Gradio Agents & MCP Hackathon 2025 — Agent Track 荣誉奖_Honorable Mention--仅需425 行 Python
引言
【内部深度思考 Thinking Process】
■ 输入/输出梳理
Input: 用户自然语言 query(客服问题)+ 多轮对话历史
Output: LLM 生成的、有知识库 grounding 的回答 + 可观测的检索溯源面板
■ 核心难点
难点1: 多轮对话中的指代消解(coreference)
"它多少钱?" → "它"是什么?
→ 解法: CondensePlusContextChatEngine 的 Condense 步骤用 LLM 把历史+新问题压缩成一个
独立完整的问题,再送去检索。
难点2: 多知识库路由决策
不能把所有 index 全查一遍(延迟高、噪声多)
→ 解法: LlamaCloudCompositeRetriever(mode=ROUTING) —— 给每个 index 挂一段
自然语言 description,内部 LLM Router 根据 query 语义匹配 description 来决策
"去哪个抽屉找材料",而不是把所有抽屉翻一遍。
难点3: Gradio 响应式 UI(避免长时间白屏等待)
→ 解法: 两阶段链式事件(.then() 链),第一阶段 queue=False 立即更新 UI 显示
"Retrieving...",第二阶段 queue=True 排队等 LLM 结果返回再刷新。
难点4: 幻觉控制 + 元数据感知
→ 解法: temperature=0 + system_prompt 双重约束;
明确要求 LLM "从 context 的 metadata 中提取文件信息"。
■ 资料缺失时的合理推测
LlamaCloud 内部的 ROUTING 实现没有开源,但根据 LlamaIndex 官方文档和论文,
其内部很可能是一个 function-calling 或 tool-selection 形式的 LLM 调用,
把各 index 的 description 作为 tool description 传入,让 LLM 决定调用哪个"工具"。
rerank 步骤很可能使用 Cohere Rerank(requirements 隐含,GitHub topic 标签有 cohere-embeddings)。
项目全局视角 (Overview)
一句话定位:这是一个用 LlamaIndex 托管检索服务 + Claude Sonnet + Gradio 搭建的多知识库智能路由客服机器人,其核心价值在于:用极简的代码(425行)把"企业多部门文档 → 精准路由 → 对话式问答"这条工程链跑通,并内置可观测性。
业务痛点
传统客服系统面临的经典三角困境:
| 痛点 | 表现 | 该项目的解法 |
|---|---|---|
| 知识碎片化 | 产品手册、FAQ、账单政策分散在不同部门 | 4个独立 LlamaCloud Index,各司其职 |
| 意图识别不准 | 全文搜索关键词匹配,跨库检索噪声大 | ROUTING 模式,LLM 做意图分类再定向检索 |
| 多轮对话失忆 | 每轮当作新问题,无法理解"它/这个政策" | CondensePlusContext,用 LLM 把历史压缩成独立问题 |
| 黑盒不可信 | 客服回答没有来源,无法溯源审计 | 右侧检索溯源面板,暴露 Index名/文件名/置信分 |
胜负手
这个项目最聪明的设计不是 LLM 本身,而是**把****“意图路由”**这个决策外包给了 LlamaCloud 的托管 LLM Router,并用自然语言 description 作为路由信号——无需训练任何分类器,无需维护路由规则表,只需写好几句话描述每个知识库是干什么的。
多模态数据摄入与解析 (Data Ingestion & Parsing)
What:文档类型组合
ProductManuals/ → PDF(产品手册,含技术规格、操作步骤)
FAQGeneralInfo/ → PDF(常见问题、公司政策)
BillingPolicy/ → PDF × 4(计费政策,含 v1/v2 版本迭代)
CompanyIntroductionSlides/ → PPTX(公司介绍幻灯片)+ CSV 元数据
注意两个非常规点:
- PPTX 文件:LlamaCloud 会逐 slide 解析,
page_label字段对应幻灯片页码(代码第205-208行有专门处理) - CSV 元数据文件:每个子目录都有一个
*_metadata.csv,这是手工补充的文档元数据(作者、创建日期、修改日期等),弥补 PDF 原生 metadata 字段经常为空的缺陷
# app.py L202-208: 元数据感知的页码提取
file_name = metadata.get("file_name", "N/A")
if file_name.lower().endswith(".pptx"):
page_label = metadata.get("page_label")
if page_label:
page_info = f" p.{page_label}"
Why:为什么用 LlamaCloud 托管解析而不是自己跑 OCR?
