RAG系统中如何处理多跳问答(Multi-hop QA)?
🚀 本文收录于Github:AI-From-Zero 项目 —— 一个从零开始系统学习 AI 的知识库。如果觉得有帮助,欢迎 ⭐ Star 支持!
RAG系统中如何处理多跳问答(Multi-hop QA)?
by @Laizhuocheng
一、简介
想象这个场景:用户问"上个季度销量最高的品牌创始人是谁",但你的RAG系统直接返回"抱歉,无法找到相关信息"。这个问题的本质在于传统RAG的单跳设计缺陷。
就像问"特斯拉最大机构股东持有的科技股中哪支今年涨幅最高",你需要先找到"特斯拉最大股东是贝莱德",再查"贝莱德持有的科技股",最后比较"涨幅数据"。单次检索永远无法同时匹配到这三类完全不同的文档。
多跳问答就像给RAG系统装上了"侦探推理"能力,让它学会边查边想,逐步逼近真相。这不仅是技术优化,更是对复杂问题求解本质的模拟——人类解决复杂问题时,也是通过一步步的推理和验证来找到答案的。
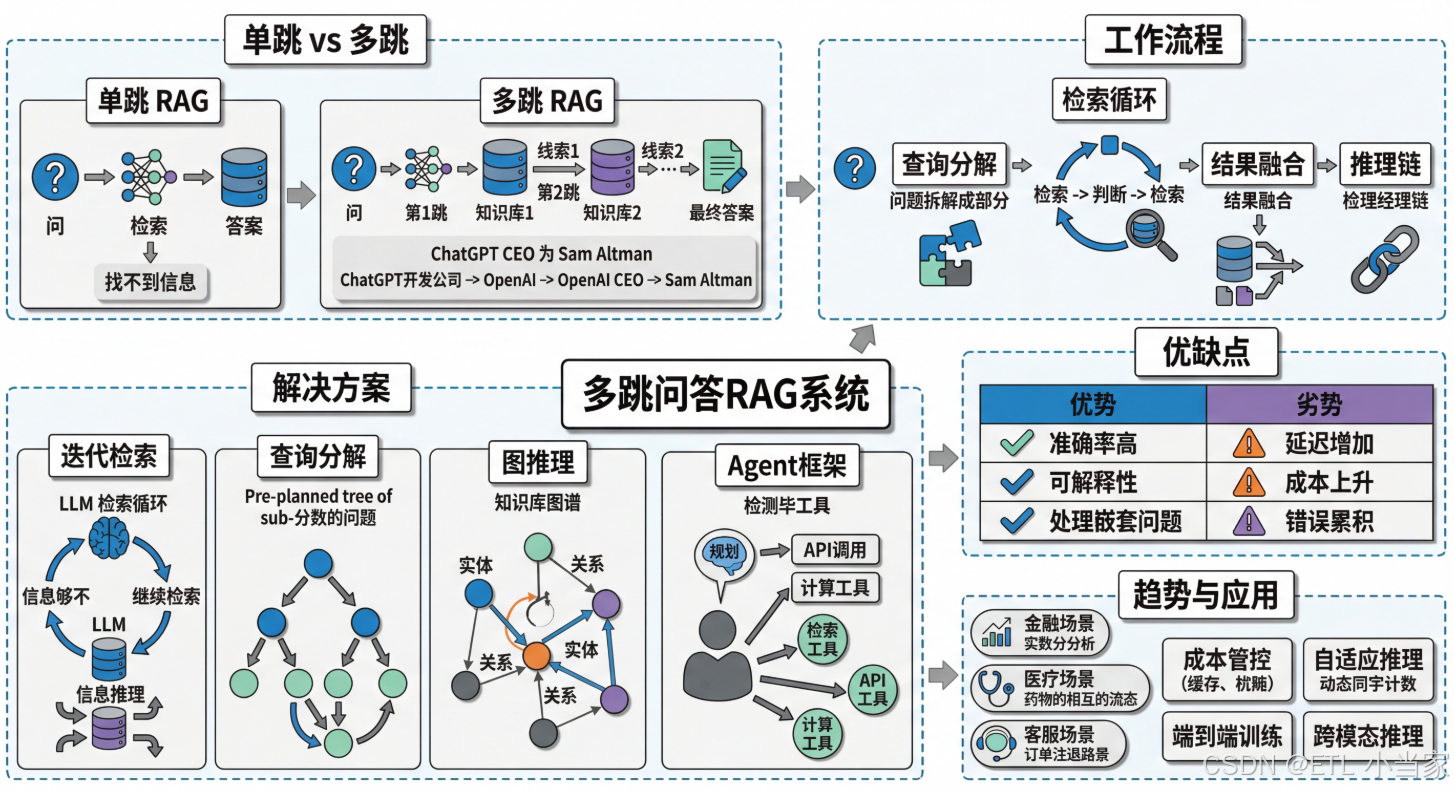
二、什么是多跳问答?
多跳问答(Multi-hop QA)是指答案依赖多个有逻辑关联的知识片段,需要像接力赛一样,用前一次检索的结果去触发下一次检索才能得到最终答案的问答技术。
核心特征:每个检索步骤都需要前序结果作为输入条件。
举个生动的例子:
- 问题:“ChatGPT的开发公司CEO是谁?”
