亚马逊选品工具替代方案:用 Pangolinfo API 替代 Jungle Scout / Helium 10 的完整技术方案
前言
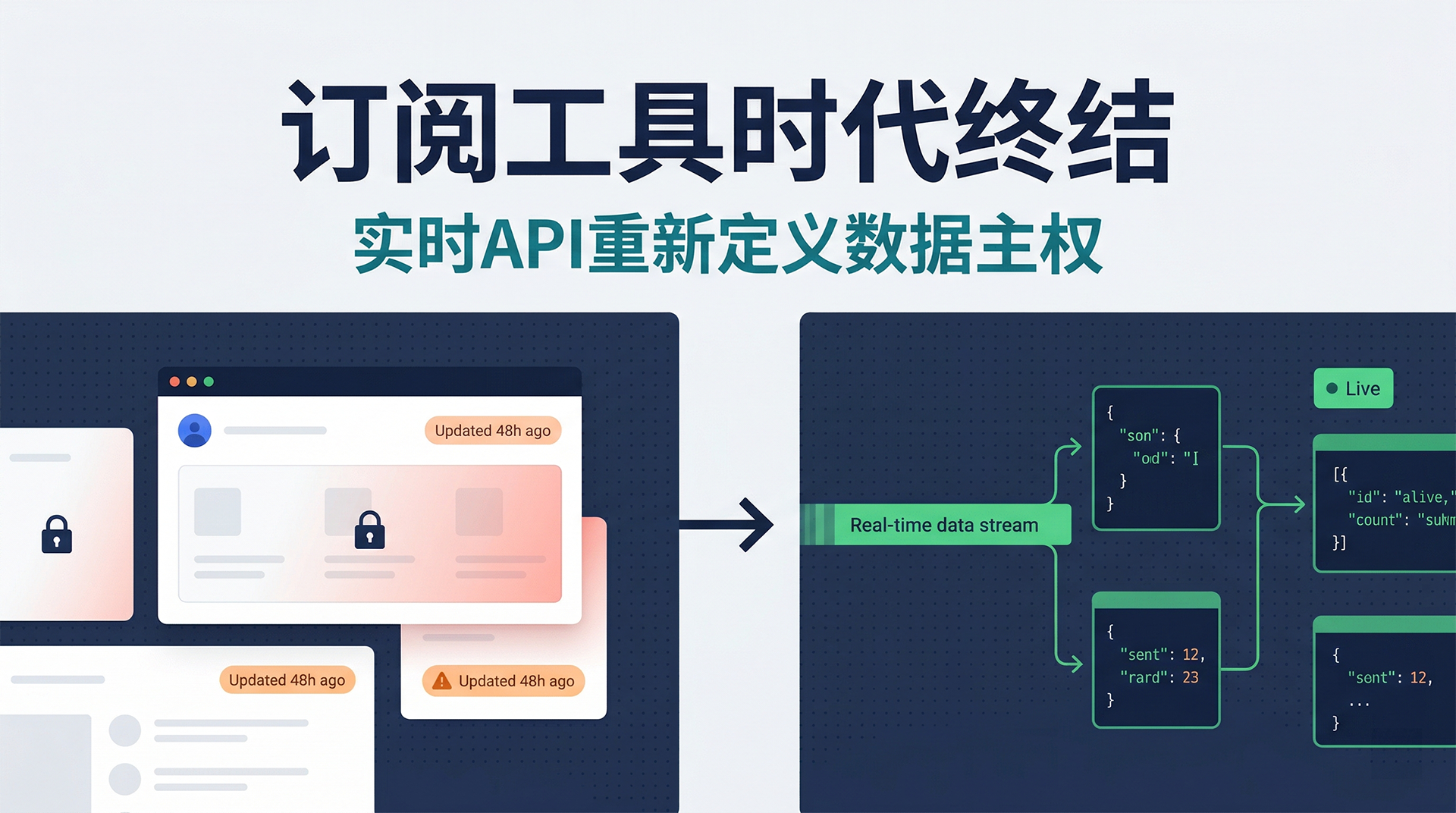
亚马逊跨境电商领域,Jungle Scout、Helium 10 等订阅制工具几乎是标配。但当你需要把亚马逊数据接入自动化系统、AI Agent 工作流,或者构建分钟级竞品监控时,这些工具的封闭数据架构就成了真正的瓶颈。
本文从技术角度深入分析订阅制工具的数据架构局限,并给出基于 Pangolinfo Scrape API 的完整替代方案——包括竞品价格监控系统的完整代码实现、AI 选品 Agent 的接入方式,以及从 SaaS 工具迁移到 API 方案的技术路径。
目录
- 订阅制工具的数据架构分析
- Pangolinfo API 技术规格与核心接口
- 完整代码:竞品价格监控系统
- AI Agent 集成:Scraper Skill 接入方案
- 从订阅工具迁移的技术路径
- 性能优化与最佳实践
- 常见问题与错误处理
1. 订阅制工具的数据架构分析
1.1 数据流对比
订阅制工具(Helium 10 / Jungle Scout 等)的数据链路:
亚马逊公开页面
↓ 工具方爬虫(非实时,周期性)
工具方数据库(存储时间戳滞后 24–72小时)
↓ 指标计算(月销量估算等模型预测)
工具 SaaS 界面(封闭数据,人工操作)
↓ 手动导出
CSV 文件(离线分析)
Pangolinfo API 的数据链路:
亚马逊公开页面
↓ API 调用(实时请求,分钟级)
结构化 JSON 输出(字段完整,无加工误差)
↓ 直接接入
自有数据库 / AI Agent / 飞书多维表格 / 自动化工作流
1.2 关键差异量化
| 维度 | 订阅制工具 | Pangolinfo API |
|---|---|---|
| 数据刷新频率 | 24–72 小时 | 分钟级(每次调用实时采集) |
| 数据维度 | 工具预定义,无法扩展 | 完整页面字段,按需提取 |
| AI Agent 接入 | 不支持 | 原生支持(标准 REST API) |
| SP 广告位采集率 | ~60–75%(估算) | 98%(行业最高) |
| 邮区定向采集 | 不支持 | 支持(zip_code 参数) |
| 定价模式 | 固定月费(无论使用量) | 按调用量计费 |
2. Pangolinfo API 技术规格
2.1 API 基础信息
Base URL: https://api.pangolinfo.com/v2
认证方式: Bearer Token (Authorization: Bearer {API_KEY})
