Agent + MCP + Skill:构建数仓全链路口径查询
引子:数据口径之殇
数据团队最消耗人力的工作之一是回答一个看似简单的问题-"这个指标是怎么算的?"GMV口径是什么?这个DAU包不包含游客?财务口径的收入和业务口径的收入差在哪?这些问题散落在飞书群聊、文档批注、代码注释、甚至某位同事的脑子里。每次回答都需要人肉溯源-翻 SQL 代码、查调度依赖、对照 PRD 文档、最后口头或飞书告知结果。一个高级数据工程师,一天可能有30%的时间在做这件事。
2025年下半年开始,Agent + MCP(Model Context Protocol)+ Skill 的组合逐渐成熟,让我们看到了一种全新的可能:把数仓的口径查询能力,从"人工服务"变成"Agent 自助服务"。本文不讲概念,只讲落地。我们会从架构设计、MCP Server 实现、Skill 编排、代码示例到上线路径,完整拆解这套方案。
一、问题拆解:口径查询到底难在哪
在动手之前,先理清口径查询的真实复杂度。它不是一个简单的"查字典"操作,而是一个涉及多数据源、多系统、多步推理的链路。一个典型的口径查询请求,比如"电商 GMV 和财务 GMV 为什么对不上",背后需要的信息包括:
-
指标定义:两个 GMV 的业务口径分别是什么,过滤条件有何不同 加工链路:各自的 SQL 逻辑、数据来源表、加工层级(ODS → DWD → DWS → APP)
-
血缘关系:上游表是否一致,在哪一层开始分叉
-
数据质量:上游数据有无异常、是否存在延迟或缺失
-
文档记录:PRD 或数仓设计文档中对这两个口径的说明这些信息分布在至少4-5个不同的系统中-元数据平台、血缘系统、调度平台、数据质量平台、文档中心。传统做法是数据工程师用经验和直觉在这些系统之间人肉串联,效率极低且不可复制。Agent + MCP + Skill 要解决的,就是把这个"人肉串联"过程自动化。
二、整体架构:三层分工
先看全局,再逐层拆解。
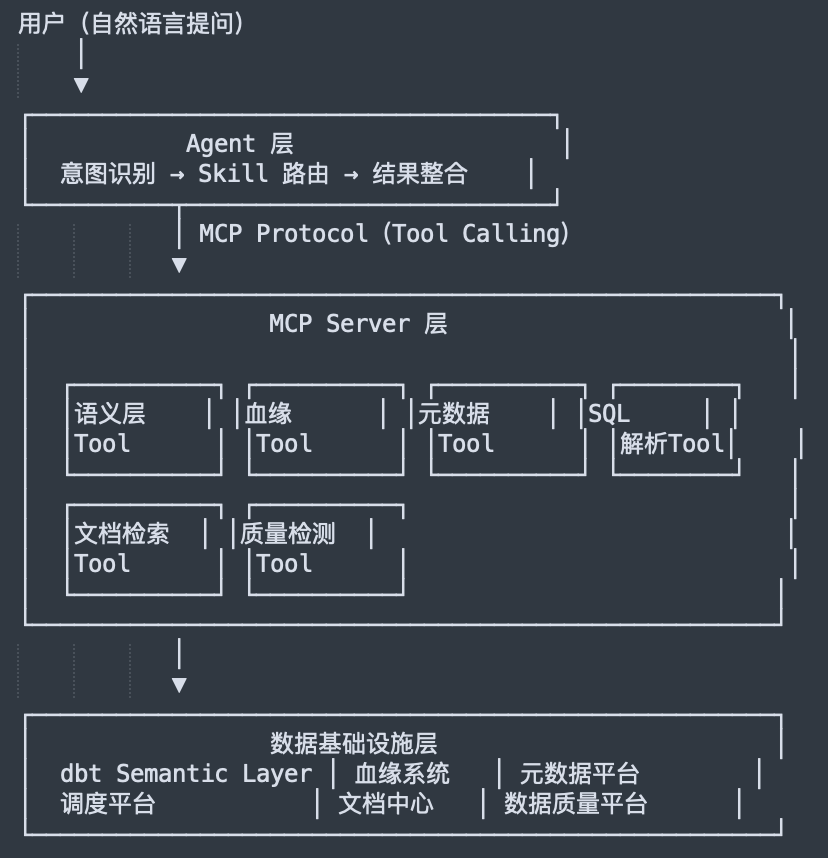
三层各司其职:
-
Agent 层:接收自然语言,识别意图,选择合适的 Skill,编排多个 Tool 调用,整合结果返回给用户
-
MCP Server 层:将数仓基础设施的能力封装为标准化的 MCP Tool,通过 Model Context Protocol 暴露给 Agent
-
数据基础设施层:已有的数仓系统、元数据平台、血缘系统等,不需要改造,只需要被 MCP Server 对接这套架构的核心设计原则是:不动基础设施,只加接入层。 所有已有系统保持原样,MCP Server 作为"翻译层"把它们的能力暴露出来。
3.1 Tool设计总览
|
Tool 名称 |
职责 |
对接系统 |
|---|---|---|
semantic_lookup |
查询指标的业务口径定义 |
dbt Semantic Layer / 指标元数据表 |
lineage_trace |
追溯指标的血缘链路 |
血缘系统 API |
metadata_search |
查询表和字段的元数据 |
元数据平台 API |
sql_explain |
解析 SQL 代码的口径含义 |
调度平台 + LLM |
doc_retrieve |
检索数仓设计文档中的口径描述 |
向量数据库(RAG) |
dq_check |
校验两个指标的口径一致性 |
数据质量平台 API |
3.2 关键 Tool 实现
以 Spring Boot 3.x + Spring AI MCP Starter 技术栈为例,逐个实现核心 Tool。
Tool 1:semantic_lookup - 指标口径查询
这是被调用频率最高的 Tool,90% 的口径问题从这里起步。
@Component
public class SemanticLookupTool {
private final MetricRepository metricRepo;
@Tool(description = "查询数仓指标的业务口径定义,包括计算逻辑、"
+ "数据来源、过滤条件、聚合方式、所属业务域和责任人。"
+ "当用户问'XX指标怎么算''XX口径是什么''XX的定义'时使用此工具。"
+ "支持中文指标名、英文指标名和常用别名。")
