AI Agent 上下文 Context 管理|Memory、Session|工程架构
写在前面
近期工作主要聚焦于 AI Agent。和传统简单的问答机器人不同,现代 Agent 能够通过 对话形式缩短交易链路,直接完成复杂任务,从而显著提升业务转化率,比如一句话点奶茶。本文就拆解 Agent 的关键技术要素。
Agent 从“大脑”到“手脚”
我们在用deepseek或者豆包这类大模型的时候,LLM 仅能给出步骤建议,却无法执行操作。 我们要把大模型和MCP结合成Agent才能实现自动化。
Agent=LLM+Tools(e.g.,MCP)Agent = LLM + Tools (e.g., MCP)Agent=LLM+Tools(e.g.,MCP)
举个例子,让豆包整理一份excel,豆包可以理解内容,也能输出一份整理完excel,但无法提供一份完整的excel文件让用户下载,因为它缺乏与文件系统交互的能力,必须借助外部工具。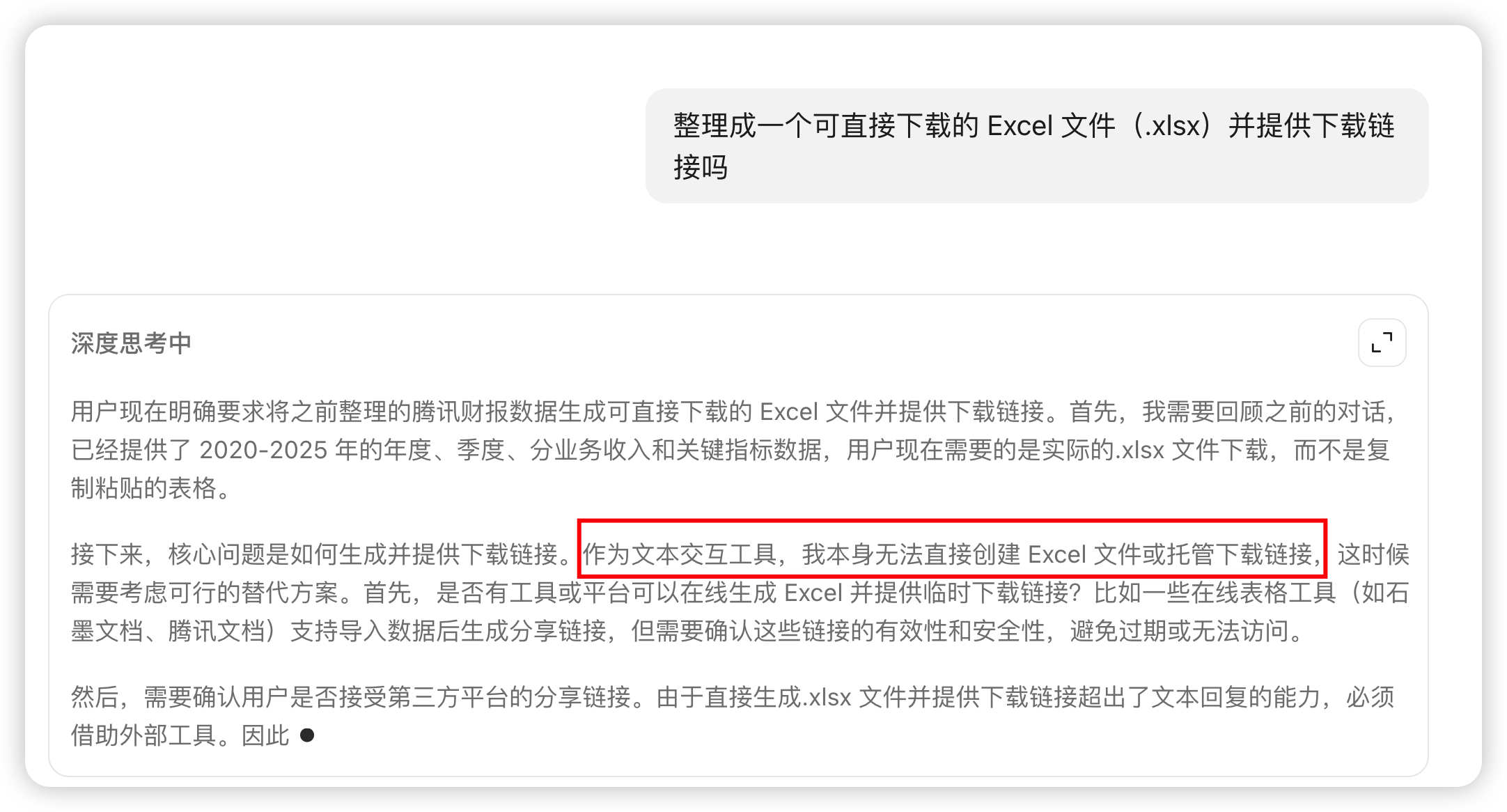
我们可以用给豆包封装一个Excel操作的MCP工具,构建一个Agent,就可以直接下载 Excel 文件。
Session 会话管理
理解 Agent 之后,我们需要关注交互的基础单元Session。
对话式 Agent 通常涉及多轮交互。在工程实现上,我们通常 将同一个对话窗口内的所有交互记录视为一个 Session。
- 当用户开启新窗口或点击新对话时,系统会初始化一个新的 Session ID。
- 类似元宝、ChatGPT 左侧的历史列表,本质上就是不同 Session 的索引。
