LangChain实战:新手手撸RAG全记录(二)
2.1 这个文件是干啥的
上个章节我们了解了项目整体的结构,这一章我们就来看看具体代码。首先是模型调用相关的llms.py,这个文件是整个项目的发动机,负责两件事:提供大语言模型和提供文本嵌入模型,简单说就是,谁想要跟AI对话,谁想要把文本转成向量,都来找这个文件要
设计思路很明确:对外只暴露两个函数——get_llm()和get_embeddings(),内部怎么实现,调用时一概不用关心,这就是典型的封装思想
2.2 环境变量配置
项目开始先加载.env文件,用于接收API_KEY,这样写既安全又方便
from dotenv import load_dotenv
load_dotenv()2.3 路径配置验证
代码开始于一大段路径验证,包含用到的向量数据库和本地模型的位置
PROJECT_PATH = Path("C:/项目路径")
DATA_DIR = PROJECT_PATH / "data"
CHROMA_PERSIST_DIR = DATA_DIR / "chroma"
BAAI_MODEL_DIR = DATA_DIR / "llm" / "BAAI"
MODEL_PATH = BAAI_MODEL_DIR / "bge-large-zh-v1.5"如果模型路径不存在,还会自动创建目录并提示用户放模型文件:
if not MODEL_PATH.exists():
print(f"\n模型路径不存在,正在创建目录...")
MODEL_PATH.mkdir(parents=True, exist_ok=True)
print(f"已创建目录: {MODEL_PATH}")
print(f"请将模型文件放入此目录")这个地方我就踩过坑,一开始我用的是Hugging Face在线模型进行数据向量化,测试时发现它响应不快还可能因为网络问题报错,换成本地模型之后又显示模型不存在,改了半天路径结果是模型里有同名文件被我用进去了,所以大家在写的时候要注意确认文件夹里的内容是不是真正的模型文件
2.4 DeepSeekChatModel:大语言模型封装
这个类继承自LangChain的ChatOpenAI,但实际上是用来调用DeepSeek的,为什么能这么用?因为DeepSeek的API接口跟OpenAI是兼容的,改个base_url就行
读取配置:从环境变量读取API密钥、模型名称、各种参数
api_key = os.getenv("DEEPSEEK_API_KEY")
base_url = os.getenv("DEEPSEEK_BASE_URL", "https://api.deepseek.com")
model_name = os.getenv("DEEPSEEK_MODEL", "deepseek-chat")设置模型参数:温度、最大token数、超时时间、重试次数,这些参数直接影响到模型回答的质量和响应速度
temperature = float(os.getenv("DEEPSEEK_TEMPERATURE", "0.7"))
max_tokens = int(os.getenv("DEEPSEEK_MAX_TOKENS", "4096"))
timeout = int(os.getenv("DEEPSEEK_TIMEOUT", "60"))
max_retries = int(os.getenv("DEEPSEEK_MAX_RETRIES", "3"))调用父类初始化:把所有参数传给ChatOpenAI
super().__init__(
model=model_name,
api_key=api_key,
base_url=base_url,
temperature=temperature,
max_tokens=max_tokens,
timeout=timeout,
max_retries=max_retries,
streaming=streaming,
model_kwargs={
"top_p": top_p,
"frequency_penalty": frequency_penalty,
"presence_penalty": presence_penalty,
}
)这样封装之后,我就可以不用关心大模型调用的细节了,就跟用OpenAI一样简单
2.5 BGELocalEmbeddings:本地嵌入模型封装
这个类用于加载本地的BGE模型,本地知识库里的文字要通过这个模型才能变成大模型能看懂的向量
检查模型路径:确保模型文件可用
self.model_path = model_path or MODEL_PATH
if not self.model_path.exists():
raise FileNotFoundError(f"BGE 模型路径不存在: {self.model_path}")加载模型:用sentence-transformers加载本地模型,device参数可以指定用CPU还是GPU,有GPU的话速度会快很多
self.model = SentenceTransformer(str(self.model_path), device=self.device)
self.dimension = self.model.get_sentence_embedding_dimension()初始化缓存:为了提升性能,加了缓存机制
self._cache = {} # 缓存已经计算过的文本
self._call_count = 0 # 统计调用次数
self._total_texts = 0 # 统计处理文本总数_embed:私有的嵌入方法,实现缓存逻辑
def _embed(self, texts: List[str]) -> List[List[float]]:
# 去重处理
unique_texts = list(set(texts))
# 检查缓存
for text in unique_texts:
if text in self._cache:
cached_embeddings[text] = self._cache[text]
else:
uncached_texts.append(text)
# 计算未缓存的文本
if uncached_texts:
embeddings = self.model.encode(uncached_texts, ...)
for i, text in enumerate(uncached_texts):
self._cache[text] = embeddings[i].tolist()
# 按原始顺序返回
return [cached_embeddings[text] for text in texts]这样先去重,再查缓存,只计算没见过的文本,最后按原始顺序返回的设计可以实现重复的问题秒回,性能提升很大
embed_documents:批量嵌入文档,自动分批处理
def embed_documents(self, texts: List[str]) -> List[List[float]]:
if len(texts) <= self.batch_size:
return self._embed(texts)
# 分批处理,避免内存溢出
results = []
for i in range(0, len(texts), self.batch_size):
batch = texts[i:i + self.batch_size]
batch_results = self._embed(batch)
results.extend(batch_results)
return resultsembed_query:嵌入单个查询,直接调用_embed
def get_stats(self) -> dict:
return {
"model_path": str(self.model_path),
"device": self.device,
"dimension": self.dimension,
"cache_size": len(self._cache),
"call_count": self._call_count,
"total_texts_processed": self._total_texts,
}这个函数可以用来监控模型的使用情况,看看缓存命中率、处理了多少文本,对调优很有帮助
2.6 LLMManager:单例管理器
这个类用类变量缓存模型实例,避免重复加载:
class LLMManager:
_llm_instance = None
_embeddings_instance = None
@classmethod
def get_deepseek_model(cls, ...):
if cls._llm_instance is not None and not force_recreate:
return cls._llm_instance
# 创建新实例并缓存
cls._llm_instance = DeepSeekChatModel(...)
