AI Agent落地的7个工程陷阱:为什么你的Agent总是“demo级别“
模型准确率99%不等于产品可用,demo跑通不等于能上线。
本文基于17个企业级Agent项目的真实复盘,总结出7个最常见的工程陷阱。
前言:62%的Agent项目死在了工程化阶段
2026年Q1,某头部AI咨询机构对127家已部署AI Agent的企业进行了调研,结论令人震惊:
62%的Agent项目停留在"demo级别",无法进入生产环境。
不是因为模型不行。GPT-4o、Claude 3.5、DeepSeek V3——这些模型的能力已经足够强。
失败的原因,几乎都是工程问题。
本文从17个真实项目中提炼出7个最致命的工程陷阱,每个陷阱都附带具体的技术方案和代码示例。
陷阱一:Prompt脆弱性——输入变了,Agent就崩了
问题描述
Demo阶段,你精心设计了一套Prompt,效果完美。
上线后,用户的输入千奇百怪:
- 输入包含特殊字符(emoji、SQL注入、HTML标签)
- 输入超长(用户粘贴了一整篇文章)
- 输入语义模糊("帮我看看那个东西")
- 输入语言混杂(中英文夹杂、方言)
每一种情况都可能让你的Agent给出荒谬的回答。
解决方案:输入预处理管道
核心思路是建立一条输入预处理流水线——每条用户输入在进入Agent之前,先经过5道"安检":
- 注入过滤:识别并拦截"忽略之前的指令"等Prompt注入攻击
- 编码归一化:统一处理全角/半角、繁简体、特殊Unicode字符
- 智能截断:超长输入不是简单截断,而是保留首尾、压缩中间,避免丢失关键信息
- 语言检测:识别输入语言,路由到对应的处理分支
- 意图分类:预判用户意图,为后续Agent决策提供先验信息
这条流水线的设计原则是:任何一道检查失败,都能优雅降级,而不是让Agent给出荒谬回答。
下面是完整的实现代码:
class InputPreprocessor:
"""Agent输入预处理管道"""
def __init__(self, max_length=4096):
self.max_length = max_length
self.sanitizers = [
self._remove_injection,
self._normalize_encoding,
self._truncate,
self._detect_language,
self._classify_intent,
]
def process(self, raw_input: str) -> dict:
"""依次执行所有预处理步骤"""
context = {"raw": raw_input, "cleaned": raw_input}
for sanitizer in self.sanitizers:
context = sanitizer(context)
if context.get("rejected"):
return context
return context
def _remove_injection(self, ctx: dict) -> dict:
"""过滤Prompt注入攻击"""
dangerous_patterns = [
r"ignore previous instructions",
r"system prompt",
r"you are now",
r"忽略之前的指令",
]
text = ctx["cleaned"]
for pattern in dangerous_patterns:
if re.search(pattern, text, re.IGNORECASE):
ctx["rejected"] = True
ctx["reason"] = f"Prompt injection detected: {pattern}"
return ctx
return ctx
def _truncate(self, ctx: dict) -> dict:
"""智能截断:保留首尾,压缩中间"""
text = ctx["cleaned"]
if len(text) > self.max_length:
head = text[:self.max_length // 2]