返回格式: application/json
编码: UTF-8
文档地址:https://docs.pangolinfo.com/cn-api-reference/universalApi/universalApi
2.2 主要接口列表
| 接口 | 路径 | 说明 |
|---|---|---|
| 商品详情 | /amazon/product |
BSR / 价格 / 评分 / 功能卖点 / Coupon 状态 |
| 关键词搜索 | /amazon/keyword |
搜索结果 Top N / 排名 ASIN 列表 / 广告位分布 |
| BSR 榜单 | /amazon/bestseller |
指定类目 BSR Top K |
| 新品榜 | /amazon/new-releases |
指定类目新品榜 |
| 评论数据 | /amazon/reviews |
分页评论采集 / 差评关键词 |
| 广告位监控 | /amazon/ads |
SP/SB/SD 广告位 ASIN 分布 |
3. 完整代码:竞品价格监控系统
以下是一个生产可用的 Python 竞品监控系统,支持:
- 并发 ASIN 批量采集
- 历史数据对比告警
- 飞书 Webhook 推送
- 异常重试机制
#!/usr/bin/env python3
"""
Amazon Competitor Price Monitoring System
基于 Pangolinfo Scrape API 的竞品价格实时监控系统
依赖:
pip install requests schedule sqlite3 python-dotenv
"""
import os
import json
import time
import sqlite3
import logging
import requests
import schedule
from datetime import datetime, timedelta
from concurrent.futures import ThreadPoolExecutor, as_completed
from typing import Optional, Dict, List
from dotenv import load_dotenv
load_dotenv()
# ─────────────────────────────────────────
# 配置
# ─────────────────────────────────────────
API_KEY = os.getenv("PANGOLINFO_API_KEY")
BASE_URL = "https://api.pangolinfo.com/v2"