public MetricDefinition semanticLookup(
@ToolParam(description = "指标名称,如:GMV、DAU、支付转化率、"
+ "arpu、客单价。支持模糊匹配。")
String metricName) {
// 1. 精确匹配
MetricDefinition metric = metricRepo
.findByNameOrAlias(metricName);
// 2. 精确匹配失败,走模糊搜索
if (metric == null) {
List<MetricDefinition> candidates = metricRepo
.fuzzySearch(metricName, 5);
if (candidates.isEmpty()) {
return MetricDefinition.notFound(metricName);
}
// 返回候选列表,让 Agent 决策
return MetricDefinition.ambiguous(metricName, candidates);
}
return metric;
}
}这里有几个关键设计决策:description 的质量决定 Agent 路由的准确率。
这不是写给人看的文档注释,而是写给 LLM 的"使用说明书"。必须明确列出触发条件("当用户问 XX 时")和输入格式("支持中文/英文/别名"),否则 Agent 会在该调这个 Tool 时调错别的,或者在不该调的时候误调。模糊匹配是必须的。
用户不会精确说出指标的系统名称,他们会说"那个电商的 GMV"而不是"dwd_trade_order_gmv_1d"。支持别名和模糊搜索,是Tool可用性的底线。"不确定"是一种合法返回值。当模糊搜索命中多个候选时,不要替用户做选择-返回候选列表,让Agent追问用户确认。
Tool 2:lineage_trace - 血缘溯源
@Component
public class LineageTraceTool {
private final LineageService lineageService;
@Tool(description = "追溯指标或表的血缘链路,返回从源头到目标的"
+ "完整数据流转路径,包括每一层的表名、加工逻辑摘要和调度任务ID。"
+ "当用户问'数据从哪来''上游是什么表''这个指标经过了哪些加工'时使用。")
public LineageResult lineageTrace(
@ToolParam(description = "指标名称或表名")
String target,
@ToolParam(description = "溯源深度,1=直接上游,"
+ "2=上两层,-1=追溯到源头。默认为3")
int depth) {
// 识别输入类型:指标名 or 表名
if (isMetricName(target)) {
// 先查指标对应的物理表
String tableName = metricRepo
.getPhysicalTable(target);
return lineageService
.traceUpstream(tableName, depth);
}
return lineageService.traceUpstream(target, depth);
}
}depth 参数是精心设计的。 默认深度为 3 层,覆盖 APP → DWS → DWD 的典型链路。设为-1可追溯到 ODS 源头。Agent可以根据用户的问题复杂度自行决定深度-简单问题用1层,"为什么对不上"这类问题用-1。
Tool 3:sql_explain - SQL 口径解析
这是六个 Tool 中技术含量最高的一个-它需要 LLM 来"读懂"SQL 代码。
@Component
public class SqlExplainTool {
private final SchedulerClient schedulerClient;
private final ChatClient chatClient;
@Tool(description = "解析 SQL 代码的业务口径含义。输入一段 SQL 或"
+ "调度任务ID,返回逐层拆解的口径说明,包括每个 CTE/子查询的"
+ "业务含义、过滤条件的业务语义、聚合逻辑的口径描述。"