| 方案 | 优点 | 缺点 |
|---|---|---|
| 自建 Docling/PyMuPDF | 完全可控,可以自定义 chunk 策略 | 需要维护解析管线、处理公式/图表/表格的 corner case |
| LlamaCloud 托管 | 零代码接入,自动处理 PDF/PPTX/CSV,内置 pipeline 解析 | 黑盒,依赖第三方服务,成本随量计费 |
作者的选择是 LlamaCloud 托管,这是一个典型的"换钱买时间"的工程决策,在 Hackathon 场景下完全合理。
How:Chunking 策略(推测)
LlamaCloud 的默认 chunking 对 PDF 是语义感知切块(非固定字符数截断):
- PDF → 按段落/标题层级切块
- PPTX → 按 slide 切块(每张幻灯片是一个 node)
- CSV 元数据 → 逐行映射到对应文档的 metadata 字段,而非作为独立可检索节点
这解释了为什么 system prompt 里特别说:“When asked about file-specific details like the author, creation date, or last modification date, retrieve this information from the document’s metadata if available in the provided context.”
元数据是附着在 node 上作为 metadata dict 传入 LLM context 的,不是通过语义检索得到的。
版本控制的隐式实现:BillingPolicy 文件夹里同时有 late_payment_policy.pdf 和 late_payment_policy_v2.pdf。用户问"最新的逾期政策是什么?"时,语义检索可以同时召回两个文件,而 LLM 可以根据文件名中的 v2 判断哪个更新——这是一种不需要任何额外代码的版本感知,纯靠文件命名规范 + LLM 语义理解实现。
检索与召回引擎 (Retrieval & Reranking)
这是整个项目最核心的部分,值得逐行拆解。
LlamaCloudCompositeRetriever:架构核心
# app.py L87-93
composite_retriever = LlamaCloudCompositeRetriever(
name="Customer Support Retriever",
project_name=LLAMA_CLOUD_PROJECT_NAME,
create_if_not_exists=True,
mode=CompositeRetrievalMode.ROUTING, # ← 关键参数
rerank_top_n=2, # ← 严格截断到2个节点
)
ROUTING vs FULL 模式对比:
| 参数 | FULL 模式 | ROUTING 模式 |
|---|---|---|
| 查询哪些 Index | 全部 | LLM 决定的子集(通常1个) |
| 延迟 | 高(并发查N个Index) | 低(只查1-2个) |
| 召回精度 | 可能混入不相关Index的结果 | 定向精准 |
| 适用场景 | 跨域综合查询 | 意图明确的客服场景 |
ROUTING 模式的本质是:把"多数据源检索"问题转化为**“先做一次意图分类,再做单数据源检索”**的两步问题。
Description-as-Routing-Signal 模式
# app.py L98-113
composite_retriever.add_index(
product_manuals_index,
description="Information source for detailed product features, technical specifications,
troubleshooting steps, and usage guides for various products.",
)
composite_retriever.add_index(
billing_policy_index,
description="Provides information related to pricing, subscriptions, invoices,
payment methods, and refund policies.",
)
# ... 其余两个 index 类似
这段代码的精妙之处:
LlamaCloud 内部的 Router(推测实现如下):
# 伪代码,还原 LlamaCloud ROUTING 模式的内部逻辑
tools = [
{"name": "ProductManuals", "description": "... technical specs, troubleshooting ..."},
{"name": "FAQGeneralInfo", "description": "... common questions, policies ..."},
{"name": "BillingPolicy", "description": "... pricing, invoices, refunds ..."},
{"name": "CompanyIntroSlides","description": "... company overview, leadership ..."},
]
# 用 LLM function calling 选择要查哪个 tool(index)
selected_index = llm.select_tool(query=condensed_question, tools=tools)
# 只查选中的 index
results = selected_index.retrieve(condensed_question)
关键洞察:description 字段就是路由器的"地图标签"。写得越清晰、边界越分明,路由准确率就越高。作者在描述中特意选用了**领域关键词**(troubleshooting、invoices、refund policies、leadership),这些词与用户可能使用的自然语言高度重叠,降低了语义 gap。
Reranking 策略
rerank_top_n=2 # 从查询结果中只保留 top 2 个节点
Why 只要 top 2?
