手把手搭建论文写作AI助手:我用Nexent让本科毕设效率翻倍
目录

引言:每个大四毕业生心中都有一个“论文救星”
作为计算机科学与技术专业的大四学生,我正处在毕业论文的“水深火热”之中。电脑里塞满了从知网、IEEE下载的参考文献PDF,还有自己写的实验报告、代码注释、以及导师发的修改意见。每次要引用某个观点,都得在几十篇论文里翻找;想看看某个算法的实现细节,又得在乱糟糟的代码文件夹里搜索。直到我在Nexent(nexent.tech)上亲手“孕育”了一个专属论文写作助手,取名“毕设小助手”。它不仅能消化我所有的杂乱文档,还能帮我查文献、转格式、甚至理清综述思路。这篇文章是我的完整“孕育手记”,希望能给同样在毕设苦海中挣扎的你一些启发。
第一步:搭建神经中枢——模型接入的两种姿势
打开Nexent,我被简洁的界面吸引。左侧导航栏清晰,我直奔“模型管理”——这里是智能体的大脑配置中心。

点击添加模型,首先需要选择当前需要添加的模型的类型,这里我先添加的是大语言模型。刚好我有之前申请SiliconCloud的API Key,里面储备了多个主流模型。我尝试了两种接入方式:
首先是单个添加。输入模型名称deepseek-ai/DeepSeek-V3,粘贴API地址和密钥,点击验证,几秒后提示可用,点击添加。整个过程零代码,干脆利落,就像给手机装App一样简单。
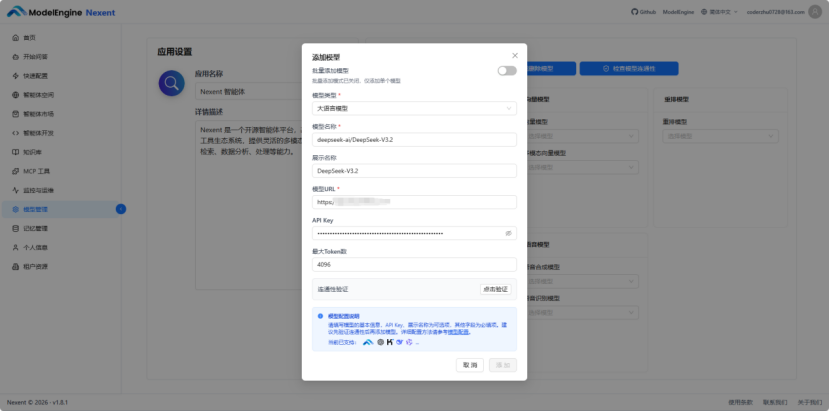