+ "当用户问'这段SQL在算什么''这个任务的口径是什么'时使用。")
public SqlExplanation sqlExplain(
@ToolParam(description = "SQL 文本或调度任务ID")
String input) {
String sql;
String taskId = null;
// 如果输入是任务ID,先拉取 SQL
if (isTaskId(input)) {
taskId = input;
sql = schedulerClient.getTaskSql(taskId);
} else {
sql = input;
}
// 调用 LLM 做 SQL 语义解析
String explanation = chatClient.prompt()
.system("""
你是一名资深数据仓库工程师。请逐层解析以下 SQL 的业务口径:
1. 列出每个 CTE / 子查询的业务含义
2. 说明 WHERE 条件的业务语义(而非技术语义)
3. 说明聚合逻辑对应的业务口径
4. 给出最终输出的一句话口径总结
不要解释 SQL 语法,只解释业务含义。
""")
.user(sql)
.call()
.content();
return new SqlExplanation(sql, taskId, explanation);
}
}这里用了 LLM-in-the-loop 的设计模式。 SQL 口径解析不是规则引擎能搞定的事-同样是WHERE status = 1,在订单表中意味着"已支付",在退款表中意味着"退款中"。只有LLM能结合上下文做出正确的业务语义解读。
Tool 4:doc_retrieve - 文档 RAG 检索
@Component
public class DocRetrieveTool {
private final VectorStore vectorStore;
@Tool(description = "检索数仓设计文档、PRD、需求文档中与查询相关"
+ "的口径描述。基于语义搜索,不要求精确关键词匹配。"
+ "当其他工具返回的信息不足以回答用户问题时,使用此工具"
+ "补充文档中的口径说明。")
public List<DocFragment> docRetrieve(
@ToolParam(description = "查询内容,用自然语言描述")
String query) {
// 向量检索 + 元数据过滤
SearchRequest request = SearchRequest.builder()
.query(query)
.topK(5)
.similarityThreshold(0.7)
.filterExpression("doc_type in "
+ "['dw_design', 'prd', 'metric_spec']")
.build();
return vectorStore.similaritySearch(request)
.stream()
.map(doc -> new DocFragment(
doc.getMetadata().get("title"),
doc.getMetadata().get("source_url"),
doc.getContent()))
.toList();
}
}这是 RAG 在数仓场景的典型应用。 数仓设计文档、PRD、指标规范文档在入库时做好分块和 Embedding 计算,查询时通过语义检索召回相关片段。similarityThreshold(0.7) 避免召回不相关的噪声。
Tool 5:dq_check - 口径一致性校验
@Component
public class DqCheckTool {
private final MetricRepository metricRepo;
private final QueryEngine queryEngine;
@Tool(description = "对比两个指标的口径差异和数值差异。"
+ "返回口径定义对比、计算逻辑差异点、最近N天的数值偏差、"
+ "以及可能的差异原因分析。"
+ "当用户问'为什么对不上''两个指标差在哪'时使用。")
public DqCheckResult dqCheck(
