大模型开发(四):技术原理与行业实战
1、Agent 介绍
AI Agent,称为人工智能代理,或者称为 AI 智能体。它是一种模拟人类智能行为的人工智能系统,以大型语言模型(LLM)作为其核心规划决策引擎。能够感知环境,做出决策,并执行任务以实现特定的目标。
举例
通俗说,可以将 Agent 智能体比作一个自动执行任务的小助手。它利用人工智能技术来完成特定的活动或作业。想象一下,你有一个看不见的机器人,它可以根据你的命令或者自己的判断来帮你做事。这个看不见的机器人就是我们说的 “智能体”。
举个例子,想象你在家里用智能音箱(如天猫精灵或小米小爱同学),你说:“帮我播放今天的新闻。” 智能音箱就会根据你的命令,从网络上获取最新的新闻,并通过音箱播报出来。
这时,智能音箱就是一个智能体,它感知到了你的语音命令,然后在数字环境中获取新闻信息,并执行了播放新闻的任务。
甚至,你打开抖音,帮你推荐你喜欢的视频,其实抖音 app 就是一个智能体,它感知了你的兴趣爱好和用户行为,然后给你推荐视频,让你体验数字娱乐
原理
Agents 定义为:LLM + memory + planning skills + tool use,即大语言模型、记忆、任务规划、工具使用的集合
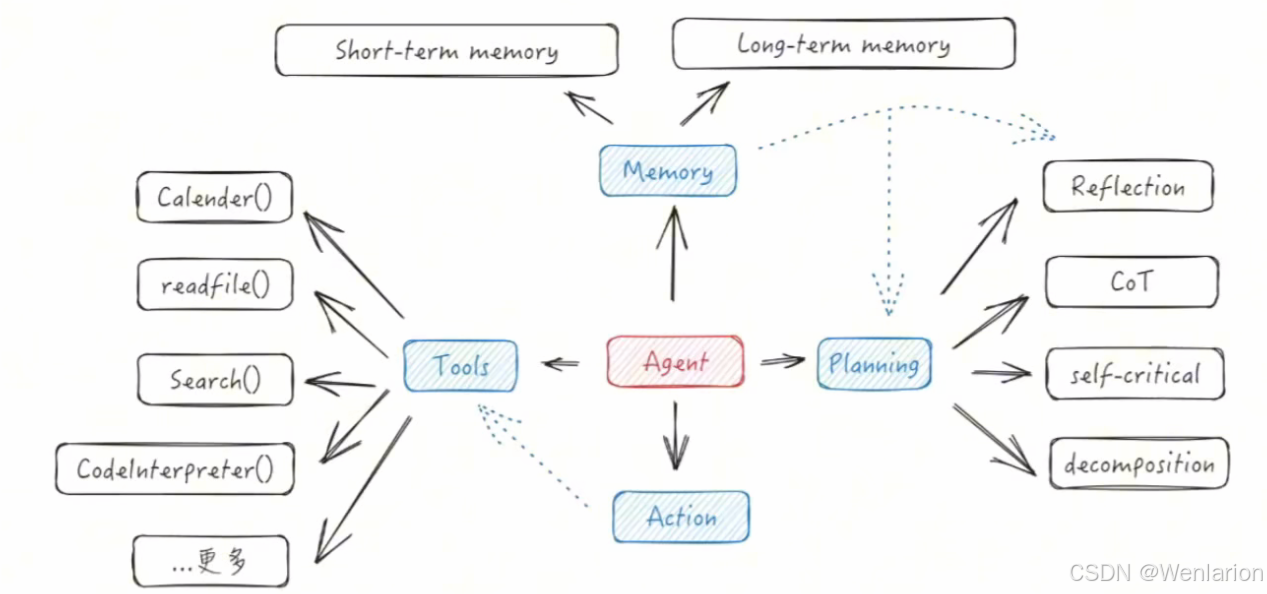
架构
吴恩达分享的 AI Agents 设计模式:
感知(Perception)
- Agent 通过感知系统从环境中收集信息,这些信息可以是文本、图像、声音等多种形式。
- 感知是 Agent 理解周遭世界的第一道工序
规划(Planning)
- 对问题进行拆解得到解决路径,即进行任务规划,类似于思维链,分解复杂任务,找到路径
使用工具(Tool Use)
- 评估自己所需的工具,进行工具选择,并生成调用工具请求
- 这些行动可能是物理的,如机器人的移动,也可能是虚拟的,如软件系统的数据处理、电脑里未归档文件的归档
协作(Multiagent Collaboration)
- 多 Agent,不同类型的助理(agent),可以通过协作组成一个团队或一家公司
记忆(memory)
- 短期记忆包括提示词上下文、工具的返回值、已经完成的推理路径;长期记忆包括可访问的外部长期存储,例如 RAG 知识库
任务规划
-
子目标 & 拆解(Subgoal and decomposition)我们处理问题时会采用 “分治” 的思想,将复杂任务拆解成一个个小任务处理。在 Agent 的实现中也是如此,一个复杂任务很难一次性解决,需要拆分成多个并行或串行的子任务来求解,从而提升处理复杂问题的能力。这个在 Agent 的实现中也是一样,一个复杂任务不太可能一次性就能解决,需要拆分成多个并行或串行的子任务来进行求解,从而提升处理复杂问题的能力。
-
反思 & 完善(Reflection and refinement)Agent 能够对过去的行动决策进行自我反思,完善过去的行动决策并纠正以前的错误来迭代改进。ReAct 提示词技术就是很经典的反思和完善过程。结合 ReAct 提示词技术的 Agent 会在执行下一步 action 的时候,加上 LLM 自己的思考过程,并将思考过程、执行的工具及参数、执行的结果放到 prompt 中,让 LLM 对当前和先前的任务完成度有更好的反思能力,从而提升模型的问题解决能力。
ReAct 的提示模板,大致格式如下:
Thought: ...
Action: ...
Observation: ...
...(重复以上过程)记忆
记忆可以定义为用于获取、存储、保留以及随后检索信息的过程。
-
短期记忆(Short-Term Memory (STM))可以理解为多轮对话的上下文窗口,受到 Transformer 有限上下文窗口长度的限制,所以尽管对话很长,短期记忆理想情况只保留大模型能够处理的上下文窗口的上限;如果是先进先出(first in first out)的模式,则只保留最近的几次对话内容。
-
长期记忆(Long-Term Memory (LTM))可以理解为外置知识库,在 Agent 处理任务的过程中作为额外检索数据的地方。
工具使用
尽管大语言模型在预训练阶段学习了大量的知识,但只能与大模型 “纸上谈兵”,它只会说、不会做,同时也不能回答一些如天气、时间之类的简单问题。Agent 对于工具的使用就是弥补大模型只说不做的缺陷。Agent 可以调用外部 API 来获取模型权重中缺失的额外信息,包括当前时间、地理位置信息、代码执行能力、对专有知识库的访问等。
Agent 的工作机制
【接收任务】用户提交任务给 Agent。
【组装提示词】Agent 收到用户提交的任务之后,对输入信息进行架构处理并合并为最终的 prompt。
【与大模型交互】Agent 将处理后的 prompt 提交给 LLM,拿到下一步需要执行的动作和思考过程。
【循环执行】Agent 会执行 LLM 返回的 Action、观察评估结果、获取下一步 Action。执行的过程中会自主判断是否需要使用工具来处理 Action 或者获取额外的信息。应用领域
AI Agent 技术已广泛应用于多个领域,包括但不限于:
- 客户服务(Customer Service):自动回答客户咨询,提供个性化服务。
- 医疗诊断(Medical Diagnosis):辅助医生进行疾病诊断和治疗方案推荐。
- 股市交易(Stock Trading):自动化交易系统,根据市场数据做出买卖决策。
- 智能交通(Intelligent Transportation):自动驾驶车辆和交通管理系统。
- 教育辅导(Educational Tutoring):个性化学习助手,根据学生的学习进度提供辅导。
程序开发范式变化
本质上,所有的 Agent 设计模式都是将人类的思维、管理模式以结构化 prompt 的方式告诉大模型来进行规划,并调用工具执行,且不断迭代的方法。从这个角度来说,Agent 设计模式很像传统意义上的程序开发范式,但是泛化和场景通用性远大于传统的程序开发范式。在 Agent 设计模式中,Prompt 可以类比为 Python 这类高级编程语言,大模型可以类比于程序语言编译 & 解释器
大模型时代,AI agent 编程给 IT 行业带来的革命性改变
1. 传统编程语言时代