tail = text[-self.max_length // 4:]
ctx["cleaned"] = f"{head}\n...[内容已截断]...\n{tail}"
ctx["truncated"] = True
return ctx
代码的核心逻辑很清晰:process()方法依次执行所有预处理步骤,任何一步标记rejected就立即返回,不再继续后续处理。这种"管道+熔断"模式,保证了即使输入极其恶劣,系统也不会崩溃。
实际部署后,你会发现生产环境的输入质量远比想象中差:
关键指标
| 指标 | Demo阶段 | 生产环境 |
|---|---|---|
| 输入异常率 | <1% | 15-25% |
| Prompt注入概率 | 0% | 3-5% |
| 超长输入比例 | 0% | 8-12% |
一句话总结:你在Demo里看到的输入,只是真实世界的冰山一角。没有输入预处理,上线就是自杀。
陷阱二:幻觉失控——Agent自信地给出错误答案
问题描述
大模型最大的"feature"也是最大的"bug":它永远不会说"我不知道"。
在企业场景中,一个自信但错误的答案,比没有答案更危险。
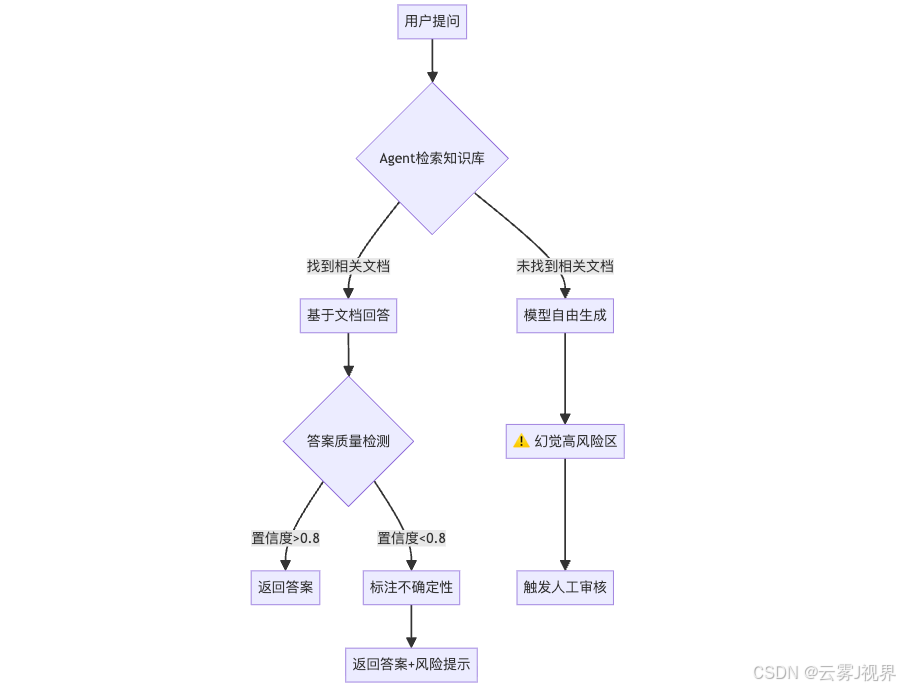
解决方案:多层幻觉检测
单靠一种方法检测幻觉是不够的。我们在实践中总结出"三层检测"策略:
- 接地检测(Grounding):答案中的每一个事实陈述,是否在检索到的文档中有据可查?如果Agent的回答完全脱离了知识库,那基本就是在编。
- 一致性检测(Consistency):答案是否真正回答了用户的问题?有时候模型会"答非所问"——看起来很专业,但完全没切题。
- 置信度检测(Confidence):答案中是否包含过度肯定的表述?比如"一定"、"绝对"、"100%"——在没有充分证据的情况下,这些词本身就是幻觉的信号。
任何一层检测未通过,都会触发风险标记或人工审核流程。
class HallucinationDetector:
"""多层幻觉检测器"""
def __init__(self, retriever, llm):
self.retriever = retriever
self.llm = llm
def check(self, question: str, answer: str, sources: list) -> dict:
"""三层检测"""
result = {
"grounding_score": self._check_grounding(answer, sources),
"consistency_score": self._check_consistency(question, answer),
"confidence_score": self._check_confidence(answer),
}
result["is_hallucination"] = any([
result["grounding_score"] < 0.6,
result["consistency_score"] < 0.7,
result["confidence_score"] < 0.5,
])
return result
def _check_grounding(self, answer: str, sources: list) -> float:
"""检查答案是否有文档支撑"""
if not sources:
return 0.0 # 无来源文档,高幻觉风险
# 计算答案中的关键信息点与来源文档的重叠度
answer_claims = self._extract_claims(answer)
supported_claims = 0
for claim in answer_claims:
for source in sources:
if self._is_supported(claim, source):
supported_claims += 1
break
return supported_claims / max(len(answer_claims), 1)
def _check_consistency(self, question: str, answer: str) -> float:
"""检查答案与问题的一致性"""
# 用LLM判断答案是否真正回答了问题
prompt = f"""
问题:{question}
答案:{answer}
请判断这个答案是否真正回答了问题。
评分0-1,1表示完全回答,0表示完全没回答。
只输出数字。
"""
score = float(self.llm.invoke(prompt).strip())
return score
陷阱三:上下文爆炸——对话越长,Agent越蠢
问题描述
Demo阶段,对话通常只有3-5轮。
生产环境中,用户可能在一个会话里聊50轮以上。
当上下文超过模型的有效注意力窗口,Agent会出现:
- 忘记之前的约定
- 重复回答相同问题
- 回答质量断崖式下降
解决方案:分层上下文管理
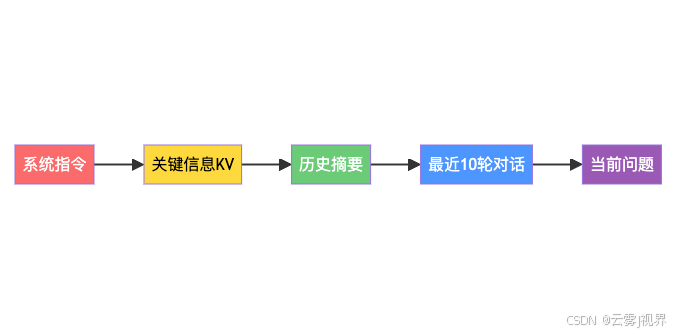
解决上下文爆炸的关键思路是分层存储——不是把所有历史对话一股脑塞进Prompt,而是按重要性分成四层:
- 系统指令层(永不压缩):Agent的角色定义、行为规则,这些必须始终存在
- 关键信息层(KV存储):对话中提取的关键信息,比如用户名字、偏好、已确认的决策——用键值对存储,体积小但信息密度极高
- 历史摘要层(定期压缩):早期对话不保留原文,而是压缩成摘要,保留核心语义
- 最近对话层(滑动窗口):最近10轮对话完整保留,保证当前上下文的连贯性
这种分层架构的好处是:无论对话多长,Prompt的Token消耗始终可控,同时关键信息不会丢失。
class ContextManager:
"""分层上下文管理器"""
def __init__(self, max_tokens=8192):
self.max_tokens = max_tokens
self.system_context = "" # 系统指令(永不压缩)
self.summary_context = "" # 历史摘要(定期更新)
self.recent_context = [] # 最近N轮对话(滑动窗口)
self.working_memory = {} # 关键信息提取(KV存储)
self.window_size = 10 # 滑动窗口大小
def add_turn(self, role: str, content: str):
"""添加新的对话轮次"""
self.recent_context.append({"role": role, "content": content})
self._extract_key_info(content)
# 超过窗口大小时,压缩旧对话
if len(self.recent_context) > self.window_size:
old_turns = self.recent_context[:5]
self.recent_context = self.recent_context[5:]
self._update_summary(old_turns)
def build_prompt(self) -> list:
"""构建最终的Prompt"""
messages = []
# Layer 1: 系统指令(永远在最前面)
messages.append({"role": "system", "content": self.system_context})
# Layer 2: 关键信息摘要
if self.working_memory:
memory_str = "\n".join(
f"- {k}: {v}" for k, v in self.working_memory.items()
)
messages.append({
"role": "system",
"content": f"[关键信息]\n{memory_str}"
})
# Layer 3: 历史摘要
if self.summary_context:
messages.append({
"role": "system",
"content": f"[历史摘要]\n{self.summary_context}"
})
