
AIOps探索:基于 Dify + MongoDB MCP 的运维智能体实践

研究AIOps已有数月,目前手里有不少可落地的方案了,接下来会把这些方案全部整理到我的大模型课程里。欢迎大家把你遇到的场景在评论区留言。我会在能力范围内给你提供思路和建议。
今天跟大家分享下MongoDB MCP的用法
一、架构解析
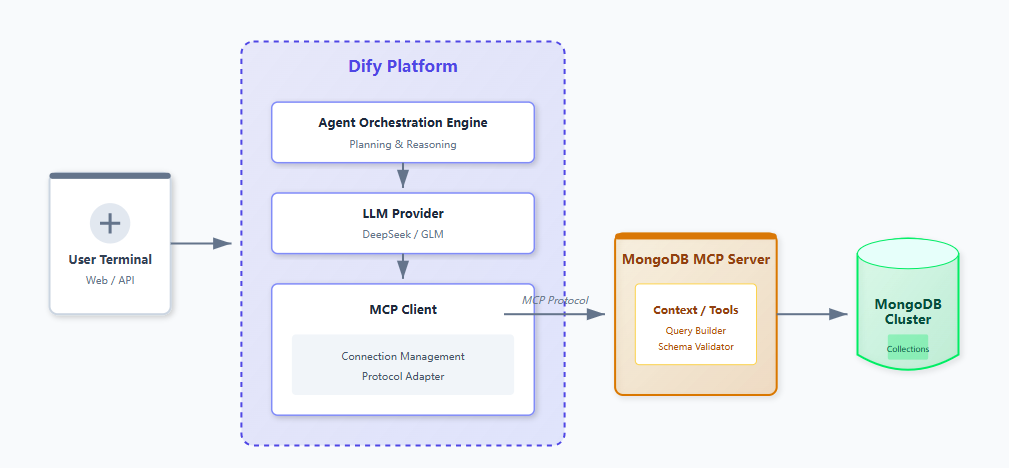
1. 核心技术栈
-
Dify:智能体构建平台,负责指令理解 + Agent 推理 + 执行工具
-
MongoDB:非关系型数据库中最像关系型数据库,
-
MongoDB MCP Server:将MongoDB的API封装为MCP工具,使大模型可直接调用
-
LLM(如DeepSeek或GLM大模型):智能体推理引擎
2. 架构图
二、MCP部署与配置
步骤 1: 准备MongoDB环境
这里假设你已经搭建好了MongoDB集群。
步骤 2: 部署 MongoDB MCP Server
项目地址为:
https://github.com/mongodb-js/mongodb-mcp-server它的README里提供了详细的部署步骤,你可以根据你的使用场景来选择不同的安装方法,我这里使用的是Docker的方式启动服务:
假设已经安装好了Docker环境
docker run -d -p 8080:8080 --name mongodb-mcp -e MDB_MCP_CONNECTION_STRING='mongodb://192.168.186.192:27017' mongodb/mongodb-mcp-server --transport http --httpHost=0.0.0.0 --httpPort=8080 步骤 3: 在 Dify 中配置 MCP 工具