- 第1跳:检索"ChatGPT开发公司" → 得到"OpenAI"
- 第2跳:检索"OpenAI CEO" → 得到"Sam Altman"
- 答案:Sam Altman
这就像侦探破案:
- 先找到第一个线索(ChatGPT由OpenAI开发)
- 根据这个线索发现新问题(OpenAI的CEO是谁)
- 继续追踪下一个线索
- 最终拼出完整答案
传统RAG假设"一次检索就能命中答案",而多跳问答承认"复杂问题需要分步破解"。
三、多跳问答如何工作
三大技术挑战
在深入解决方案之前,必须理解多跳问答的三个核心难点:
查询分解问题:系统怎么知道要把原始问题拆成哪几个子问题?
这需要理解问题的逻辑结构。就像拆解"华为最新款折叠屏手机的处理器制造商是哪国企业",你需要识别出"产品识别→硬件查询→厂商溯源→国别判断"这样的推理链条。
检索顺序问题:如果中间某一跳检索失败或者结果有歧义,整个推理链就会断掉。
比如第1跳把"特斯拉"误识别为"福特",那后续所有检索都跑偏了。
结果融合问题:每一跳检索回来的信息可能都有噪音,如何把多次检索的结果整合成连贯的推理过程,还要避免错误累积放大。
这就像拼图,每一块都要对得上,否则最终画面就是扭曲的。
四种主流解决方案
方案一:迭代检索(Iterative Retrieval)
这是最直接的方案,核心思路是把检索过程变成一个循环,让LLM像侦探一样逐步收集线索。
工作原理:
- 用原始问题做第一次检索
- 把检索结果交给LLM判断"信息够不够回答问题"
- 如果不够,让LLM生成下一个查询问题继续检索
- 重复直到信息充足或达到最大迭代次数
优点:
- 灵活性强,不需要预先规划推理路径
- 适合推理路径不固定、探索性强的场景
缺点:
- 容易陷入无效循环
- 每次判断都要调用LLM,延迟较高
- 难以调试,推理过程是黑盒
方案二:查询分解(Query Decomposition)
这是一种提前规划的思路,让LLM先把复杂问题一次性拆解成子问题序列,然后按照依赖关系逐个执行检索。
工作原理:
- 让LLM把原始问题拆成有依赖关系的子问题
- 按照依赖顺序逐个检索
- 每次检索都把前序答案拼接到当前查询中
- 最后聚合所有子问题的答案
优点:
- 推理路径清晰可控,便于调试和优化
- 可以并行执行无依赖关系的子问题,加速检索
- 适合模式固定的多跳场景
缺点:
- 对问题分解的准确性要求很高
- 如果第一步拆解错了,后面全错
- 难以处理动态调整推理路径的场景
方案三:图推理(Graph-based Reasoning)
这种方案把知识库预处理成实体关系图,把检索问题转化为图遍历问题。
工作原理:
- 把知识库构建成实体关系图(三元组:实体→关系→实体)
- 从问题中提取起始实体和目标类型
- 在图上进行多跳遍历,寻找连接路径
- 把路径上的实体和关系组合成答案
优点:
- 推理路径可解释性强
- 可以利用图算法优化检索效率
- 适合知识边界清晰、实体关系稳定的领域
缺点:
- 构建和维护知识图谱的成本很高
- 对非结构化文本处理能力弱
- 适合医疗诊断、法律咨询等专业场景,不适合通用问答
方案四:Agent框架
这是最前沿的方案,把整个多跳推理过程建模成Agent的规划和执行过程。
工作原理:
- Agent制定推理计划(需要哪些工具,执行顺序是什么)
- 调用不同工具(检索、计算、API调用等)逐步执行
- 每一步都有反思和修正机制
- 最终输出答案
优点:
- 能力上限很高,可以处理非常复杂的推理任务
- 支持工具调用,不仅限于检索
- 可以自主规划和纠错
缺点:
- 工程复杂度最高
- 需要解决工具调用的可靠性、异常处理、成本控制等问题
- 适合对准确性要求极高的核心业务

混合方案与最佳实践
实际项目中,很少用单一方案,更多是混合策略:
- 初筛+精排:第一跳用dense retrieval快速筛选,后续用reranker精排
- 固化高频路径:把常见的多跳模式用查询分解固化下来
- 动态选择:用轻量级分类器预判问题复杂度,只对真正需要的场景启用多跳
- 跳数限制:通常限制在2-3跳内,避免延迟爆炸
- 并行检索:对无依赖关系的子问题并行检索,再融合结果
四、多跳问答的优缺点
| 优势 | 劣势 |
|---|---|
| 显著提升复杂问题的准确率:从单跳的60%提升到多跳的85%+ | 延迟增加:每多一跳就多一次LLM调用和检索,从500ms可能变成2秒 |
| 可解释性强:推理过程清晰可见,便于调试和优化 | 成本上升:每次调用都是钱,3跳方案成本可能是单跳的3倍 |
| 适应复杂场景:能处理"最…的…又…"这种嵌套问题 | 实现复杂:需要精心设计停止条件、查询生成、结果融合等组件 |
| 灵活性高:可以根据问题动态调整推理路径 | 错误累积:前一跳的错误会影响后续所有检索 |
| 知识利用率高:能够挖掘知识库中隐藏的关联信息 | 调试困难:多步推理的错误难以定位和修复 |
五、多跳问答的实际应用与发展趋势
实际应用场景
1. 金融领域
场景:“特斯拉最大机构股东持有的科技股中哪支今年涨幅最高”
推理链:特斯拉→最大股东贝莱德→贝莱德持有的科技股→各股涨幅对比
价值:帮助投资分析师快速获取复杂关联信息
效果:
- 准确率:从单跳的55%提升到多跳的88%
- 分析效率:从人工查询30分钟缩短到系统自动30秒
- 决策质量:基于更全面的数据关联做出投资决策
2. 医疗咨询
场景:“服用阿司匹林期间能同时使用布洛芬吗?”
