阿里面试官: 如何设计一个 Agent 工具?工业级实战:本地工具 + MCP 混合工具底座设计
尼恩说在前面
在45岁老架构师尼恩的读者交流群(50+人)里,最近不少小伙伴拿到了阿里、滴滴、极兔、有赞、希音、百度、字节、网易、美团这些一线大厂的面试入场券,恭喜各位!
Harness 架构已经是 架构面试的核心题目, 前两天就有个小伙伴面 架构, 问到 下面的场景题
-
“你们怎么实现 Harness Agent 的?
-
你们项目中,工业级Harness Agent Tools 底座 是如何落地实现的?
-
你是否了解Harness Agent Tools Infra底层基础设施架构?核心设计理念是什么?
-
如何从零搭建一套生产级别的Agent Tools 底层工具底座?
最近,尼恩 发现一个共性面试问题,也是目前大厂AI架构岗必考高频重难点:Harness基础设施架构,其中涵盖Agent工具底座、本地+远程混合工具架构、MCP服务治理等相关知识点。
尼恩 有很多 面架构、或者面大厂 的学员,在架构终面直接折戟在这类场景题上。
通过这个 系列的 文章, 这里 尼恩给大家做一下 系统化、体系化的梳理,写一个系列的文章组成 尼恩编著 《Harness 架构与源码 学习圣经》 深入剖析 Harness AI 平台级 架构的 架构思维与 核心源码,使得大家可以充分展示一下大家雄厚的 “技术肌肉”,让面试官爱到 “不能自已、口水直流”。
同时,也一并把这个题目以及参考答案,收入咱们的 《尼恩Java面试宝典PDF》V176版本,供后面的小伙伴参考,提升大家的 3高 架构、设计、开发水平。
尼恩编著 《 DeepAgents /Deerflow / 手写 Harness基建 圣经》
第一章: 什么是 Harness架构?2026年AI核心范式解析 : Harness架构与Agent工程化
具体文章: 54k+Star 爆火!AI 框架 新王者 Harness Agent 来了!尼恩 来一次Harness穿透式解读
第二章: Harness架构 与 LangChain、LangGraph 三者联动 的底层逻辑
具体文章: Harness架构 与 LangChain、LangGraph 三者联动 的底层逻辑
第十四章: 架构哲学和思维: Harness /ReAct /PlanExec /Reflect /混合范式 的 区别
架构哲学和思维: Harness /ReAct /PlanExec /Reflect /混合范式 的 区别
第十五章: Harness 底层知识: MCP与FC的10大差别?Harness 怎么 用MCP与FC?
Harness 底层知识: MCP与FC的10大差别?Harness 怎么 用MCP与FC?
第17章: Harness SDK 架构 :DeepAgent 基于LangGraph的生产级Super Agent驾驭层实现
本文
第17章: Harness SDK 架构 :DeepAgent 基于LangGraph的生产级Super Agent驾驭层实现
第18章:DeepAgent : 基于LangGraph的 Harness 执行层 生产级 子智能体 Sub-Agent 深度拆解
第18章:DeepAgent : 基于LangGraph的 Harness 执行层 生产级 子智能体 Sub-Agent 深度拆解
第19章: 深入解析DeepAgents的Middleware管道:设计一个Harness 护栏完成Agent全生命周期的治理
第19章: 深入解析DeepAgents的Middleware管道:设计一个Harness 护栏完成Agent全生命周期的治理
第20章: DeepAgents 经验注入+记忆注入:基于Memory与Skills双中间件 实现 渐进式披露 + 运行时 经验注入
第20章: DeepAgents 经验注入+记忆注入:基于Memory与Skills双中间件 实现 渐进式披露 + 运行时 经验注入
第21章:【顶级架构思维】Harness 架构如何 上下文压缩: 深入 剖析 DeepAgents 四级上下文 压缩流水线 底层原理和核心源码
【顶级架构思维】Harness 架构如何 上下文压缩: 深入 剖析 DeepAgents 四级上下文 压缩流水线 底层原理和核心源码
第22章:Hermes +Claude 实现 AI 编程 Agent Team 硅基团队 ,一人 开启 10个Agent的 个人boss 之路
第22章:Hermes +Claude 实现 AI 编程 Agent Team 硅基团队 ,一人 开启 10个Agent的 个人boss 之路
第24章:【顶级架构】穿透Hermes 塔尖工具系统:自注册设计+ 组合式按需推送+四层纵深防御+零配置插件 +常驻事件循环
第24章:【顶级架构】穿透Hermes 塔尖工具系统:自注册设计+ 组合式按需推送+四层纵深防御+零配置插件 +常驻事件循环
第25章:【Harness顶级架构】Hermes skills 自进化 秘诀:三层引擎 + 影子Agent + 边车文件 + 伞状合并
第25章:【Harness顶级架构】Hermes skills 自进化 秘诀:三层引擎 + 影子Agent + 边车文件 + 伞状合并
第26章:Harness 底层架构: 基于 Deep Agents 深入底层 Sandbox沙盒Infa 基础设施架构
第26章:Harness 底层架构: 基于 Deep Agents 深入底层 Sandbox沙盒Infa 基础设施架构
第27章:【手写 Harness 基建实操】阿里面试官: 如何设计一个 Agent 工具?工业级实战:本地工具 + MCP 混合工具底座设计
第27章:【Harness 基建实操 之 工具底座】阿里面试官: 如何设计一个 Agent 工具?工业级实战:本地工具 + MCP 混合工具底座设计