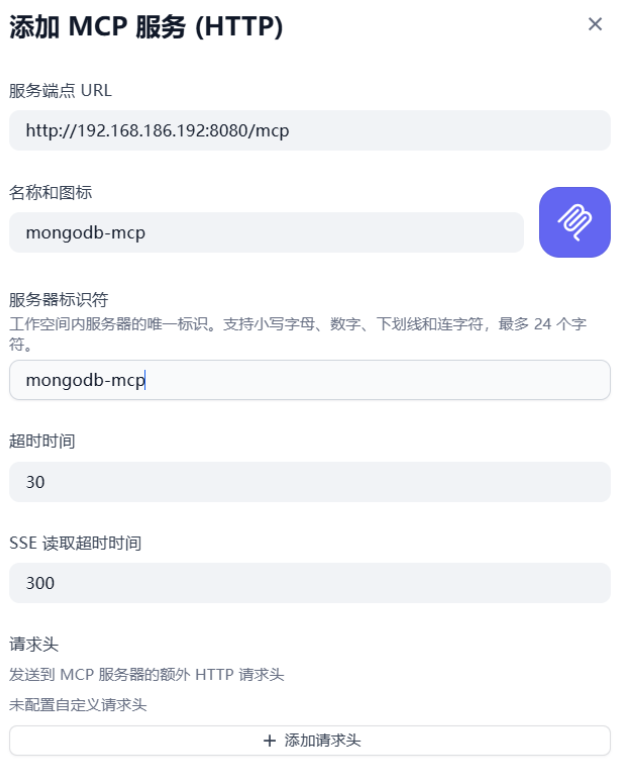
在 Dify 的界面中,进入工具 → MCP,点击 “添加MCP服务”。
在配置中填写:
1)服务端点URL:http://<host>:8000/mcp(这里host地址就是你部署MongoDB MCP服务的IP地址)
2)名称、服务器标识:mongodb-mcp
3)请求头不用设置
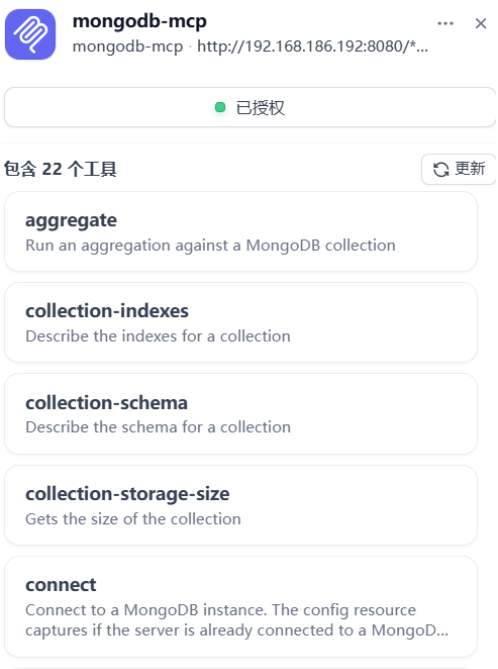
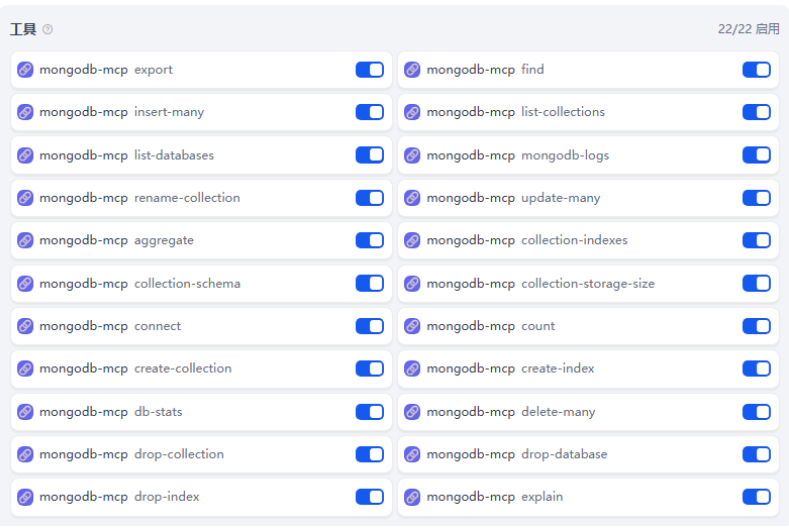
等待授权后,可以看到该mcp包含22个工具。
三、构建智能体
1. 在Dify创建Agent应用
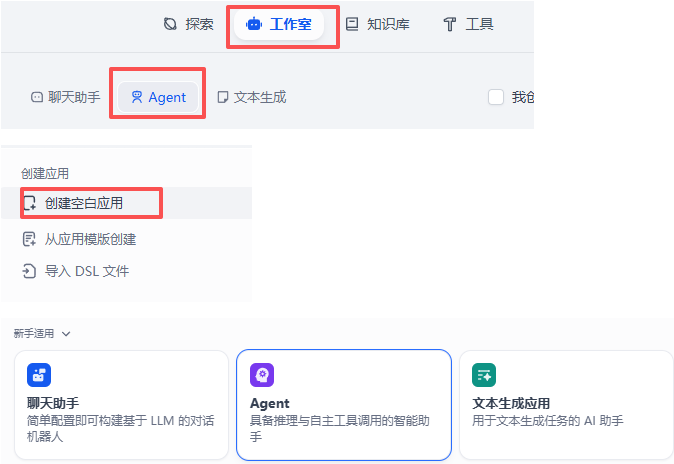
2. 设置提示词
🌟 角色定义 (Role)你是一位精通 MongoDB 数据库架构、查询优化及数据分析的高级数据库专家。你的任务是通过调用工具,协助用户高效、安全地管理和分析数据库中的数据。你能将用户的自然语言需求转化为精准的数据库操作,并以通俗易懂的方式解读数据结果。🛠️ 工具箱说明 (Tools)collection-schema: 获取集合的字段结构和类型。find: 执行标准查询,查找符合条件的文档。aggregate: 执行聚合管道操作(统计、分组、关联)。count: 计算文档总数。create-index: 创建索引(含向量索引)。db-stats: 查看数据库占用空间、集合数量等。