
从零开始理解 Agent(四):给 Agent 找个帮手——最简 SubAgent 实现

想象一下这个场景:你让 Agent "搭建一个博客系统,前端用 React,后端用 FastAPI,数据库用 SQLite"。一个 Agent 要同时精通前端、后端、数据库——它可以做到,但很容易顾此失彼,上下文越来越长,后面写前端的时候把前面后端的细节忘了。
现实中我们怎么解决这类问题?找帮手,分工合作。
这就是 SubAgent(子智能体)的核心思想:主 Agent 当项目经理,把子任务委派给拥有不同专业身份的 SubAgent,各管一块,互不干扰。
★ 关于本篇代码的说明:
前三篇分析的 agent.py、agent-plus.py、agent-claudecode.py 都来自 nanoAgent 原始仓库。本篇的 agent-subagent.py 是我们在 agent-claudecode.py 基础上新开发的文件(GitHub 源码[2]),专门用来演示 SubAgent 机制。
你可能注意到它只有 192 行,反而比第三篇的 265 行更少了。这是刻意为之——为了让 SubAgent 的核心逻辑尽可能通俗易懂,我们去掉了 Plan(规划)功能,只保留基础工具 + 记忆 + SubAgent。少即是多:去掉 Plan 相关的全局变量、递归调用和特殊分支后,核心循环 run_agent 从 35 行简化到了 12 行,整个代码一目了然。
一、一个生活类比秒懂 SubAgent
之前(一个人干所有活):
老板 → "小张,你把前端后端数据库全搞定"
小张(一个人扛所有)
- 写后端 API...
- 写前端页面...(等等,后端那个接口叫啥来着?)
- 建数据库表...(前端那个字段是什么格式?)
现在(项目经理 + 专人):
老板 → 项目经理(主 Agent)
│
├── "后端用 FastAPI" → 后端工程师(SubAgent A)
├── "前端用 React" → 前端工程师(SubAgent B)
└── "验证能跑通" → 测试工程师(SubAgent C)
每个人只管自己的事,干完把结果交给项目经理汇总。
但要注意一个关键点:这个类比不完全准确。现实中的员工有名字、有工位、有记忆,下次还能找他。SubAgent 不是这样的。 SubAgent 的生命周期是:
生成 → 接收任务 → 干活(可以调用工具)→ 返回结果摘要 → 消亡
一次性的。 没有持久身份,没有跨调用的记忆。主 Agent 第一次派出的"后端工程师"和第二次派出的"后端工程师"之间没有任何关联——它们是两个完全独立的、用完就扔的临时工。
这个"用完即弃"的设计是刻意的:SubAgent 解决的是单次任务内的分工问题,不是长期协作问题。它的价值在于给子任务一个干净的上下文和专注的角色,而不是构建一个持久的团队。
二、在代码里怎么实现?
如果你读过前三篇,这个实现可能会让你惊讶——核心新增只有大约 30 行代码。
为什么这么少?因为前三篇已经把所有基础设施搭好了:工具系统(第一篇)、Agent 循环(第一篇)、工具路由表(第一篇)、记忆(第二篇)。SubAgent 要做的,只是复用这些基础设施,再启动一个独立的 Agent 循环。
(由于我们去掉了 Plan 功能来保持代码简洁,整个 agent-subagent.py 只有 192 行,核心循环干净到只有 12 行——这让 SubAgent 的逻辑完全没有噪音干扰。)
2.1 新增一个工具定义
还记得第一篇中的核心洞察吗?