这是一个非常激进的截断策略,背后的工程考量是:
- 减少 LLM context 长度 → 降低 token 成本,减少"答案被淹没"的风险
- 强迫 reranker 做精准筛选 → 把召回质量的压力前置到 reranker,而不是让 LLM 在大量噪声中"自己找"
- 客服场景的特点 → 问题通常有唯一正确答案,top 2 的精确率足够覆盖大多数问题
Reranker 的实现由 LlamaCloud 托管,根据 GitHub topic 标签 cohere-embeddings 推断,底层很可能使用 Cohere Rerank API(cross-encoder 架构,比双塔向量检索精度高得多)。
检索透明度面板
# app.py L188-216:解析 source_nodes,展示给用户
for i, node in enumerate(nodes):
node_block = f"""
[Node {i + 1}]
Index: {metadata.get("retriever_pipeline_name", "N/A")} # ← 是哪个知识库
File: {file_name}{page_info} # ← 具体文件(+页码)
Score: {score} # ← rerank 置信分
"""
这个右侧溯源面板是该项目最有工程价值的 UX 设计:在不需要用户懂 RAG 的情况下,让 QA 工程师可以实时监控**“路由是否正确、文件是否命中、分数是否合理”**。
Agent 编排与防幻觉 (Agent Workflow & Anti-Hallucination)
CondensePlusContextChatEngine:完整执行链路
# app.py L117-133
memory = ChatMemoryBuffer.from_defaults(token_limit=4096)
chat_engine = CondensePlusContextChatEngine.from_defaults(
retriever=composite_retriever,
memory=memory,
system_prompt="""...""",
verbose=True,
)
完整的每轮对话执行链如下:
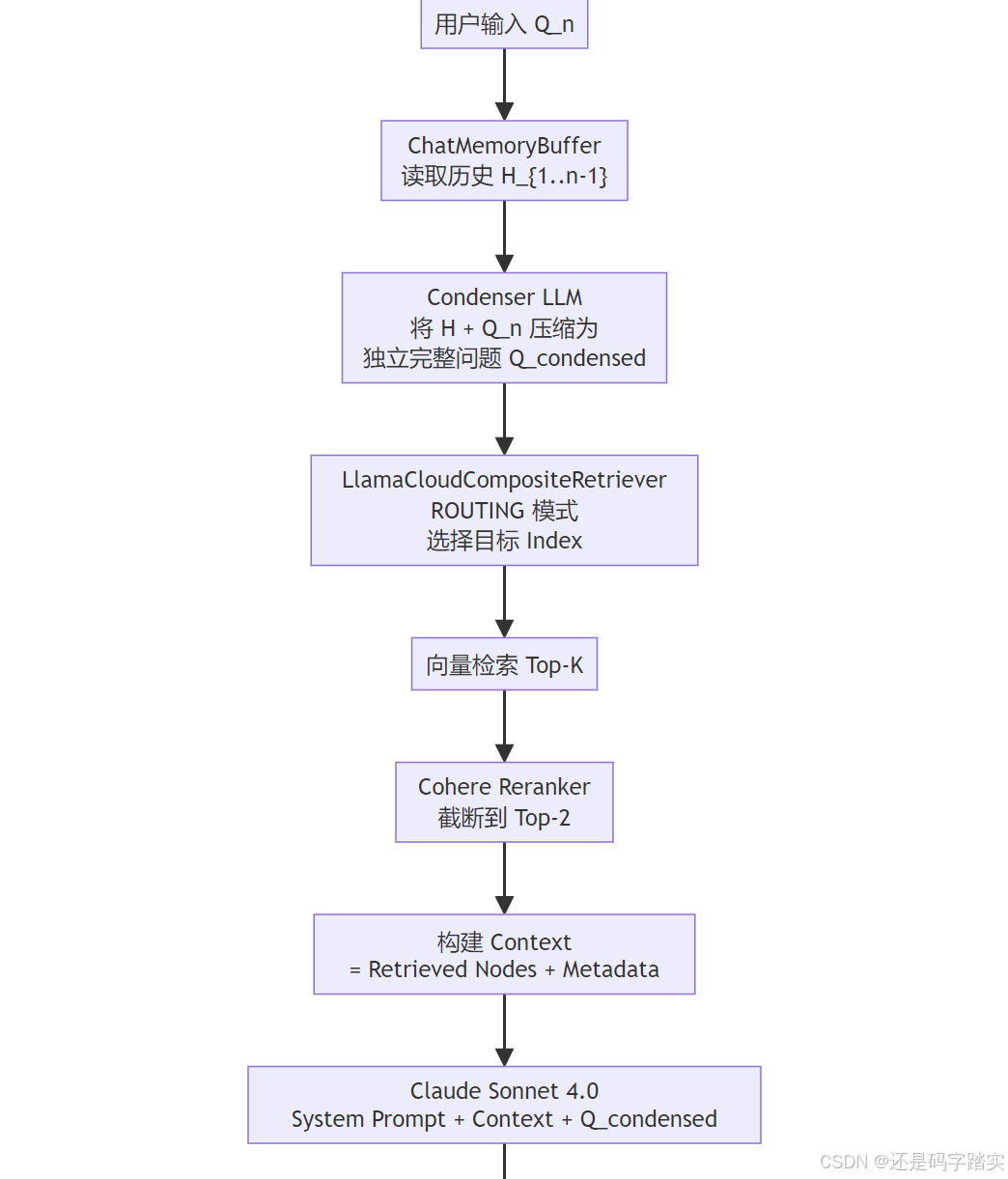
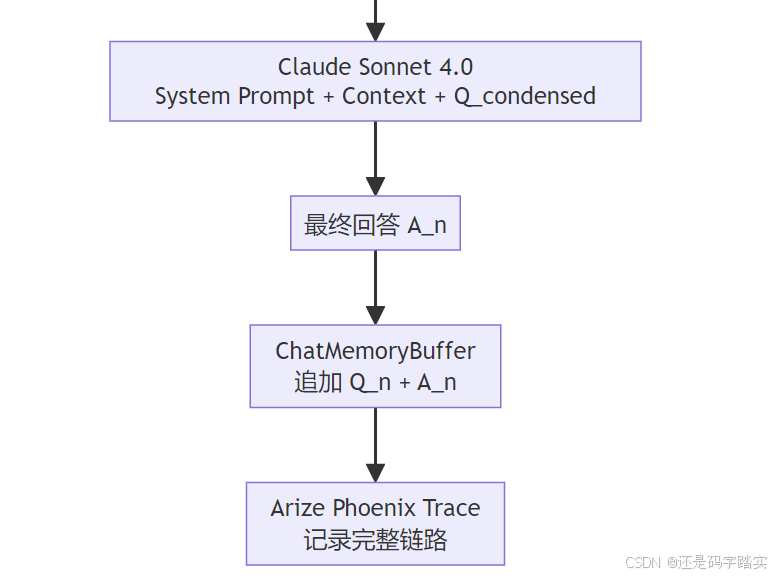
Condense 步骤的核心价值
没有 Condense 时的问题(经典 RAG 的失败模式):
Turn 1: "What is the late payment policy?"