@ToolParam(description = "指标A的名称")
String metricA,
@ToolParam(description = "指标B的名称")
String metricB) {
MetricDefinition defA = metricRepo
.findByNameOrAlias(metricA);
MetricDefinition defB = metricRepo
.findByNameOrAlias(metricB);
// 1. 口径定义对比
DefinitionDiff defDiff = compareDefinitions(defA, defB);
// 2. 数值差异计算(最近7天)
List<ValueDiff> valueDiffs = queryEngine
.compareValues(defA, defB, 7);
// 3. 差异归因
List<String> rootCauses = analyzeRootCauses(
defDiff, valueDiffs);
return new DqCheckResult(
defA, defB, defDiff, valueDiffs, rootCauses);
}
}3.3 MCP Server配置
将所有 Tool 注册到 Spring AI MCP Server:
# application.yml
spring:
ai:
mcp:
server:
name: dw-metrics-server
version: 1.0.0
type: SYNC
capabilities:
tool: true@Configuration
public class McpServerConfig {
@Bean
public ToolCallbackProvider toolCallbackProvider(
SemanticLookupTool semanticLookup,
LineageTraceTool lineageTrace,
MetadataSearchTool metadataSearch,
SqlExplainTool sqlExplain,
DocRetrieveTool docRetrieve,
DqCheckTool dqCheck) {
return MethodToolCallbackProvider.builder()
.toolObjects(
semanticLookup, lineageTrace,
metadataSearch, sqlExplain,
docRetrieve, dqCheck)
.build();
}
}至此,MCP Server的6个Tool全部就绪。Agent 可以通过MCP协议发现和调用这些Tool。
四、Skill:把多步编排封装成复合能力
单个 MCP Tool 解决的是单点查询-查一个指标的口径、查一张表的血缘。但真实的口径查询往往是多步推理-需要调多个 Tool、做中间判断、按条件分支。这正是Skill的价值所在:Skill=多个Tool 的编排逻辑+领域知识+输出模板。
metrics-trace/
├── SKILL.md # Skill 元信息:触发条件、能力描述、可用 Tool
├── references/
│ ├── metric_naming.md # 指标命名规范(供 Agent 做匹配参考)
│ ├── dw_layers.md # 数仓分层说明(ODS/DWD/DWS/APP 含义)
│ └── common_diffs.md # 常见口径差异模式(历史经验沉淀)
└── scripts/
├── trace.py # 口径溯源主逻辑
└── compare.py # 口径对比逻辑4.2 SKILL.md - Skill的"身份证"
SKILL.md是Agent发现和理解Skill的入口,它告诉Agent"这个Skill能做什么、什么时候该用、怎么用"。
# metrics-trace
## Description
数仓指标口径溯源与对比。当用户提出指标口径相关问题时,
自动编排多个 MCP Tool 完成口径查询、血缘追溯、
差异对比和根因分析,返回结构化的分析报告。
## Trigger Conditions
- 用户询问指标的计算口径、业务定义