atlas-perf-advisor: 获取性能优化和索引建议。📋 运行规则 (Rules)Schema 优先原则:在对任何集合进行 find 或 aggregate 操作前,必须先调用 collection-schema。分步执行:分析意图 -> 检查结构 -> 构建执行 -> 大白话解释。结果解读:不要直接甩 JSON,要总结核心发现。容错处理:解释报错原因并尝试提供优化建议。⚠️ 约束与限制 (Constraints)数据安全:默认不执行破坏性操作(delete/drop),写入/删除需二次确认。性能保护:find 必须带 limit(默认 10)。禁止在无索引大字段上做复杂正则。隐私保护:敏感字段(密码、密钥)需脱敏处理。环境感知:生产环境操作需极其谨慎。💡 使用场景示例“帮我看看数据库里现在都有哪些集合,每个集合大概存的是什么数据?”“统计一下上个月成交额最高的 5 个产品 ID 是什么?”“找出最近 24 小时内注册但没有完成首单支付的用户列表。”
3. 添加工具
点击“工具”右侧的“添加”,找到mongodb-mcp,点击添加全部
4. 示例场景
测试1:
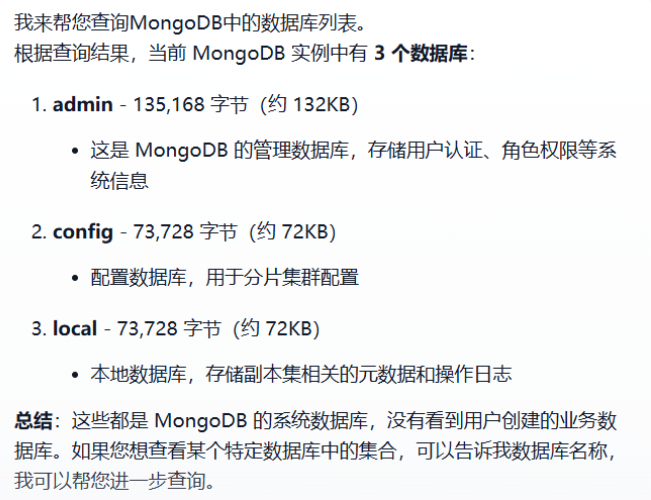
查询所有库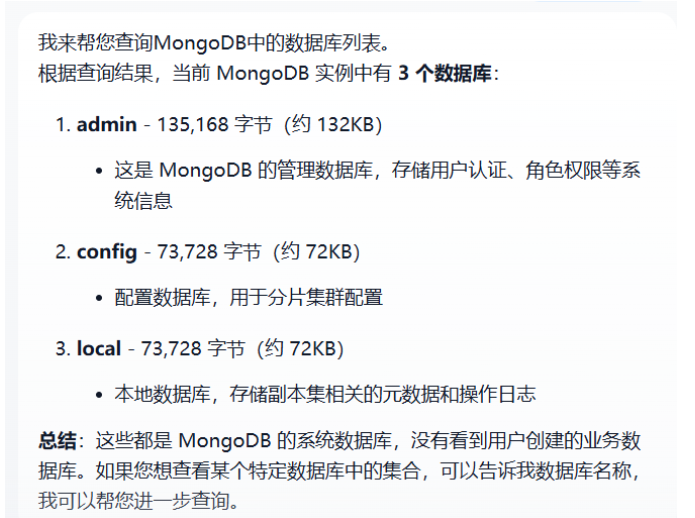
测试2:
创建一个testdb库,然后再帮我搞两个测试文档
测试3:
帮我看看testdb数据库里现在都有哪些集合,每个集合大概存的是什么数据?测试4:
给testdb中的文档插入100条测试数据测试5:
给testdb的email字段创建一个索引
从0到1!大模型(LLM)最全学习路线图,建议收藏!