第28章:【手写 Harness 基建 之 记忆底座】 字节面试官: 如何设计一个 Agent 记忆系统?工业级实战: 四层记忆 infra 底座架构
第28章:【Harness 基建实操 之 记忆底座】 字节面试官: 如何设计一个 Agent 记忆系统?工业级实战: 四层记忆 infra 底座架构
第29章:【手写 Harness 基建 之 Agent 编排底座】 字节面试官: Agent 和 Workflow 到底有什么区别?90%的人都理解错了! 手写 一个工业级实战: 四层Agent协同编排引擎 Infra 底座 , 新一代的Agent 协同编排引擎 Infra 底座
其他的高质量 文章, 估计有 10章以上,具体请关注技术自由圈。
尼恩还在写,后续发布

Agent Tools 工业级实战: 本地工具 + MCP 混合 infra 工具底座 架构设计
工具设计是 Agent 工程最核心的技能。
工具设计质量,直接决定 Agent 能力层级:是仅能表面智能化,还是可以稳定落地、独立完成各类业务工作。
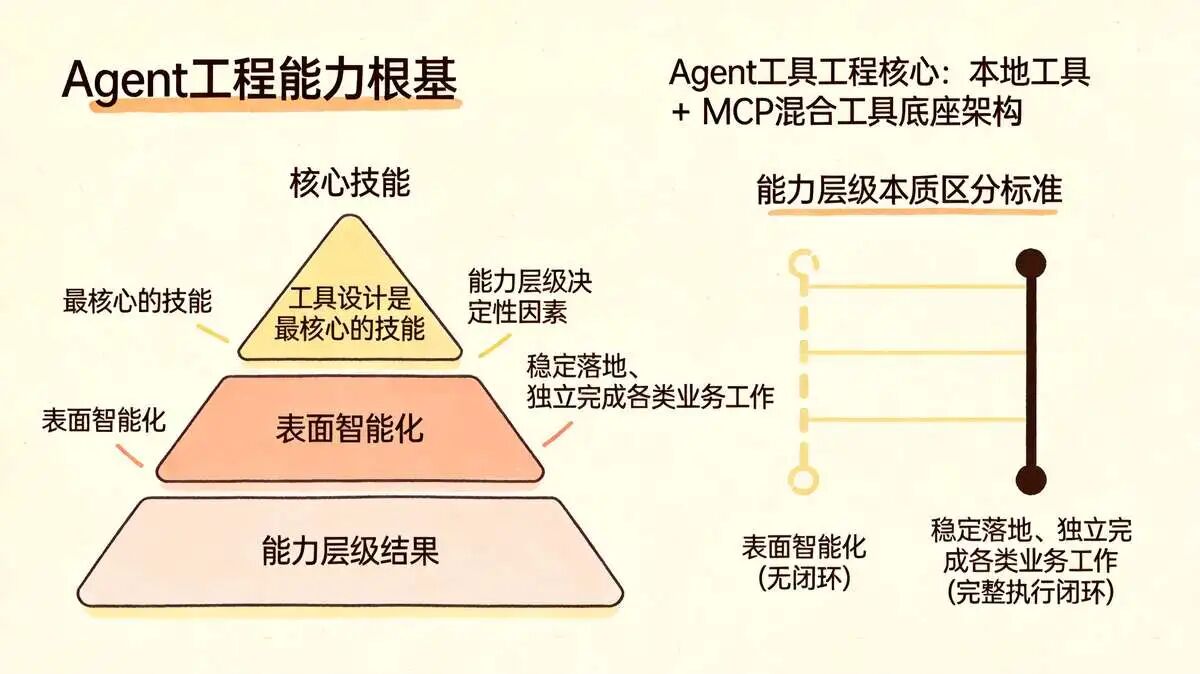
一、基础知识:什么是 Agent 工具?
工具, 是给 LLM 提供可调用的外部函数。
工具,是LLM的手和脚。
工具, 打破大模型仅能基于文本生成内容的局限,让Agent形成观察→思考→行动→获取反馈→二次思考的闭环工作模式。
工具的定义:其实是 一段 文本。
这段 文本 是一段 具备明确Schema接口契约、副作用可控的json,依托Function Calling/Tool Use机制,交由大模型自主调度执行。
二、 业务抽象 + 工具 的 拆分准则
业务需求抽象与 工具 的 拆分 是Agent工具落地的基础。
核心目标是完成业务能力拆解,界定能力归属(Prompt原生推理/工具外部调用),并遵循单一职责原则完成工具粒度拆分,从源头规避大杂烩工具、调用边界模糊等底层问题。
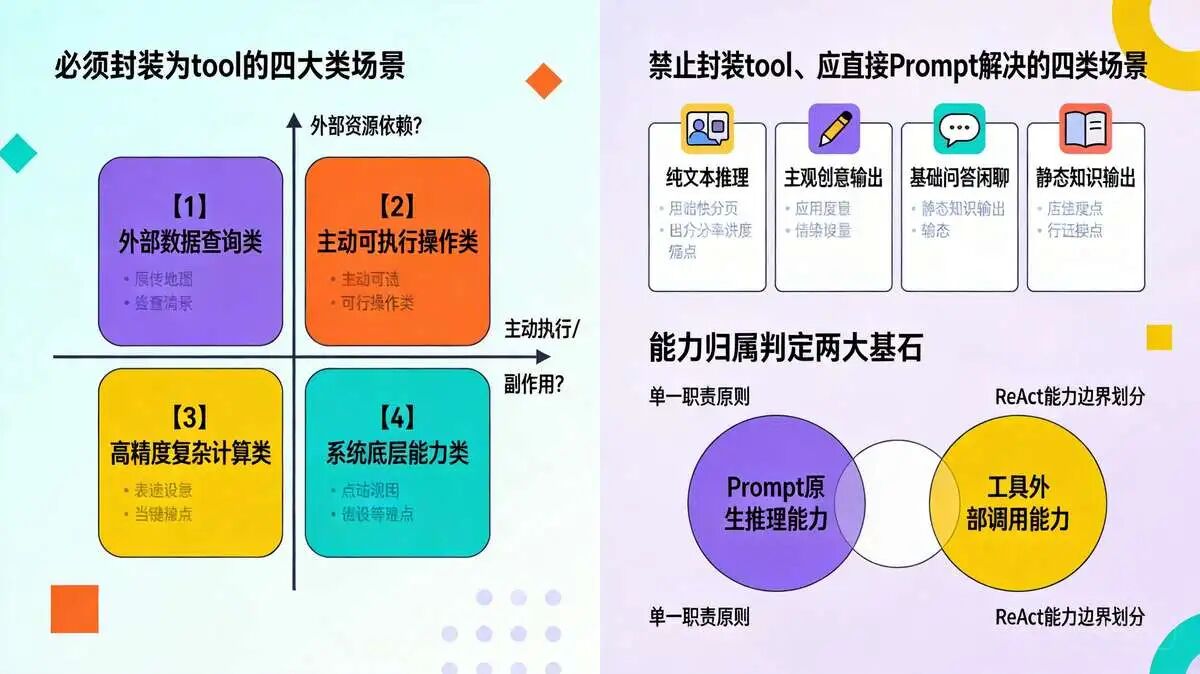
2.1 需要 用到 tool 的 四大类场景
凡是存在外部资源依赖、模型原生能力短板、需要可追溯执行动作的业务场景,必须封装为独立工具,具体分为四大品类,覆盖95%企业级Agent业务需求:
【1】外部数据查询类: 实时联网搜索、第三方API数据拉取(天气、股票、物流、汇率)、企业私有知识库RAG检索、数据库多类型查询、CRM/ERP业务数据调取、历史会话数据复盘查询;核心痛点:模型训练数据存在时间截止线,无法获取动态实时数据。
【2】主动可执行操作类: 本地/服务器文件读写与格式转换、Python/Shell代码运行、数据库增删改查、消息推送(短信/邮件/企业微信)、订单创建/取消、权限申请、硬件设备指令下发;核心痛点:LLM仅能输出文本,无法直接作用于操作系统与业务系统。
【3】高精度复杂计算类: 多维数学运算、财务报表统计、税费核算、批量数据排序/去重/汇总、矩阵运算、概率统计、单位批量换算;核心痛点:大模型上下文易丢失、浮点运算容错率低,高频出现计算幻觉,无法满足生产级数值精度要求。
【4】系统底层能力类: 定时任务调度、用户权限校验、接口限流熔断、第三方支付回调、多文件资源锁管控、多智能体任务分配、日志采集上报;核心痛点:属于底层工程能力,不属于模型推理范畴,需标准化接口统一调度。
2.2 禁止 用 tool 工具,直接Prompt解决的场景
无外部资源依赖、无需执行外部操作、仅依赖模型原生推理能力即可完成的场景,禁止冗余封装工具,避免增加调用链路耗时、提升运维成本、放大幻觉风险:
- 纯文本推理: 语义理解、意图识别、文本分类、情感分析、内容摘要;
- 主观创意输出: 文案创作、剧本编写、海报文案、话术优化、仿写改写;
- 基础问答闲聊: 日常问候、常识解答、行业概念解读、简单话术答疑;
- 静态知识输出: 通用历史常识、基础语法、固定行业名词解释(非实时更新内容)。
2.3 工具抽象 的 黄金原则
统一遵循单一职责、低耦合、高内聚、原子化四大拆分原则。
一个工具仅负责一项独立原子业务能力,严禁多功能聚合的巨型工具,降低模型调用决策难度、简化参数校验逻辑、便于故障定位与权限管控:
- 反面案例(高危错误): 封装
all_business_api聚合工具,同时实现查天气、创建订单、发送邮件、数据库查询四大功能;弊端:参数冗余、意图识别误差大、权限无法精细化管控、故障难以溯源。 - 正面案例(标准规范): 按能力拆分独立原子工具
get_real_time_weather、create_user_order、send_target_email、query_product_sql,各司其职。
2.4 工具粒度分级策略
为适配通用场景与垂直行业场景,工具分为粗、细两种粒度,开发者可按需选型:
- 粗粒度工具: 面向通用轻量化场景,能力覆盖面广、参数简单,如
global_network_search全网搜索工具,适用于C端通用问答Agent; - 细粒度工具: 面向垂直行业复杂场景,能力高度专用、参数约束严格,如
calculate_enterprise_tax企业税费核算工具、delete_warehouse_inventory库存删除工具,适用于B端政企智能体。
三、tool 工具 Schema 的 标准化 契约定义
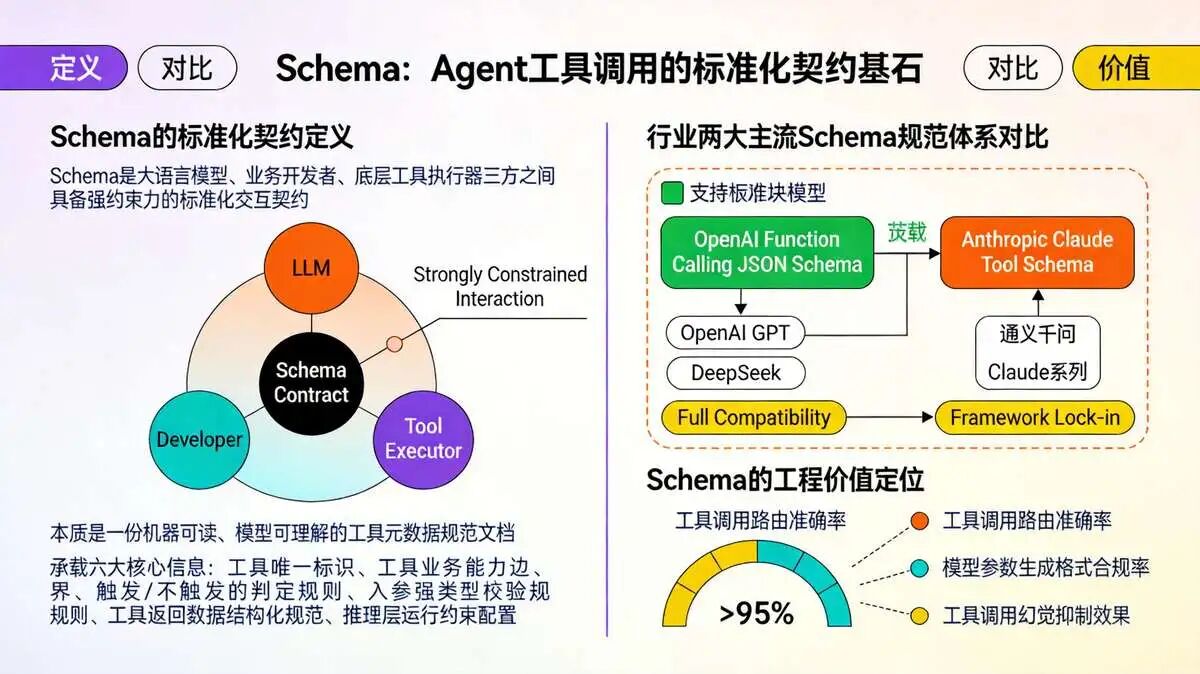
在大模型 Agent 工具调用(Function Calling/Tool Calling)工程体系中,Schema 是大语言模型、业务开发者、底层工具执行器三方之间具备强约束力的标准化交互契约,
Schema 本质是一份机器可读、模型可理解的工具元数据规范文档。