填写好相关信息后,先点击连通性验证行的”点击验证”,这是添加该模型前优先需要做的事,只有连通性验证通过后才能添加当前大语言模型。
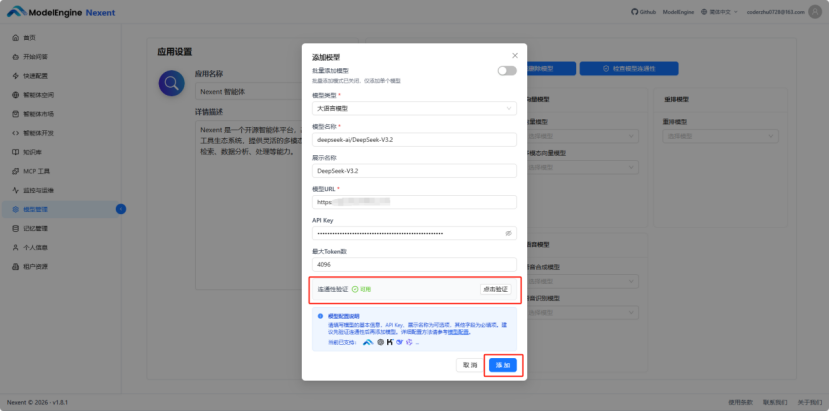
当连通性验证旁边出现绿色的”可用”字样,以及右下方的添加按钮由灰变蓝变成可点击状态时,代表当前大语言模型可以添加。
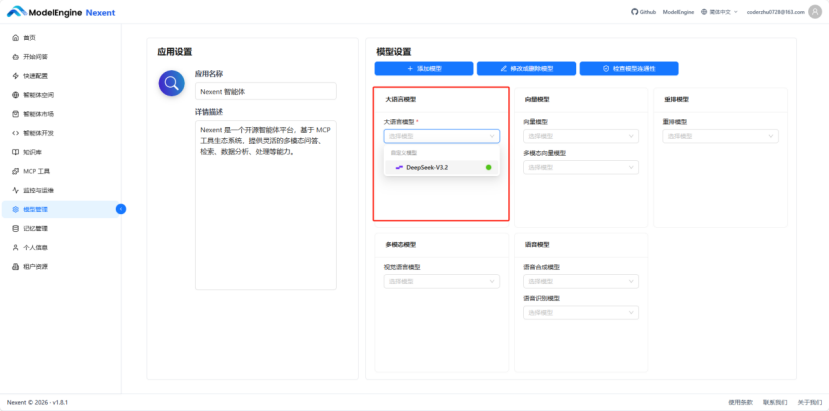
成功添加后在大语言模型处可以展开当前成功添加的大语言模型列表,可以根据需求选择需要的大语言模型。
其次是批量导入,点击”添加模型”后切换到批量添加模型,选择模型提供商以及模型类型,我这里选择的模型提供商是硅基流动,模型类型是大语言模型。并填写从硅基流动获取的API Key。
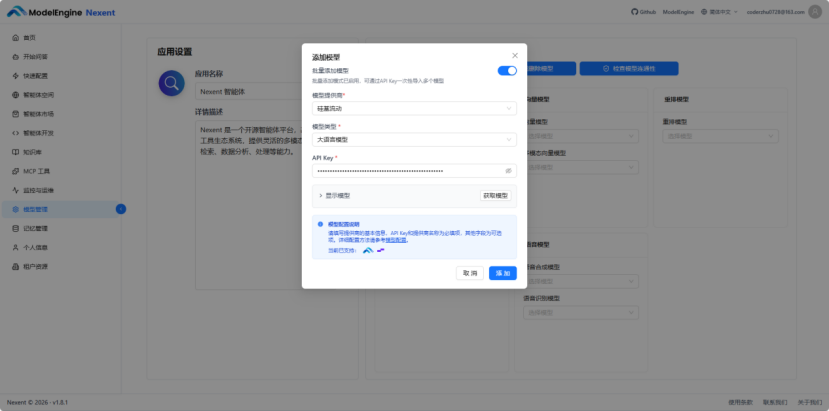
填写好相关信息后,点击”获取模型”,展示出该模型供应商可使用的大语言模型,在这里只需要选择自己需要的,最后点击”添加”即可。
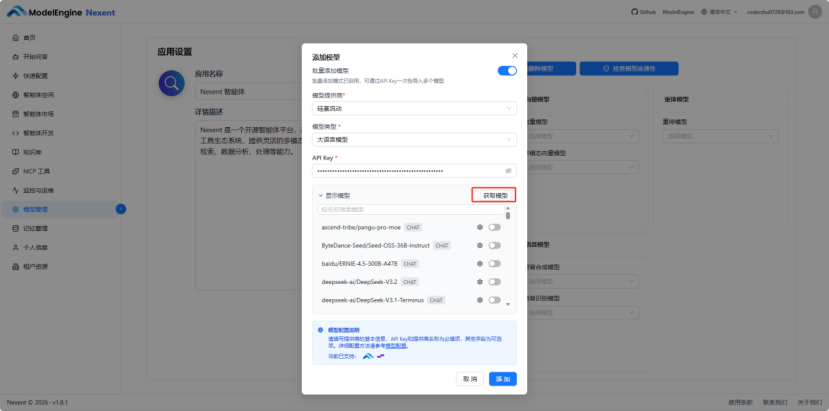
为了后续灵活切换,我一次性复制了多个模型信息(Qwen/Qwen2.5-72B-Instruct、inclusionAI/Ling-flash-2.0等),使用平台的“批量导入”功能,一键全部添加成功。
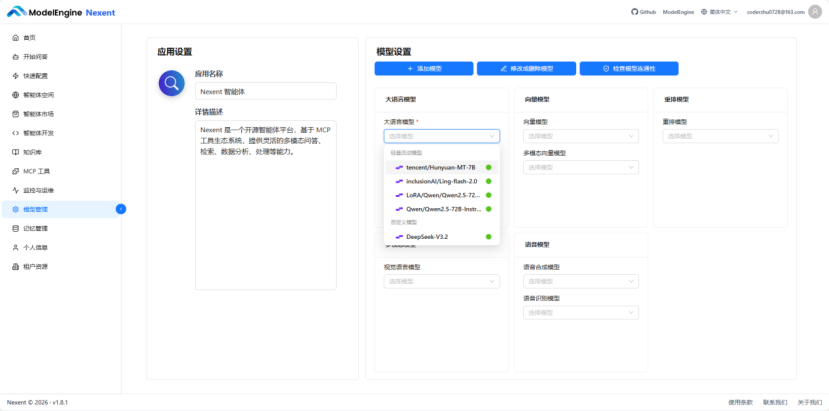
成功添加后,展开大语言模型列表,就能看到批量添加的大语言模型以及之前添加的DeepSeek-V3。这种设计对需要尝试不同模型的场景非常友好,我可以根据任务需求随时切换“大脑”。