FEISHU_WEBHOOK = os.getenv("FEISHU_WEBHOOK_URL") # 飞书机器人 Webhook URL
MONITOR_ASINS = [
"B0XXXX001",
"B0XXXX002",
"B0XXXX003",
# 添加你的竞品 ASIN...
]
ALERT_THRESHOLDS = {
"price_change_pct": 5.0, # 价格变化 > 5% 触发告警
"bsr_change_positions": 50, # BSR 变化 > 50 位触发告警
}
COLLECTION_INTERVAL_MINUTES = 120 # 每 2 小时采集一次
# ─────────────────────────────────────────
# 日志配置
# ─────────────────────────────────────────
logging.basicConfig(
level=logging.INFO,
format='%(asctime)s [%(levelname)s] %(message)s',
handlers=[
logging.StreamHandler(),
logging.FileHandler('monitor.log', encoding='utf-8')
]
)
logger = logging.getLogger(__name__)
# ─────────────────────────────────────────
# 数据库初始化
# ─────────────────────────────────────────
def init_db(db_path: str = "competitor_monitor.db") -> sqlite3.Connection:
"""初始化 SQLite 数据库,创建历史数据表"""
conn = sqlite3.connect(db_path)
conn.execute("""
CREATE TABLE IF NOT EXISTS price_history (
id INTEGER PRIMARY KEY AUTOINCREMENT,
asin TEXT NOT NULL,
price REAL,
bsr_rank INTEGER,
rating REAL,
review_count INTEGER,
coupon_active BOOLEAN,
coupon_value TEXT,
collected_at TEXT NOT NULL
)
""")
conn.execute("CREATE INDEX IF NOT EXISTS idx_asin_time ON price_history(asin, collected_at)")
conn.commit()
return conn
# ─────────────────────────────────────────
# API 调用层(含重试机制)
# ─────────────────────────────────────────
def fetch_product_data(
asin: str,
marketplace: str = "amazon.com",
zip_code: str = "90001",
max_retries: int = 3
) -> Optional[Dict]:
"""
实时采集亚马逊商品数据
Args:
asin: 商品 ASIN
marketplace: 站点 (amazon.com / amazon.co.uk / amazon.de 等)
zip_code: 买家邮区(影响价格和库存显示)
max_retries: 最大重试次数
Returns:
结构化商品数据字典,失败时返回 None
"""
endpoint = f"{BASE_URL}/amazon/product"
headers = {
"Authorization": f"Bearer {API_KEY}",
"Content-Type": "application/json"
}
payload = {
"asin": asin,
"marketplace": marketplace,
"zip_code": zip_code,
"fields": [
"current_price", "bsr_rank", "bsr_category",
"rating", "review_count", "coupon_status",
"inventory_status", "timestamp"
]
}
for attempt in range(max_retries):
try:
response = requests.post(
endpoint,
json=payload,
headers=headers,
timeout=30
)
response.raise_for_status()
data = response.json()
logger.info(f"✓ {asin}: 价格=${data.get('current_price')}, BSR=#{data.get('bsr_rank')}")
return data
except requests.exceptions.Timeout:
logger.warning(f"⚠ {asin}: 请求超时 (第{attempt+1}次)")
except requests.exceptions.HTTPError as e:
if response.status_code == 429: # Rate limit
wait_time = 2 ** attempt * 5 # 指数退避
logger.warning(f"⚠ {asin}: 触发限流,等待 {wait_time}s")
time.sleep(wait_time)
else:
logger.error(f"✗ {asin}: HTTP错误 {e}")
return None
except Exception as e:
logger.error(f"✗ {asin}: 未知错误 {e}")
return None
def batch_fetch(
asin_list: List[str],
max_workers: int = 5,
request_interval: float = 0.5
) -> Dict[str, Optional[Dict]]:
"""
并发批量采集(含速率控制)
Args:
asin_list: ASIN 列表
max_workers: 并发线程数
request_interval: 请求间隔(秒),控制采集速率
Returns:
{asin: product_data} 字典
"""
results = {}
with ThreadPoolExecutor(max_workers=max_workers) as executor:
future_to_asin = {
executor.submit(fetch_product_data, asin): asin
for asin in asin_list
}
for future in as_completed(future_to_asin):
asin = future_to_asin[future]
try:
results[asin] = future.result()
except Exception as e:
logger.error(f"✗ {asin}: 并发执行异常 {e}")
results[asin] = None
time.sleep(request_interval) # 控制请求频率
return results
# ─────────────────────────────────────────
# 价格变化检测
# ─────────────────────────────────────────
def get_previous_snapshot(conn: sqlite3.Connection, asin: str) -> Optional[Dict]:
"""从数据库获取最近一次历史快照"""
cursor = conn.execute(
"""SELECT price, bsr_rank, coupon_active, coupon_value, collected_at
FROM price_history WHERE asin = ? ORDER BY collected_at DESC LIMIT 1""",
(asin,)
)
row = cursor.fetchone()
if not row:
return None
return {
"price": row[0], "bsr_rank": row[1],
"coupon_active": bool(row[2]), "coupon_value": row[3],
"collected_at": row[4]
}
def detect_alerts(
asin: str,
current: Dict,
previous: Optional[Dict]
) -> List[Dict]:
"""检测是否触发告警条件"""
alerts = []
if not previous:
return alerts # 首次采集,无历史数据对比
curr_price = current.get("current_price", 0)
prev_price = previous.get("price", 0)
# 价格变化告警
if prev_price and curr_price:
change_pct = ((curr_price - prev_price) / prev_price) * 100
if abs(change_pct) >= ALERT_THRESHOLDS["price_change_pct"]:
alerts.append({
"type": "price_change",
"asin": asin,
"prev_price": prev_price,
"curr_price": curr_price,
"change_pct": round(change_pct, 2),
"direction": "↓降价" if change_pct < 0 else "↑涨价",
"curr_bsr": current.get("bsr_rank"),
"severity": "🔴高" if abs(change_pct) >= 15 else "🟡中"
})
# Coupon 开启告警
curr_coupon = current.get("coupon_status", {}).get("is_active", False)
prev_coupon = previous.get("coupon_active", False)
if curr_coupon and not prev_coupon:
alerts.append({
"type": "coupon_activated",
"asin": asin,
"coupon_value": current.get("coupon_status", {}).get("value", "未知"),
"curr_price": curr_price,
"curr_bsr": current.get("bsr_rank"),
"severity": "🟡中"
})
# BSR 大幅变动告警
curr_bsr = current.get("bsr_rank")
prev_bsr = previous.get("bsr_rank")
if curr_bsr and prev_bsr:
bsr_change = prev_bsr - curr_bsr # 正值表示排名上升(数字变小)
if abs(bsr_change) >= ALERT_THRESHOLDS["bsr_change_positions"]:
alerts.append({
"type": "bsr_movement",
"asin": asin,