Turn 2: "Does it apply to annual subscriptions?"
↑ 如果直接用这句话去检索,向量数据库根本找不到相关内容
因为"it"没有明确指代,"apply"也过于泛化
有 Condense 后:
Turn 1: "What is the late payment policy?" → 检索 → 回答 → 存入 Memory
Turn 2: 原始问题 "Does it apply to annual subscriptions?"
+ Memory 中的 Turn 1
↓ Condenser LLM 处理
→ "Does the late payment policy apply to annual subscriptions?"
↓ 用这个完整问题去检索
→ 精准命中 BillingPolicy Index
raw_input["message"]** 的提取技巧**:
# app.py L169-176:从 AgentChatResponse 中挖出压缩后的问题
if hasattr(response, "sources") and response.sources is not None:
context_source = response.sources[0]
if (
hasattr(context_source, "raw_input")
and context_source.raw_input is not None
and "message" in context_source.raw_input
):
condensed_question = context_source.raw_input["message"]
这是一段不在文档里、需要读源码才能发现的逆向工程技巧:LlamaIndex 的 AgentChatResponse.sources[0].raw_input["message"] 隐藏了发给 Retriever 的实际 query(即压缩后的问题),作者把它暴露到 UI 上供调试。
防幻觉的多层防御
# 第一层:LLM 温度为 0
Settings.llm = Anthropic(model="claude-sonnet-4-0", temperature=0)
# → 消除随机性,迫使 LLM 输出最高概率(最保守/准确)的 token 序列
# 第二层:System Prompt 的"权威陈述"指令
"""
Provide accurate answers from product manuals, FAQs, and billing policies...
