Agent 会话系统:上下文、历史与并发隔离
echo-agent 前身为 2025 年 11 月启动的个人助理项目 fubot,最初面向长期陪伴型个人智能体,围绕认知记忆、上下文延续、用户偏好沉淀、任务闭环与持续自我优化展开。随着真实场景迭代,项目逐步形成多入口接入、统一事件模型、消息总线、Agent Loop、多模型抽象、工具调用、MCP 接入、任务调度、权限审批、运行轨迹、长期记忆和受控自演进等能力。目前已支持微信、QQ、CLI、Gateway、Webhook、Cron 等入口,服务用户超过 20 万、累计下载超过 50 万,是面向长期运行、记忆增强和可持续成长智能体的开源 Agent Runtime。
你可能遇到过这样的 Agent 异常:用户连续发了两条消息,第一条还在跑工具,第二条已经开始构造上下文;或者长会话被裁剪后,模型突然报 tool message 结构不合法。
这些问题表面上看像并发 bug、存储 bug 或模型兼容问题,底层其实都指向同一件事:系统没有把会话当成 Agent 的上下文边界来设计。
本篇只讲一个点:Agent 会话系统如何同时管理上下文、历史结构和并发隔离。
问题入口
在普通聊天应用里,会话经常被理解成“聊天记录”:用户发一句,系统存一句;下次请求时,把最近几轮消息塞回模型。这个理解放到 Agent 上就不够了。
Agent 的上下文里不只有 user 和 assistant 文本,还包含工具调用、工具结果、审批响应、压缩边界、记忆整合位置和通道元数据。如果这些内容跨会话串扰,后果不只是“回答不准”,还可能变成错误执行。
例如,用户在 A 项目里让 Agent 读取了一个文件路径,在 B 项目里又说“把刚才那个改掉”。边界过宽,模型可能拿 A 项目的上下文解释 B 项目的指令;边界过窄,模型又无法理解“刚才那个”。
会话不是消息缓存,而是定义“哪些历史可以解释当前输入”的上下文边界。
为了不停留在抽象层面,下面以 echo-agent 的实现为例。
会话边界
echo-agent 中,所有进入 AgentLoop 的事件都必须先落到明确的 session_key 上。默认情况下,session_key 由 channel 和 chat_id 组成:
@property
def session_key(self) -> str:
if self.session_key_override:
return self.session_key_override
return f"{self.channel}:{self.chat_id}"
这个设计很朴素,但边界很硬。CLI、Telegram 群聊、Slack channel、Webhook、Cron 投递,都可以拥有独立历史。Agent 处理某个 chat 时,不会把另一个 chat 的上下文混进来。
session_key_override 则给产品化入口留下空间。Gateway 可以让多个浏览器连接共享同一 session;A2A 可以按外部 task id 组织上下文;定时任务可以携带 source_session_key 回到原始会话。
关键不是字符串格式,而是隔离策略。真正的原则是:每个入口进入核心 Loop 前,都要明确回答“这条消息属于哪个上下文”。

会话边界和用户边界不能混为一谈。一个用户可以同时处理多个项目,一个群聊可以有多个线程。只按用户 ID 建 session,容易混入无关任务;每条消息都新建 session,又会丢掉多轮连续性。
比较稳妥的做法,是让 session 粒度贴近真实对话边界:
| 场景 | 更合适的边界 | 主要原因 |
|---|---|---|
| 私聊 | channel:chat_id |
保留个人连续对话 |
| 群聊 | channel:chat_id 或线程级 key |
避免不同群或线程串扰 |
| Gateway | 显式 session_key_override |
产品侧可能需要统一浏览器连接 |
| A2A | task id 或外部任务 key | 每个任务需要独立上下文 |
| Cron | source_session_key |
定时任务要回到原始上下文 |