以 Java、C++、Rust 等语言为典型代表,这个时代的软件开发最重要的一件事就是 **“抽象建模”**。产品经理或技术经理需要深刻理解现实世界的业务场景和需求,将其转化为逻辑流与数据流的处理逻辑,用编程语言进行抽象描述,并明确定义输入输出的字段和格式。随后将软件代码部署在 VM 平台上,通过 UI 交互向用户交付价值。
2. ML/DL 编程时代
在传统编程时代,面对图像识别、长文本处理等超高维复杂问题时,if-else 逻辑范式几乎失效。神经网络技术出现后,程序员可以通过训练神经网络(相当于开发程序)来解决这类问题。但在该范式下,现实业务场景与软件代码逻辑之间仍存在巨大鸿沟,建模、UML 流程图等传统步骤依然阻碍了软件的大规模应用。
3. AI Agent 编程时代
进入大模型编程时代,现实世界与软件逻辑世界的鸿沟被大幅缩短。原本用于描述现实世界的自然语言、图片、音频等模态信息,可以直接以 “代码” 形式被大模型这个新型解释器执行。可以这么说,在 AI Agent 编程时代,改变的是建模范式,不变的是数据流和逻辑流。
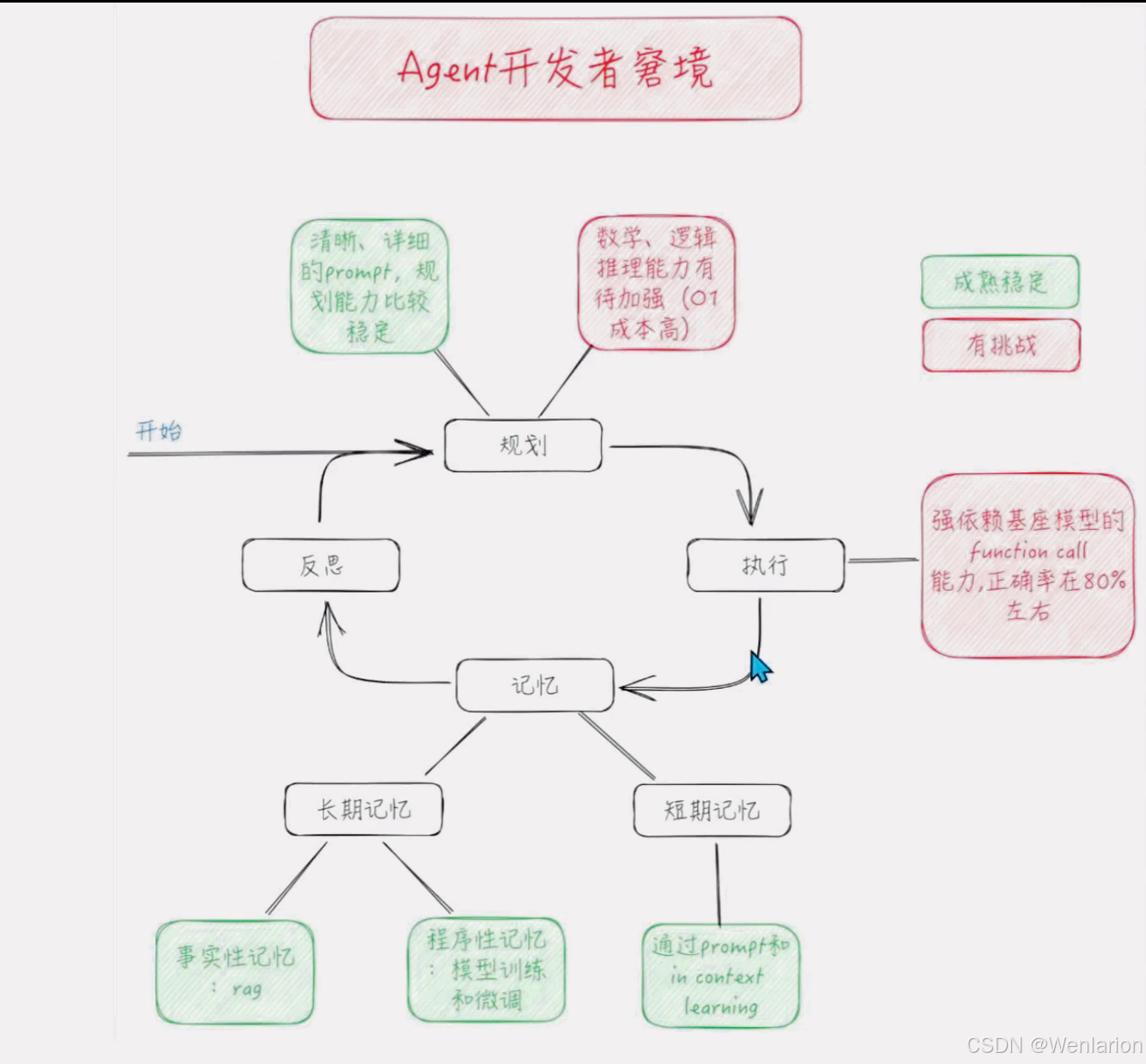
Agent 开发注意事项
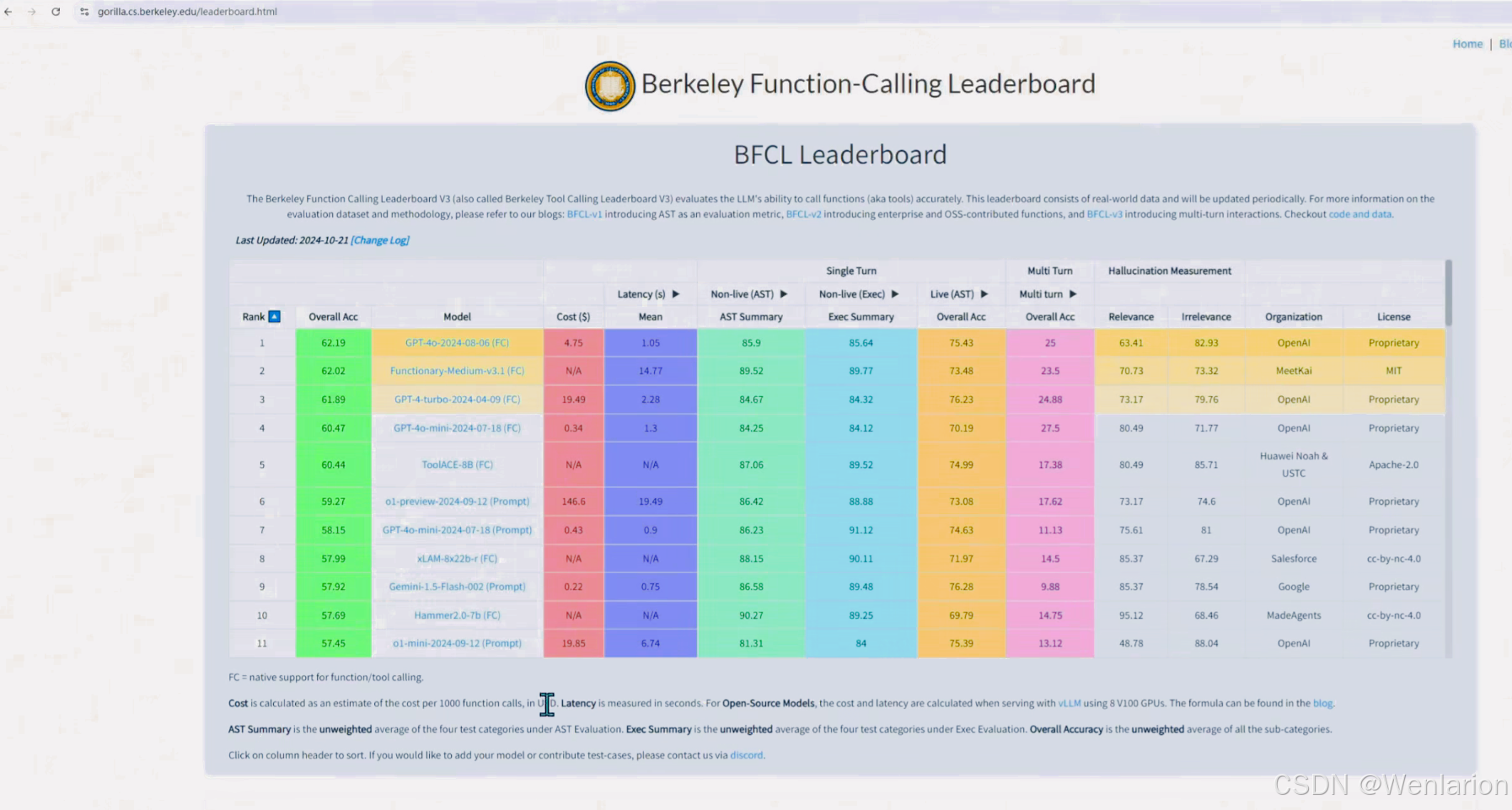
function calling 榜单:https://gorilla.cs.berkeley.edu/leaderboard.html
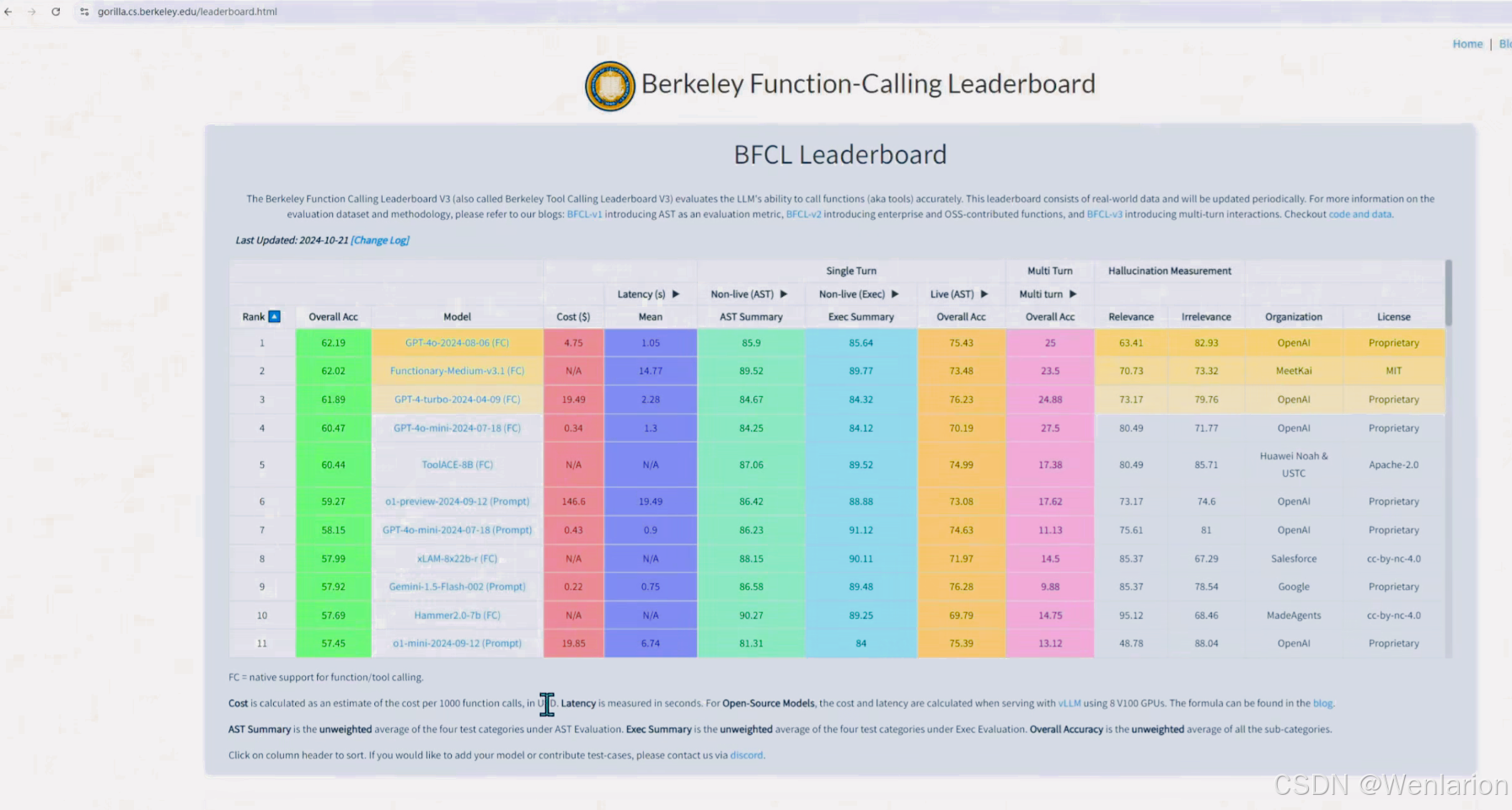
在实际应用场景中进行 Agent 开发之前,有一些关键点需要注意和确认:
-
规划能力依赖 Prompt 工程能力
- Agent 的规划能力高度依赖 Prompt 工程,这比想象中更重要,执行也更琐碎。
- 目前 LLM 的数学、逻辑推理能力在思维链(COT)基础上仅能达到及格水平,因此不要让 Agent 一次性处理复杂的推理性规划,建议人工拆解复杂任务后再交给 Agent(这一点会随模型迭代而弱化)。
-
Action 能力依赖基座模型的 function calling 能力
- 在规划 Agent 之前,必须充分调研基座模型的 function calling 能力。
- 加州大学伯克利大学发布的 function calling 榜单(https://gorilla.cs.berkeley.edu/leaderboard.html)显示,表现最好的 GPT-4 准确率仅为 86%,仍不够理想。
-
记忆分为短期记忆和长期记忆
- 短期记忆由 Prompt 负责(上下文学习,in-context learning),类似 “Plan and resolve” 模式中的 “碎碎念”,用来告知 Agent 已完成的内容和原始目标。
- 长期记忆中,事实性记忆通过 RAG(外部知识库)实现,程序性记忆可通过微调或增量预训练实现(向模型中注入知识)。
-
反思能力依赖记忆能力
- Agent 的反思能力建立在其记忆能力之上,需要依赖记忆来回顾和优化过去的决策。
上述几点正好对应着 Agent 的四大核心能力:规划、反省、记忆、执行。
用一张图来表示,其中绿色代表对 Agent 开发友好,红色代表对 Agent 应用开发有一些难以逾越的阻碍因素,需要靠产品降级来解决。
2、 提示词工程
论文:《The Prompt Report: A Systematic Survey of Prompting Techniques》
链接:https://arxiv.org/pdf/2406.06608
资料:https://www.promptingguide.ai/zh/techniques
介绍
提示工程(Prompt Engineering),也称为上下文提示,是一种不更新模型权重 / 参数,仅通过设计提示来引导 LLM 行为,使其输出符合特定结果的方法。提示工程可应用于各类任务,包括回答问题、算术推理以及各种专业领域。理解提示工程,能帮助我们更好地认识大语言模型的能力边界与局限。
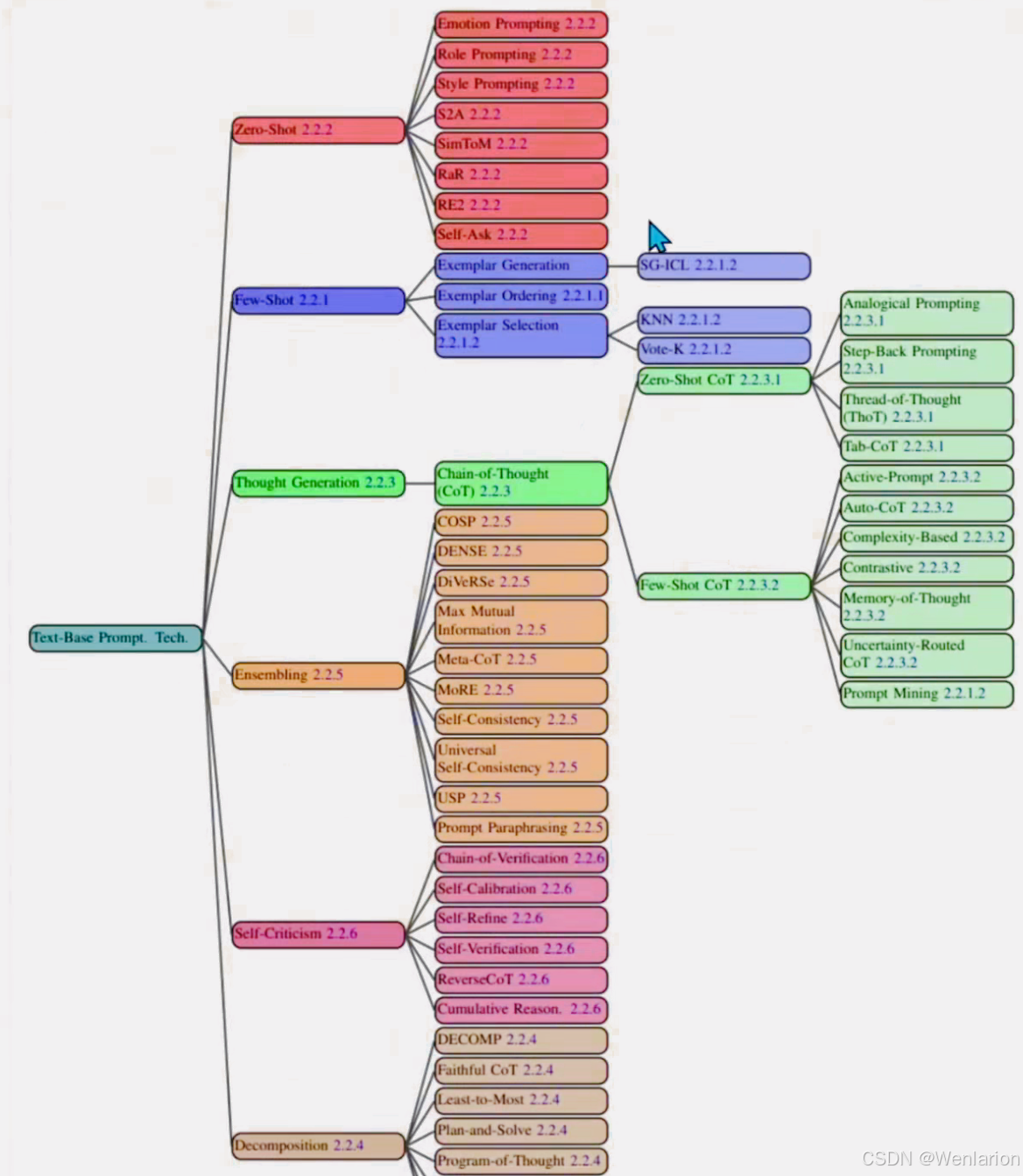

硬提示 (Hard Prompt)
传统提示是以自然语言的形式手动设计的。例如,想让模型完成一个任务时,你可能会输入一句话,像 “今天的天气如何?”。这种提示直接使用了自然语言,是固定不变的。
软提示 (Soft Prompt)
软提示并不一定是自然语言,而是通过在模型训练过程中学习得到的可训练向量表示。它可能不具有任何语言意义,但能够通过改变模型内部的激活模式来影响模型的输出。软提示不需要由人类显式编写,而是通过训练数据来学习最有效的提示。在 web 端的大模型界面使用不到,一般编程做大模型任务的时候可以用到缩减成本。
Prompt Tuning 是一种参数高效的微调方法,它属于软提示(Soft Prompt)的一种实现方式。在 Prompt Tuning 中,模型的权重被固定,只有提示(prompt)的参数会被更新论文《The Power of Scale for Parameter-Efficient Prompt Tuning》: https://arxiv.org/pdf/2104.08691 论文《Pre-train, Prompt, and Predict: A Systematic Survey of Prompting Methods in Natural Language Processing》: https://arxiv.org/pdf/2107.13586
软提示的使用通常分为两个主要部分:生成软提示向量 和 将软提示应用于模型推理。我们通过一个具体的例子来解释这两个步骤
软提示 (Soft Prompt) 使用例子
场景:电影评论情感分类任务假设我们有一个预训练的大型语言模型(例如 llama3.1),你想让模型判断一段电影评论是积极还是消极的。但我们不想用很多资源去微调整个模型,而是希望通过软提示来快速适应这一任务。
1. 准备数据
我们有以下几条电影评论数据(少量数据,因为我们要用软提示实现少样本学习):
-
评论 1: “这部电影太棒了,我非常喜欢!”
-
评论 2: “这部电影真是无聊透顶,浪费时间。”
-
评论 3: “演员的表演很精彩,但故事情节比较平淡。”我们希望模型能够根据这些评论的内容给出 “积极” 或 “消极” 的情感分类。
2. 生成软提示 (Soft Prompt Tuning)