"prev_bsr": prev_bsr,
"curr_bsr": curr_bsr,
"change": bsr_change,
"direction": "↑ 排名上升" if bsr_change > 0 else "↓ 排名下降",
"severity": "🟡中"
})
return alerts
# ─────────────────────────────────────────
# 飞书告警推送
# ─────────────────────────────────────────
def send_feishu_alert(alerts: List[Dict]):
"""向飞书机器人推送告警卡片"""
if not alerts or not FEISHU_WEBHOOK:
return
alert_texts = []
for alert in alerts:
asin = alert["asin"]
asin_link = f"https://www.amazon.com/dp/{asin}"
if alert["type"] == "price_change":
text = (
f"{alert['severity']} **价格变动** [{asin}]({asin_link})\n"
f"• {alert['direction']}:${alert['prev_price']:.2f} → ${alert['curr_price']:.2f} "
f"({alert['change_pct']:+.1f}%)\n"
f"• 当前 BSR:#{alert.get('curr_bsr', 'N/A')}"
)
elif alert["type"] == "coupon_activated":
text = (
f"{alert['severity']} **Coupon 开启** [{asin}]({asin_link})\n"
f"• 优惠额度:{alert['coupon_value']}\n"
f"• 当前价格:${alert.get('curr_price', 'N/A'):.2f}\n"
f"• 当前 BSR:#{alert.get('curr_bsr', 'N/A')}"
)
elif alert["type"] == "bsr_movement":
text = (
f"{alert['severity']} **BSR 大幅变动** [{asin}]({asin_link})\n"
f"• {alert['direction']}:#{alert['prev_bsr']} → #{alert['curr_bsr']} "
f"(变化 {alert['change']:+d} 位)"
)
else:
text = f"⚠ 未知告警类型:{json.dumps(alert, ensure_ascii=False)}"
alert_texts.append(text)
card_content = {
"msg_type": "interactive",
"card": {
"header": {
"title": {"tag": "plain_text", "content": "🔔 亚马逊竞品动态告警"},
"template": "red"
},
"elements": [
{
"tag": "markdown",
"content": f"**检测时间**:{datetime.now().strftime('%Y-%m-%d %H:%M:%S')}\n"
f"**告警数量**:{len(alerts)} 条\n\n" + "\n\n---\n\n".join(alert_texts)
}
]
}
}
try:
response = requests.post(FEISHU_WEBHOOK, json=card_content, timeout=10)
response.raise_for_status()
logger.info(f"✓ 飞书告警推送成功,共 {len(alerts)} 条")
except Exception as e:
logger.error(f"✗ 飞书告警推送失败:{e}")
# ─────────────────────────────────────────
# 数据持久化
# ─────────────────────────────────────────
def save_snapshot(conn: sqlite3.Connection, asin: str, data: Dict):
"""将采集数据写入数据库"""
coupon = data.get("coupon_status", {})
conn.execute(
"""INSERT INTO price_history
(asin, price, bsr_rank, rating, review_count, coupon_active, coupon_value, collected_at)
VALUES (?, ?, ?, ?, ?, ?, ?, ?)""",
(
asin,
data.get("current_price"),
data.get("bsr_rank"),
data.get("rating"),
data.get("review_count"),
coupon.get("is_active", False),
coupon.get("value"),
datetime.utcnow().isoformat()
)
)
conn.commit()
# ─────────────────────────────────────────
# 主监控循环
# ─────────────────────────────────────────
def run_monitoring_cycle():
"""执行一轮完整的监控采集→对比→告警循环"""
logger.info(f"开始监控采集,共 {len(MONITOR_ASINS)} 个 ASIN")
conn = init_db()