会话系统回答的是“这条消息应该看见哪段历史”。它不回答“这个用户被允许做什么”。权限仍然要由 channel 认证、sender_id、ApprovalGate、tool_policy、path_policy 和凭证作用域共同决定。
这一点非常重要:session 隔离上下文,security 决定权限。如果把 session_key 当成权限凭证,知道会话 key 就可能被误认为有权访问其中的能力或历史。
历史轨迹
Session 表面上像一个消息数组,实际承载的是 Agent 的执行轨迹。书稿中的结构包含 key、messages、created_at、updated_at、metadata、last_consolidated 和 status。
其中 messages 不是纯文本记录。它可以携带 tool_calls、tool_call_id、name 等 tool calling 字段,是 LLM 协议消息、工具协议消息和运行元数据的组合。
一次工具调用的结构大致是:
user -> assistant(tool_calls) -> tool(tool_call_id) -> assistant
模型先生成 tool call,系统执行工具并把 tool result 写回历史,模型再基于结果继续回答。只保存文本,不保存结构链,下一轮模型就无法知道工具结果属于哪个调用。
Agent 会话历史更像状态机日志,不是可以随便按时间切一刀的聊天记录。
这也解释了为什么 messages 要保持 append-only。它不是任意覆盖的当前状态,而是可追溯的因果轨迹。
安全裁剪
长会话不可能把所有历史都塞回模型。token 成本会上升,旧信息会稀释注意力,历史结构还可能被裁坏。
echo-agent 的 get_history 做了一个很容易被忽视但非常关键的处理:从 last_consolidated 之后取未整合消息,再按 max_messages 截断;如果截断后的开头是 tool message,就跳过这些孤立工具结果;最后尽量从第一条 user message 开始返回。
可以简化成下面这段伪代码:
def get_history(max_messages=500):
unconsolidated = messages[last_consolidated:]
sliced = unconsolidated[-max_messages:]
while sliced and sliced[0]["role"] == "tool":
sliced = sliced[1:]
for i, msg in enumerate(sliced):
if msg["role"] == "user":
return sliced[i:]
return sliced
这个逻辑解决的是 orphan tool result 问题。tool result 必须对应前面的 assistant tool_calls。如果历史裁剪留下孤立的 tool message,轻则模型理解混乱,重则 provider 直接拒绝请求。
这里的工程判断很明确:历史不是越多越好,结构完整比数量更重要。last_consolidated 不是普通时间戳,而是短期会话历史和长期记忆整理之间的边界。
并发隔离
消息总线可以并发分发事件,但同一个 session 不能并发修改同一条历史。echo-agent 用 per-session lock 保证这一点。
SessionManager.acquire 会为每个 session_key 返回一把独立锁。AgentLoop 在处理入站事件时,先拿到该 session 的锁,再进入 _process_event。
session_lock = await self.sessions.acquire(event.session_key)
async with session_lock:
result = await self._process_event(
event,
trace_id,
publish_response=True,
)
这意味着同一会话的两条消息即使同时到达,也会排队处理;不同会话持有不同锁,可以并行推进。
为什么不能让同一 session 并发?用户先发“帮我修复测试失败”,紧接着又发“等等,不要改配置文件”。如果两个请求并发,第二条可能在第一条工具执行之后才进入上下文;也可能第一条还没写回工具结果,第二条已经读了半截历史。