与传统的硬提示不同,软提示是通过学习的方式来自动生成的。这个过程大致包括以下步骤:
Step 1: 初始化软提示向量
软提示不是自然语言词汇,而是由一组随机初始化的向量组成。例如,假设我们决定使用长度为 10 的提示,那么初始的软提示就是一组随机向量 P = [p1, p2, ..., p10]。
Step 2: 联合训练软提示和模型
现在,我们将这些软提示向量与评论数据结合起来作为输入。例如,对于评论 1“这部电影太棒了,我非常喜欢!”,模型的输入可以是 软提示 P + 评论文本。
这些软提示向量不需要人类显式设计,而是通过训练数据进行调整的。
-
输入 1:
[p1, p2, ..., p10]+ “这部电影太棒了,我非常喜欢!” -
输入 2:
[p1, p2, ..., p10]+ “这部电影真是无聊透顶,浪费时间。” -
评论 4: “故事情节非常有趣,特效也很棒!”
推理输入: [p1, p2, ..., p10] + “故事情节非常有趣,特效也很棒!”
Step 3: 固定预训练模型,仅调整软提示
重要的一点是,在整个过程中,我们不改变预训练的语言模型的权重。我们只调整和优化软提示向量。这意味着通过少量的数据和计算资源,我们就能让模型适应情感分类任务。
应用软提示进行推理
一旦软提示经过训练并学会了如何帮助模型执行分类任务,我们可以将这些提示用于新数据。
例如,当我们输入一个新的评论:
- 评论 4: “故事情节非常有趣,特效也很棒!”
-
推理阶段,我们会将训练好的软提示与这条评论结合:
- 推理输入:
[p1, p2, ..., p10]+ “故事情节非常有趣,特效也很棒!” -
模型根据软提示的辅助,可以更加准确地给出情感分类,可能预测出 “积极” 结果。
软提示 (Soft Prompt) 训练
以下是软提示训练的详细步骤,以及前缀向量是如何更新的。
1. 初始化前缀向量
首先,初始化一组前缀向量:P=[p1,p2,...,pk]其中 k 是向量的维度。通常这些向量是随机生成的,或者使用零向量初始化。
2. 准备训练数据
准备一小部分与任务相关的数据集,包括输入文本和相应的标签。例如,在情感分类任务中,输入可能是电影评论,标签则是 “积极” 或 “消极”。
3. 构建模型输入
在训练过程中,每次输入将结合前缀向量和任务文本。例如,对于一个输入评论,模型的输入可以表示为:
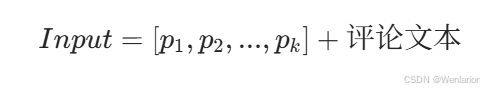
4. 前向传播
将输入送入预训练语言模型,模型会根据输入的前缀向量和文本生成一个输出。这个输出通常是一个预测,比如情感分类的概率分布。
5. 计算损失
根据模型输出和真实标签,计算损失函数。例如,常用的损失函数是交叉熵损失(cross-entropy loss):

6. 反向传播和优化
通过反向传播算法计算损失对前缀向量 P 的梯度。反向传播会将损失的梯度从输出层传递回输入层,从而计算出前缀向量的更新。
具体更新步骤如下:

提示工程(Prompt Engineering)基本方式
Zero-shot Prompt
用户的输入问题直接被传入了大模型中,并将大模型返回结果直接返回给了终端用户
#提示词
将文本分类为中性、负面或正面。
文本:我认为这次假期还可以。情感:
#输出
中性Few-shot Prompt
论文:https://arxiv.org/pdf/2005.14165
few-shot prompt 则是通过提供模型少量高质量的示例,这些示例包括目标任务的输入和期望输出。通过观察这些良好的示例,模型可以更好地理解人类意图和生成准确输出的标准。与 zero-shot 相比,few-shot 通常会产生更好的性能。然而,这种方法可能会消耗更多的 token,并且在处理长文本的输入或者输出的时候可能会遇到上下文长度限制的问题。
在 Few-shot Prompting 中,提示包含少量示例(称为 “shots”),向模型展示期望的输出应该是什么样子。通常,使用两到五个示例,为模型提供从模式和结构中学习的框架,这个过程被称为上下文学习(in-context learning)。
Few-shot Prompting 的工作原理包括以下几个步骤:
-
查询制定:用户通过包含清晰的任务描述和相关示例来制定提示。
-
示例提供:在提示中提供几个示例,这些示例展示了任务的输入和期望输出。
-
模型学习:模型通过这些示例学习任务的模式和结构,然后能够对新的输入生成准确的响应。
让我们看一下下面的例子
任务描述:对给定的文本进行情感分析,判断其是积极的、消极的还是中性的。
示例对:
输入:这部电影真是太棒了,我强烈推荐!
输出:积极
输入:服务很慢,食物冷冰冰的。
输出:消极
输入:天气不错,适合散步。
输出:中性
新输入:这个产品符合我的期望,价格也很合理。
预期输出:积极我们可以从上面的提示中看到,模型被给定一个或几个例子,然后能够为下一个问题生成答案
思维链 Chain-of-Thought Prompting
论文《Chain-of-Thought Prompting Elicits Reasoning in Large Language Models》:https://arxiv.org/pdf/2201.11903
Chain-of-Thought(CoT)提示生成一系列短句,即被称为思维链的句子。这些句子描述了逐步推理逻辑,最终导向答案。对于复杂推理任务和较大的模型,这种方法能带来显著的性能提升。
常见的两种基本 CoT 提示包括 Few-shot CoT 和 Zero-Shot CoT,并在下面对它们进行描述。
Few-shot CoT
Few-shot CoT 允许模型查看一些高质量推理链的演示。在向大语言模型(LLM)提问前,手工在 prompt 中加入一些包含完整思维过程(Chain of thought)的问答示例,就可以让 LLM 在推理任务上大幅提升。
让我们看下面的例子:
# few shot
问:罗杰有 5 个网球。他又买了两罐网球。每个罐子有 3 个网球。他现在有多少个网球?
A:11 个
问:自助餐厅有 23 个苹果。如果他们用 20 个做午餐,再买 6 个,他们有多少个苹果?
A:27 个
# few shot cot
问:罗杰有 5 个网球。他又买了两罐网球。每个罐子有 3 个网球。他现在有多少个网球?