try:
# 并发批量采集当前数据
current_batch = batch_fetch(MONITOR_ASINS, max_workers=5)
all_alerts = []
for asin, current_data in current_batch.items():
if not current_data:
logger.warning(f"⚠ {asin}: 采集失败,跳过告警检测")
continue
# 获取历史快照,检测变化
previous = get_previous_snapshot(conn, asin)
alerts = detect_alerts(asin, current_data, previous)
all_alerts.extend(alerts)
# 持久化当前数据
save_snapshot(conn, asin, current_data)
# 推送告警
if all_alerts:
logger.info(f"检测到 {len(all_alerts)} 条告警,准备推送")
send_feishu_alert(all_alerts)
else:
logger.info("本轮无价格异动,监控正常")
finally:
conn.close()
def main():
"""启动定时监控任务"""
logger.info(f"竞品监控系统启动,采集间隔:{COLLECTION_INTERVAL_MINUTES} 分钟")
# 立即执行一次
run_monitoring_cycle()
# 定时调度
schedule.every(COLLECTION_INTERVAL_MINUTES).minutes.do(run_monitoring_cycle)
while True:
schedule.run_pending()
time.sleep(60)
if __name__ == "__main__":
main()
3.1 运行方式
# 安装依赖
pip install requests schedule python-dotenv
# 配置环境变量
echo "PANGOLINFO_API_KEY=your_api_key_here" >> .env
echo "FEISHU_WEBHOOK_URL=https://open.feishu.cn/open-apis/bot/v2/hook/xxx" >> .env
# 启动监控(后台运行)
nohup python monitor.py > /dev/null 2>&1 &
# 或者使用 Docker:
# docker run -d --env-file .env pangolinfo-monitor:latest
4. AI Agent 集成:Scraper Skill 接入方案
4.1 OpenClaw Skill 接入(无代码路径)
在支持 Skill 商城的 Agent 平台上,可以直接在商城搜索并安装 Pangolinfo Amazon Scraper Skill,无需自行配置 API。
安装完成后,在 Agent 对话中支持以下指令格式:
# 竞品调研
分析关键词 "portable blender" 在 amazon.com 的 Top 20 竞品,
包括:ASIN、价格区间、平均评分、BSR、评论数量。
找出评分低于 4.0 的产品并提取其主要差评主题。
# 价格监控
检查这些 ASIN [B0XX001, B0XX002, B0XX003] 的当前价格和 BSR,
与我昨天给你的数据对比,找出变化超过 5% 的项目。
# 市场机会评估
评估 "cat water fountain" 赛道的入场机会:
当前 Top 30 的价格分布、评分分布、竞争壁垒评分。
输出结构化的进/不进建议。
4.2 自定义 Agent Tool JSON 配置
如果使用不支持 Skill 商城的 Agent 平台(Dify / Coze / AnythingLLM 等),可以手动配置 Tool:
{
"name": "pangolinfo_amazon_product",
"description": "实时采集亚马逊商品详情,包括价格、BSR 排名、评分、评论数量、Coupon 状态、功能卖点。每次调用均为实时数据,不存在延迟缓存。",
"parameters": {
"type": "object",
"properties": {
"asin": {
"type": "string",
"description": "亚马逊商品 ASIN,例如 B09Z8LSMSK"
},
"marketplace": {
"type": "string",
"description": "站点域名,默认 amazon.com",
"enum": ["amazon.com", "amazon.co.uk", "amazon.de", "amazon.co.jp", "amazon.ca"],
"default": "amazon.com"
},
"zip_code": {
"type": "string",
"description": "买家邮编,影响价格和库存显示,默认 90001(洛杉矶)"
}
},
"required": ["asin"]
},
"api_config": {
"method": "POST",
"url": "https://api.pangolinfo.com/v2/amazon/product",
"headers": {
"Authorization": "Bearer {{PANGOLINFO_API_KEY}}",
"Content-Type": "application/json"
}
}
}
5. 从订阅工具迁移的技术路径
5.1 迁移阶段规划
阶段一(第1–2周):数据验证
- 注册 Pangolinfo 控制台,申请免费试用额度
- 选取 10 个你最熟悉的 ASIN,同时用订阅工具和 Pangolinfo API 采集相同数据
- 比较:价格数据是否一致?BSR 哪个更接近亚马逊实时显示值?