★
LLM 本身不会执行任何代码。它只是根据工具说明书,输出一段结构化的 JSON。真正的执行发生在我们的 Python 代码里。
SubAgent 也不例外。我们要做的第一步,就是写一份"工具说明书"告诉 LLM:"你有一个叫 subagent 的工具,可以指定角色和任务来委派子任务":
{
"name": "subagent",
"description": "Delegate a task to a specialized sub-agent with its own role and independent context.",
"parameters": {
"type": "object",
"properties": {
"role": {"type": "string", "description": "The sub-agent's specialty, e.g. 'Python backend developer'"},
"task": {"type": "string", "description": "The specific task to delegate"}
},
"required": ["role", "task"]
}
}
就这么一个 JSON。和 read、write、bash 等工具完全一样的格式——对 LLM 来说,subagent 就是"又一个工具",没有任何特殊之处。
2.2 实现 subagent 函数
def subagent(role, task):
"""启动一个独立的 Agent 循环,拥有专属角色和独立上下文"""
print(f"\n[SubAgent:{role}] 开始: {task}")
# 关键 1:独立的 messages,独立的 system prompt
sub_messages = [
{"role": "system", "content": f"You are a {role}. Be concise and focused. Only do what is asked."},
{"role": "user", "content": task}
]
# 关键 2:排除 subagent 自身,防止无限递归
sub_tools = [t for t in tools if t["function"]["name"] != "subagent"]
# 关键 3:一个完整的 Agent 循环(和第一篇的核心循环一模一样)
for _ in range(10):
response = client.chat.completions.create(
model=MODEL, messages=sub_messages, tools=sub_tools
)
message = response.choices[0].message
sub_messages.append(message)
ifnot message.tool_calls:
print(f"[SubAgent:{role}] 完成")
return message.content
for tc in message.tool_calls:
fn = tc.function.name
args = json.loads(tc.function.arguments)
print(f" [SubAgent:{role}] {fn}({args})")
result = available_functions[fn](**args "fn")
sub_messages.append({"role": "tool", "tool_call_id": tc.id, "content": result})
return"SubAgent: max iterations reached"
2.3 注册到路由表
available_functions["subagent"] = subagent
完了。就这些。
三、等一下——代码里没有调用 subagent 的地方?
如果你仔细看完整个代码,会发现一件"奇怪"的事:没有任何地方主动调用 subagent() 函数。没有 if task == "复杂任务": subagent(...),没有任何预编排逻辑。
这正是 Agent 和传统程序的根本区别,也是贯穿这整个系列的核心设计思想。
让我用一张图还原 subagent 被调用的完整链路:
用户: "创建一个 TODO 应用,包含 Python 后端和 HTML 前端"
│
▼
主 Agent 的 run_agent() 循环启动
│
▼
(1) 代码把 messages + tools 列表发送给 LLM
tools 列表里包含: [read, write, edit, glob, grep, bash, subagent]
^^^^^^^^
LLM 看到了这个工具
│
▼
(2) LLM 分析任务,决定委派,返回:
{"tool_calls": [{"function": {"name": "subagent",
"arguments": {"role": "Python backend developer",
"task": "用 FastAPI 创建..."}}}]}
│
▼
(3) 核心循环中的通用调度代码执行:
fn = "subagent"
args = {"role": "Python backend developer", "task": "..."}
result = available_functions["subagent"](**args ""subagent"")
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
走到了我们写的 subagent() 函数!
│
▼
(4) subagent() 内部启动一个全新的 Agent 循环
- 独立的 system prompt: "You are a Python backend developer."
- 独立的 messages 列表
- 可以使用 read/write/edit/bash 等工具
- 循环结束后,返回结果文本
│
▼
(5) 结果返回给主 Agent,主 Agent 可能继续派出前端 SubAgent...
关键在第 (3) 步——available_functions["subagent"](**args ""subagent"") 这行代码。它和 available_functions["bash"](**args ""bash"") 走的是完全相同的调度路径。在核心循环眼里,subagent 和 bash 没有任何区别,都是"LLM 说要调用,那我就执行"。
控制流在 LLM 手里,不在代码里。 代码只提供能力(注册工具),LLM 决定何时使用。
四、三个关键设计决策
4.1 为什么 SubAgent 要有独立的 messages?
# 主 Agent 的 messages(可能已经很长了)
messages = [system, user, assistant, tool, assistant, tool, ...]