A:罗杰从 5 个球开始。2 罐 3 个网球每个等于 6 个网球。5+6=11 答案是 11。
问:自助餐厅有 23 个苹果。如果他们用 20 个做午餐,再买 6 个,他们有多少个苹果?
A:自助餐厅原来有 23 个苹果。他们用 20 个来做午餐。剩下 23-20=3。所以他们又买了 6 个苹果,就有了 3+6=9。所以他们的答案是 9。Zero-shot CoT
论文《Large Language Models are Zero-Shot Reasoners》:https://arxiv.org/pdf/2205.11916
Zero-shot CoT(Zero-shot Chain of Thought)是一种无需任何标注数据即可激发大型语言模型(LLMs)进行复杂推理的技术。这种方法的核心在于使用特定的提示语,如 “Let's think step by step”,来引导模型生成推理步骤,并基于这些步骤得出答案。
例子
prompt:我去市场买了 10 个苹果。我给了邻居 2 个苹果和修理工 2 个苹果。然后我去买了 5 个苹果并吃了 1 个。我还剩下多少苹果?让我们一步步思考
推理:首先,从 10 个苹果中减去给邻居的 2 个和修理工的 2 个,剩下 6 个苹果。然后,加上新买的 5 个苹果,总共有 11 个苹果。最后,减去吃掉的 1 个苹果,剩下 10 个苹果。
答案:我还剩下 10 个苹果。Zero-shot CoT 能够帮助我们看到模型内部,并了解它是如何推理得出答案的。
自一致性 (Self-Consistency)
论文《SELF-CONSISTENCY IMPROVES CHAIN OF THOUGHT REASONING IN LANGUAGE MODELS》:https://arxiv.org/pdf/2303.11171
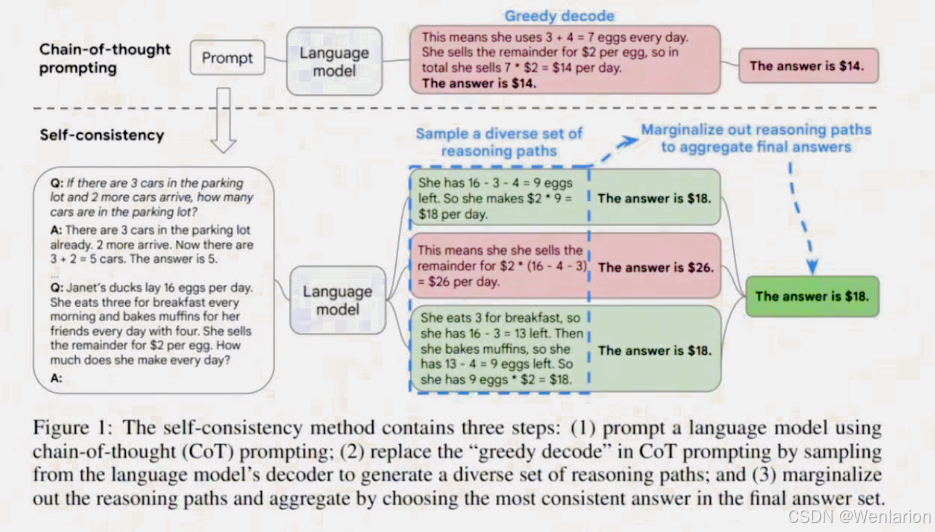
通过独立生成多条解题思路并对最终解答进行多数表决,增强了推理过程的鲁棒性。
本文提出了一种新的解码策略 ——self-consistency,以取代贪婪解码。
例子
Q: 假设你有 3 个苹果,又买了 2 个苹果,现在你有多少个苹果?
A1:首先,我有 3 个苹果。接着,我又买了 2 个苹果。因此,我现在总共有 3 + 2 = 5 个苹果。
A2:首先,我有 3 个苹果。然后,我买了 2 个苹果。所以总共有 3 + 2 = 5 个苹果。
A3:我有 3 个苹果,买了 2 个苹果,所以我有 5 个苹果。
聚合结果:每次的答案都是 5,因此选择答案 5 作为最终结果思维树 (Tree of Thought)
论文《Tree of Thoughts: Deliberate Problem Solving with Large Language Models》:https://arxiv.org/pdf/2305.10601
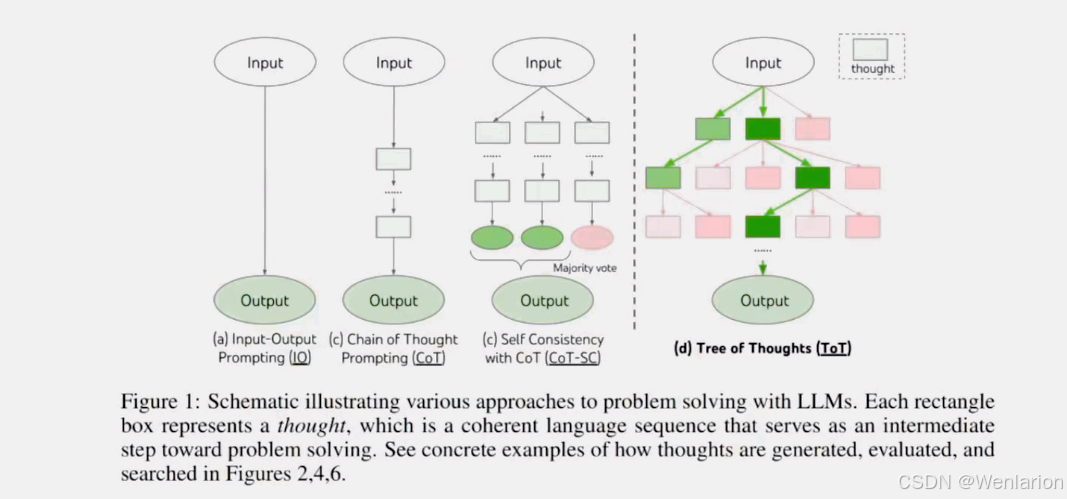
思维树 (Tree of Thought,简称 ToT) 是一种新型的语言模型推理框架,它通过模拟人类的决策过程来解决复杂问题。这种方法允许大型语言模型(LLMs)通过考虑多个不同的推理路径和自我评估选择来决定下一步行动,并在必要时向前看或回溯以做出全局选择,从而进行深思熟虑的决策。
它首先将问题分解为多个思维步骤,并在每个步骤中生成多个思维,实质上是创建一个树形结构,搜索过程可以是广度优先过程或深度优先的过程。
提示词:
假设三位不同的专家来回答这个问题。所有专家都写下他们思考这个问题的第一个步骤,然后与大家分享。
然后,所有专家都写下他们思考的下一个步骤并分享。
以此类推,直到所有专家写完他们思考的所有步骤。只要大家发现有专家的步骤出错了,就让这位专家离开。
请问...CO-STAR 提示词框架
框架

这是 Sheila Teo 用来赢得新加坡 GPT-4 提示工程竞赛的框架。CO-STAR 的每个字母都代表提示词的一个具体部分:
- “C” 代表 Context(上下文):你可以在这里给出任何相关的背景信息,比如你自己或是你希望它完成的任务的信息。
- “O” 代表 Objective(目标):在这里,你需要给出非常明确的指示,告诉 ChatGPT 你希望它做什么。
- “S” 代表 Style(风格):在这一部分,我们需要告诉 ChatGPT 我们想要的写作风格,可以是有趣的,比如我们希望它以 Snoop Dogg 的说唱风格来写作,或者像顶级 CEO 那样的风格。
- “T” 代表 Tone(语调):你希望回答的语调是什么?幽默的?情绪化?有威慑性?由你来决定。
- “A” 代表 Audience(受众):即我们要告诉 ChatGPT 的听众是谁。比如说,如果目标听众是五岁的孩子,那么结果会截然不同于目标听众是世界级物理学家的情况。
- 最后一个字母 “R”,代表 Response(回应类型):我们想要的回应类型。我们需要一份详细的研究报告吗?或者需要一个表格?我们需要一个复杂的编程格式,比如 JSON 吗?或者只是一大堆文字?你想要的,在这里都能找到。
具体的构建方法是这样的:
- 首先,我提供了一个我经营的背景,如我制作 AI 课程。
- 接着,我设定目标是撰写一个社交媒体(比如小红书风格)帖子以吸引人们购买。
- 然后,我设定我需要的风格,基本上是模仿小红书文案的方式。
- 其次,我要求 AI 用礼貌并且具有说服力的语调来编写文案。
- 第五,我告诉 AI 目标受众为 30 岁左右的人群。
- 最后,我指定了 AI 回答的格式:“你的回复应该是四句话,不需要话题标签,但需要加入一些表情符号。”
试用 CO-STAR 设计模型,有几个基本原则需要遵守:
- 借助 CO-STAR 框架构建高效的提示
- 利用分隔符来分节构建提示
- 设计含有 LLM 保护机制的系统级提示
- 仅依靠大语言模型分析数据集,无需插件或代码
针对上述 4 原则,我们分别举例来说明效果。
论文阅读助手提示词模板
## Context(背景)
作为一名学者或研究人员,阅读和理解学术论文是一项日常任务。然而,由于时间限制和论文数量的增加,快速准确地获取论文的关键信息变得尤为重要。“论文阅读助手” 旨在帮助用户高效地筛选和理解学术论文,专注于提供论文的核心观点、研究方法、主要发现和结论。
## Objective(目标)
“论文阅读助手” 的目标是:
提取并总结论文的研究问题、目的和背景。
明确论文的研究方法和数据来源。
突出论文的主要发现、结论和可能的影响。
评估论文的质量和相关性,为用户的研究提供参考。
## Style(风格)
“论文阅读助手” 的写作风格应是学术性的、客观的,同时要清晰和易于理解。避免过度使用行业术语,除非对理解内容至关重要。
## Tone(语调)
语调应保持中立和专业,同时传达出对学术研究的尊重和对用户需求的同情理解。
## Audience(受众)
目标受众是学术研究人员、学者、大学生以及任何需要深入理解学术论文的专业人士。
## Response(回应)
“论文阅读助手” 的回应格式应包括以下部分:
-标题和作者:提供论文的标题和作者信息。