Schema 契约完整承载六大核心信息:工具唯一标识、工具业务能力边界、触发 / 不触发的判定规则、入参强类型校验规则、工具返回数据结构化规范、推理层运行约束配置。
Schema 直接决定三大工程指标:工具调用路由准确率、模型参数生成格式合规率、工具调用幻觉(错调用、漏调用、乱传参)抑制效果,是生产级 Agent 系统稳定性的底层核心基石。
Schema是开发者与大模型之间的标准化交互契约,用于直白告知模型:工具名称、能力边界、触发条件、入参规则、返回结构、运行配置,是决定工具调用准确率、抑制调用幻觉的核心环节。
目前行业主流两套规范:OpenAI Function Calling JSON Schema, 天然兼容OpenAI、DeepSeek、通义千问、LangGraph、AutoGen、Microsoft 365 Agents SDK等全主流Agent框架,具备极强通用性。
3.1 行业两大主流 Schema 规范体系对比
当前全球 AI Agent 生态存在两套标准化工具调用 Schema 体系,其中 OpenAI Function Calling JSON Schema 为事实工业标准,具备全域兼容性:
【1】OpenAI Function Calling JSON Schema(推荐生产使用): 底层基于 JSON Schema Draft-07 规范子集裁剪实现,原生兼容 OpenAI GPT 全系列、DeepSeek、通义千问、文心一言、LangGraph、AutoGen、Microsoft 365 Agents SDK、LangChain、LlamaIndex 等海内外几乎全部主流 Agent 开发框架,跨厂商、跨开源 / 闭源模型无缝迁移,通用性拉满,也是本文核心讲解规范。
【2】Anthropic Claude Tool Schema(独立私有规范): Claude 系列自研工具定义格式,语法、字段约束与 OpenAI 体系存在割裂,仅适配 Anthropic 模型,跨框架迁移成本高,企业多作为多模型兼容分支方案使用,不作为通用标准化首选。
3.2 标准化 Schema 不可替代的工程收益
【1】消除模型调用幻觉: 通过strict严格模式 + 强类型约束,底层推理引擎拦截非法 Token,强制输出 100% 匹配 Schema 的 JSON 参数,杜绝参数类型错乱、多余字段、缺失必填项等问题;
【2】降低前后端联调成本: Schema 等价于工具接口文档,可自动生成接口校验器、入参解析逻辑,无需人工手写参数校验代码;
【3】多工具智能路由: 完整的description语义约束可让模型精准区分多工具适用场景,大幅减少工具选错概率;
【4】可自动化生成: 支持 Zod/Pydantic 等类型库反向导出 Schema,也支持 OpenAPI 接口文档一键转工具 Schema,自动化提效;
【5】全链路可观测: 标准化元数据可埋点统计工具调用成功率、参数错误类型,用于 Agent 迭代优化。
3.3、OpenAI Function Calling 顶层 Schema 六大核心字段完整详解
顶层标准固定模板(生产通用模板,唯一标准格式)
OpenAI 官方强制规定,单工具定义顶层根节点固定为{"type": "function"},内部包裹完整函数元数据,无任何自定义扩展根字段,完整模板如下:
{
"type": "function",
"function": {
"name": "tool_name_snake_case",
"description": "完整语义描述,包含正例调用场景、反例禁止场景、工具输出说明",
"strict": true,
"parameters": {
"type": "object",
"properties": {},
"required": [],
"additionalProperties": false
}
}
}
六大字段精细化设计规范
【1】name(工具唯一标识):
- 命名规范: 统一小写蛇形命名法,格式固定为「动词_名词」,语义直白无歧义;
- 约束要求: 全局唯一,不可重名,Agent调度器依靠该字段路由工具;禁止使用简写、拼音、特殊符号;
- 标准示例:
search_internal_product_doc、calculate_finance_profit。
【2】description(调用决策核心,最重要字段):
- 标准化三段式+优先级补充写法,缺一不可: ①核心能力:直白说明工具可实现的所有功能;②强制触发条件:明确哪些用户提问/任务场景必须调用;③绝对禁用场景:划定边界,杜绝无效调用;④补充优先级:多工具共存时的调用排序规则;
- 禁忌要求: 禁止模糊化描述(如“用于查询相关数据”),描述越模糊,模型幻觉概率越高;
- 高阶优化: 可加入负向示例,明确告知模型错误调用场景。
【3】parameters(入参约束):
- 基础配置: 明确required必填/选填参数,所有参数必须配备完整描述、合法输入示例;
- 强约束优化: 枚举enum固定离散型参数取值、max/min限制数值范围、maxLength限制字符串长度;新增additionalProperties:false,禁止模型传入未定义冗余参数;
- 复杂参数: 多维嵌套参数用object类型,批量数据用array类型,嵌套层级建议不超过3层,降低解析难度。
【4】return_schema(出参契约):
- 设计原则: 强制统一结构化返回,禁止自由文本返回;所有工具返回结构对齐,包含状态码、提示信息、业务数据三大基础字段;
- 作用: 统一模型解析逻辑,避免自由文本解析错乱,同时便于调度器做数据清洗、异常识别。
【5】error_schema(专属异常结构):
-
生产级新增字段,标准化定义所有报错格式,区分错误类型,引导模型自主重试、修正参数或直接终止任务;