Never refer to or mention your information sources
(e.g., "the manual says", "from the document").
State facts authoritatively.
"""
# → 防止 LLM 使用"the document says..."这类可能引发幻觉的引用模式
# 强迫它用"事实陈述"语气,减少不确定性措辞
# 第三层:Token 限制的 Memory
memory = ChatMemoryBuffer.from_defaults(token_limit=4096)
# → 超出 4096 token 时自动截断早期对话
# 防止过长历史引入噪声,同时控制成本
# 第四层:Retrieval Grounding(本质上是 RAG 的核心价值)
# → LLM 只能基于 retrieved context 回答,无法"凭空创造"
Gradio 两阶段异步模式
# app.py L362-385:两阶段链式事件
submit_event = msg.submit(
fn=initial_submit, # 阶段1: 立即更新UI(无需等LLM)
inputs=[msg, chatbot],
outputs=[chatbot, msg, retriever_output, user_message_state],
queue=False, # ← 不排队,立即执行
).then(
fn=get_agent_response_and_retriever_info, # 阶段2: 调用LLM
inputs=[user_message_state, chatbot],
outputs=[chatbot, retriever_output],
queue=True, # ← 可排队,处理并发请求
)
为什么需要 user_message_state?
# 阶段1 执行 initial_submit 时,msg textbox 被清空了(返回 "")
# 阶段2 需要用原始 message 调用 LLM
# 如果直接用 msg 作为输入,得到的是空字符串!
# 解决方案:用 gr.State 在阶段1和阶段2之间传递原始 message
user_message_state = gr.State(value="")
这是 Gradio 异步编程中的一个经典陷阱,作者用 **gr.State** 完美规避。
Feynman 大白话类比
类比一:ROUTING 模式 = 智能前台接待员
想象一个大公司的前台接待。公司有4个部门:产品部(处理产品问题)、客服部(FAQ)、财务部(账单)、公关部(公司介绍)。
没有 ROUTING 模式(FULL 模式):前台把你的问题同时转给所有4个部门,每个部门都给你回复一封邮件,最后秘书从所有邮件里挑出最相关的2条给你读。效率低,还容易引入不相关部门的"乱答"。
有 ROUTING 模式:前台是个聪明人,听你说"我这个月的账单有问题",直接说"你去找财务部",只派一个部门处理,速度快、答案准。而"聪明"的来源,就是每个部门门口挂的那块牌子上的描述(description 字段)——前台看牌子就知道该敲哪扇门。
类比二:CondensePlusContext = 速记员 + 图书馆员的黄金搭档
假设你在图书馆跟一个图书馆员(RAG 系统)聊天:
你说(第1轮):“我想了解逾期还款政策。”
图书馆员去书架找来了相关章节,给你读了一段。你说(第2轮):“那它对年度订阅用户也适用吗?”
问题来了:你说的"它"和"那",图书馆员根本不知道指什么,如果直接拿"那它对年度订阅用户也适用吗?"去搜索书架,什么都找不到。
CondensePlusContext 的做法:在图书馆员去书架之前,旁边有个速记员(Condenser LLM),他翻看你们之前的对话记录,把你说的话"翻译"成:“逾期还款政策对年度订阅用户是否适用?”——一个完整的、不含指代的独立问题。然后图书馆员拿着这个完整问题去书架,一击即中。
三个可以直接抄作业的工程 Trick
Trick 1:Description-as-Intent-Signal 路由模式
适用场景:任何多知识库、多数据源的企业 RAG 系统。
# 工程精髓:description 是路由的"灵魂",写好它比调参数更重要
# 三条黄金原则:
# 1. 用领域专属词(domain-specific terms),避免通用词
# 2. 明确边界(exclude 比 include 更重要)
# 3. 覆盖用户可能用的口语化表达
composite_retriever.add_index(
billing_index,
description=(
"Provides information related to pricing, subscriptions, invoices, "
"payment methods, and refund policies. "