-摘要:提供论文摘要的精简版,突出研究问题和目的。
-研究方法:简要描述研究设计、样本、数据收集和分析方法。
-主要发现:总结论文的关键结果和数据。
-结论:概述作者的结论和对研究领域的潜在影响。
-批判性评价:提供对论文质量、方法和结论的简要评估。
-推荐阅读:如果适用,推荐相关的进一步阅读材料。
3、AI Agents 平台
大厂平台
代表:钉钉、Coze 以及微信
优势:有多年的客户使用数据,以及传统业务流程(如请假、报销等)积累,目前 workflow 更多是基于自身生态。Coze 更多在开发者社区,但 Coze 后面应该还会围绕飞书、头条等来提升字节整体的生态影响力。拥有最大客户群体的微信,腾讯小微、小微助手和微信对话开放平台等都陆续上线。
企业 AI 需求不仅仅是办公,看钉钉、Coze 等能否会走出自己的体系,变得更加开放。
国企、央企的办公基于钉钉为主几乎所有工作交流和大部分文件传输都在钉钉上,日常聊天内容和文件网盘都在钉钉上,知识无需搬迁,使用效率极高,使用体验很好;在请假、招聘、会议等重复性很高的办公流程上,钉钉的助理(实际就是 Agent)非常好用,因为这就是对钉钉原有业务的增强。目前钉钉给出来的功能更多是聚焦在办公室业务上,还无法深入企业的核心业务;作为一家企业,如果要对外服务,不能要求他们的所有客户都用钉钉,也不希望把所有数据都放在钉钉上。
对普通用户来说,最好的是钉钉,其次是 Coze,Dify 有点难度。
Agent 工作流平台
代表:Dify、Coze、voiceflow 等
优势:开源的精神,活跃的社区。其实 Coze 也有自己的 workflow 工具,也属于这个流派,只是更纯粹、更有代表性的应该是 Dify。
Dify 官网:https://cloud.dify.ai/apps使用无代码和画板让用户自由由 Agent 组成的 workflow,热度很高,各种社区上被开发者热捧,在一定程度上在 LLM 企业应用上往前走了一步。
Dify 的用户:
-
试用系统默认只支持 Github 和 Google 账号登录使用,用户至少是产研人员
-
目标客户不是无研发能力的公司(IT 基础太弱,知识积累不成体系,造成应用场景很窄)和大型科技公司(自己会造)
-
RAG 会长期存在,且会越来越偏向数据工作
国内主流一站式 Agent 平台
Coze
Coze,作为字节精心打造的 AI Bot 开发旗舰平台,致力于赋能开发者,以强大而简洁的界面,加速智能聊天机器人的设计与部署流程。
在中文大模型智能体生态中,Coze 以其先驱地位傲视群雄,无论是率先布局的市场先机,还是其在智能体编排工具的成熟度、插件的广泛性、兼容大模型种类的多样性,乃至发布渠道的全面覆盖,均展现出非凡实力。
Coze 平台慷慨开放,无论是其自研的云雀大模型,还是外部知名的 moonshot 等尖端技术,均对开发者免费开放,极大地降低了创新门槛。
用户体验好、日活用户数大、底层技术支撑完善,Coze 是众多智能体平台中佼佼者。
豆包
字节另一款 AI 智能对话助手 —— 豆包:豆包以其独特的 prompt 驱动方式,让用户能够轻松定制专属智能体,无缝集成了先进的 TTS(文本到语音)技术,让自定义的智能体能够直接与用户进行语音交互,更偏向于 C 端用户。
相较于 Coze 的全方位智能体构建方案,豆包更像是一款功能精炼、操作快捷的便携式 Coze 版本,尤其适合在移动端快速高效地应用。
百度千帆 AgentBuilder
百度 AgentBuilder 是一款智能体开发工具,旨在降低智能体开发门槛,让每个人、每个组织都能够成为智能体的开发者。AgentBuilder 是百度推出的三大 AI 开发工具之一,另外两个工具分别是 AppBuilder 和 ModelBuilder。
-
产品形态:基于文心大模型的智能体平台,也是平台型。
-
开发方式:支持开发者根据自身行业领域和应用场景选择不同类型的开发方式,提供低成本的 prompt 编排方式。
-
功能特点:提供零代码和低代码两种开发模式,适合不同技术背景的开发者。
阿里云魔搭社区
网址:https://modelscope.cn/studios/agent
产品形态革新
专为开源大语言模型(LLM)量身定制的 AI Agent 开发框架。完美兼容各类主流 LLM,是高度灵活与可扩展的平台,让 AI Agent 的开发与部署更加便捷高效。
开发方式多元化
该框架支持创建多样化的多模态 AI Agent,涵盖客户服务、个人助理等多个领域,满足不同场景下的智能化需求。用户可以根据具体业务场景,轻松构建出既能处理文本对话,又能理解图像、语音等多类型信息的智能体。
一键协作,简化流程
该框架创新性地引入了一键发送指令调用其他 AI 模型的功能,大幅简化了模型集成与协作的流程。用户无需深入技术细节,即可轻松实现多模型间的无缝对接,提升整体项目的智能化水平和响应速度。
低 / 零代码平台,降低门槛
为了进一步降低 AI Agent 的开发门槛,我们结合了低 / 零代码平台的设计理念,让非技术背景的用户也能参与到 AI 应用的开发中来。通过直观的图形化界面和丰富的预设模板,用户可以快速上手,实现个性化定制的智能体,无需编写复杂的代码。
智谱
网址:https://chatglm.cn/main/toolsCenter
智谱清言推出的 Agent 生成器,在提供基础智能体生成能力的同时,独具特色地支持开发者通过 API 调用方式灵活使用智能体。该 API 广泛覆盖清言 C 端页面的核心功能,包括文本对话、文生图、图片解读、联网搜索、文档解析、Python 代码执行及外部 API 调用等。
在智能体中心,热门智能体琳琅满目,既有官方精心打造的,也有个人开发者热情贡献的。这些智能体系紧贴时事热点,如高考志愿填报助手便是一例,彰显了其高度的实时性和实用性。此外,分类上与其他平台相似,涵盖了工具类(搜索、修图、数据分析等)、娱乐类(搞笑、角色对话)及生活类(搭配选择)等多个领域,满足不同用户的多样化需求。
讯飞的星火友伴
网址:https://xinghuo.xfyun.cn/botcenter/createbot
讯飞科技,以其深厚的 AI 技术底蕴,携手星火 V3.0 这一强大引擎,精心打造了一个专注于虚拟人格 GPTs 应用的创新平台。该平台不仅代表了讯飞在人工智能领域的又一里程碑式成果,更是为探索个性化智能交互体验开辟了全新的道路。
智能体中心,是由讯飞官方精心设计的虚拟人格模板。这些模板各具特色,涵盖了从亲切友善的客服助手到风趣幽默的聊天伙伴,再到专业严谨的顾问导师等多种角色设定。用户可根据自身需求与偏好,轻松选择一款合适的模板作为起点,也可以通过平台的强大功能进行二次改造与个性化定制。
SkyAgents(昆仑万维)
网址:https://model-platform-skyagents.nangong.cn/home/agent
昆仑万维公司隆重推出天工 SkyAgents,这是一款引领未来的 AI Agents 构建平台,旨在重塑智能应用的创造边界。
开发体验革新