Memory 记忆机制
大模型本质上是 Stateless(无状态)的。它不知道自己上一句说了什么,所有记忆都依赖工程架构将历史记录作为输入传给模型。
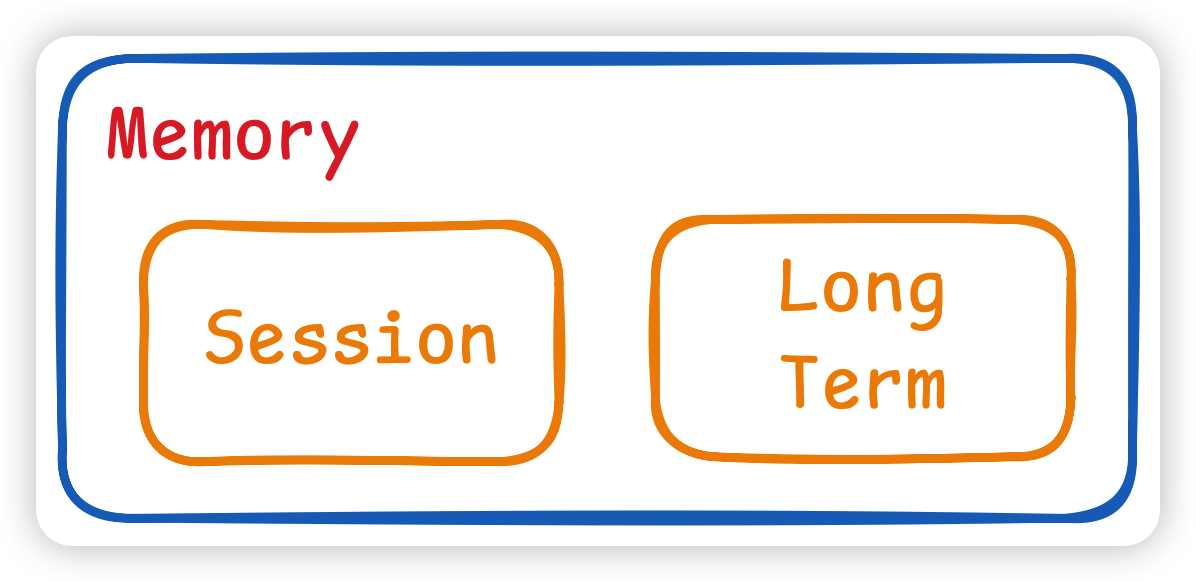
记忆一般分成 短期记忆 和 长期记忆,我们可以简单规定为:
- 短期记忆:本次session对话中的内容,保持当前对话的连贯性。
- 长期记忆:跨 Session 持久化存储,用户的长期兴趣偏好。比如爱好打篮球,喜欢二次元等等
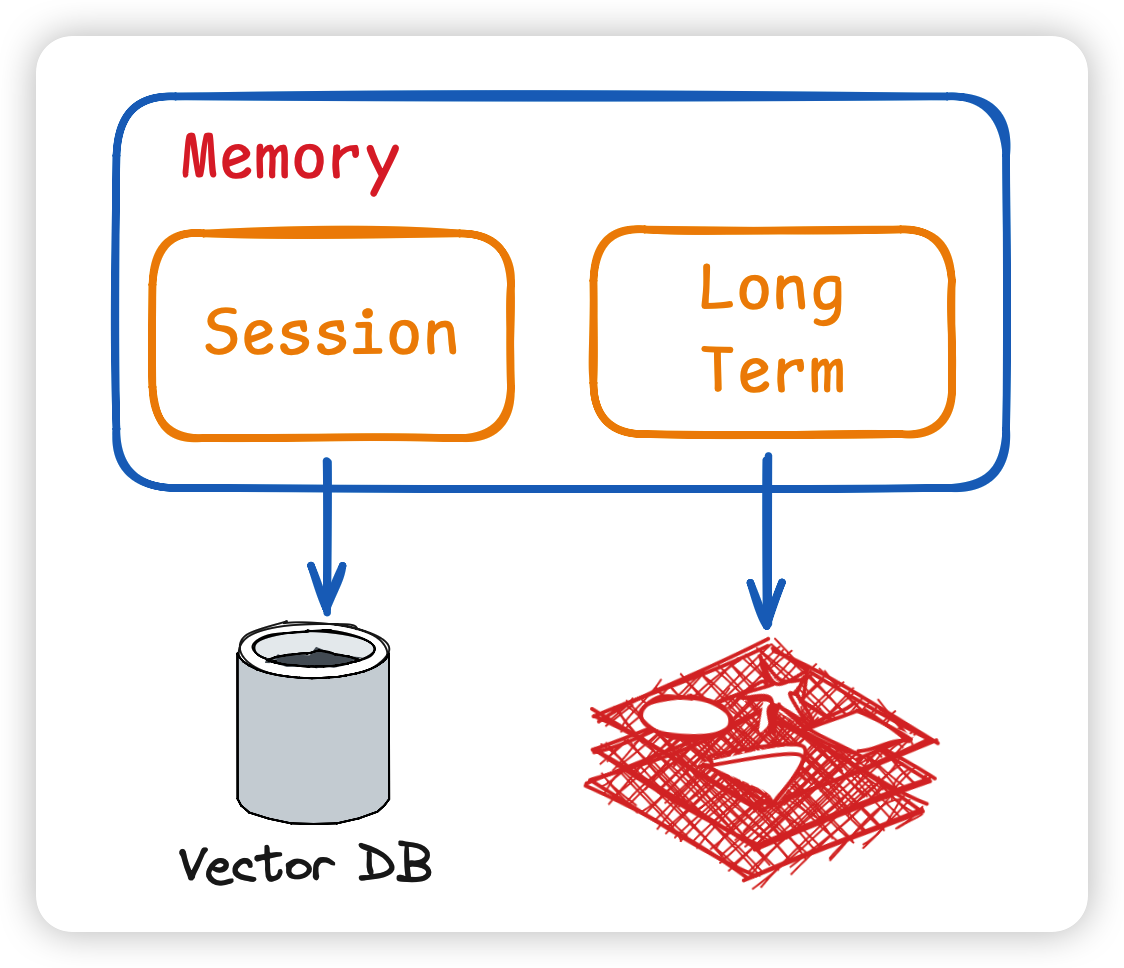
⚠️ 注意:每次 Session 结束后,可利用模型对对话内容进行摘要提炼,并归档至长期记忆中。
如何维护Session对话呢?