# ↓ 加上反例,帮助 router 区分边界(可选但效果好)
# "Does NOT cover product usage or company background."
),
)
# 可复用 Pattern:多租户 SaaS 的知识库隔离
# 每个客户/部门 = 一个 LlamaCloudIndex
# 通过 description 精准路由,无需训练分类器
Trick 2:Gradio 两阶段链式事件 + gr.State 传递原始输入
# 适用场景:任何需要"立即反馈 + 后台异步处理"的 Gradio 应用
# 例如:图像生成、文档摘要、代码分析等
user_input_state = gr.State(value="") # 跨阶段传递原始输入
def stage_1_instant_feedback(user_input, history):
"""阶段1:立即更新UI,告知用户正在处理"""
history.append({"role": "user", "content": user_input})
return history, "", "⏳ Processing...", user_input # 清空输入框,保存原始输入到 State
def stage_2_heavy_processing(original_input, history):
"""阶段2:执行耗时操作"""
result = call_llm_or_any_heavy_api(original_input)
history.append({"role": "assistant", "content": result})
return history, "✅ Done: " + result
# 链式绑定
submit_btn.click(
fn=stage_1_instant_feedback,
inputs=[user_input, chatbot],
outputs=[chatbot, user_input, status_box, user_input_state],
queue=False, # 立即执行,不排队
).then(
fn=stage_2_heavy_processing,
inputs=[user_input_state, chatbot],
outputs=[chatbot, status_box],
queue=True, # 排队执行,支持并发