这时问题不只是数据竞争。模型看到的世界已经不再是真实发生顺序,推理路径也会随之改变。
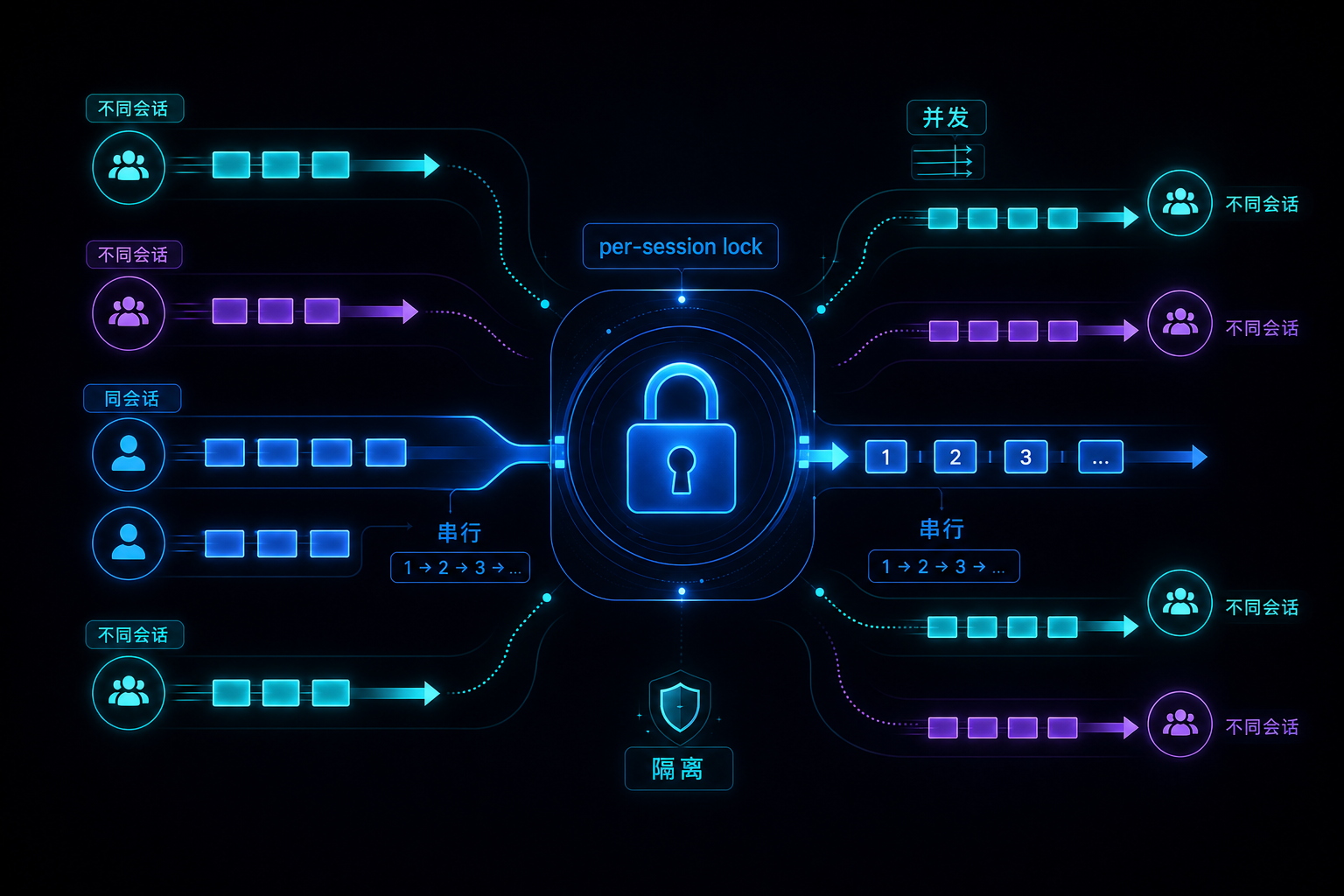
同一会话串行保护的是语义顺序,不只是内存一致性。
更合理的边界是:同 session 串行,不同 session 并发。这样既保护对话因果,又不让一个长任务阻塞所有用户。
书稿中的测试也不是只验证锁对象存在,而是验证真实行为:两个同 session 事件并发进入 _on_inbound 时,必须等第一条处理结束后,第二条才开始。这类测试验证的是系统承诺,而不是实现细节。
生命周期
会话系统还要处理缓存、持久化、过期和记忆交界。
SessionManager 使用 OrderedDict 做内存缓存。get_or_create 先查缓存,再从 storage 或 JSONL 加载。缓存超过上限时,最旧 session 会在淘汰前保存,避免内存无限增长又不丢历史。
保存也要考虑失败路径。有 storage 时写 SQLite,失败则 fallback 到 JSONL;文件写入使用临时文件、fsync 和 os.replace,目标是保存失败不破坏旧状态。
过期和归档由 status 控制。但会话过期不是删除记忆。会话处理短期上下文生命周期,长期记忆可以继续保留稳定偏好、项目事实和已验证经验。
ConsolidationWorker 会重新获取 session lock、重新加载 session,再推进整合边界,避免后台任务拿着旧对象处理已经变化的历史。整合成功后,它也会避开末尾未配对的 tool message 或 assistant tool_calls。会话历史有结构边界,压缩和记忆都必须尊重它。
生产可用性
判断一个 Agent 会话系统是否生产可用,不能只看“能不能保存聊天记录”。至少要看这些工程项:
| 检查项 | 可检验标准 |
|---|---|
| 上下文边界 | 每个入口进入 AgentLoop 前都有明确 session_key |
| 历史结构 | assistant tool_calls 与 tool result 能成对保留 |
| 安全裁剪 | 截断后不会把 orphan tool result 放进模型输入 |
| 并发隔离 | 同 session 串行,不同 session 可并发 |
| 持久化 | 保存失败不破坏旧文件,缓存淘汰前会落盘 |
| 生命周期 | 支持 active、expired、archived |
| 记忆边界 | 有 last_consolidated 避免重复或漏整合 |
| 权限分层 | session 不被当成身份或权限凭证 |
| 测试覆盖 | 有并发、原子保存、跨模块串行行为测试 |
这张表背后的判断是:会话系统的核心质量不是字段齐全,而是一致性。历史不丢,结构不错,同会话不并发写,不同会话可并发,保存失败不破坏旧状态。
只保存最近 N 条文本,也许可以做 Chatbot;但要做能调用工具、等待审批、承接长任务、被追踪复盘的 Agent,就必须把会话设计成上下文治理模块。
小结
会话系统处在消息总线和 Agent Loop 之间。消息总线把事件送进来,会话系统决定事件属于哪个局部世界,Agent Loop 再基于这个世界推理和行动。
理解了这一层,很多工程问题会变得清晰:为什么不能只按用户 ID 建会话,为什么历史裁剪不能随便切,为什么同一会话要串行,为什么会话不是权限边界。
会话不是 Agent 最显眼的模块,但它决定模型看到的世界是否真实。世界错了,推理再强也只是在错误上下文里行动。
(全篇完)
本文为 echo-agent 设计笔记系列第 06 篇。项目源码已开源至 GitHub。如果你对工业级 Agent 的工程落地感兴趣,欢迎加入技术交流群参与日常讨论。下一篇我们将探讨 《Agent Loop 的运行流程:从单体循环到三阶段 Pipeline》,敬请期待。

欢迎加入 MCP 技术社区!与志同道合者携手前行,一同解锁 MCP 技术的无限可能!
更多推荐
 8
8 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)