OpenClaw 实战 #04:如果一个 Agent 不能被长期运行,那它就只是一个高级聊天框
这是我第一次,敢去设计一个“可以被长期运行的 Agent”。
注意这里的措辞:
不是“已经 24×7 跑在后台”,
而是——
在工程层面,满足长期后台运行条件的 Agent。
不是 Demo,
不是玩具,
也不是为了炫技。
而是一个:
在引入调度机制之后,我敢放心交给系统去跑的 Agent。
在前两篇里,我已经解决了两件事:
- OpenClaw 是什么,适合干什么
- 如何用最小成本把它跑起来
但真正的分水岭,在这一篇。
这一篇不谈“效果炫不炫”,
只谈一件事:
如何从工程角度,正确地设计第一个“可放心自动运行”的 Agent。
一、为什么我没有一上来就做「自动整理 Downloads」
很多人一想到 Agent,第一反应是:
“让它帮我把 Downloads 整理干净。”
我一开始也这么想过,
甚至脚本都写好了。
但最后,我把代码删了。
原因只有一个:
👉 这是一个对「第一个 Agent」来说,失败成本极高的场景。
从工程视角看,它几乎踩中了所有反模式:
- ❌ 自动 move / rename,本质是破坏性操作
- ❌ 一旦出错,恢复成本极高
- ❌ 你会忍不住反复确认、反复盯着
- ❌ 最终结局往往是:你不敢把它交给系统长期跑
而我想要的不是:
“一个很能干的 Agent”
而是一个:
在工程上,我敢让它长期存在的 Agent。
二、我重新定义了「第一个可用 Agent」的 4 条工程硬标准
在真正写代码之前,我给自己定了 4 条不可妥协的工程标准。
这 4 条,决定了它是否有资格被长期运行。
✅ 1. 永远不动「重要状态」
- 不改文件
- 不删东西
- 不写数据库
第一个 Agent,必须是只读的。
这是工程安全的起点。
✅ 2. 出错成本必须接近 0
即使模型判断错了,最坏结果也只能是:
- 多提醒一次
- 或少提醒一次
不能出现任何“做错一次就要回滚”的情况。
✅ 3. 它省的是「注意力」,不是「体力」
- 不是“帮我干活”
- 而是帮我决定:要不要操心
这是 Agent 和自动化脚本的本质区别。
✅ 4. 工程上允许长期运行
注意这里的表述是:
允许长期运行(capable of long-running)
而不是“已经在后台跑”。
它意味着:
- 不依赖人工确认
- 不需要我盯着日志
- 行为边界清晰、可预期
这是能力层,而不是运行态。
三、第一个真正适合这个标准的 Agent 场景
当这 4 条同时成立后,第一个浮现出来的场景是:
👉 下载目录清理「提醒」Agent
注意关键词:提醒。
它明确不做这些事:
- ❌ 不整理文件
- ❌ 不分类、不重命名
- ❌ 不 move、不 delete
它只做一件事:
判断:现在要不要提醒我「该清理 Downloads 了」?