# Layer 4: 最近对话(完整保留)
messages.extend(self.recent_context)
return messages
陷阱四:工具调用失败——Agent的"手"断了
问题描述
Agent的核心能力是调用外部工具(API、数据库、文件系统等)。
Demo阶段,所有工具都在本地,网络延迟为0,接口永远可用。
生产环境中:
- API超时(第三方服务响应慢)
- 接口限流(QPM超限)
- 参数格式变化(API版本升级)
- 权限失效(Token过期)
一个工具调用失败,整个Agent任务链断裂。
解决方案:弹性工具调用框架
工具调用的可靠性问题,本质上是分布式系统的经典问题。我们借鉴了微服务架构中的三个核心模式:
- 重试(Retry):第一次失败不要慌,等一下再试。用指数退避策略(第一次等1秒,第二次等2秒,第三次等4秒),避免雪崩
- 熔断(Circuit Breaker):如果某个工具连续失败5次,直接"熔断"——在接下来60秒内不再调用它,避免无意义的重试浪费时间和资源
- 降级(Fallback):工具不可用时,不是直接报错,而是切换到备用方案。比如外部API挂了,先用缓存数据兜底
这三个模式组合起来,就是一个"弹性工具调用框架"。它的核心原则是:任何单个工具的失败,都不应该导致整个Agent任务链断裂。
class ResilientToolExecutor:
"""弹性工具调用框架"""
def __init__(self):
self.retry_config = {
"max_retries": 3,
"backoff_factor": 2,
"timeout": 30,
}
self.fallback_registry = {}
self.circuit_breakers = {}
async def execute(self, tool_name: str, params: dict) -> dict:
"""执行工具调用(含重试、降级、熔断)"""
# 1. 检查熔断器
if self._is_circuit_open(tool_name):
return self._execute_fallback(tool_name, params)
# 2. 重试执行
for attempt in range(self.retry_config["max_retries"]):
try:
result = await asyncio.wait_for(
self._call_tool(tool_name, params),
timeout=self.retry_config["timeout"]
)
self._record_success(tool_name)
return {"status": "success", "data": result}
except asyncio.TimeoutError:
wait_time = self.retry_config["backoff_factor"] ** attempt
await asyncio.sleep(wait_time)
except Exception as e:
self._record_failure(tool_name, e)
if attempt == self.retry_config["max_retries"] - 1:
return self._execute_fallback(tool_name, params)
def _is_circuit_open(self, tool_name: str) -> bool:
"""熔断器:连续失败5次则熔断60秒"""
cb = self.circuit_breakers.get(tool_name, {})
if cb.get("failures", 0) >= 5:
if time.time() - cb.get("last_failure", 0) < 60:
return True
cb["failures"] = 0 # 半开状态,重置计数
return False
陷阱五:评估缺失——你不知道Agent到底好不好
问题描述
"这个Agent效果怎么样?"
"挺好的。"
"怎么个好法?"