return cls._llm_instance为什么要这么设计?因为加载大模型很耗时,DeepSeek还好,调用API而已,但BGE模型加载一次要好几秒,如果每次提问都要重新加载用户的体验会很差
2.7 对外接口
最后暴露两个简洁的函数:
def get_llm(model_name: Optional[str] = None, force_recreate: bool = False) -> DeepSeekChatModel:
return LLMManager.get_deepseek_model(model_name, force_recreate)
def get_embeddings(force_recreate: bool = False) -> BGELocalEmbeddings:
return LLMManager.get_bge_embeddings(force_recreate)调用的话只需要:
from llms import get_llm, get_embeddings
llm = get_llm()
embeddings = get_embeddings() 2.8 自测代码
文件末尾加了一段自测代码,运行时可以直接验证模型是否正常:
if __name__ == "__main__":
# 测试DeepSeek
chat_model = get_llm()
print(f"对话模型: {chat_model.model_name}")
# 测试BGE
embedding_model = get_embeddings()
print(f"向量维度: {embedding_model.dimension}")
# 测试嵌入
embedding = embedding_model.embed_query("测试文本")
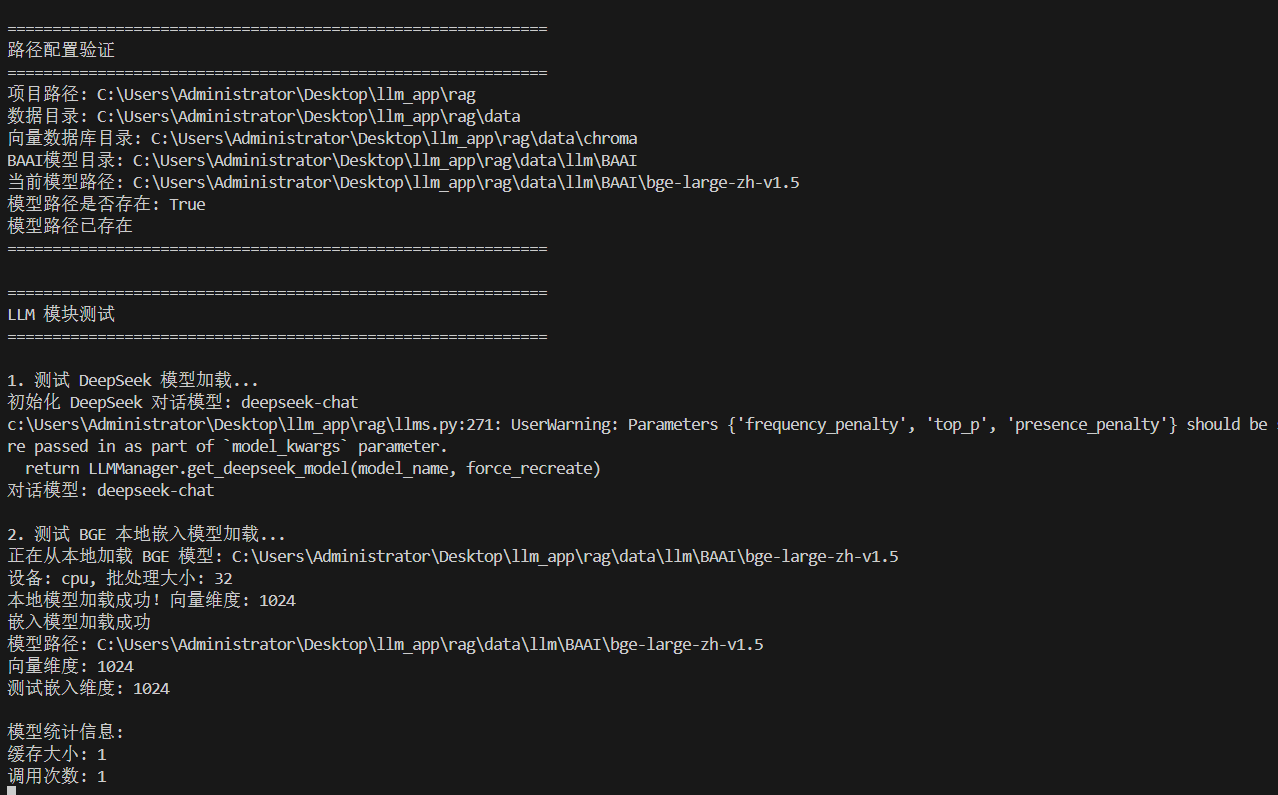
print(f"测试嵌入维度: {len(embedding)}")运行结果:

欢迎加入 MCP 技术社区!与志同道合者携手前行,一同解锁 MCP 技术的无限可能!
更多推荐

 16
16 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)