-
适配所有异常场景,与后续容错体系一一对应。
【6】meta(运行元数据):
- timeout: 工具最大执行超时时间,普通查询类3000-5000ms,复杂计算/文件类10000ms以内;
- permission: 权限白名单,绑定用户角色,精细化管控高危工具调用权限;
- cache_ttl: 结果缓存有效期,静态数据3600s、动态实时数据0s(禁用缓存);
- need_confirm: 高危操作开关,true=调用前需人工二次确认;
- retry_times: 运行异常自动重试次数,默认2次。
3.4 生产级完整工具实战示例
整合前文所有字段、数组、标量约束,提供可直接接入 API 的完整工具定义,覆盖绝大多数业务场景:
{
"type": "function",
"function": {
"name": "search_internal_doc",
"description": "专门检索企业内部产品文档、售后政策、收费标准、操作手册知识库。
当用户提问涉及产品规格、保修期、收费价格、售后流程、功能使用时必须优先调用;日常闲聊、创意写作、外部资讯查询、通用常识问答场景禁止调用。
",
"parameters": {
"type": "object",
"required": ["query"],
"additionalProperties": false,
"properties": {
"query": {
"type": "string",
"description": "精简后的用户核心问题关键词,禁止传入冗余闲聊内容,示例:产品官方保修期多久",
"maxLength": 200,
"minLength": 2
},
"top_k": {
"type": "integer",
"description": "需要返回的匹配文档条数,默认3条",
"minimum": 1,
"maximum": 10,
"default": 3
}
}
},
"return_schema": {
"type": "object",
"required": ["code", "msg", "docs"],
"properties": {
"code": {"type": "integer", "description": "0=执行成功,-1=无匹配数据,-2=参数错误,-3=服务异常"},
"msg": {"type": "string", "description": "工具执行状态提示文案"},
"docs": {
"type": "array",
"description": "知识库匹配文档列表",
"items": {
"type": "object",
"properties": {
"title": {"type": "string", "description": "文档标题"},
"content": {"type": "string", "description": "文档核心片段内容"},
"score": {"type": "number", "description": "相似度匹配分数,区间0-1"}
}
}
}
}
},
"error_schema": {
"type": "object",
"properties": {
"code": {"type": "integer"},
"error_type": {"type": "string","enum": ["参数错误","资源异常","权限拒绝"]},
"msg": {"type": "string"}
}
},
"meta": {
"timeout": 5000,
"permission": ["user", "admin"],
"cache_ttl": 300,
"need_confirm": false,
"retry_times": 2
}
}
}
3.5、生产 Schema 标准化设计最佳实践(避坑指南)
(1) 强制开启 strict: true + additionalProperties: false,双重拦截多余参数、缺失字段,从底层杜绝参数解析报错;
(2) 所有字段补充 description,顶层 function 描述分三段(能力 + 正例 + 反例),每个入参标注业务含义、取值限制;
(3) 能用 enum 就不用自由字符串,状态、类型、分类类参数全部枚举固定值,减少模型自由生成错误文本;
(4) 数组强制配置 minItems/maxItems,限制批量参数上下限,防止模型一次性传入上百条数据触发工具接口超限;
(5) required 仅标记真正不可缺省参数,分页、开关类存在业务默认值的参数放入非必填列表;
(6) 工具 name 动词开头蛇形命名,统一团队规范,便于埋点日志统计;
(7) 复杂业务分层拆解多工具,不要将多类无关能力塞进同一个 function,降低模型路由混淆概率;
(8) 上线前使用 JSON Schema 校验器预校验 Schema 合法性,避免 API 调用时返回 400 参数错误。
四、Agent 工具 设计 5条黄金原则
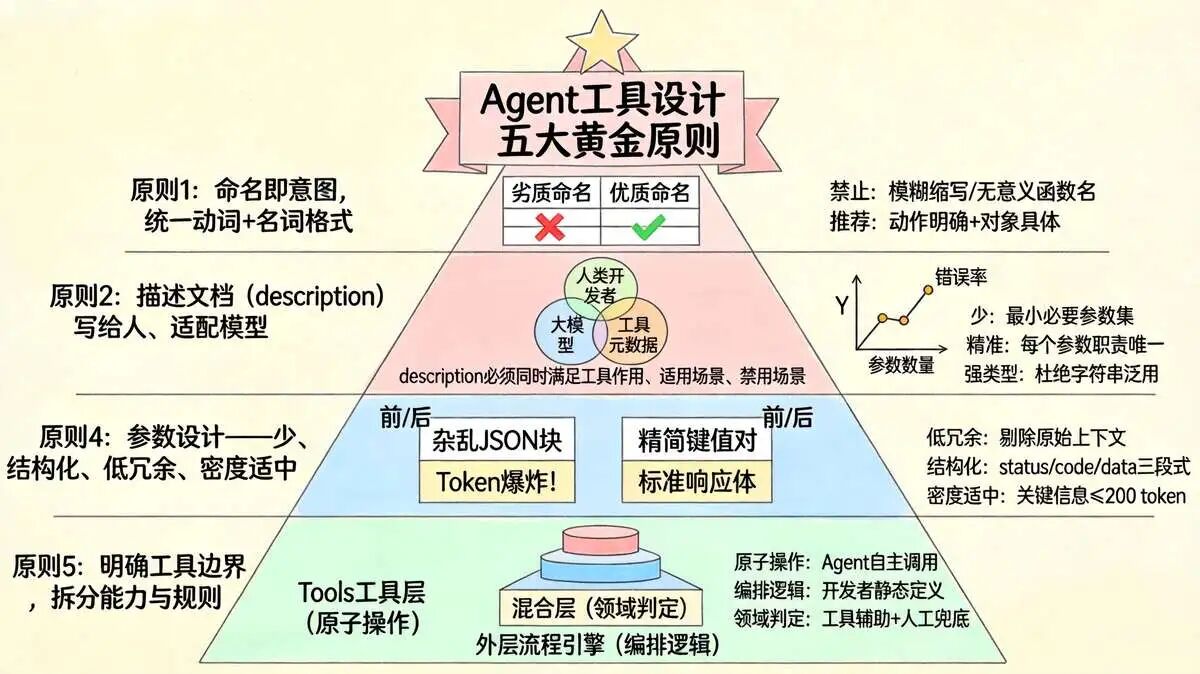
原则1:命名即意图,统一动词+名词格式
大模型依靠工具名称+描述判断调用时机,模糊的工具名称会直接导致模型乱选、误调用。
命名固定规则:动词(执行动作)+ 名词(操作对象),直观表达工具核心用途。
| 劣质命名(禁止) | 优质命名(推荐) | 优化说明 |
|---|---|---|
| DataAPI | search_documents | 直白体现检索文档的核心功能 |
| process() | summarize_and_store_note | 明确包含总结、存储两个动作 |