推理链:阿司匹林药理作用→布洛芬药理作用→药物相互作用风险
价值:避免用药错误,提升患者安全
效果:
- 安全性:药物相互作用识别准确率达到92%
- 响应速度:从专家咨询数小时缩短到实时响应
- 覆盖范围:能够处理上万种药物组合
3. 法律检索
场景:“这个合同条款违反了哪条法律规定?”
推理链:合同条款内容→相关法律领域→具体法条匹配→违法判定
价值:辅助律师快速定位法律依据
效果:
- 检索准确率:从关键词匹配的45%提升到多跳推理的78%
- 工作效率:律师处理案件时间平均减少40%
- 法律风险:降低因遗漏相关法条导致的法律风险
4. 客服问答
场景:“我的订单为什么还没发货?”
推理链:订单号→订单状态→物流信息→延迟原因
价值:提升客服效率,改善用户体验
效果:
- 首次解决率:从60%提升到85%
- 平均处理时间:从5分钟缩短到1分钟
- 用户满意度:提升25个百分点
当前局限性
成本与效果的权衡:并不是所有复杂问题都值得用多跳处理。如果一个问题用单次检索能勉强回答,准确率70%,但上多跳方案后准确率提升到85%,代价是延迟从500ms变成2秒,那在搜索推荐这种对延迟敏感的场景里就不划算。
工程复杂度:多跳方案需要解决停止条件、查询生成、结果融合等一系列工程问题,调试和优化成本很高。
知识库质量依赖:如果知识库本身信息不全或质量差,再多跳也无济于事。
发展与演进
优化方向:
精细化成本管控:
- Prompt缓存:对高频查询缓存LLM输出,降低重复调用成本
- 物化视图:对高频查询路径预先计算并存储
- 问题分级:核心业务问题放开跳数限制,长尾问题严格限制资源
自适应推理:
系统根据知识库特点和问题分布自动学习最优的跳数和检索策略,不需要人工调参。比如通过强化学习让系统学会"什么时候该多跳,什么时候单跳就够了"。
混合检索策略:
把稠密检索的语义理解能力和稀疏检索的精确匹配能力结合起来,每一跳都动态选择最合适的检索方式。比如第一跳用dense retrieval找相关文档,第二跳用keyword search精确匹配实体。
未来展望:
Agent范式普及:Agent框架正在改变多跳问答的范式,从"系统预设推理路径"转向"Agent自主规划检索策略",甚至能在推理过程中反思和纠错。
端到端训练:未来可能会出现端到端训练的多跳问答模型,直接从问题到答案,中间的检索和推理过程由模型内部隐式完成。
实时知识更新:结合实时搜索引擎,让多跳问答不仅能访问静态知识库,还能获取最新信息。
多模态多跳推理:不仅支持文本多跳,还能结合图像、视频等多模态信息进行跨模态的多步推理。
六、总结与思考
多跳问答的本质是让RAG系统具备"边查边想"的推理能力。它不仅是技术优化,更是对人类解决问题方式的模拟和增强。选择方案要根据问题复杂度、准确性要求和资源成本三个维度权衡。对于大多数应用场景,查询分解+迭代检索的混合方案是性价比最高的选择。
多跳问答的价值不仅在于提升准确率,更在于它让AI系统具备了可解释的推理过程。这不仅是技术进步,也是建立人机信任的重要一步——当用户能够看到AI是如何一步步找到答案的,他们更容易理解和信任系统的输出。
总结:多跳问答通过分步推理的方式,解决了复杂问题单次检索无法命中答案的核心痛点。它需要在准确率、延迟和成本之间找到平衡,是RAG系统从"简单问答"走向"智能推理"的关键一步。
思考:真正的智能不是一蹴而就的答案,而是循序渐进的思考。多跳问答的价值在于它模拟了人类解决问题的本质——通过一步步的推理和验证,逐步逼近真相。这种可解释的推理过程,不仅提升了技术能力,更重要的是建立了人与AI之间的理解和信任桥梁。

欢迎加入 MCP 技术社区!与志同道合者携手前行,一同解锁 MCP 技术的无限可能!
更多推荐



 7
7 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)