- 用户询问两个指标为什么数据对不上
- 用户询问指标的数据来源和加工链路
- 用户需要口径差异的根因分析
## Available MCP Tools
- semantic_lookup: 查询指标口径定义
- lineage_trace: 追溯血缘链路
- metadata_search: 查询表/字段元数据
- sql_explain: 解析 SQL 口径
- doc_retrieve: 检索口径文档
- dq_check: 口径一致性校验
## references/
- metric_naming.md: 指标命名规范,用于模糊匹配时的消歧
- dw_layers.md: 数仓分层架构说明
- common_diffs.md: 常见口径差异模式和排查思路4.3 三个核心 Skill 的编排逻辑
-
Skill 1:单指标口径查询
最简单的场景,用户问"GMV 怎么算"。
执行流程:
1. semantic_lookup("GMV")
├─ 精确命中 → 拿到口径定义
└─ 模糊命中多个 → 追问用户确认
2. lineage_trace(metric, depth=2)
→ 拿到 APP → DWS → DWD 的加工链路
3. doc_retrieve("GMV 口径")
→ 补充 PRD/设计文档中的口径说明
4. 整合输出:口径定义 + 计算公式 + 数据链路 + 文档补充-
Skill 2:口径差异对比(最高频场景)
用户问"电商 GMV 和财务 GMV 为什么对不上"。
执行流程:
1. semantic_lookup("电商GMV") → 口径A
2. semantic_lookup("财务GMV") → 口径B
(步骤1和2可并行调用)
3. dq_check("电商GMV", "财务GMV")
→ 口径差异 + 数值偏差 + 初步归因
4. lineage_trace("电商GMV", depth=-1) → 链路A
5. lineage_trace("财务GMV", depth=-1) → 链路B
(步骤4和5可并行调用)
6. 比对两条链路,定位分叉点
7. sql_explain(分叉节点的SQL)
→ 解析分叉处的具体逻辑差异
8. 整合输出:
- 口径对比表(并排展示定义差异)
- 数值偏差趋势(最近7天)
- 链路分叉点
- 分叉处的 SQL 逻辑差异
- 修复建议这个流程体现了Skill的核心价值:Agent自己很难从零推理出这个 8 步的编排逻辑,但Skill预定义了这个流程,Agent只需要按步骤执行并填充参数。
-
Skill 3:新指标上线审核
数据开发提交新指标前的自动化审核。
执行流程:
1. semantic_lookup(新指标名)
→ 检查是否已存在同名/同义指标
2. metadata_search(物理表)
→ 检查上游表是否存在、字段是否匹配
3. sql_explain(加工SQL)
→ 检查 SQL 逻辑是否符合口径描述
4. dq_check(新指标, 参照指标)
→ 与已有的同类指标做数值合理性校验
5. 对照 references/metric_naming.md
→ 检查命名是否符合规范
6. 输出审核报告:通过/不通过 + 具体问题项4.4 references 目录:沉淀领域知识
references目录是Skill的"知识库"。它不是代码,而是结构化的领域知识文档,供 Agent 在执行 Skill 时参考。以 common_diffs.md 为例:
# 常见口径差异模式
## 模式一:时间窗口差异
- 表现:两个指标数值在月初/月末差异较大,月中差异较小
- 常见原因:一个用自然日,一个用T+1;或时区处理不一致
- 排查方向:检查 WHERE 中的时间过滤条件
## 模式二:状态过滤差异
- 表现:数值有固定比例的偏差(如一个总比另一个大5%)
- 常见原因:订单状态过滤条件不同(已支付 vs 已发货 vs 已签收)
- 排查方向:对比 WHERE 中的 status/state 过滤字段
## 模式三:去重逻辑差异
- 表现:数值级别差异较大,无固定比例
- 常见原因:一个按订单去重,一个按子订单去重;或去重时间窗口不同
- 排查方向:检查 DISTINCT / GROUP BY 的粒度这些模式来自数据团队多年的排障经验。把它们沉淀到Skill的references中,等于让Agent继承了团队的集体智慧。当Agent在执行口径对比时,会参照这些模式来辅助归因,而不是每次都从零推理。