)
Trick 3:从 AgentChatResponse 挖掘 Condensed Question(逆向工程)
# 适用场景:任何使用 CondensePlusContextChatEngine 的项目
# 用于调试、日志记录、用户体验优化
def extract_debug_info(response: AgentChatResponse) -> dict:
"""
从 AgentChatResponse 中提取关键调试信息
这些信息 LlamaIndex 文档几乎没有提及,靠读源码发现
"""
debug_info = {
"condensed_question": "N/A",
"source_nodes": [],
}
# 1. 提取压缩后的独立问题(实际发给 Retriever 的 query)
if hasattr(response, "sources") and response.sources:
context_source = response.sources[0]
if (
hasattr(context_source, "raw_input")
and context_source.raw_input
and "message" in context_source.raw_input
):
debug_info["condensed_question"] = context_source.raw_input["message"]
# 2. 提取每个 retrieved node 的溯源信息
for node in (response.source_nodes or []):
meta = node.metadata or {}
debug_info["source_nodes"].append({
"index_name": meta.get("retriever_pipeline_name"), # 哪个 Index
"file_name": meta.get("file_name"), # 哪个文件
"page": meta.get("page_label"), # 哪页
"score": node.score, # rerank 分数
})
return debug_info
# 用途:
# 1. 在生产环境记录日志,监控路由准确率
# 2. 在开发阶段调试,快速发现"为什么路由到了错误的 Index"
# 3. 作为 UI 透明度面板的数据源(本项目的做法)
完整架构 Mermaid 图