| get_info | lookup_user_by_email | 指定查询方式与查询对象 |
原则2:描述文档(description)写给人、适配模型
大模型无法读取工具底层代码,仅能识别三大要素:name、description、parameters。
因此工具描述不能写无效废话,必须清晰回答三大问题:工具作用、适用场景、禁用场景。
编写范例
def search_knowledge_base(query: str, top_k: int = 5) -> list[dict]:
"""
在内部知识库中语义检索文档片段。
适用场景:
- 用户提问需要核实事实性内容
- 需要引用公司制度、产品文档、历史业务记录
不适用场景:
- 纯日常闲聊、主观观点类问题(禁止调用本工具)
参数:
- query: 检索关键词,提炼核心短语,禁止整句复述用户原话
- top_k: 返回高相关结果数量,默认值为5
返回:包含content(内容)、source(来源)、score(匹配度)的结果列表
"""
核心编写技巧
-
强制标注适用/不适用场景,约束模型调用范围
-
参数补充示例值,降低模型入参填写难度
-
杜绝无效话术,例如“本函数用于实现xx功能”
原则3:参数设计——少、精准、强类型
参数数量与模型出错概率成正比。
每新增一个参数,就会增加模型的决策成本与调用错误率,优先采用最小必要参数集。
正反案例对比
# ❌ 反面案例:过度参数化,冗余且极易出错
def search(user, keyword, date_from, date_to, status, dept, fuzzy, ...): ...
# ✅ 正面案例:最小参数集,强类型约束
def search_documents(
query: str = Field(..., description="检索关键词,提炼后的核心短语"),
scope: Literal["public", "internal"] = "internal",
):
...
落地经验法则
(1) 位置参数数量严格控制在2~3个以内;
(2) 复杂筛选条件不单独拆分为参数,交由模型通过自然语言写入检索词,后端统一解析;
(3) 时间、日期等易出错参数,拆分独立工具(get_current_time),辅助模型完成入参。
原则4:返回值——结构化、低冗余、密度适中
返回值设计极易被忽视。
- 原始完整数据会造成Token爆炸、模型推理混乱;
- 所有工具统一封装标准化返回格式,成功/报错均可被机器直接识别。
正反案例对比
# ❌ 反面案例:直接返回原始数据库数据,冗余量大、Token消耗高
return full_db_row
# ✅ 正面案例:裁剪摘要,结构化返回核心数据
return [
{"title": r.title, "snippet": r.body[:200], "doc_id": r.id}
]
返回值设计契约
-
每条结果必须携带唯一标识: id/来源链接;
-
默认返回内容摘要(snippet),全文仅支持二次单独调取;
-
备注标识ID的后续可执行操作,给模型明确决策指引;
-
统一报错信封格式,禁止直接抛出程序异常。
统一报错返回模板
{
"ok": false,
"error": "doc_not_found",
"hint": "可调用list_available_docs()工具查看有效文档列表"
}
原则5:明确工具边界,拆分能力与规则
经典开发误区:将完整业务编排流程封装为单一巨型工具。
需要严格区分原子操作与业务编排,各司其职。
| 业务类型 | 承载位置 | 管控主体 | 举例 |
|---|---|---|---|
| 原子操作(查/读/算/发) | Tools工具层 | Agent自主决策调用 | 查询订单、发送验证码、计算数据 |
| 编排逻辑(顺序/分支/权限) | 外层流程引擎 | 开发者固定配置 | 下单后校验身份、失败自动重试 |
| 领域判定(主观策略) | 混合层 | 工具辅助+人工审计 | 判断用户消息是否为投诉诉求 |
一句话总结:工具负责基础能力(Capability),外层流程负责业务规则(Policy)。
五、从零落地工具:完整实战流程
以「用户查询订单状态」为实战案例,复刻标准化开发全流程。
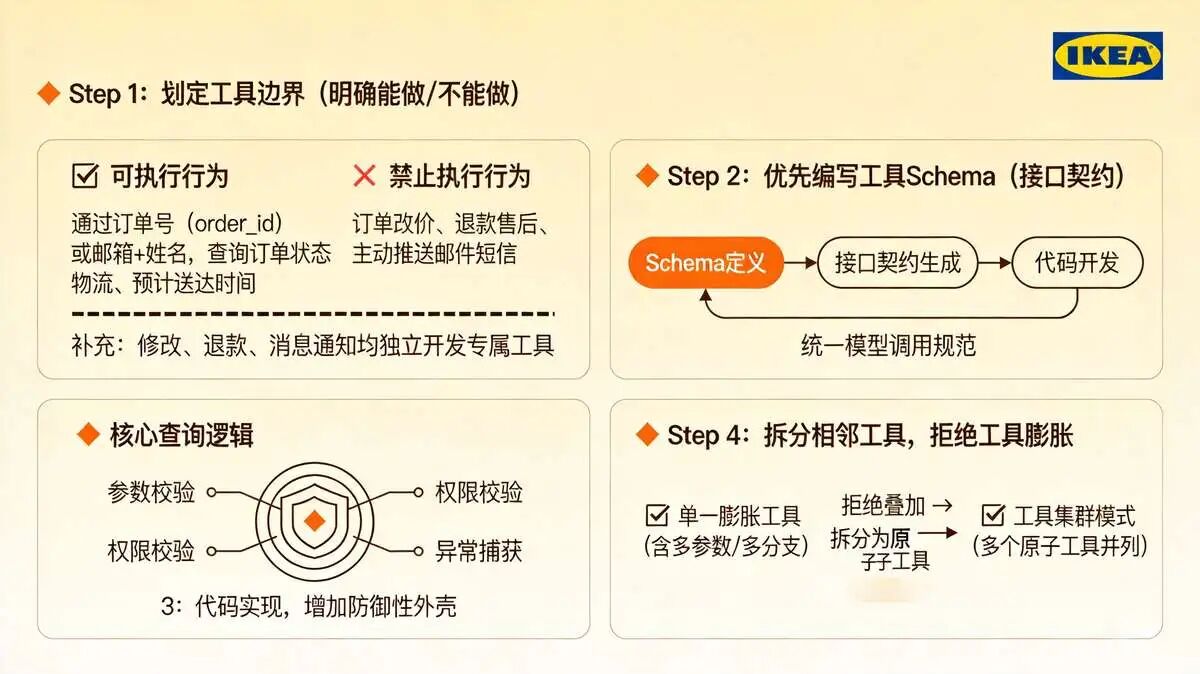
Step 1:划定工具边界(明确能做/不能做)
- 可执行: 通过订单号(order_id)或邮箱+姓名,查询订单状态、物流、预计送达时间;
- 禁止执行: 订单改价、退款售后、主动推送邮件短信;
- 补充: 修改、退款、消息通知均独立开发专属工具。
Step 2:优先编写工具Schema(接口契约)
先定义Schema,后开发代码,统一模型调用规范。
TOOL_SCHEMA = {
"name": "lookup_order",
"description": (
"根据订单号或客户邮箱查询订单状态。
"
"调用约束:仅在用户提供订单号,或完成身份验证后可调用。
"
"返回内容:订单状态、物流节点、预计到达时间。
"
"兜底规则:若用户未提供订单号与邮箱,主动反问用户索要信息。
"
),
"parameters": {
"type": "object",
"properties": {
"order_id": {"type": "string", "description": "订单号,示例:ORD-2024-0891"},
"customer_email": {"type": "string", "description": "客户下单邮箱,与订单号二选一传入即可"}
},
"required": [] # 不强制入参,由模型判断缺失参数并反问用户
}
}
Step 3:代码实现,增加防御性外壳