# SubAgent 创建全新的 messages(从零开始)
sub_messages = [
{"role": "system", "content": f"You are a {role}. ..."},
{"role": "user", "content": task}
]
还记得第二篇中的"短期记忆"概念吗?messages 列表就是 Agent 的短期记忆。如果 SubAgent 共享主 Agent 的 messages,它会看到所有历史——前端 SubAgent 会被后端的代码细节干扰,上下文越来越长,token 开销越来越大。
独立的 messages 意味着:SubAgent 只知道自己的角色和任务,保持专注。而且这个 sub_messages 在函数返回后就被垃圾回收了——SubAgent 没有任何持久记忆,干完活就消亡,下次调用是一个全新的 SubAgent。
4.2 为什么 SubAgent 有不同的 system prompt?
# 主 Agent: 协调者
"You are an orchestrator agent. You can delegate to sub-agents..."
# SubAgent: 专家
f"You are a {role}. Be concise and focused. Only do what is asked."
第三篇中我们讲了 Rules——用声明式文件定制 Agent 的行为。SubAgent 的 system prompt 是同一个思路的极简版:通过不同的角色描述,让同一个 LLM 展现出不同的专业行为。
当 role 是 "Python backend developer" 时,LLM 会倾向于用 FastAPI/Flask,写 RESTful 接口;当 role 是 "frontend developer" 时,LLM 会倾向于写 HTML/CSS/JavaScript。同一个模型,不同的人格。
4.3 为什么要排除 subagent 工具?
sub_tools = [t for t in tools if t["function"]["name"] != "subagent"]
这和第三篇中 plan 工具排除自身是同样的思路——防止无限递归。如果 SubAgent 也能派出自己的 SubAgent,而那个 SubAgent 又派出自己的……就会无限嵌套下去。
一行代码,一个过滤,问题解决。
五、实际运行效果
假设用户输入:
python agent-subagent.py "创建一个简单的 TODO 应用,包含 Python 后端和 HTML 前端"
终端输出大致如下:
[Tool] subagent({"role": "Python backend developer", "task": "创建一个 FastAPI ..."})
==================================================
[SubAgent:Python backend developer] 开始: 创建一个 FastAPI 后端...
==================================================
[SubAgent:Python backend developer] write({"path": "app.py", ...})
[SubAgent:Python backend developer] bash({"command": "pip install fastapi"})
[SubAgent:Python backend developer] 完成
[Tool] subagent({"role": "frontend developer", "task": "创建一个 HTML 前端..."})
==================================================
[SubAgent:frontend developer] 开始: 创建一个 HTML 前端...
==================================================
[SubAgent:frontend developer] write({"path": "index.html", ...})
[SubAgent:frontend developer] 完成
已完成 TODO 应用的创建:
- app.py: FastAPI 后端,包含 GET/POST/DELETE 接口
- index.html: 前端页面,包含添加和删除功能
注意两个关键现象:
主 Agent 自己一行代码都没写。 它只做了两件事:调用 subagent 委派后端任务,再调用 subagent 委派前端任务,最后汇总结果。
两个 SubAgent 各管各的。 后端 SubAgent 在写 app.py 时,前端 SubAgent 还不存在。前端 SubAgent 启动时,有自己全新的上下文,不会被后端的细节干扰。
六、SubAgent vs 之前的方案:什么时候用哪个?