我最终选择了DeepSeek-V3作为主模型,它在理解学术文本和代码方面表现出色,且支持160K上下文,足够处理长篇论文和代码文件。
第二步:喂养知识库——让AI真正“读懂”我的毕设资料
接下来是核心环节——构建知识库。
首先配置系统模型(用于Embedding)。根据官方文档,Nexent支持多种Embedding模型。我依然使用硅基流动API,选用了专为学术场景优化的组合:BAAI/bge-large-en-v1.5(处理英文文献)和BAAI/bge-large-zh-v1.5(处理中文资料)。添加向量模型和添加大语言模型类似,先点击”添加模型”切换到批量添加,选择模型供应商为硅基流动,选择模型类型为向量模型,将在硅基流动获取到的API Key输入后点击获取模型,即可展示出硅基流动下能使用的向量模型,由于模型有很多不方便翻找,这里使用了一下搜索功能,只需将关键词”BAAI”输入上去,下方的列表便会实时筛选。
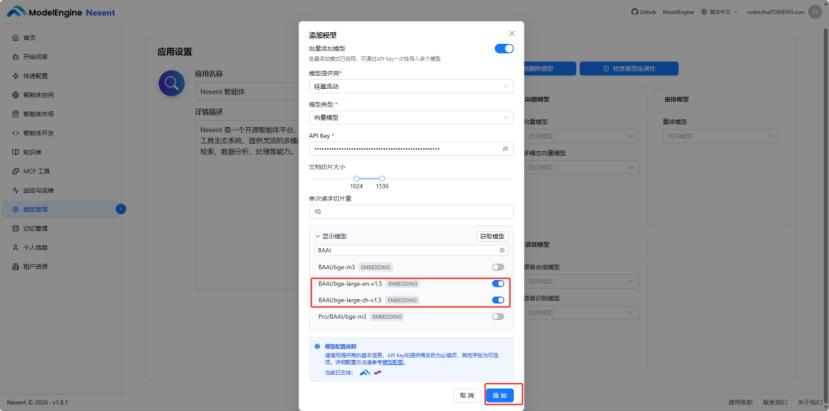
选择好所需的向量模型后,点击”添加”,添加成功后可以在向量模型模块展开已经添加好的向量模型列表,根据需求进行选择。
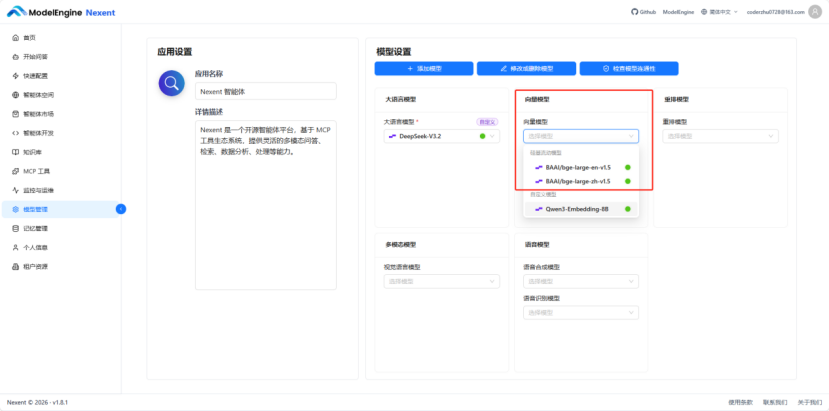
配置好所需的模型后,点击”快速配置”就可以开始制作我的论文”小助手”啦。
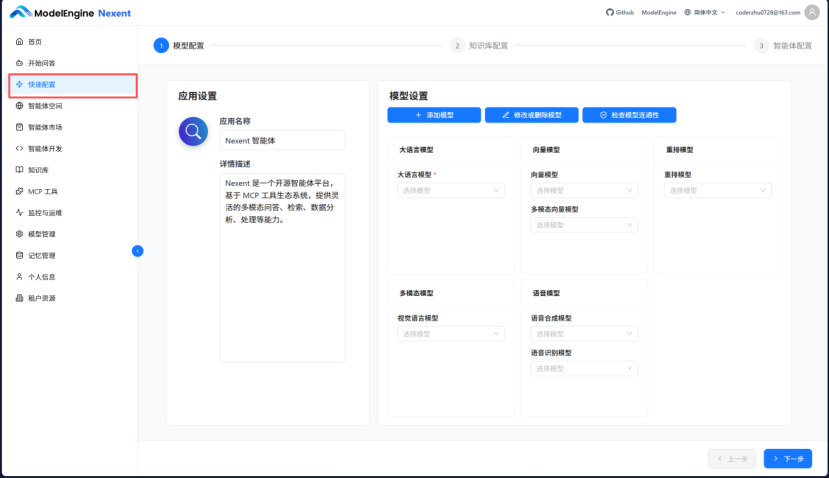