除核心查询逻辑外,叠加参数校验、权限校验、异常捕获三层防御,保障工具安全稳定。
def lookup_order(order_id=None, customer_email=None):
# 第一层防御:参数非空校验
if not order_id and not customer_email:
return {"ok": False, "hint": "请告诉我要查询的订单号或下单邮箱"}
# 第二层防御:用户身份权限校验(核心安全)
if customer_email and not _belongs_to_session(customer_email):
return {
"ok": False,
"error": "auth_required",
"hint": "请先验证身份:我们将向该邮箱发送验证码,请完成验证"
}
# 核心业务:数据库查询订单
result = db.query(order_id or customer_email)
# 第三层防御:查询结果异常处理
if not result:
return {"ok": False, "error": "not_found", "hint": "未查询到对应订单,请核对参数"}
# 标准化成功返回值
return {
"ok": True,
"order_id": result.id,
"status": result.status, # 状态枚举:placed/ shipped/ delivered
"tracking_no": result.tracking, # 物流单号
"eta": result.eta_iso, # 预计送达时间(ISO格式)
"items_summary": [i.sku for i in result.items[:3]], # 仅展示前3件商品
}
Step 4:拆分相邻工具,拒绝工具膨胀
业务新增需求时,禁止在原有工具内新增参数、叠加功能,采用工具集群模式,每个功能独立成原子工具。
# 工具集群配置
tools = [
lookup_order, # 订单查询(只读原子工具)
cancel_order, # 订单取消(写操作,独立权限校验)
send_templated_email # 邮件推送(通知类,独立风控)
]
避坑清单
| 坑点类型 | 具体现象 | 解决方案 |
|---|---|---|
| 工具数量过多 | 工具总数超20个,模型选错、幻觉调用、拒绝调用 | 工具分组管理,根据上下文动态加载,按需注入提示词 |
| 自由参数不可控 | 模型传入模糊文本(如“明天上午”),无法匹配接口日期格式 | 新增日期解析工具parse_natural_date,统一转为ISO标准格式 |
| 返回完整原始数据 | 返回全文/完整数据库行,上下文Token溢出,模型推理退化 | 固定返回id+摘要snippet,全文仅支持二次单独调取 |
| 隐性副作用风险 | 模型误以为仅预览数据,实际触发发邮件、删数据等高危操作 | 副作用工具统一前缀:send_/delete_/update_,外层增加二次确认 |
| 描述缺少负样本 | 模型无边界意识,任何问题都盲目调用查询类工具 | 所有工具description强制写入禁用场景 |
六: Agent 工具(Tools)工业级实战: 本地工具 + MCP 混合工具底座 架构设计
[ 请参考尼恩团队 《 全球顶级 全栈 AI 架构视频 第十一章 : 手写 工业级harness 基础设施架构实操 》](尼恩团队 AI全栈架构 :0数学 一步登天 精通 深度学习 + 机器学习+ 大模型微调 + Harness 架构 +Agent架构)
6.1、基础概念与分层定位(先分清两类工具边界)
1. 两类工具核心区别
| 维度 | 本地本地工具 Local Tool | MCP 远程工具(MCP Server) |
|---|---|---|
| 运行位置 | DeepAgent 主进程内,Python 函数 / 类 | 独立进程 / 远程 HTTP 服务,进程隔离 |
| 耦合度 | 强耦合,代码同仓,启动即加载 | 松耦合,标准化 JSON-RPC 协议,动态发现 |
| 适用场景 | 高频轻量、低延迟、无外部依赖:时间计算、文本处理、内存检索、轻量校验 | 重型资源、跨服务、跨机器、第三方系统:数据库、文件系统、API 网关、硬件、第三方业务服务 |
| 安全隔离 | 共享 Agent 权限,无独立沙箱 | 独立权限、独立进程,天然隔离,支持授权审批 |
| 扩展方式 | 改代码重启 Agent | 新增 MCP 服务,配置文件注册,无需改 Agent 代码、支持热加载 |
| 标准 | 框架原生 BaseTool / LangChain BaseTool | Model Context Protocol 标准,统一 Schema 自动转换 |
2. 架构顶层目标
【1】统一抽象: 本地工具、MCP 工具对外输出完全一致的 BaseTool 标准对象,LLM/Agent 调度层无感知区分;
【2】分层管控: 加载、路由、权限、限流、监控统一收口;
【3】性能最优: 高频轻量走本地,重型 / 跨服务走 MCP;
【4】安全隔离: 高危操作强制 MCP 隔离,本地仅放无副作用轻量函数;
【5】可扩展: MCP 服务即插即用,本地工具模块化注册。
3. MCP 三层原生架构(Host-Client-Server)适配 DeepAgent
- MCP Host = DeepAgent 主运行时(整个智能体框架)
- MCP Client 池: 框架内置
MultiServerMCPClient,管理所有 MCP 服务长连接、会话、心跳、重连 - MCP Server: 独立工具服务(stdio 本地进程 / HTTP 远程服务),暴露 tools/resources/prompts