区别于传统繁琐的开发流程,天工 SkyAgents 引入了革命性的开发方式。用户仅需通过自然语言输入,即可轻松描述 AI Agent 的功能与行为;可视化拖拽界面更是将复杂的技术操作简化为直观的图形操作,深度集成 Skywork 大语言模型,让 AI Agent 的智能化水平跃升至新高度。
应用场景广泛
天工 SkyAgents 的智能体,凭借其强大的感知与决策能力,能够精准适配各类具体业务场景。无论是电商平台的个性化推荐、客服系统的智能应答,还是金融领域的风险评估、智能制造的自动化控制,天工 SkyAgents 都能以用户需求为核心,提供定制化的智能解决方案,助力企业实现数字化转型与升级。
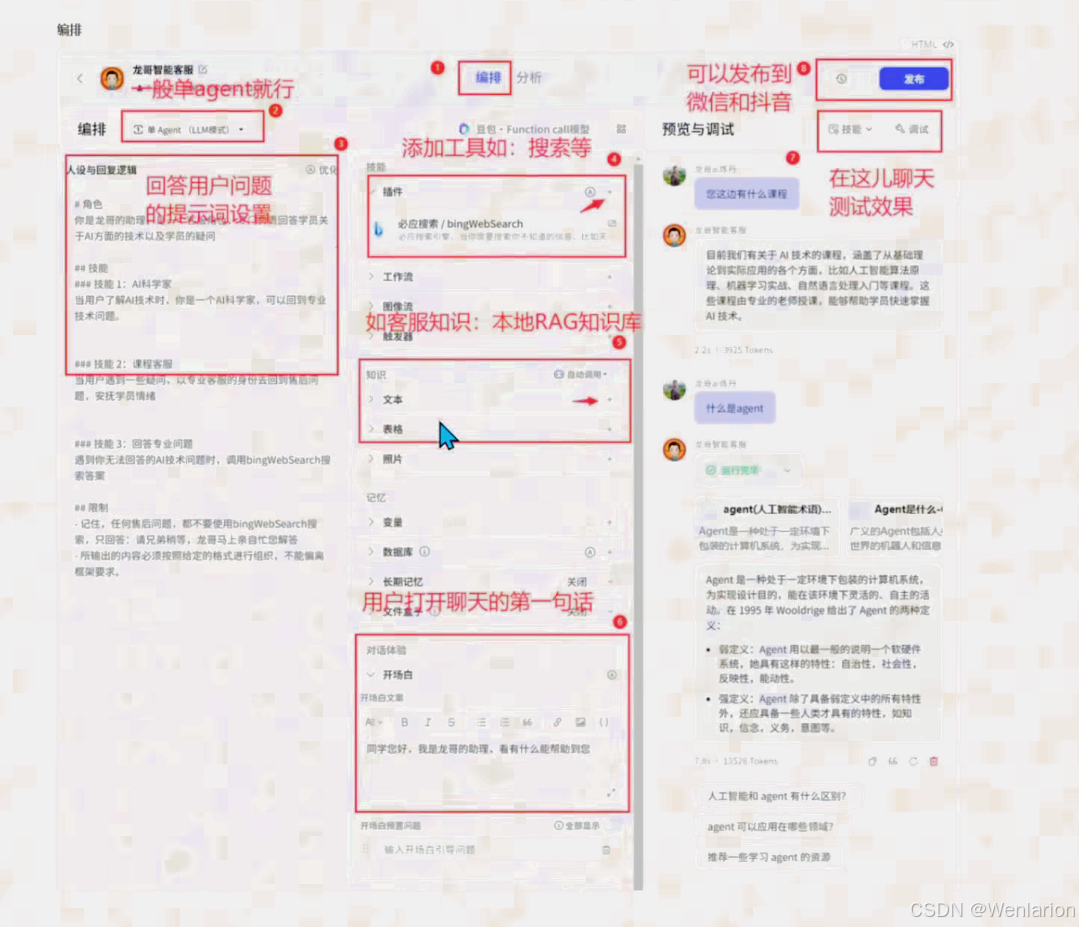
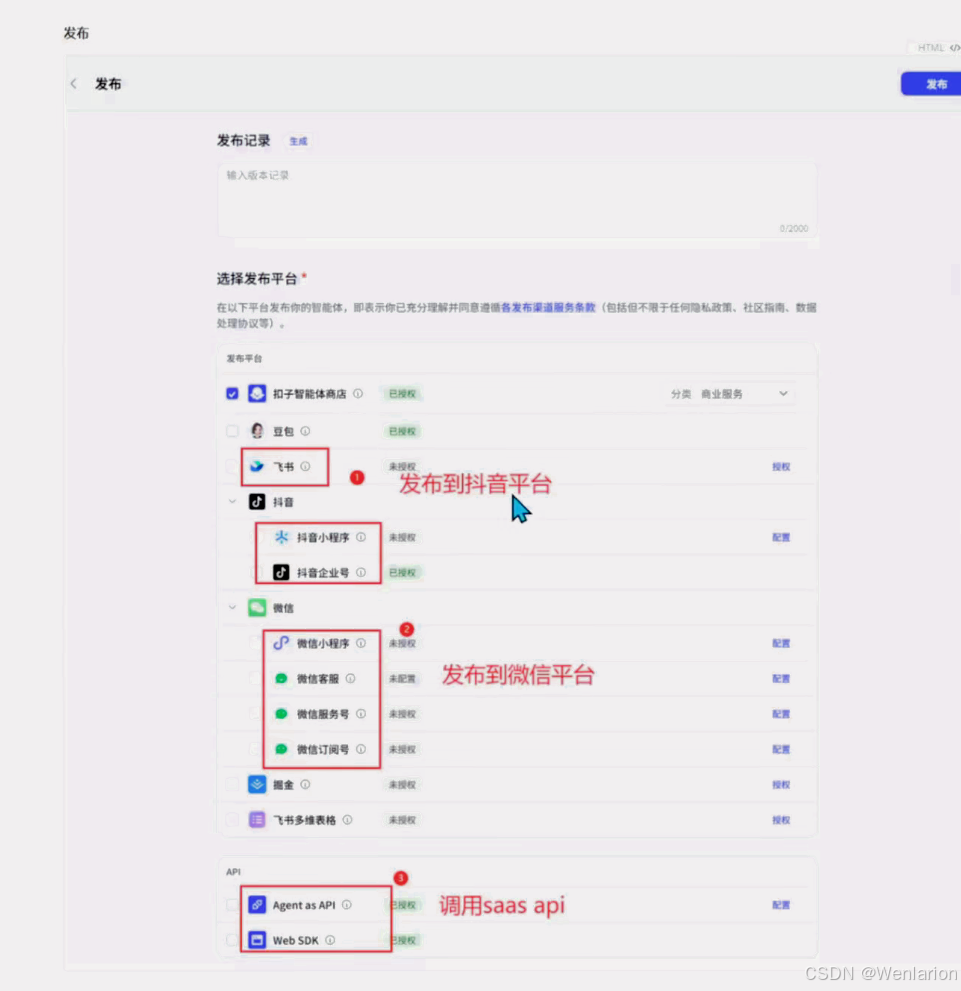
用 Coze 搭建智能客服
文档:https://www.coze.cn/docs/guides/quickstart可以发布到企业微信,公众号,抖音企业号等
创建
登录 coze:https://www.coze.cn/home
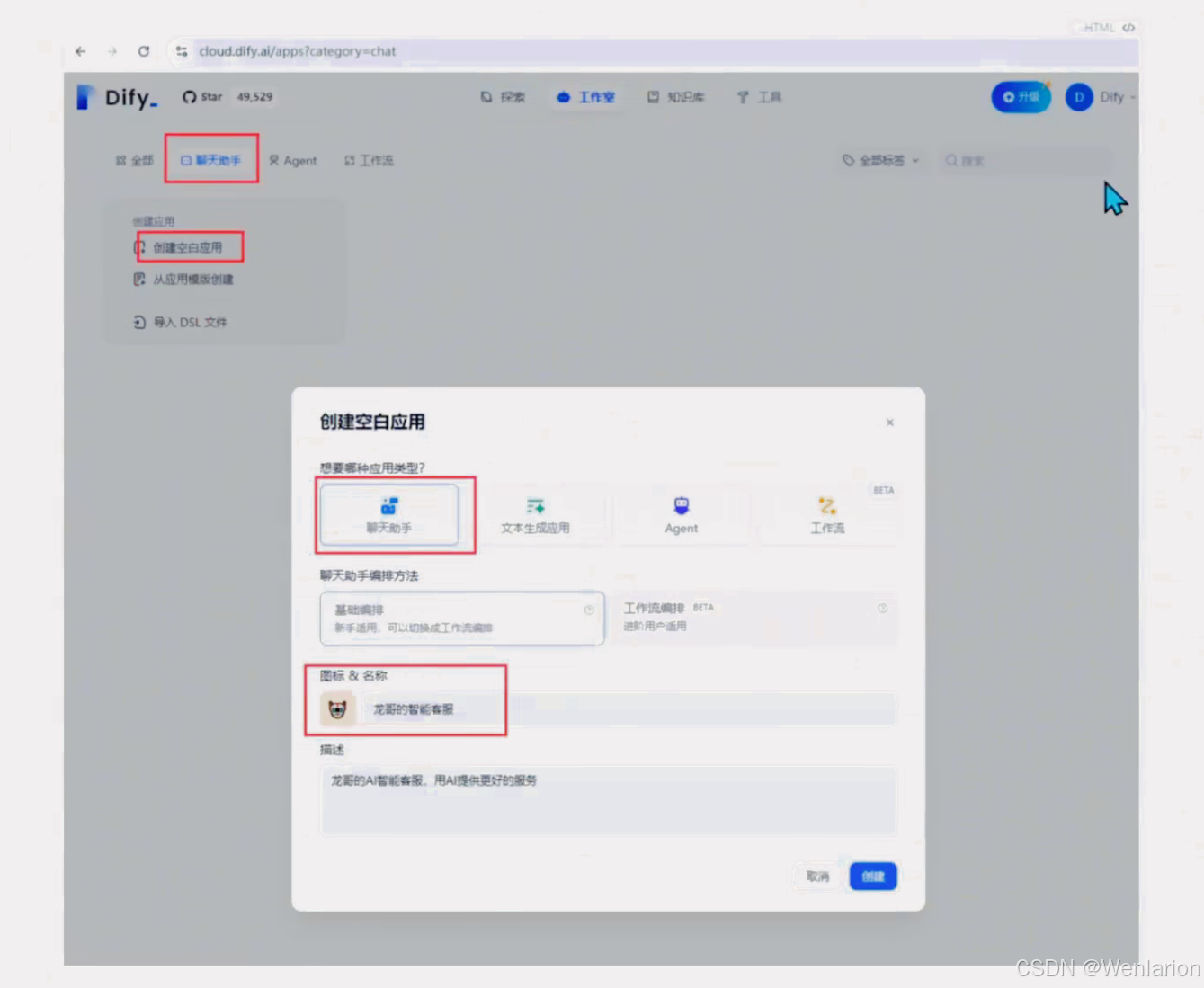
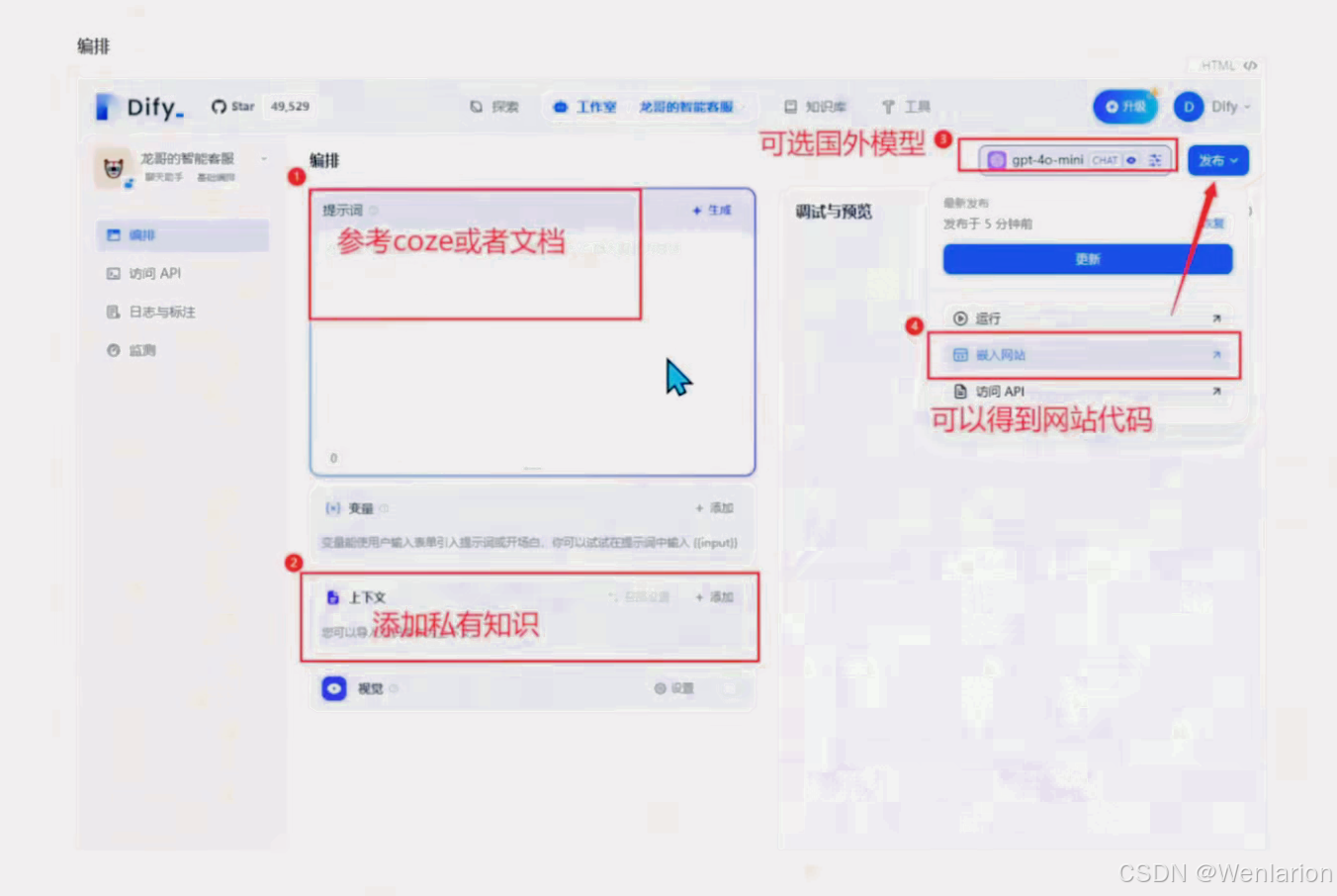
用 Dify.ai 搭建智能客服
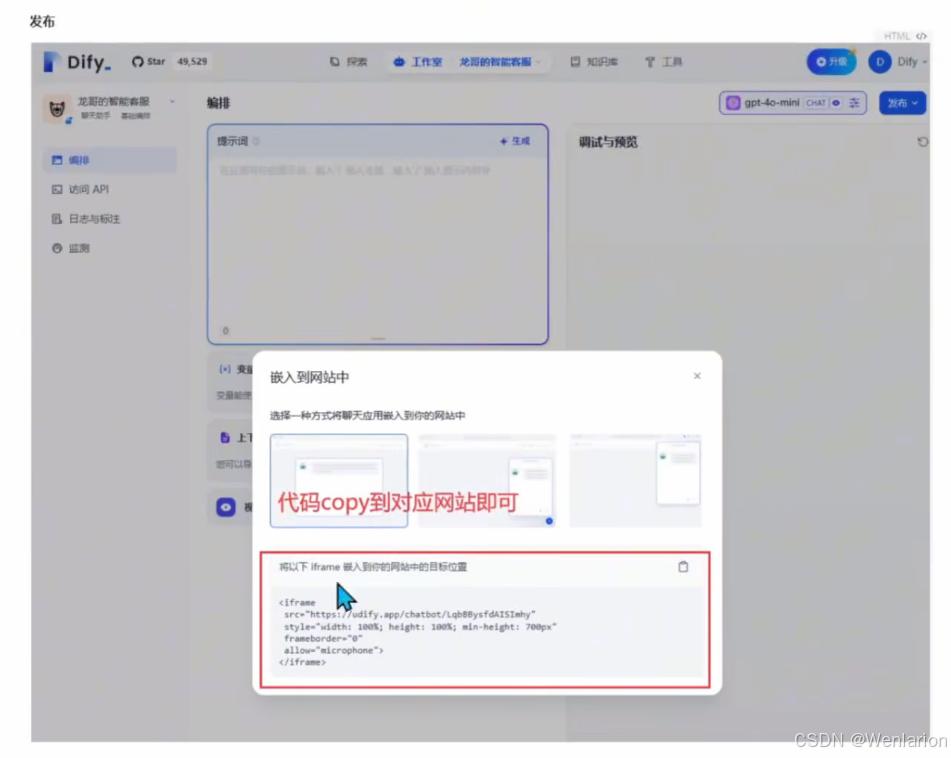
文档:https://docs.dify.ai/zh-hans/guides/application-orchestrate/conversation-application可以发布到网页,提供了嵌入代码,不过后端使用 dify.ai 的云服务
创建
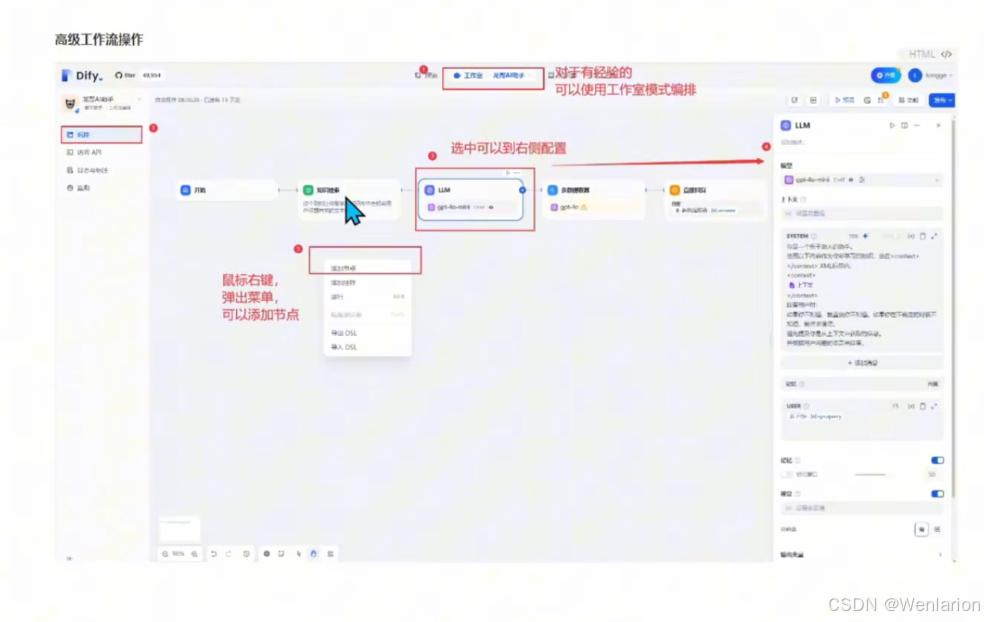
4、Tool Use 与 Function call
MRKL
论文:A modular, neuro-symbolic architecture that combines large language models, external knowledge sources and discrete reasoning链接:https://arxiv.org/pdf/2205.00445
“模块化推理、知识和语言”(Modular Reasoning, Knowledge, and Language)的缩写,MRKL 系统被提议包含一组 “专家” 模块,通用 LLM 充当路由器,将查询路由到最合适的专家模块。
这些模块可以是其它模型(例如深度学习模型)或外部工具(例如数学计算器、货币转换器、天气 API)。
MRKL 的核心思想是,现有 LLM(如 GPT-3)等仍存在一些缺陷,包括遗忘、外部知识的利用效率低下等。
MRKL 将神经网络模型、外部知识库和符号专家系统相结合,提升了自然语言处理的效率和精度。
通过 MRKL 系统,不同类型的模块能够被整合在一起,实现更高效、灵活和可扩展的 AI 系统。
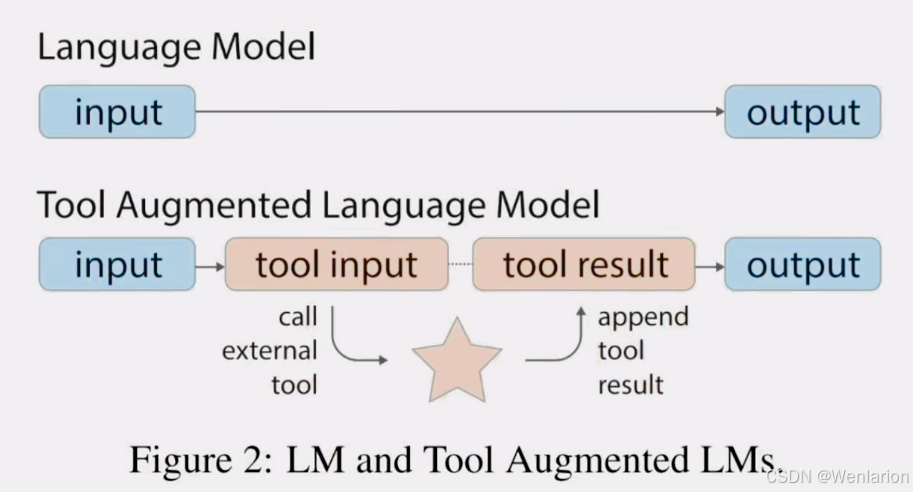
TALM
论文链接:https://arxiv.org/pdf/2205.12255
工具增强语言模型(Tool Augmented Language Models)是一种通过整合外部工具来增强大型语言模型(LLMs)能力的方法。
大型语言模型(LLM)在 zero-shot 和 few-shot 任务上表现出印象深刻的结果,展示了涌现能力。
这些模型存在固有限制,包括无法获取最新信息、幻觉事实倾向、低资源语言理解困难、缺乏精确计算数学技能和对时间进程的不了解。
工具增强语言模型的应用领域非常广泛,包括但不限于:
- 信息检索:通过搜索引擎等工具获取最新信息,提高模型在实际业务中的应用能力
- 复杂推理:利用工具进行数学计算、逻辑推理等,解决传统语言模型难以处理的问题
- 自动化和效率提升:通过自动化工具提高工作效率,如自动生成代码、执行程序等
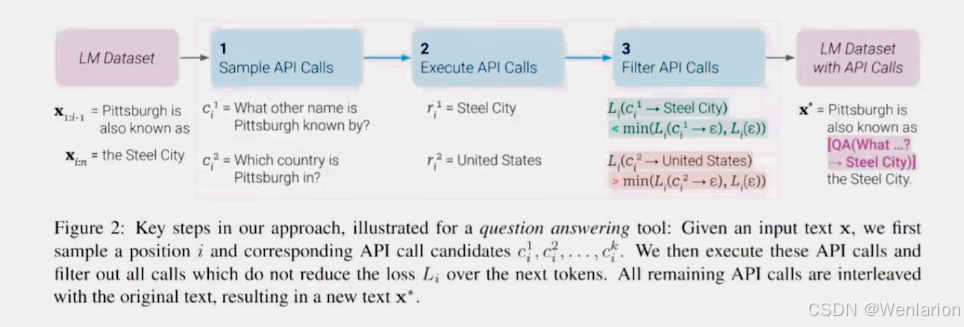
Toolformer
论文:https://arxiv.org/pdf/2302.04761
github 项目:https://github.com/lucidrains/toolformer-pytorch
论文:https://arxiv.org/pdf/2303.09014
是由 MetaAI 提出的一项创新研究,旨在赋予语言模型使用外部工具的能力。
通过 Toolformer,语言模型可以在生成文本时自动调用 API,从而获取并整合外部信息,提升文本生成的准确性和实用性。
它能够通过自监督学习的方式教会自己使用各种工具,如计算器、问答系统、搜索引擎、翻译系统和日历等。
这种方法允许模型在处理任务时,通过调用相应的工具来获取所需的信息或执行特定的功能,从而提高模型的性能和适用性。
Toolformer 的核心思想是让语言模型学会在适当的时机调用适当的工具,而这一过程不需要大量的人工注释,而是通过模型自身的上下文学习能力来实现。
Function call
function calling 榜单: https://gorilla.cs.berkeley.edu/leaderboard.html
函数调用是指可靠地连接 LLM 与外部工具的能力,让用户能够使用高效的外部工具,与外部 API 进行交互。GPT-4 和 GPT-3.5 是经过微调的 LLM,能够检测到函数是否被调用,随后输出包含调用函数参数的 JSON。
函数调用功能可以增强模型推理效果或进行其他外部操作,包括信息检索、数据库操作、知识图谱搜索与推理、操作系统、触发外部操作等工具调用场景。
需要注意的是,大模型的 Function call 不会执行任何函数调用,仅返回调用函数所需要的参数。开发者可以利用模型输出的参数在应用中执行函数调用。
openai
openai function call 文档: https://platform.openai.com/docs/guides/function-calling
有关更多详细信息,请参阅 Prompt Engineering 的 "外部 API" 部分。https://openai.com/index/chatgpt-plugins/
ChatGPT 插件和 OpenAI API 函数调用是 LLM 在实践中增强工具使用能力的良好示例。工具 API 集合可以由其他开发人员提供(如插件)或自定义(如函数调用)。
例子 1
通过查询天气举个例子,这块我用 openai 的 function call 进行演示
首先我们定义一些 function,如下所示,我只定义了一个查询天气的函数 get_current_weather,我们需要对这个函数进行简单的描述,如 "获取今天的天气"。这个函数有两个参数,分别是地点 location 和时间 time,也需要进行文本描述。
LLM 根据函数描述,参数描述以及用户的输入,来决定是不是要调用这个 function。
请求里如果有 functions 字段,返回了一个 json,并帮我们从输入文本里抽取了 get_current_weather 所需要的 location 和 time 的函数值