首先给应用命名,这里命名为”毕设小助手”,添加详情介绍,选择好之前确定需要使用的大语言模型以及向量模型。
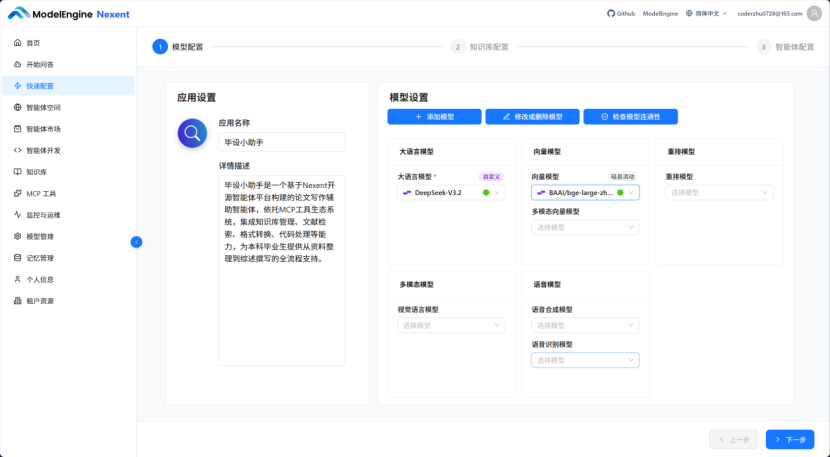
点击”下一步”,开始进行知识库配置,新建一个名为“毕设论文库”的库。这里上传了.pdf、.txt、.pptx、.docx多种格式的文件,为了测试平台解析读取能力。
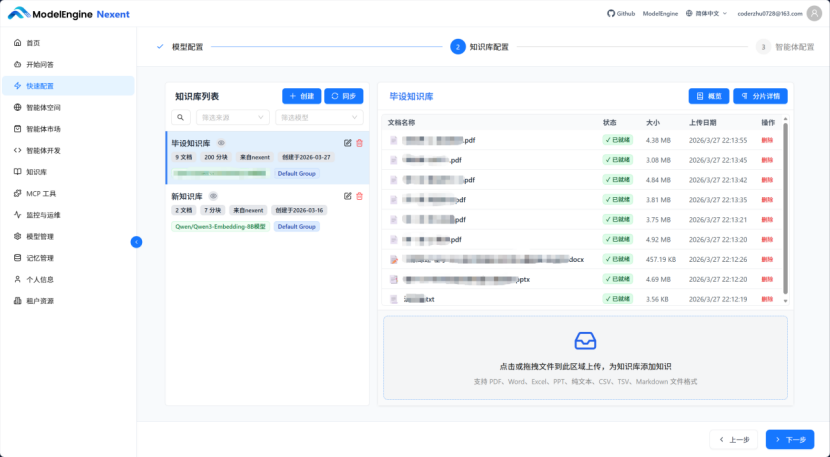
上传过程非常流畅,平台实时显示解析进度,并将文档拆分成若干“知识块”。几分钟后,所有文件状态变为“已就绪”。我注意到平台会显示每个文档被拆分成的块数,这种透明感让人安心。
知识库总结:一键生成的惊喜
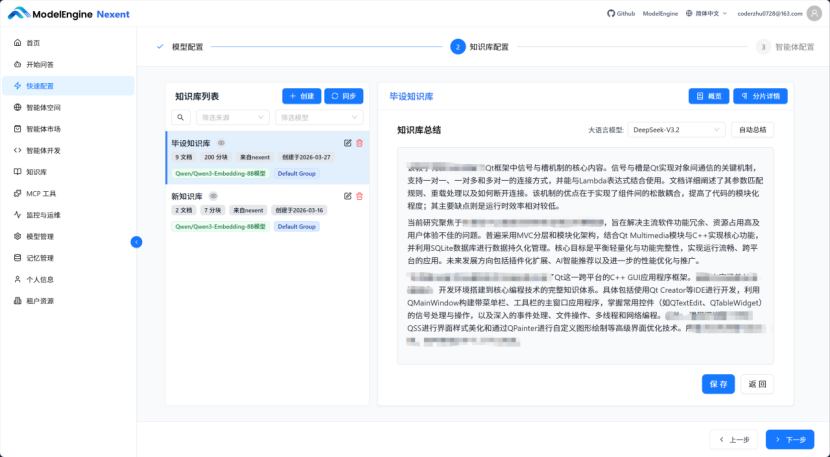
上传完成后,我点击知识库右上角的“概览”,选择好大语言模型,点击“自动总结”。短短十几秒后,平台生成了整个知识库的智能摘要、高频关键词和主题分类。这意味着我的AI助手不是简单地存储文件,而是真正“读过”并“理解”了所有材料。这个功能对于快速概览文献库全貌非常有帮助,我一下就知道我的资料主要集中在哪些方向。
第三步:接入论文工具——MCP生态让AI“动起来”
能读文献的AI很棒,但写论文还需要实时查询和工具支持。这就轮到MCP工具大显身手了。根据官方文档,Nexent基于MCP生态,具备丰富的工具集成能力。
我计划接入三个工具,分别体验三种不同的接入方式:
首先是第三方URL接入,这是最简单的接入方式。我需要一个arXiv论文查询功能(本科毕设也常看arXiv上的最新研究)。从Modelscope上找到一个公开的arXiv API(URL形式)。在“MCP工具”模块点击“添加”,填入服务器名称和该URL,点击保存,然后进行“连通性校验”,提示成功。整个过程像安装手机应用一样简单。
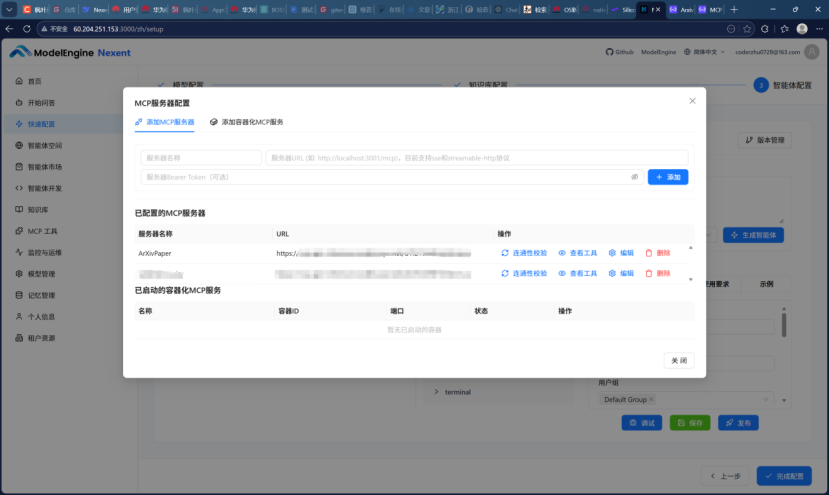
工具列表渐渐丰富:arXiv查询、格式转换、代码片段格式化……我的AI助手开始长出“手脚”。
第四步:赋予灵魂——智能体开发与调试
模型、知识库、工具都已齐备,终于进入“智能体开发”模块——这里是赋予AI灵魂的“手术台”。
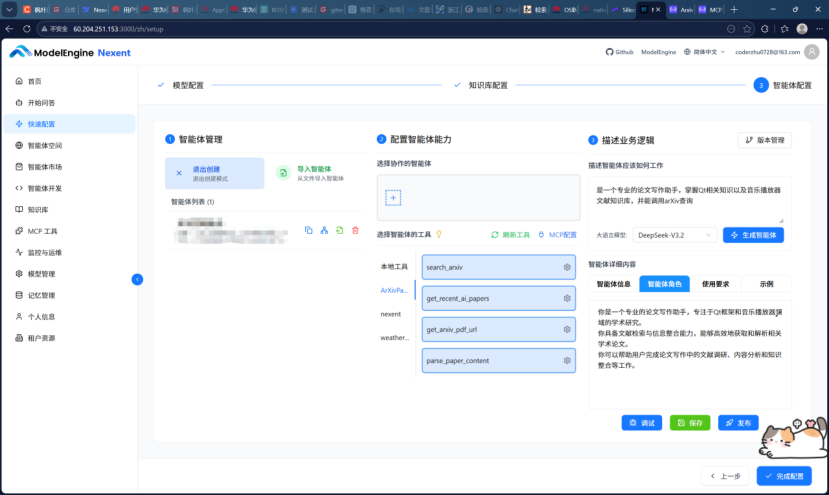
我点击“新建智能体”,命名为“毕设小助手”。配置界面非常直观:
模型选择:勾选之前接入的DeepSeek-V3。
工具选择:从MCP列表中,勾选“arXiv查询”。
知识库关联:关联刚刚建好的“毕设论文库”。
提示词模板:系统根据我的设置,自动生成了一段默认提示词:“你是一个专业的论文写作助手,专注于Qt框架和音乐播放器领域的学术研究。具备文献检索与信息整合能力,能够高效地获取和解析相关学术论文。你可以帮助用户完成论文写作中的文献调研、内容分析和知识整合等工作。”这段提示词逻辑清晰,角色定位准确。
接下来是激动人心的调试环节——我准备了一系列测试问题:
测试1
我:“我想写一篇关于Qt框架在音乐播放器开发中应用前景的论文,请帮我找一些最新的相关文献”