这是一个人类极其擅长拖延、
但又极其适合 Agent 接管判断的问题。
四、这个 Agent 在工程上只干三件事
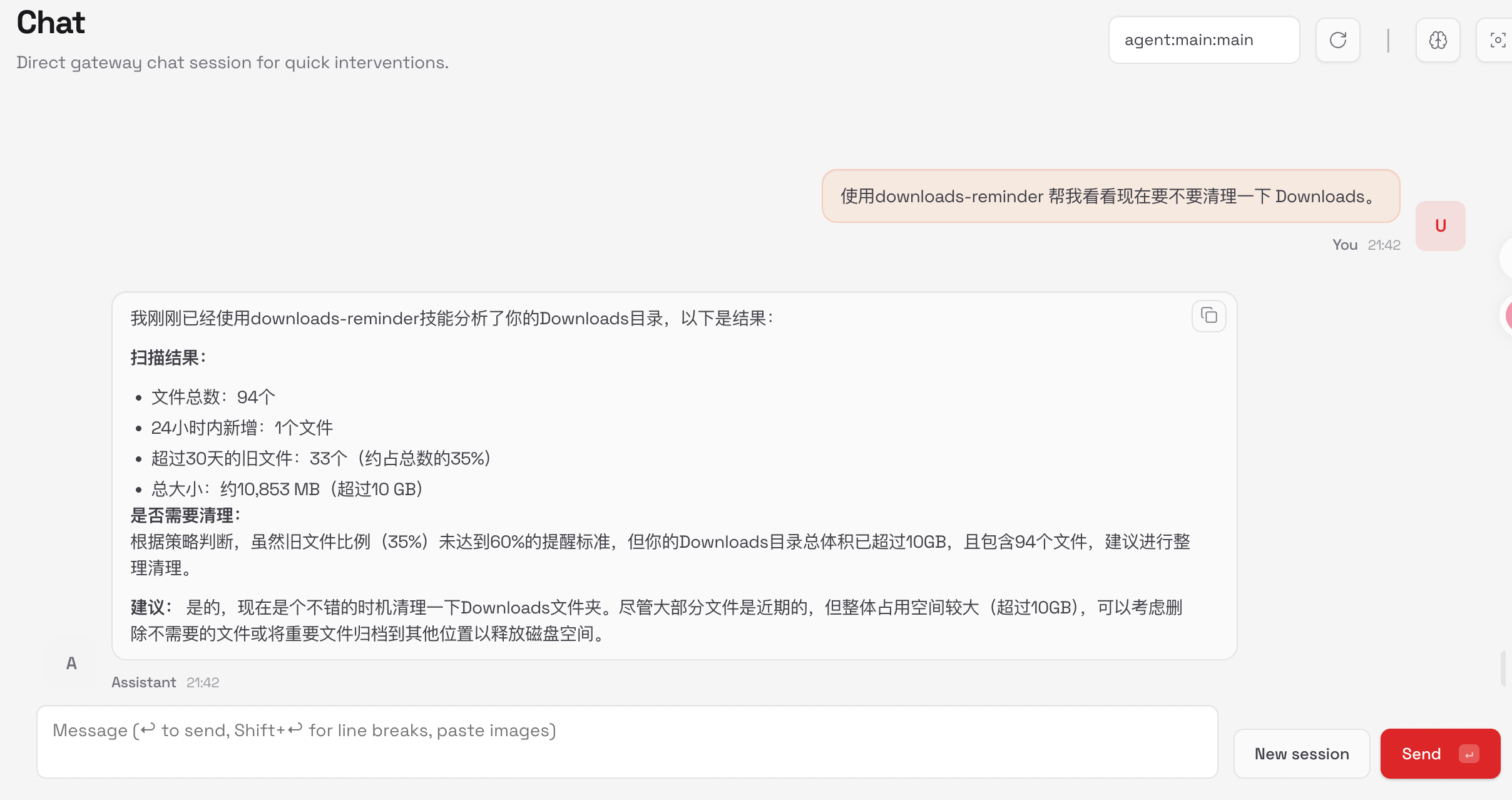
1️⃣ 扫描 Downloads(只读)
只采集客观事实,不做任何判断:
- 文件总数
- 最近 24 小时新增文件数
- 超过 30 天的旧文件数
- 总体积(MB)
2️⃣ 判断「是否值得提醒」
不是简单阈值,而是组合判断:
- 文件很多,但最近新增不多
→ 可能已经很久没整理 - 文件不算多,但 80% 都是 30 天前的
→ 很可能是长期垃圾堆积 - 最近刚下了一堆新文件
→ 现在提醒只会打断节奏
3️⃣ 输出一个决策结论
输出的是:
👉 要不要提醒?为什么?