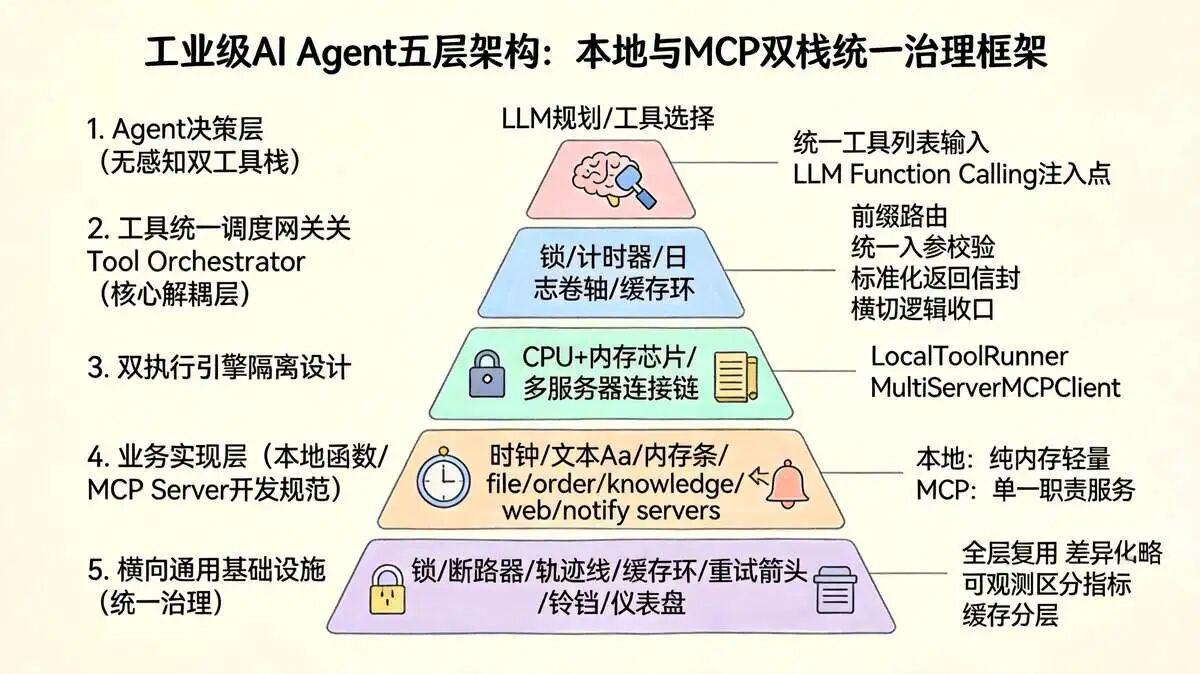
6.2、 工业级Agent Tools 底座 的 五层完整整体架构(自上而下)
┌─────────────────────────────────────────────────────────┐
│ 1. Agent 决策层(DeepAgent Core / LangGraph ReAct) │
│ LLM规划、工具选择、多轮循环、并行调用、最大迭代限制 │
│ 输入:统一工具列表(本地+MCP合并后的标准BaseTool) │
└───────────────────────┬─────────────────────────────────┘
│ 统一标准工具对象
┌───────────────────────▼─────────────────────────────────┐
│ 2. 工具统一调度网关 Tool Orchestrator(核心中间层) │
│ - 工具注册中心、分组路由、动态工具过滤、权限拦截 │
│ - 调用前置校验、参数标准化、调用后置结果格式化、埋点 │
│ - 分流:本地工具 → 本地执行器;MCP工具 → MCP客户端池 │
└─────┬──────────────────────────────┬─────────────────────┘
▼ ▼
┌───────────────┐ ┌─────────────────────────────┐
│3.本地工具执行层 │ │3.MCP客户端管理层MCPClientPool │
│ LocalToolRunner│ │ MultiServerMCPClient 连接池 │
│ - BaseTool实现 │ │ - 多服务长连接、心跳保活 │
│ - 内存缓存、本地校验 │ - list_tools自动拉取工具Schema │
│ - 进程内直接调用 │ - call_tool RPC转发、协议编解码 │
└─────┬─────────┘ └────────────┬────────────────┘
▼ ▼
┌───────────────┐ ┌─────────────────────────────┐
│4.本地业务逻辑层 │ │4.MCP服务层 MCP Server集群 │
│ 纯Python函数 │ │ 独立进程/远程HTTP服务 │
│ 时间、文本、内存检索 │ 文件、数据库、第三方API、硬件 │
└───────────────┘ └─────────────────────────────┘
▲
┌─────────────────────────────────────────────────────────┐
│5. 横向通用基础设施(全层复用) │
│ 权限鉴权、限流熔断、日志追踪、缓存、异常重试、告警、监控 │
└─────────────────────────────────────────────────────────┘
6.3、各层详细设计规范
第一层:Agent 决策层(无感知双工具栈)
(1) 工具合并机制
框架启动阶段:
-
扫描注册所有本地
BaseTool; -
MCP Client 依次连接所有配置的 MCP Server,执行
list_tools拉取远程工具 Schema,自动转换为和本地完全一致的BaseTool对象(langchain-mcp-adapters 自动适配); -
合并为单一全局工具列表,统一注入 LLM Function Calling。
(2) 工具分组路由优化(解决工具过多幻觉)
按四象限分类做动态工具子集注入,减少上下文 Token:
- 高频轻量本地组:
calc_time、text_extract(常驻注入) - 业务查询 MCP 组:
search_knowledge_mcp、query_order_mcp(意图匹配动态加载) - 高危修改 MCP 组:
cancel_order_mcp、file_write_mcp(触发前强制用户确认) - 第三方外部 MCP 组:
web_search_mcp、slack_notify_mcp(按需拉起)
(3) 执行模式统一支持
本地 / MCP 工具均兼容:单轮调用、多轮 ReAct 循环、并行批量调用、LangGraph 声明式流程编排。
第二层:统一调度网关 Tool Orchestrator(核心解耦层)
所有工具调用必经网关,抹平本地与 MCP 差异,统一管控策略:
(1) 统一入参校验
本地工具:Pydantic 本地模型校验;
MCP 工具:远程返回 JSON Schema,网关本地预校验,避免无效 RPC 请求。
(2) 分流路由规则
- 工具名前缀约定规范(强制区分,便于管控):
- 本地工具: 无特殊前缀,
get_current_time、clean_text - MCP 工具: 统一加服务前缀
mcp_file_、mcp_order_、mcp_web_ - 路由逻辑: 匹配前缀转发至 MCP 客户端池;其余走本地执行器。
(3) 统一返回信封标准化
本地、MCP 返回全部包装同一结构,LLM 无需区分来源:
{
"ok": true/false,
"source": "local" | "mcp:server_name",
"data": {},
"error": "",
"hint": ""
}
(4) 横切逻辑统一收口(避免本地 / MCP 两套逻辑)
- 权限校验: 高危 MCP 操作二次鉴权;本地只读工具放宽权限;
- 限流: 按用户、工具类型分别 QPS 限制;
- 埋点日志: 记录工具来源(local/mcp 服务名)、耗时、参数、错误;
- 缓存: 只读工具统一 TTL 缓存,MCP 远程查询缓存命中率提升。