import json
from openai import OpenAI
GPT_MODEL = "gpt-4o"
client = OpenAI()
tools = [
{
"type": "function",
"function": {
"name": "get_current_weather",
"description": "Get the current weather",
"parameters": {
"type": "object",
"properties": {
"location": {
"type": "string",
"description": "The city and state, e.g. San Francisco, CA",
},
"format": {
"type": "string",
"enum": ["celsius", "fahrenheit"],
"description": "The temperature unit to use. Infer this from the users location.",
},
},
"required": ["location", "format"],
},
}
}
]
messages = []
messages.append({"role": "system", "content": "Don't make assumptions about what values to plug into functions. Ask for clarification if a user request is ambiguous."})
# 要求用户的提示词对函数调用明确,包括要求的参数,缺参数就要告诉用户补充
messages.append({"role": "user", "content": "I'm in Glasgow, Scotland. What's the weather like today"})
# 我在苏格兰格拉斯哥。今天天气怎么样
chat_response = chat_completion_request(
messages, tools=tools
)
assistant_message = chat_response.choices[0].message
messages.append(assistant_message)
print(assistant_message)
...
ChatCompletionMessage(content=None, role='assistant', function_call=None, tool_calls=
[ChatCompletionMessageToolCall(id='call_xb7QwwNnx90LKmht1WOYrgP2', function=Function(arguments='{"location":"Glasgow, Scotland","format":"celsius"}', name='get_current_weather'), type='function')])
...本质上 ChatGPT 就是在帮我们在做个文本结构化
ChatGPT 并不帮我们真正的去查询天气,但是我们可以真的用 python 去定义一个get_current_weather函数,在这个函数里,编写程序(调用查询天气的工具包)去实现查询天气的功能,函数的输入就用 ChatGPT 返回的 json 里的内容
相当于我们通过编程帮 ChatGPT 提供了一个查询天气的工具,因此也可以管 function call 叫做 “工具调用”。
get_current_weather返回天气信息给 ChatGPT,ChatGPT 再回答给用户。
我们可以定义各种功能的函数帮 ChatGPT 完成任务,比如查询网页,算数等,因此工具调用对于 agent 来说非常重要
import json
from openai import OpenAI
GPT_MODEL = "gpt-4o"
client = OpenAI()
tools = [
{
"type": "function",
"function": {
"name": "get_current_weather",
"description": "Get the current weather",
"parameters": {
"type": "object",
"properties": {
"location": {
"type": "string",
"description": "The city and state, e.g. San Francisco, CA",
},
"format": {
"type": "string",
"enum": ["celsius", "fahrenheit"],
"description": "The temperature unit to use. Infer this from the users location.",
},
},
"required": ["location", "format"],
},
}
}
]
#定义要调用的function
#这儿简化举例,真实功能需要调用接口实现
def get_current_weather(location,format):
return "40度"
messages = []
messages.append({"role": "system", "content": "Don't make assumptions about what values to plug into functions. Ask for clarification if a user request is ambiguous."})
messages.append({"role": "user", "content": "I'm in Glasgow, Scotland.What's the weather like today"})
chat_response = chat_completion_request(
messages, tools=tools
)
assistant_message = chat_response.choices[0].message
messages.append(assistant_message)
...
ChatCompletionMessage(content=None, role='assistant', function_call=None, tool_calls=
[ChatCompletionMessageToolCall(id='call_xb7QwwNnx90LKmht1WOYrgP2', function=Function(arguments='{"location":"Glasgow, Scotland","format":"celsius"}', name='get_current_weather'), type='function')])
...