而不是动作。
五、为什么这是 Agent,而不是脚本
如果是脚本,逻辑通常是:
if file_count > 100:
notify()而 Agent 做的是判断:
“虽然文件很多,但最近 24h 新增也很多,
说明你正在集中下载资料,
现在提醒你只会打断节奏。”
这是语义判断,不是规则触发。
这就是 Agent 和自动化脚本之间的分界线。
六、最小但正确的 OpenClaw Skill 工程结构
最终我采用的结构是:
skills/downloads-reminder/
├── SKILL.md
├── tools/
│ └── scan.py
└── rules/
└── policy.yaml从工程角度看,它非常克制:
- 没有多阶段流程
- 没有 apply
- 没有 taxonomy
- 没有任何副作用
但它已经是一个:
工程上完整、行为受控、可被长期运行的 OpenClaw Skill。
七、SKILL.md 技能说明
---
name: downloads-reminder
description: Decide whether to remind user to clean Downloads directory
metadata:
openclaw:
skillKey: downloads-reminder
---
## Purpose
This Skill is designed to **decide whether the user should be reminded**
to clean their Downloads directory.
It does NOT:
- organize files
- move files
- rename files
- delete files
It only makes a **reminder decision**.
---
## Safety Rules (Hard Constraints)
1. **Never modify any file or directory**
2. **Never delete or overwrite files**
3. **Never operate outside the given Downloads path**
4. **Never perform destructive actions**
5. **Only read filesystem metadata**
6. **Only produce a reminder decision**
If any requested action violates these rules, the Skill must refuse.
---
## Allowed Tools
This Skill is allowed to call **only one tool**:
- `tools/scan.py`
This tool:
- scans the Downloads directory
- collects objective statistics
- does NOT perform any file operations
No other tools are permitted.
---
## How to Act
When this Skill is invoked, follow this process strictly:
1. Call `scan.py` to collect directory statistics
2. Evaluate the result together with `rules/policy.yaml`
3. Decide **whether a reminder is necessary**
4. Provide:
- a boolean decision (`notify: true | false`)
- a short, clear reason
---
## Decision Output Format
The Skill must output a structured decision in JSON:
```json
{
"notify": true,
"reason": "Explain why a reminder is or is not necessary"
}
一句话总结:
Skill 不是功能说明书,而是权限清单。
八、scan.py:只做事实,不做判断
这个脚本的设计原则只有一句话:
脚本负责“测量世界”,判断交给模型。
#!/usr/bin/env python3
from __future__ import annotations
from pathlib import Path
import argparse
import json
import sys
import time
def scan_downloads(path: Path):
now = time.time()
files = [f for f in path.iterdir() if f.is_file()]
return {
"file_count": len(files),
"new_24h": sum(1 for f in files if now - f.stat().st_mtime < 86400),
"old_30d": sum(1 for f in files if now - f.stat().st_mtime > 30 * 86400),
"total_size_mb": round(
sum(f.stat().st_size for f in files) / 1024 / 1024, 2
)
}
def _json_print(obj: dict) -> None:
# Tool/CLI 场景:stdout 输出机器可读 JSON
print(json.dumps(obj, ensure_ascii=False))
def main(argv: list[str]) -> int:
parser = argparse.ArgumentParser(
description="Scan Downloads directory and output stats as JSON."
)
parser.add_argument(
"--path",
type=str,
default=str(Path.home() / "Downloads"),
help="Directory to scan (default: ~/Downloads)",
)
args = parser.parse_args(argv)
target = Path(args.path).expanduser().resolve()
if not target.exists():
_json_print({"error": f"path not found: {str(target)}"})
return 2
if not target.is_dir():
_json_print({"error": f"not a directory: {str(target)}"})
return 2
try:
result = scan_downloads(target)
_json_print(result)
return 0
except PermissionError as e:
_json_print({"error": "permission denied", "detail": str(e), "path": str(target)})
return 3
except Exception as e:
_json_print({"error": "scan failed", "detail": str(e), "path": str(target)})
return 1
if __name__ == "__main__":
raise SystemExit(main(sys.argv[1:]))工程要点:
- ✅ 只读文件元数据
- ✅ 输出结构化 JSON
- ❌ 不做任何判断
- ❌ 不产生任何副作用
这也是它具备长期运行资格的根本原因。
九、policy.yaml:规则不是大脑,只是护栏
notify:
min_file_count: 80
min_old_ratio: 0.6
max_new_24h: 5
min_total_size_mb: 500这些规则的作用只有一个:
防止 Agent 在明显不该提醒的时候乱说话。
在工程语义里,它们是:
- guardrails
- 而不是决策逻辑本身
十、模型在这里真正承担的职责
模型拿到的,只是一段结构化数据:
{
"file_count": 132,
"new_24h": 2,
"old_30d": 98,
"total_size_mb": 1240
}然后被问了一个非常克制的问题:
现在要不要提醒用户清理 Downloads?为什么?