第三层:双执行引擎隔离设计
3.1 本地工具执行引擎 LocalToolRunner
【1】统一父类 BaseLocalTool(BaseTool),强制规范:
-
单一职责、无外部网络 / 文件写入副作用;
-
仅依赖内存、内置 Python 库;
-
轻量化,单调用耗时 < 100ms;
【2】生命周期: Agent 进程启动一次性实例化,常驻内存;
【3】错误处理: 进程内异常直接捕获,网关统一包装错误信封,不崩溃主 Agent。
3.2 MCP 客户端池 MultiServerMCPClient
基于 langchain-mcp-adapters 标准实现,框架内置封装:
(1) 配置中心 .mcp.json 统一管理所有 MCP 服务(stdio 本地进程 / HTTP 远程)
{
"mcpServers": {
"file_server": {"type": "stdio", "command": ["python", "mcp_file_server.py"]},
"order_server": {"type": "http", "url": "http://127.0.0.1:8001/mcp"}
}
}
(2) 生命周期管理(框架自动)
- 启动: 自动拉起 stdio 子进程 / 建立 HTTP 长连接,握手协商能力,拉取工具列表缓存;
- 运行: 心跳检测、断线自动重连、进程守护;
- 停止: 优雅关闭所有 MCP 会话、销毁子进程。
【3】协议屏蔽: 上层完全无感知 JSON-RPC、消息编解码,仅调用标准 run(args)。
【4】隔离保障: 每个 MCP Server 独立会话,无法互相访问资源,天然沙箱。
第四层:业务实现层(本地函数 / MCP Server 开发规范)
规范 1:本地工具仅实现纯内存轻量能力
禁止:数据库读写、文件操作、第三方 API、高危修改;
推荐:时间转换、文本清洗、简单数学计算、本地内存向量检索。
规范 2:MCP Server 承载所有重型 / 有副作用能力,拆分单一服务
一个 MCP Server 只负责一类资源,不混功能:
- mcp-file-server: 本地文件读写、目录遍历
- mcp-order-server: 订单查询、取消、退款
- mcp-knowledge-server: 知识库向量检索
- mcp-web-server: 联网搜索、网页抓取
- mcp-notify-server: 邮件、企业消息推送
MCP Server 使用 FastMCP 快速开发,自动暴露 Schema,无需手动写工具描述。
第五层:横向通用基础设施(统一治理)
【1】安全管控差异化策略:
- 本地工具: 只读为主,权限跟随主 Agent 会话;
- MCP 修改类工具: 独立 OAuth/Token 鉴权、操作日志留痕、调用前用户确认弹窗;
- 注入防护: MCP 服务层拦截 SQL 注入、路径穿越;本地工具输入过滤。
【2】可观测区分指标: 监控指标增加维度 tool_source = local/mcp:
- 本地工具: 平均耗时、内存占用、调用成功率;
- MCP 工具: RPC 往返耗时、服务连接失败率、重连次数、进程崩溃次数。
【3】缓存分层:
- 本地工具: 内存 LRU 缓存;
- MCP 只读查询: 分布式 Redis 缓存,配置独立 TTL。
6.4、完整调用流程示例(混合调度)
用户提问:查2026年5月订单,并把订单商品摘要整理成文本
【1】Agent LLM 读取合并后的全局工具列表:
- MCP 工具:
mcp_order_lookup(查订单) - 本地工具:
clean_text_summary(文本整理)
【2】LLM 规划两步调用: 先查远程订单,再本地文本清洗;
第一步: 调用 mcp_order_lookup
-
网关识别前缀 mcp_ → 转发 MCP 客户端池;
-
Client RPC 发送
call_tool至 order MCP 服务; -
MCP 服务查数据库返回摘要数据;
-
网关统一包装返回信封
source:"mcp:order_server";
第二步: 拿到订单数据后调用本地 clean_text_summary
-
网关无 mcp 前缀,转发本地执行器;
-
进程内直接执行文本处理函数;
-
返回信封
source:"local";
【3】Agent 汇总两次工具结果,生成最终回答。
七、参考实现
请参考尼恩团队 《 全球顶级 全栈 AI 架构视频 第十一章 : 手写 工业级harness 基础设施架构实操 》
八、生产级避坑与优化方案
(1) MCP 服务过多,工具总量爆炸,LLM 调用幻觉严重
方案:分层路由 Router Agent,按意图动态加载对应 MCP 工具组,不一次性注入全部工具。
(2) 频繁短查询走 MCP 导致 RPC 延迟高
方案:高频轻量查询下沉改造为本地工具;低频重型查询保留 MCP 隔离。
(3) MCP 服务进程崩溃导致工具不可用
方案:客户端池自动健康检测、断线重连、进程自动重启,调用失败返回标准化 hint 引导重试。
(4) 本地工具与 MCP 工具返回格式不统一,LLM 混淆
方案:调度网关强制统一返回信封,抹平两端数据差异。
(5) 高危操作本地执行无隔离,存在安全风险
强约束:文件读写、数据库修改、消息发送全部迁移至独立 MCP Server,禁止本地实现。
(6) 新增工具需要重启整个 Agent
方案:MCP 支持热加载;本地模块化工具支持动态注册接口,无需重启主进程。

欢迎加入 MCP 技术社区!与志同道合者携手前行,一同解锁 MCP 技术的无限可能!
更多推荐



 2
2 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)