见坑
| 问题 | 原因 | 解决 |
|---|---|---|
| 内存不足 | ES 吃内存 | ES_JAVA_OPTS=-Xms2g -Xmx2g |
| 答非所问 | 检索漂移 | 降低 vector_weight,增大 Top-K |
| 解析卡死 | 文档过大/格式损坏 | 单文件控制在 50MB 内,PDF 先转文字版 |
| 回答截断 | 上下文超限 | 减小 chunk_size,System Prompt 中要求精炼 |
| Agent 输出乱码 | CodeExec 异常 | 检查沙盒权限,日志查具体异常 |
运维关键指标
检索延迟 P99 < 500ms
问答准确率 > 90%
文档解析成功率 > 99%
系统可用性 > 99.9%
十一、总结
从 0 到 1 搭建企业级 RAG 知识库,用 RAGFlow 的核心路径:
- Docker 一行命令部署 → 5 分钟跑起来
- 接入大模型 → 云端 API 或本地 Ollama
- 上传文档 → 选对解析模板是关键
- 调检索 → 混合检索 + 重排序 + 父子分块
- 建 Agent → 画布编排,沙盒代码执行,MCP 工具集成
- 上生产 → 负载均衡 + 监控 + 备份
RAGFlow 2026 已经从"RAG 引擎"长成了 Agentic RAG 平台。文档理解能力无可替代,Agent 编排能力也在快速追赶 Dify。如果你的场景核心痛点是文档复杂、格式多样,RAGFlow 是当前最好的开源选择。
参考来源
RAGFlow
DeepSeek
Anthropic Claude
BGE 系列 (BAAI)
Qwen3 系列 (阿里通义)

欢迎加入 MCP 技术社区!与志同道合者携手前行,一同解锁 MCP 技术的无限可能!
更多推荐
 11
11 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)