没有文件操作
没有系统修改
没有自动化魔法
它只在做一件事:
判断,而不是执行。
十一、第一个 Agent 的工程安全底线
这是我给第一个 Agent 设定的不可突破边界:
- ❌ 不操作文件
- ❌ 不改变系统状态
- ❌ 不依赖人工确认
- ✅ 只输出建议型结果
一句话总结:
第一个 Agent 的目标,不是“多能干”,
而是“值得被长期运行”。
十二、通过这个小应用,真正体验 OpenClaw 的本质
很多人在用 OpenClaw 的时候,会下意识把注意力放在:
- 能不能自动整理文件
- 能不能一步到位做复杂流程
- 能不能“看起来很智能”
但这个下载目录提醒 Agent,真正想让你体会的不是这些。
它是一个刻意被“压到最小”的应用。
而正是这个“最小”,让 OpenClaw 的本质第一次变得清晰。
1️⃣ OpenClaw 的价值不在“它帮你做了什么”
而在于:
它在什么时刻选择了“不做”。
这个 Agent 绝大多数时间什么都不说、什么都不干。
但你会慢慢发现:
- 你不再需要“记得去整理 Downloads”
- 你也不再被频繁打断
- 注意力被悄无声息地释放了出来
这是脚本永远给不了你的体验。
2️⃣ 你第一次感受到:Agent ≠ 自动化脚本
在这个应用里:
- scan.py 只是测量事实
- policy.yaml 只是兜底规则
- 真正做决策的,是 Agent 在“是否值得打扰你”这件事上给出的判断
它没有做任何复杂事,却完整地体现了 Agent 的三件核心能力:
- 能持续运行
- 能在无人看管时做判断
- 能在“该沉默的时候保持沉默”
这就是 OpenClaw 的设计哲学。
因为它解决的不是“技术问题”,而是一个更底层的工程痛点:
失控成本。
- 自动化脚本,一旦写错就是破坏性操作
- 复杂 Agent,一旦权限太大你就不敢一直开
- Demo 能跑,但没人敢上线
而 OpenClaw 从设计上就默认:
- Agent 可以长期存在
- Agent 会经常什么都不做
- Agent 必须在“无事可做”时保持沉默
当你第一次发现:
“我已经好几天没想过这个 Agent 了,
但它还在默默帮我盯着。”
你就会理解,它为什么能爆火。
3️⃣ 你开始理解:为什么 OpenClaw 要把「安全」放在第一位
这个 Agent:
- 不操作文件
- 不改变系统状态
- 不需要人工确认流程
结果反而是:
你敢一直开着它。
这件事一旦发生,后面的世界就完全不一样了。
因为只有当 Agent 能长期存在,它的价值才会开始累积。
4️⃣ 这是你走向“真正 Agent 系统”的第一个台阶
这个 downloads-reminder 并不是终点。
但它帮你完成了三次关键的心智转变:
- 从“我要让 AI 干活”
→ “我要把判断权交出去” - 从“一次性执行”
→ “长期、稳定、无人值守” - 从“功能优先”
→ “安全与信任优先”
当你真正理解并接受这三点时:
你已经准备好,进入 OpenClaw 的下一阶段了。

欢迎加入 MCP 技术社区!与志同道合者携手前行,一同解锁 MCP 技术的无限可能!
更多推荐
 12
12 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)