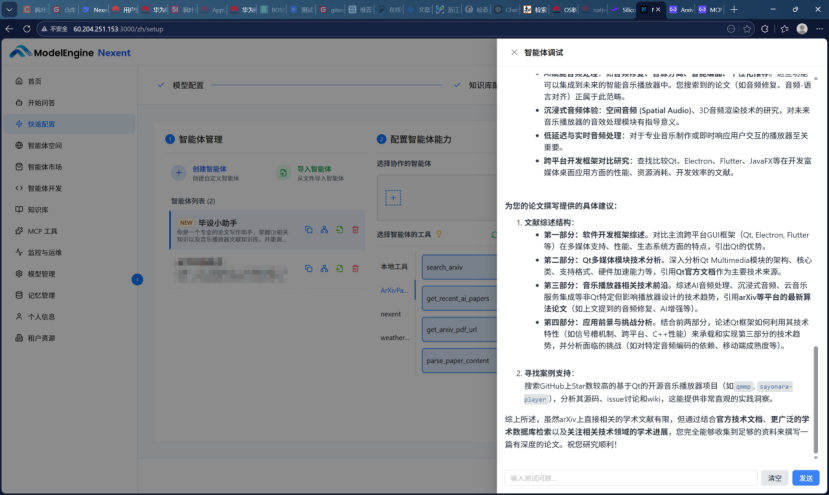
回答精准,且附有来源,体现了知识溯源能力。
测试2
我:“请帮我搜索一下最近三个月关于'audio signal processing'和'machine learning'结合的论文,最多10篇”
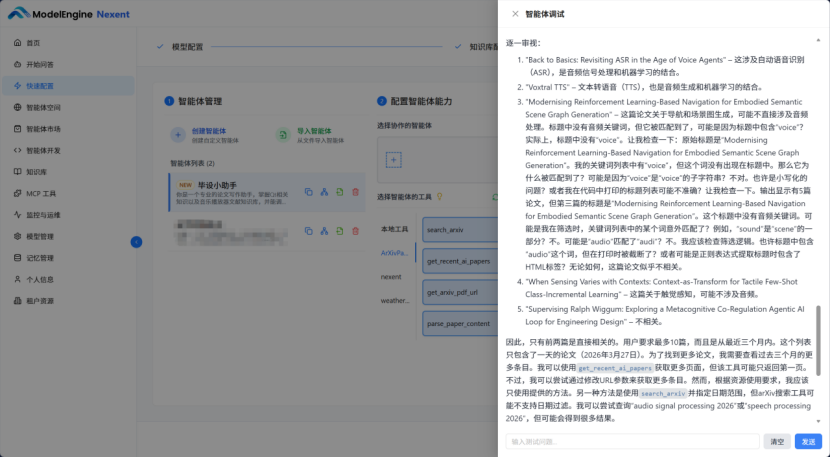
测试3
我:“我想了解Qt 6.0在多媒体模块上有哪些更新,这些更新对开发音乐播放器有什么帮助?请从学术文献中找找依据”
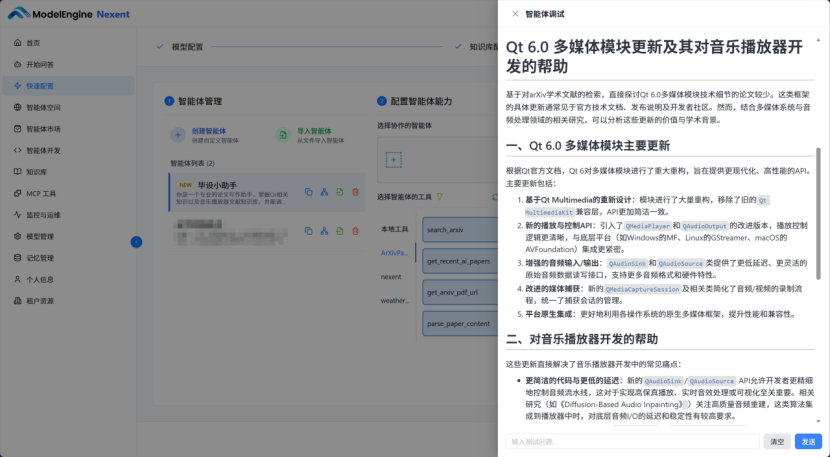
第五步:发布与生态体验——智能体“上岗”
调试无误后,我点击发布,我的“毕设小助手”就出现在个人智能体空间里。我以普通用户身份开始对话:
我:“记住,我主要做音乐播放器方向,偏好中文文献。”
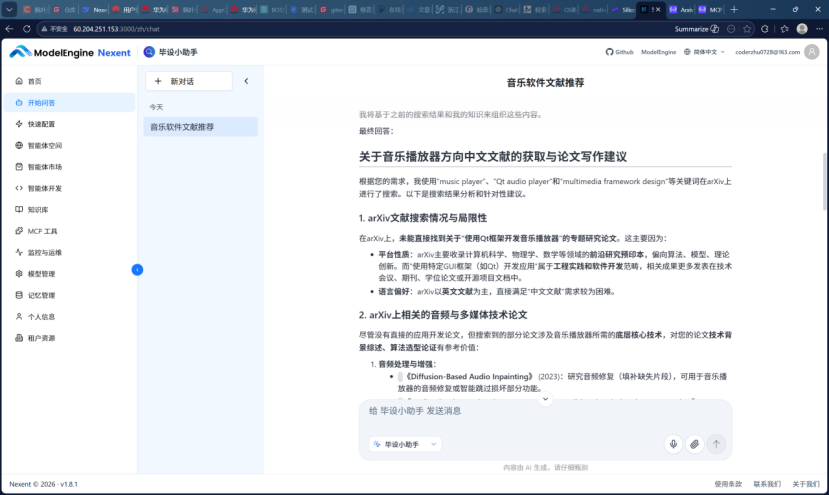
这一简单的对话指令,让我真切感受到了智能体的“记忆”能力带来的体验提升。当我向毕设小助手说出“记住,我主要做音乐播放器方向,偏好中文文献”时,它立即回复“已记住您的偏好”。在后续的对话中,当我再次询问“帮我查一下关于目标检测的最新论文”时,它返回的搜索结果果然优先展示了中文文献,且标题和摘要都以中文呈现,完全遵循了我的偏好设定。
我的感悟:好用与待优化
一整天的“孕育”经历,让我对Nexent有了切身体会。
那些让我爱不释手的设计:
第一是知识库的理解力。对PDF表格、个人笔记、第三方导入文档都能精准理解,知识库总结功能绝对是效率神器。它让我那些“沉睡”的文献和笔记真正活了起来。官方文档提到的“智能提取”和“知识溯源”功能,在预览模式和问答中都得到了体现。
第二是MCP生态的开放性。从“粘贴URL”到“npx启动自定义服务”,覆盖了从普通用户到极客的扩展需求。我可以把arXiv、格式转换、代码工具统统集成进来,未来甚至能接入学校图书馆的数据库。这种基于MCP标准的架构,让平台具备了无限扩展的潜力。
第三是提示词的智能生成。大幅降低了高质量智能体的构建门槛,同时保留了手动微调的空间。系统生成的提示词已经足够专业,我只需加点个人偏好即可。这让我这样的非提示词工程师也能快速创建高质量助手。
第四是流程引导清晰。从模型管理到知识库,再到工具和智能体开发,路径明确,没有让我迷失在复杂的功能中。这种“低门槛+高天花板”的设计,对新手非常友好。
那些期待未来优化的地方:
第一是调试过程可视化。目前只能看到最终回答,希望未来能可视化工具和知识库的调用链路,实时显示“正在调用arXiv工具”、“从知识库检索到3个相关片段”等过程。这样更容易理解AI的“思考路径”和排查问题。
第二是MCP工具市场丰富度。目前工具还较少,期待一个分类清晰、有评分、一键安装的公共工具商店,就像手机应用商店一样。如果能有分类、评分、使用量统计,就更好了。
第三是记忆能力深化。短期记忆很好,但文档中提到的长期记忆(跨会话记住用户偏好)体验还不够深入。如果智能体能记住我的研究方向、常用数据库、偏好格式,那将是真正意义上的“第二大脑”。