#从dict对象中取function对象,并判断name
if assistant_message["function"]["name"] == "get_current_weather":
arguments=assistant_message["function"]['arguments']
location = json.loads(arguments)["location"]
format = json.loads(arguments)["format"]
results = get_current_weather(location, format)
else:
results = f"Error: function {message['function']['name']} does not exist"
#可以把结果results丢给大语言模型总结,也可以直接给用户results
tools 是一个 json 对象列表,每一个 json 对象,都是一个 function 对象,有名字 name,有 description 描述信息,大模型就是根据这个 description 来判断是调用哪个 function
from openai import OpenAI
client = OpenAI()
tools = [
{
"type": "function",
"function": {
"name": "get_weather",
"strict": True,
"parameters": {
"type": "object",
"properties": {
"location": {"type": "string"},
"unit": {"type": "string", "enum": ["c", "f"]},
},
"required": ["location", "unit"],
"additionalProperties": False,
},
},
},
{
"type": "function",
"function": {
"name": "get_stock_price",
"strict": True,
"parameters": {
"type": "object",
"properties": {
"symbol": {"type": "string"},
},
"required": ["symbol"],
"additionalProperties": False,
},
},
},
]
#波士顿的天气
messages = [{"role": "user", "content": "what's the weather like in Boston today?"}]
completion = client.chat.completions.create(
model="gpt-4o",
messages=messages,
tools=tools,
tool_choice="required"
)
print(completion)通义千问
文档: https://help.aliyun.com/zh/model-studio/developer-reference/use-qwen-by-calling-api#7f60648d6dfwr
使用兼容 openai 的 api 接口,工具定义格式
import os
import dashscope
tools = [
{
"type": "function",
"function": {
"name": "get_current_time",
"description": "当你想知道现在的时间时非常有用。",
"parameters": {}
}
},
{
"type": "function",
"function": {
"name": "get_current_weather",
"description": "当你想查询指定城市的天气时非常有用。",
"parameters": {
"type": "object",
"properties": {
"location": {
"type": "string",
"description": "城市或县区,比如北京市、杭州市、余杭区等。"
}
}
},
"required": [
"location"
]
}
}
]
messages = [{"role": "user", "content": "杭州天气怎么样"}]
response = dashscope.Generation.call(
# 若没有配置环境变量,请用百炼API Key将下行替换为: api_key="sk-xxx",
api_key=os.getenv('DASHSCOPE_API_KEY'),
model="qwen-plus",
messages=messages,
tools=tools,
result_format='message'
)
print(response)响应输出结果
{
"status_code": 200,
"request_id": "28d9b918-6287-95d1-9876-a67a9257c0c6",
"code": "",
"message": "",
"output": {
"text": null,
"finish_reason": null,
"choices": [
{
"finish_reason": "tool_calls",
"message": {
"role": "assistant",
"content": "",
"tool_calls": [
{
"function": {
"name": "get_current_weather",
"arguments": "{\"location\":\"杭州市\"}"
},
"index": 0,
"id": "call_e63b80aab9df4950b391d0",
"type": "function"
}
]
}
}
]
},
"usage": {
"input_tokens": 218,
"output_tokens": 18,
"total_tokens": 236
}
}ChatGLM
文档: https://open.bigmodel.cn/dev/api/normal-model/glm-4
使用兼容 openai 的 api 接口,工具定义格式
from zhipuai import ZhipuAI
client = ZhipuAI(api_key="") # 请填写您自己的APIKey
tools = [
{
"type": "function",
"function": {
"name": "query_train_info",
"description": "根据用户提供的信息查询火车时刻",
"parameters": {
"type": "object",
"properties": {
"departure": {
"type": "string",
"description": "出发城市或车站",
},
"destination": {
"type": "string",
"description": "目的地城市或车站",
},
"date": {
"type": "string",
"description": "要查询的火车日期",
},
},
"required": ["departure", "destination", "date"],
},
}
}
]
messages = [
{
"role": "user",
"content": "你能帮我查一下2024年1月1日从北京南站到上海的火车票吗?"
}
]
response = client.chat.completions.create(
model="glm-4", # 请填写您要调用的模型名称
messages=messages,
tools=tools,
tool_choice="auto",
)
print(response.choices[0].message)API-Bank
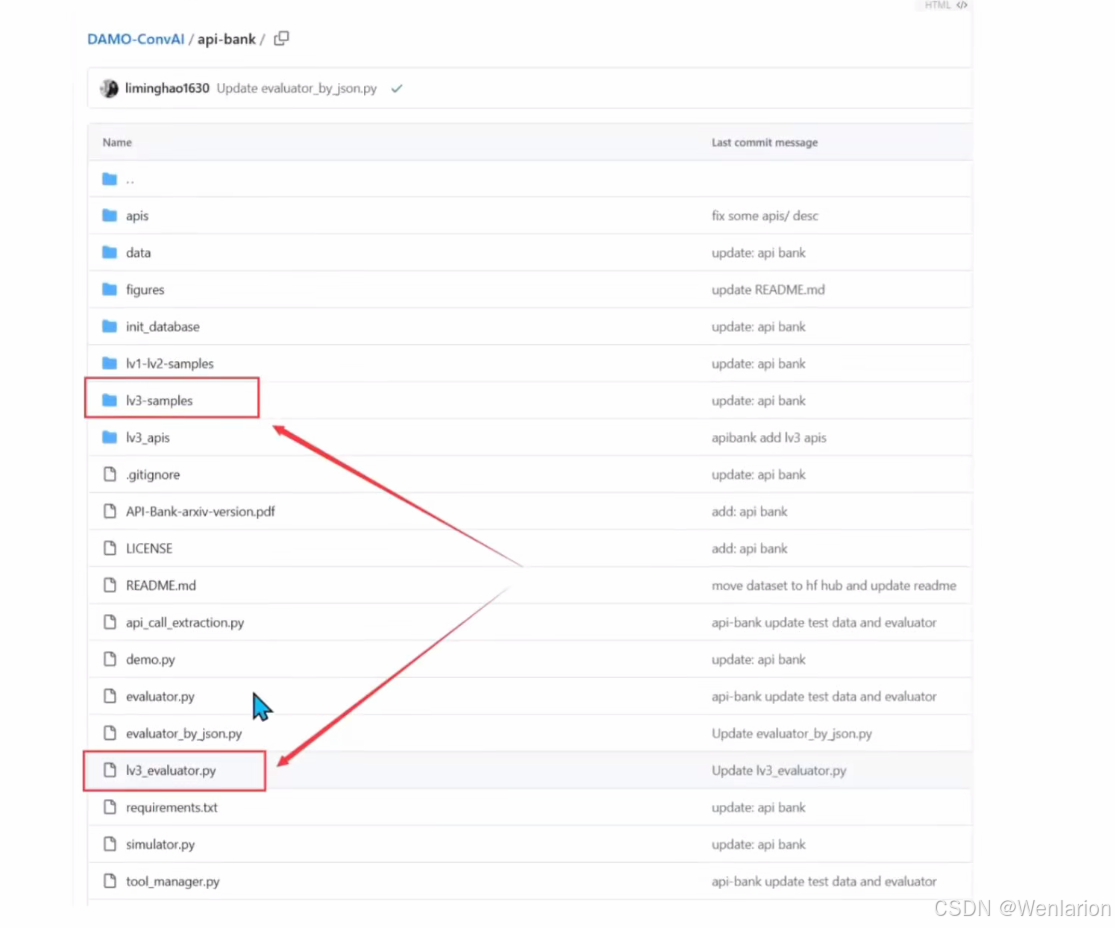
论文 API-Bank: A Comprehensive Benchmark for Tool-Augmented LLMs: https://arxiv.org/pdf/2304.08244github 项目: https://github.com/AlibabaResearch/DAMO-ConvAI/tree/main/api-bank评测数据集: https://huggingface.co/datasets/liminghao1630/API-Bank
function calling 榜单: https://gorilla.cs.berkeley.edu/leaderboard.html
23 年 10 月阿里、香港科技大学、北大和深圳智能思创的论文《API-Bank: A Comprehensive Benchmark for Tool-Augmented LLMs》
大语言模型(LLM)可以通过利用外部工具来增强其功能
三个关键问题:(1) 目前的 LLMs 在使用工具方面的效率如何?一个由 73 个 API 工具组成的可运行评估系统。用 753 个 API 调用对 314 个工具用对话进行标注,评估现有 LLMs 在规划、检索和调用 API 方面的能力
(2) 如何提高 LLMs 运用工具的能力?一个全面的训练集,其中包含来自 1,000 个不同领域的 2,138 个 API 的 1,888 个工具使用对话
(3) 使用工具需要克服哪些障碍?API 的选择相当多样化,包括搜索引擎、计算器、日历查询、智能家居控制、日程管理、健康数据管理、账户认证工作流等等。要提升大模型工具使用的准确率和有效性,还需要进一步提升大模型能力
在 API-Bank 工作流程中,LLM 需要做出几个决策,并且我们可以在每个步骤中评估该决策的准确性。
决策包括:
- 是否需要 API 调用
- 确定要调用的正确的 API:如果不够好,LLM 需要迭代修改 API 输入(例如,决定搜索引擎 API 的搜索关键字)
- 根据 API 结果做出响应:如果结果不满意,模型可以选择改进并再次调用
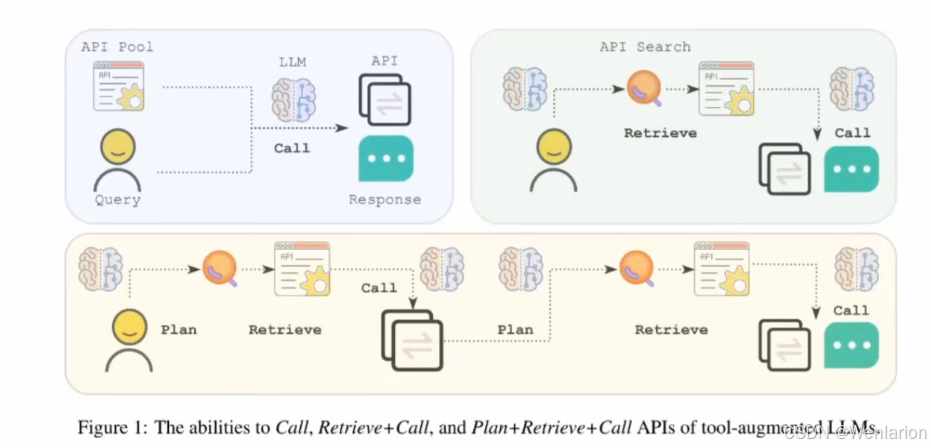
能力评估
该基准从三个层面评估代理的工具使用能力:
level 1 评估调用 API 的能力在给定 API 的用法描述和对话历史的前提下,模型需要判断是否调用 API、正确地调用 API、获得 API 调用结果后正确地回复用户对应上图 api pool
level 2 考察检索 API 的能力在测试开始时,模型仅被告知 API 检索系统的用法,任何对话中需要用到的特定 API 的信息都不可见。LLMs 必须根据对话历史判断用户需求,通过关键词搜索可能能够解决用户需求的 API,并在检索到正确的 API 后学习如何使用 API对应上图 api search
level 3 评估除了检索和调用之外规划 API 的能力在这个级别中,用户的需求可能不明确,需要多个 API 调用步骤来解决。例如:“我想从上海到北京旅行一周,从明天开始。帮我规划旅行路线并预订航班、门票和酒店。” LLMs 必须推断出合理的旅行计划,并基于计划调用航班、酒店和门票预订 API 来完成用户需求对应上图 plan
level 1/2 的对话数据存储在 lv1-lv2-samples 目录或测试数据中,请按照 evaluator.py/evaluatorbyjson.py 中的代码设计评估脚本

欢迎加入 MCP 技术社区!与志同道合者携手前行,一同解锁 MCP 技术的无限可能!
更多推荐
 13
13 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)