五、端到端示例:从用户提问到结构化回答
把上面的组件串起来,看一个完整的交互流程。用户提问: "电商 GMV 和财务确认收入为什么差了2000万?"Agent 执行过程:
Step 1: 意图识别 → 匹配 Skill: metrics-trace(口径差异对比)
Step 2: 并行调用
├─ semantic_lookup("电商GMV")
│ → 口径:已支付订单金额,含优惠券,不含运费
│ → 物理表:app_trade.dws_trade_gmv_1d
└─ semantic_lookup("财务确认收入")
→ 口径:订单实际结算金额,扣除优惠券和退款
→ 物理表:app_finance.dws_revenue_confirmed_1d
Step 3: dq_check("电商GMV", "财务确认收入")
→ 口径差异:含/不含优惠券、是否扣除退款
→ 最近7天数值偏差:均值约 8%,约 1800-2200 万
Step 4: 并行血缘追溯
├─ lineage_trace("app_trade.dws_trade_gmv_1d", -1)
│ → ODS层 → DWD订单明细 → DWS交易汇总 → APP GMV
└─ lineage_trace("app_finance.dws_revenue_confirmed_1d", -1)
→ ODS层 → DWD订单明细 → DWD退款明细 → DWS财务汇总 → APP收入
Step 5: 链路对比 → 分叉点在 DWS 层
→ 电商 GMV 不关联退款表,财务收入关联了 DWD 退款明细表
Step 6: sql_explain(DWS财务汇总的加工SQL)
→ "该 SQL 在 DWD 订单基础上 LEFT JOIN 退款明细表,
扣除了已完成退款的金额,并排除了优惠券补贴部分"Agent 最终输出:
口径对比
|
电商 GMV |
财务确认收入 |
|
|---|---|---|
|
定义 |
已支付订单金额 |
订单实际结算金额 |
|
优惠券 |
包含 |
扣除 |
|
退款 |
不扣除 |
扣除已完成退款 |
|
运费 |
不包含 |
不包含 |
差异归因两个指标在 DWS 层出现分叉。核心差异有两处:
-
电商 GMV 不扣除退款金额,财务收入扣除了已完成退款(约占 5%)
-
电商 GMV 包含平台优惠券补贴部分,财务收入将其扣除(约占 3%)
两项合计约 8%,与近7天均值偏差一致,2000万差额属正常范围。建议:如需对齐口径,建议在电商 GMV 的基础上扣除
dwd_refund_detail中refund_status=2的退款金额,并排除coupon_type=1(平台券)的补贴部分。这就是 Agent + MCP + Skill 的完整工作流:用户一句话提问,Agent 自动执行 6 步操作,跨 5 个系统检索信息,最终返回一个结构化的、可操作的回答。整个过程对用户来说是一次自然语言对话,对数据工程师来说是解放了 30% 的工时。
七、总结
回到开头,Agent + MCP + Skill 这套方案的核心价值,是把数仓团队多年积累的口径知识,散落在代码、文档、人脑中的隐性知识封装成一套可被Agent调用的标准化服务。
MCP Server把数仓基础设施的能力标准化为Tool,Skill把多步编排逻辑和领域知识固化为可复用的流程,Agent作为前端把自然语言翻译成Tool Calling。
三者各司其职,组合起来覆盖了从"这个指标怎么算"到"两个指标为什么对不上"的完整口径查询链路。这不是取代数据工程师-而是把数据工程师从"人肉查询引擎"中解放出来,让他们去做更有价值的事:架构设计、口径治理、数据标准推动。
Agent不会替你思考,但它可以替你跑腿。
我们今天的分享就到这里啦。欢迎大家持续关注。

最后,欢迎加入我们的知识星球小圈子:
如果这个文章对你有帮助,不要忘记 「在看」 「点赞」 「收藏」 三连啊喂!


欢迎加入 MCP 技术社区!与志同道合者携手前行,一同解锁 MCP 技术的无限可能!
更多推荐
 7
7 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)