|
场景 |
推荐方案 |
为什么 |
|---|---|---|
|
"统计目录下的文件数" |
第一篇的基础 Agent |
简单任务,不需要额外机制 |
|
"找到所有 TODO 并整理到文件" |
第二篇的 Plan 多步执行 |
步骤之间有依赖(先搜索、再整理、再写入) |
|
"前端用 React,后端用 FastAPI" |
SubAgent |
子任务之间相对独立,需要不同专业身份 |
|
"按照项目规范重构代码" |
第三篇的 Rules |
需要行为约束,不需要分工 |
SubAgent 和 Plan 最大的区别:
|
维度 |
Plan(第二篇) |
SubAgent(本文) |
|---|---|---|
|
上下文 |
所有步骤共享 messages |
每个 SubAgent 独立 messages |
|
身份 |
同一个 Agent,同一个角色 |
每个 SubAgent 不同的专业角色 |
|
生命周期 |
步骤间 Agent 持续存在 |
生成 → 干活 → 返回摘要 → 消亡
(一次性) |
|
跨次记忆 |
步骤 2 能看到步骤 1 的全部细节 |
SubAgent B 看不到 SubAgent A 做了什么 |
|
适合 |
步骤之间有依赖 |
子任务之间相对独立 |
|
类比 |
一个人按步骤做事 |
叫了个跑腿临时工,干完就走 |
七、系列总结:从 115 行到完整 Agent 架构
四篇文章,我们从零搭建了一个完整的 Agent 认知体系:
┌───────────────────────────────────────────────────────┐
│ Agent 架构全景 │
│ │
│ ┌──────────────┐ 第四篇 (本文) │
│ │ SubAgent │ 多智能体协作 ── subagent() 工具 │
│ ├──────────────┤ 第三篇 │
│ │ Rules │ 行为约束层 ──── .agent/rules/ │
│ │ Skills │ 技能知识层 ──── .agent/skills/ │
│ │ MCP │ 工具扩展层 ──── .agent/mcp.json │
│ ├──────────────┤ 第二篇 │
│ │ Memory │ 持久记忆层 ──── agent_memory.md │
│ │ Planning │ 任务分解层 ──── create_plan() │
│ ├──────────────┤ 第一篇 │
│ │ LLM │ 推理决策层 ──── OpenAI API │
│ │ Tools │ 工具执行层 ──── bash/read/write │