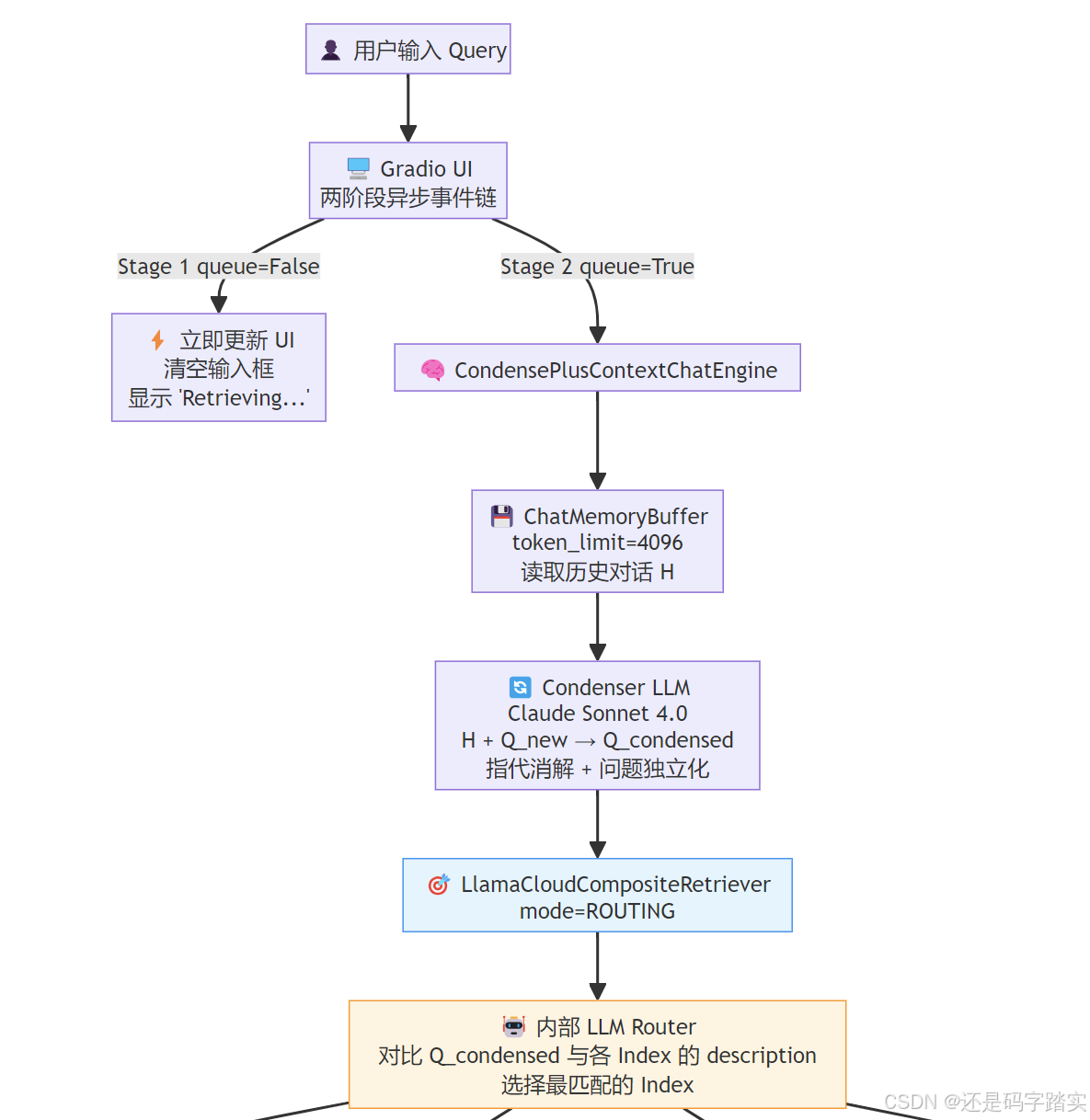
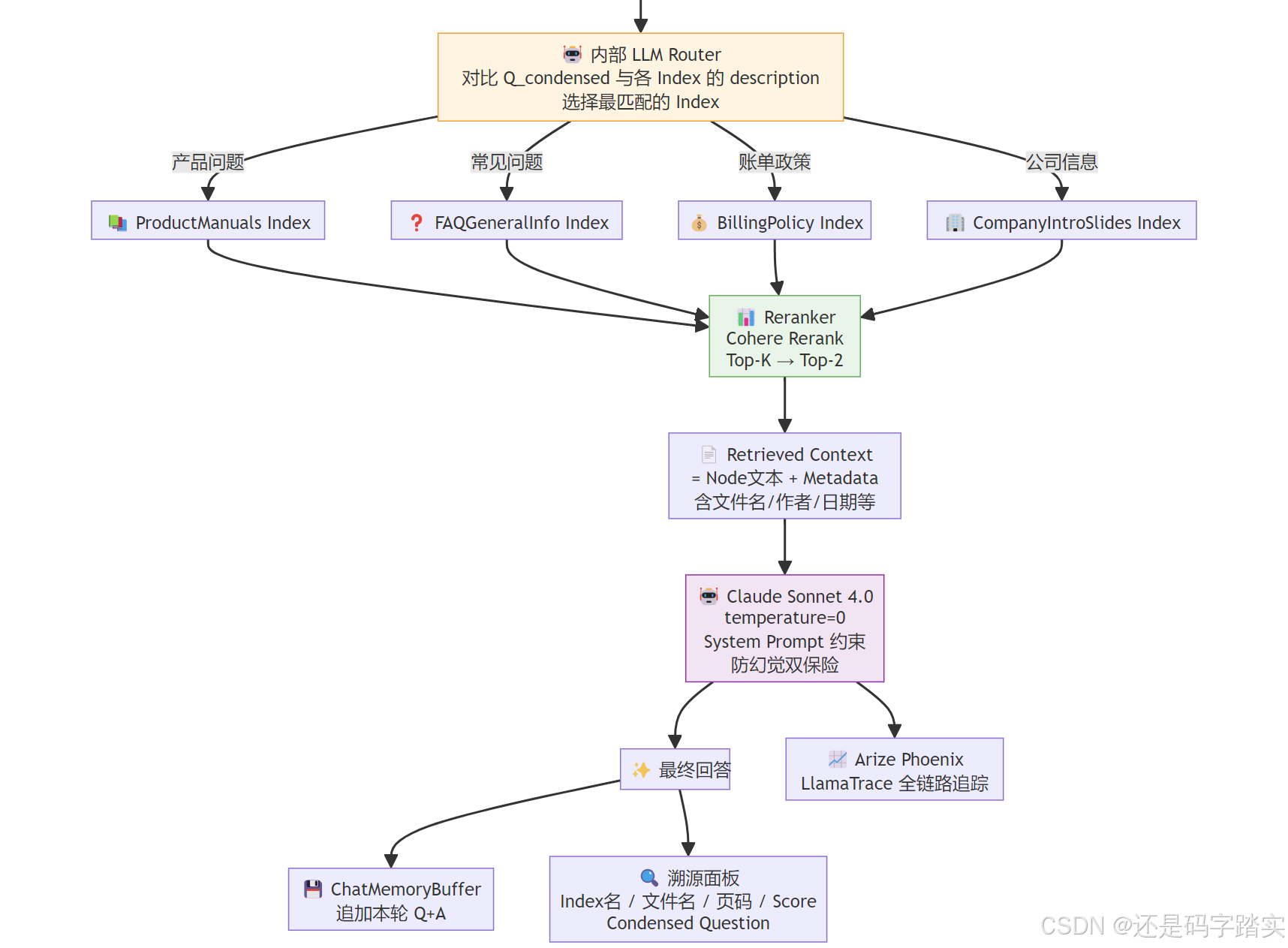
关键局限性与改进方向
| 现有局限 | 根本原因 | 进阶改法 |
|---|---|---|
rerank_top_n=2 过于激进,复杂多文档问题可能漏答 |
追求精度牺牲了召回率 | 动态 top_n:简单问题=2,复杂问题=5,用 query 复杂度分类器判断 |
| ROUTING 模式无法处理跨 Index 的综合型问题 | 每次只路由到1个 Index | 引入 ROUTING+FULL 混合模式,或先路由、再 agent 决定是否追加查询 |
| 没有流式输出(Streaming) | chat_engine.chat() 是同步阻塞调用 |
改用 chat_engine.stream_chat() + Gradio Generator 模式 |
| 无法感知"查不到答案"并优雅降级 | 没有空结果处理逻辑 | 检测 source_nodes 为空时,返回"我暂时找不到相关信息,请联系人工客服" |
| Memory 截断策略粗暴(直接裁掉早期对话) | ChatMemoryBuffer 的默认行为 |
换用 SummaryMemoryBuffer,对早期对话做摘要而非丢弃 |
最后一句硬核总结:这个项目的精髓不是任何单一技术,而是证明了一件事——在正确的抽象层次上组合现有工具,远比自己重造轮子更高效。
LlamaCloud 托管了解析和检索,Claude 处理语言,Gradio 处理 UI,Arize 处理可观测性,作者只需用 425 行 Python 把它们粘合在一起,就实现了一个生产级别可用的智能客服系统。这本身就是一种工程智慧。
参考项目
Agentic RAG chatbot that intelligently routes customer queries to relevant knowledge bases for accurate responses.

欢迎加入 MCP 技术社区!与志同道合者携手前行,一同解锁 MCP 技术的无限可能!
更多推荐



 12
12 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)