第四是多模态能力增强。目前知识库主要处理文本,但我的论文里还有很多图表、实验结果截图。如果未来能直接“看懂”图表中的文字、公式,甚至支持OCR识别扫描版论文,那将是质变。官方文档中提到的“多模态支持”正在路上,我很期待。
第五是协作功能。如果智能体支持多人共享知识库,对于小组合作写论文会非常有帮助。比如共享文献库、共同维护实验记录等。
尾声:未来已来
总的来说,Nexent给我的感觉是一个骨骼清奇、灵魂有趣、肌肉正在生长的平台。它把构建智能体的复杂过程简化成了“搭积木”,让普通人也能创造属于自己的论文写作助手。虽然一些高阶功能还在路上,但已经展现出的核心能力,足够让我对用它来改造我的毕设写作方式充满期待。
接下来,我打算再给它投喂更多资料——所有参考文献、实验数据、代码文件,看看它能不能成为真正的“毕设知识中枢”。同时,我也想尝试接入更多工具,比如学校图书馆的检索系统、甚至是LaTeX编译工具,让它成为更得力的“毕业设计数字员工”。
如果你也受够了在论文海洋里“随波逐流”,不妨也来试试Nexent,亲手“养”一个懂你的毕设助手。或许你会发现,写毕业论文,只需要带上想法,剩下的都交给AI。
感谢各位大佬支持!!!
互三啦!!!

欢迎加入 MCP 技术社区!与志同道合者携手前行,一同解锁 MCP 技术的无限可能!
更多推荐



 40
40 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)