- 如果验证通过,进入阶段二
阶段二(第3–4周):并行运行
- 使用上方的监控脚本,开始对核心竞品的 API 监控
- 保留订阅工具订阅,双轨并行
- 记录 API 方案发现的告警事件,评估是否比订阅工具更及时
阶段三(第5–8周):逐步替换
- 订阅工具降级到最低套餐(保留偶发调研用途)
- 高频监控、AI 工作流数据全面切换到 API
- 取消不再使用的高价套餐
5.2 费用测算模板
# 估算你的月度 API 调用成本
MONITORED_ASINS = 30 # 监控的竞品数量
MONITORING_FREQUENCY_HOURS = 4 # 每几小时采集一次
KEYWORD_TRACKING_COUNT = 20 # 追踪的关键词数量
MONTHLY_RESEARCH_ASINS = 100 # 每月新品调研的 ASIN 数量
product_calls_per_month = (
MONITORED_ASINS *
(24 / MONITORING_FREQUENCY_HOURS) * 30
)
keyword_calls_per_month = KEYWORD_TRACKING_COUNT * 30
research_calls_per_month = MONTHLY_RESEARCH_ASINS
total_monthly_calls = (
product_calls_per_month +
keyword_calls_per_month +
research_calls_per_month
)
# 以当前 Pangolinfo 定价区间估算(实际请参考官网)
estimated_monthly_cost_usd = total_monthly_calls * 0.006 # 示例单价
print(f"月度总调用量:{total_monthly_calls:,} 次")
print(f"估算月费:约 ${estimated_monthly_cost_usd:.2f}")
6. 性能优化与最佳实践
6.1 请求速率控制
import time
from functools import wraps
def rate_limited(max_per_second: float):
"""装饰器:控制函数的调用频率"""
min_interval = 1.0 / max_per_second
last_called = [0.0]
def decorator(func):
@wraps(func)
def wrapper(*args, **kwargs):
elapsed = time.time() - last_called[0]
if elapsed < min_interval:
time.sleep(min_interval - elapsed)
last_called[0] = time.time()
return func(*args, **kwargs)
return wrapper
return decorator
@rate_limited(max_per_second=2) # 最高 2 次/秒
def fetch_with_rate_limit(asin: str) -> dict:
return fetch_product_data(asin)
6.2 异步批量采集(高吞吐场景)
import asyncio
import aiohttp
async def async_fetch_product(session, asin: str, api_key: str) -> dict:
"""异步 API 请求,适合大批量采集场景"""
async with session.post(
f"{BASE_URL}/amazon/product",
json={"asin": asin, "marketplace": "amazon.com"},
headers={"Authorization": f"Bearer {api_key}"},
timeout=aiohttp.ClientTimeout(total=30)
) as response:
return {"asin": asin, "data": await response.json()}
async def batch_async_fetch(asin_list: list, api_key: str) -> list:
"""并发批量异步采集"""
async with aiohttp.ClientSession() as session:
tasks = [async_fetch_product(session, asin, api_key) for asin in asin_list]
return await asyncio.gather(*tasks, return_exceptions=True)
# 使用示例:100 个 ASIN 并发采集,通常 30–90 秒内完成
# results = asyncio.run(batch_async_fetch(asins_100, API_KEY))
7. 常见问题与错误处理
Q1: 返回 403 错误
# 检查 API Key 是否正确
# 确保 Bearer Token 格式:Authorization: Bearer pgl_yourkeyhere
# 免费试用额度是否已耗尽(访问控制台确认)
Q2: 部分 ASIN 返回空数据
# 可能原因:
# 1. 商品已下架或被删除
# 2. 该 ASIN 在该站点不存在
# 3. 亚马逊临时限流(重试通常解决)
# 建议:添加健康检查逻辑
def is_valid_data(data: dict) -> bool:
return data and data.get("current_price") is not None
Q3: 价格数据和亚马逊页面显示不一致
# 最常见原因:zip_code 参数影响价格
# 亚马逊对不同邮区显示不同价格,建议固定zip_code参数
# 如果需要多邮区分析:
ZIP_CODES = {"LA": "90001", "NYC": "10001", "CHI": "60601"}
for region, zipcode in ZIP_CODES.items():
data = fetch_product_data(asin, zip_code=zipcode)
print(f"{region}: ${data.get('current_price')}")
总结
从架构角度看,亚马逊选品工具的核心价值应当是数据获取能力的延伸,而不是对数据的控制和封装。Pangolinfo Scrape API 提供了一种更接近数据本质的访问方式——实时、结构化、可编程、可 AI 接入。
对于有技术能力的团队,本文提供的代码框架可以直接作为竞品监控系统的生产基础,按需扩展。如果你是运营背景、没有编程经验,可以先从 Pangolinfo 控制台的无代码配置工具入手,同样可以实现本文描述的核心监控场景。

欢迎加入 MCP 技术社区!与志同道合者携手前行,一同解锁 MCP 技术的无限可能!
更多推荐
 10
10 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)