│ │ Loop │ 核心循环层 ──── for + tool_calls │
│ └──────────────┘ │
└───────────────────────────────────────────────────────┘
|
篇 |
文件 |
核心主题 |
一句话总结 |
|---|---|---|---|
|
一 |
agent.py (115行) |
工具 + 循环 |
Agent 的最小本质——LLM 是大脑,代码是手脚 |
|
二 |
agent-plus.py (182行) |
记忆 + 规划 |
时间维度——记住过去、规划未来 |
|
三 |
agent-claudecode.py (265行) |
Rules + Skills + MCP |
空间维度——扩展知识与工具 |
|
四 |
agent-subagent.py (192行) ⭐新 |
SubAgent |
协作维度——给 Agent 找帮手 |
★ 注:
前三个文件来自 nanoAgent 原始仓库[3]。第四个文件是本文新开发的(GitHub 源码),为了聚焦 SubAgent 核心逻辑,刻意去掉了 Plan 功能,因此行数反而比第三篇少。这不是倒退,而是做减法——用最干净的代码展示最核心的概念。
四个维度叠加,就构成了 OpenClaw、Claude Code、Cursor Agent、Devin 等产品的完整架构。
而贯穿整个系列的核心设计思想只有一个:一切能力都是"工具"。 读文件是工具,写文件是工具,搜索是工具,规划是工具(第三篇),甚至派出一个子智能体也是工具(本文)。LLM 通过统一的 Function Calling 协议按需调用它们,代码通过统一的路由表(available_functions)执行它们。
但 SubAgent 的"一次性"本质也带来了局限:它们之间无法通信,不记得上次做了什么,无法被多次调用。当任务需要真正的团队协作——你写完我来接、测出 bug 你去改、改完我再测——就需要把临时工升级为正式员工。
这就是第五篇:多智能体协作与编排的主题:用两个类(Agent + Team)实现持久记忆、身份管理和通信通道。
最后
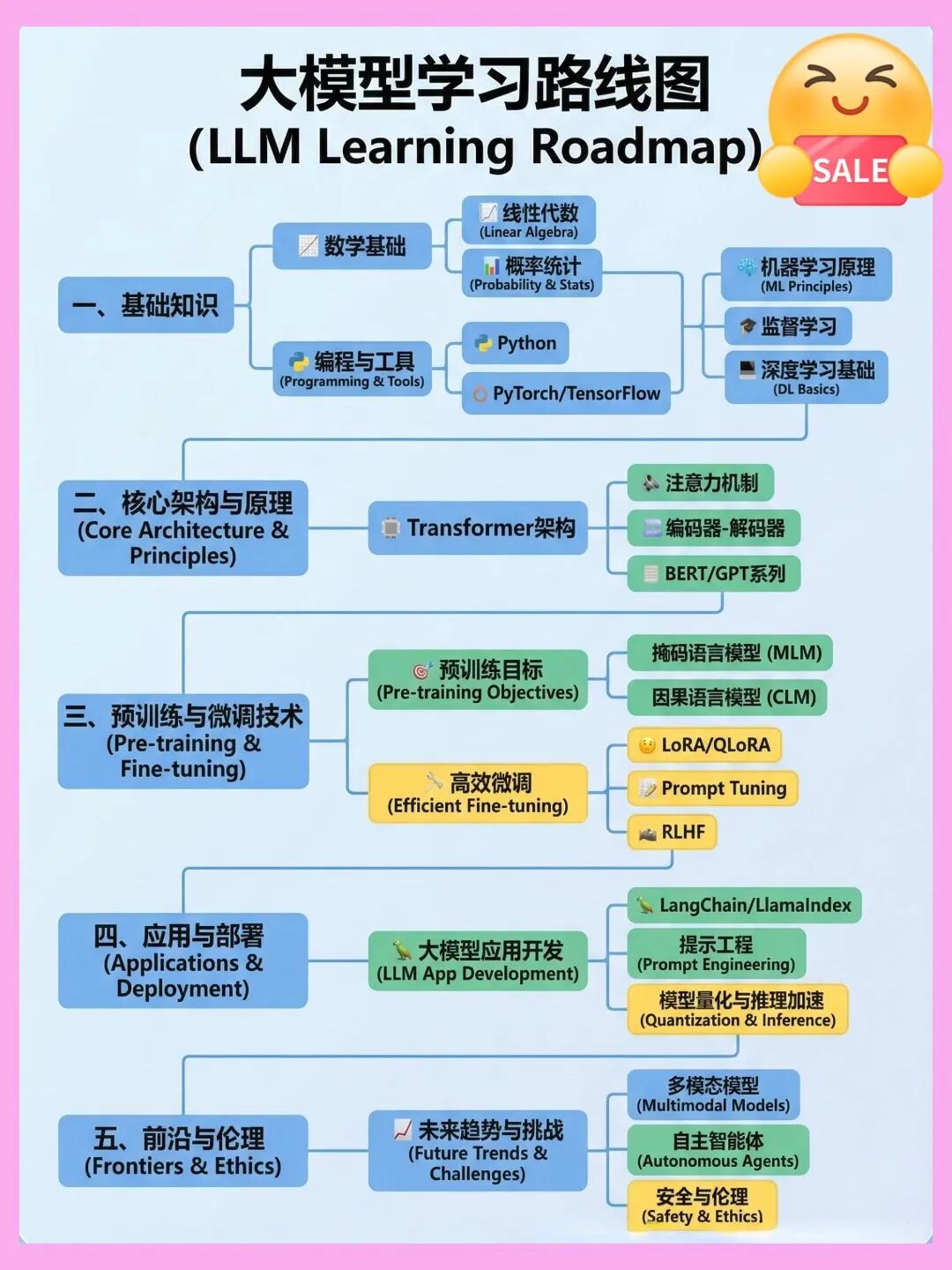
从0到1!大模型(LLM)最全学习路线图,建议收藏!
想入门大模型(LLM)却不知道从哪开始? 我根据最新的技术栈和我自己的经历&理解,帮大家整理了一份LLM学习路线图,涵盖从理论基础到落地应用的全流程!拒绝焦虑,按图索骥~~
因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取