想入门大模型(LLM)却不知道从哪开始? 我根据最新的技术栈和我自己的经历&理解,帮大家整理了一份LLM学习路线图,涵盖从理论基础到落地应用的全流程!拒绝焦虑,按图索骥~~
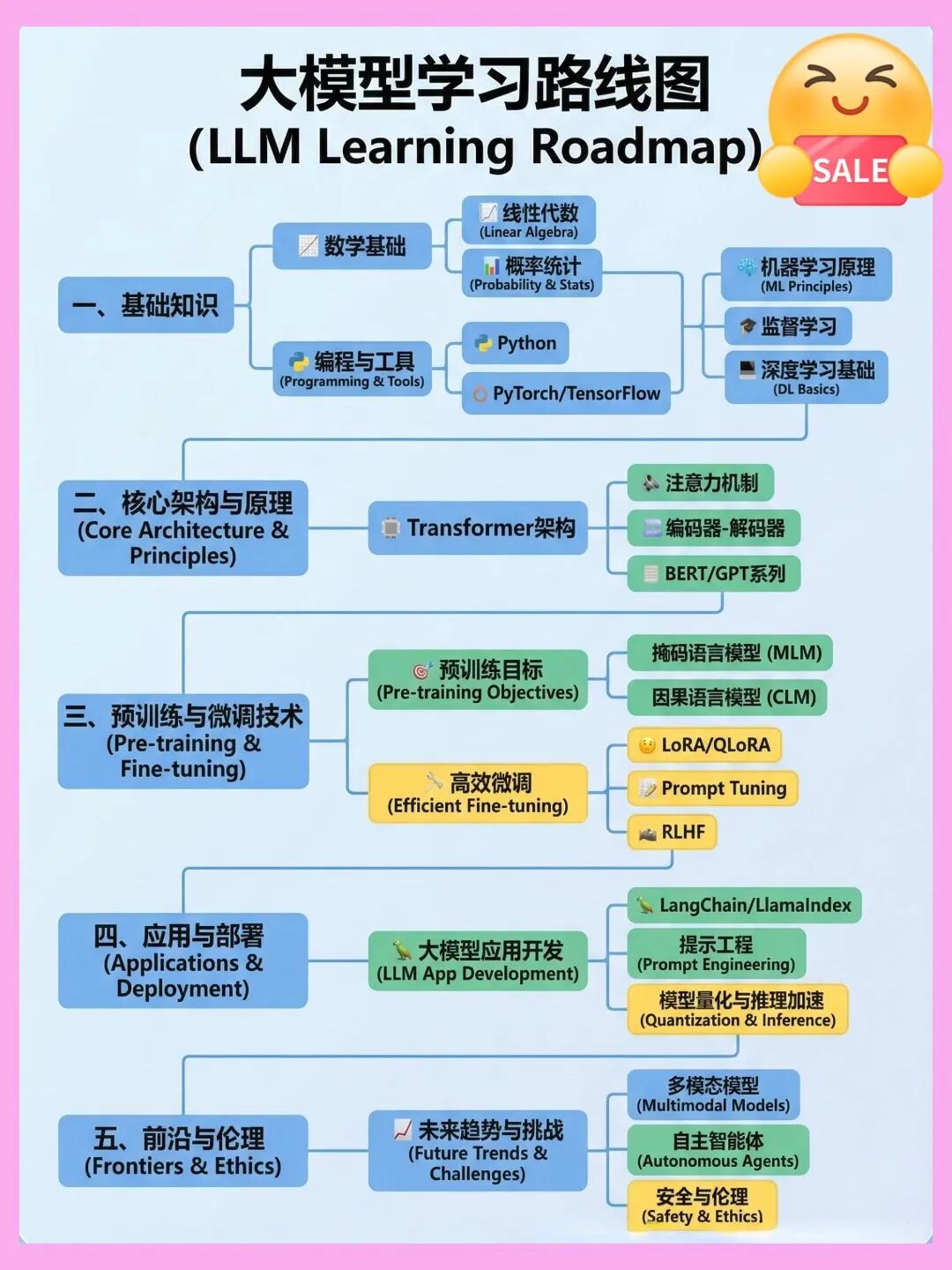
因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取