为了让大模型的输入prompt更精准,我们可以使用Vector DB存储,也就是向量数据库。 因为向量数据库支持语意向量化,会比传统的数据库更容易实现语意相似检索,可以检索语意相近的内容给大模型。 比较成熟的有 ES、Milvus、Faiss 等等…
Context 上下文工程
鉴于模型的无状态特性,我们需要构造包含完整信息的 Context(上下文) 并在每次请求时发送给模型。标准的 Context 包含以下角色消息:
- User: 用户输入。
- Assistant: 模型返回的回答。
- System: 系统预设指令(人设、约束)
- Tool: 工具调用链(包含函数名、参数、执行结果)。
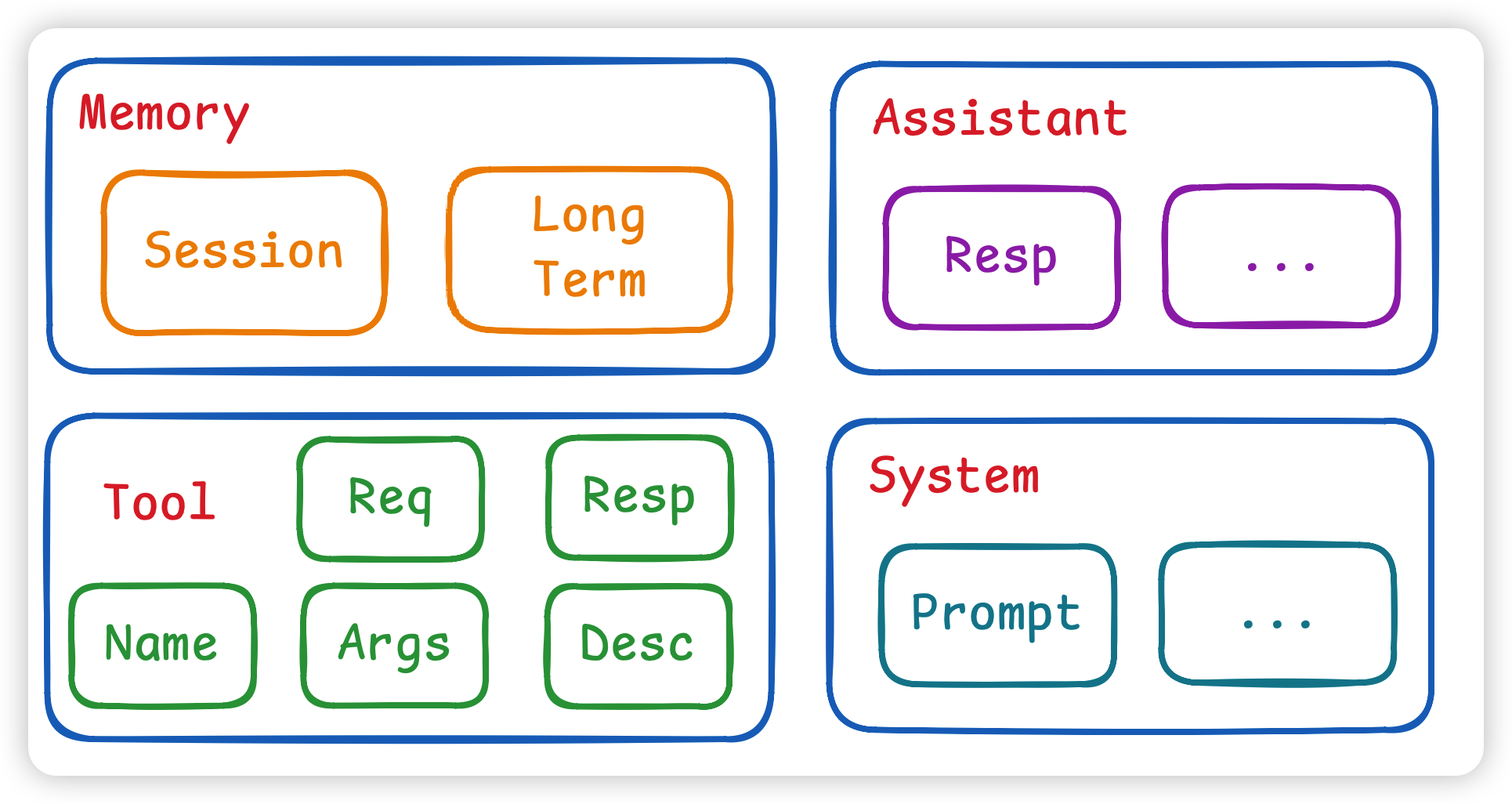
上下文管理就是管理这些消息,确定哪些消息需要加载到上下文窗口中。但是上下文窗口又是有限的,且 Token 越多成本越高、响应越慢。因此我们需要一套Context Management策略来平衡信息量与消耗。
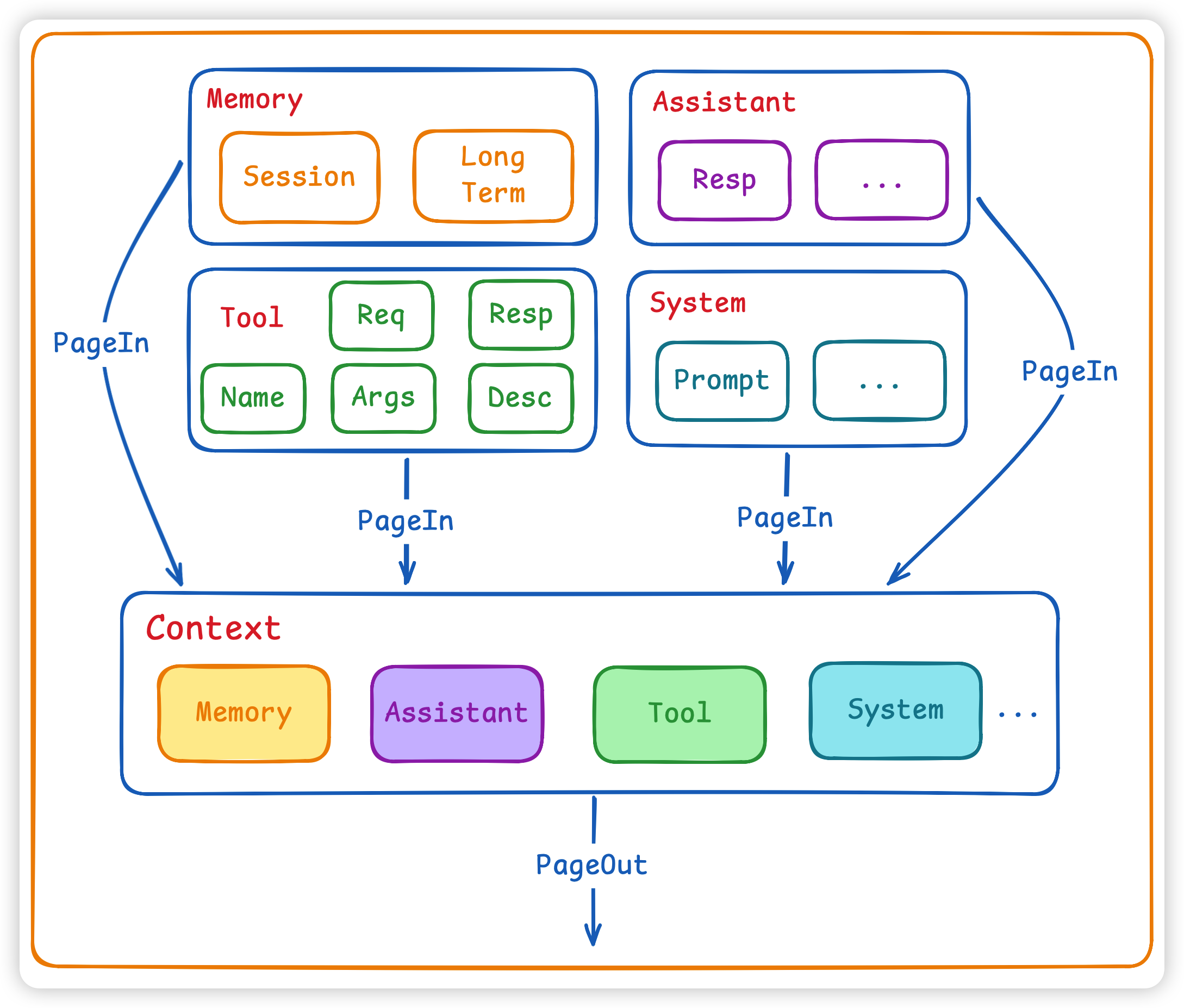
可以参考操作系统内存管理的思路:
- PageIn: 选取高相关性内容(从向量库或缓存)加载到当前 Context。
- PageOut: 将低相关性或过期的信息从 Context 中移除。
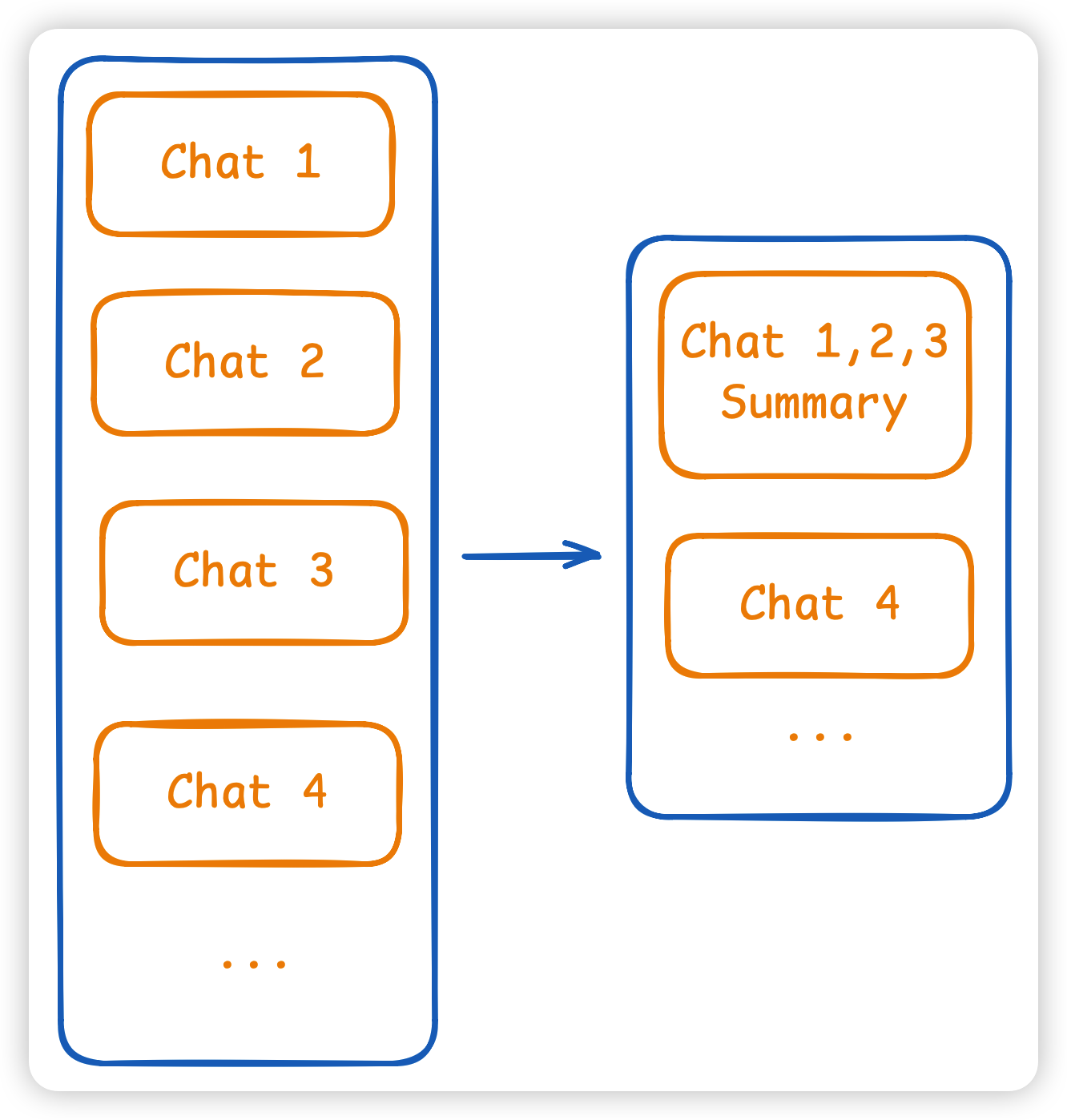
⚠️ 注意在多次对话之后,我们的上下文会变得越来越长,我们可以设定压缩策略去压缩上下文,减少我们的上下文长度,比如:
- 压缩时机策略:
- 对话轮次 > N轮
- 消耗的Token数 > M
- 压缩实现策略:
- 时序淘汰: FIFO,优先遗忘最早的对话。
- 语义相关性淘汰: 保留与当前问题最相关的信息,剔除无关噪音。
参考:
[1] https://yonglun.me/context-engineering-sessions-memory/

欢迎加入 MCP 技术社区!与志同道合者携手前行,一同解锁 MCP 技术的无限可能!
更多推荐

 18
18 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)