"……就是挺好的。"
没有量化评估体系,你永远不知道Agent是在进步还是退步。
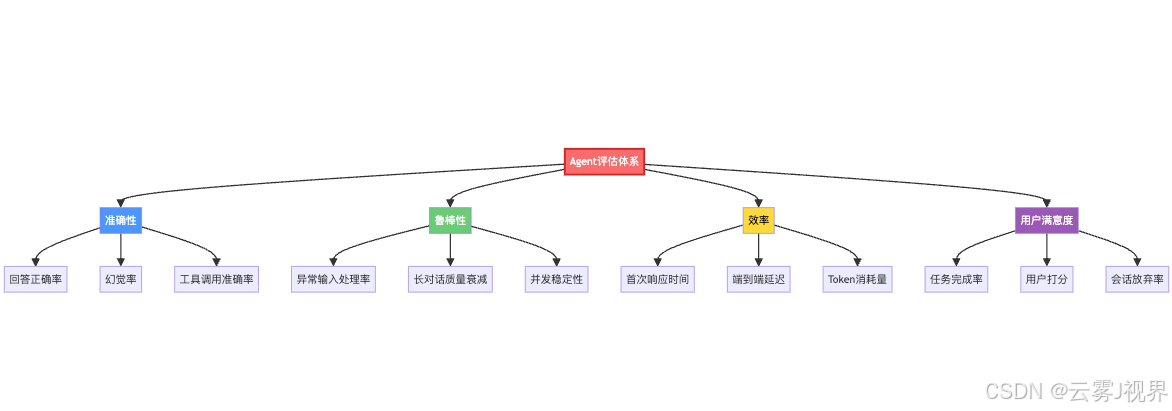
解决方案:四维评估框架
我们在实践中建立了一套"四维评估体系",从准确性、鲁棒性、效率、用户满意度四个维度量化Agent表现。
为什么是这四个维度?因为它们分别回答了四个核心问题:
- 准确性:Agent回答对不对?
- 鲁棒性:Agent在极端条件下还能不能用?
- 效率:Agent快不快、贵不贵?
- 用户满意度:用户愿不愿意继续用?
只看一个维度是不够的——准确率99%但响应要10秒,用户照样不用。
class AgentEvaluator:
"""Agent四维评估器"""
def __init__(self):
self.metrics = {
"accuracy": [],
"robustness": [],
"efficiency": [],
"satisfaction": [],
}
def evaluate_response(self, query, response, ground_truth=None):
"""单次响应评估"""
scores = {}
# 准确性
if ground_truth:
scores["accuracy"] = self._calc_accuracy(response, ground_truth)
# 效率
scores["latency_ms"] = response.metadata.get("latency_ms", 0)
scores["tokens_used"] = response.metadata.get("total_tokens", 0)
# 幻觉检测
scores["hallucination_risk"] = self._detect_hallucination(
query, response.content, response.sources
)
return scores
def generate_report(self, period="daily") -> dict:
"""生成评估报告"""
return {
"period": period,
"total_queries": len(self.metrics["accuracy"]),
"avg_accuracy": np.mean(self.metrics["accuracy"]),
"hallucination_rate": self._calc_hallucination_rate(),
"p95_latency_ms": np.percentile(self.metrics["efficiency"], 95),
"avg_satisfaction": np.mean(self.metrics["satisfaction"]),
"task_completion_rate": self._calc_completion_rate(),
}
陷阱六:成本失控——Token消耗比预期高10倍
问题描述
Demo阶段:每次调用花几分钱,不痛不痒。
生产环境:日均10万次调用,每月Token费用6位数。
成本超标是Agent项目被砍的第二大原因(仅次于效果不达标)。
解决方案:分层模型路由
解决成本问题的核心思路是不要所有任务都用最贵的模型。
想想看:用户问"今天几号?"——你真的需要调用GPT-4o来回答吗?
实际上,80%的用户请求是简单问答或格式化输出,用最便宜的模型就够了;只有15%需要中等模型做多步推理;真正需要最强模型的复杂分析,可能只有5%。
智能模型路由器的作用就是:根据任务复杂度,自动选择最合适的模型。简单任务用便宜模型,复杂任务才用贵的。
这个策略在实际部署中,通常能在效果损失<2%的前提下,降低70-80%的成本。
class ModelRouter:
"""智能模型路由器:根据任务复杂度选择模型"""
MODELS = {
"simple": {"name": "qwen-turbo", "cost_per_1k": 0.001},
"medium": {"name": "qwen-plus", "cost_per_1k": 0.004},
"complex": {"name": "gpt-4o", "cost_per_1k": 0.01},
}
def route(self, query: str, context: dict) -> str:
"""根据任务复杂度路由到不同模型"""
complexity = self._assess_complexity(query, context)
if complexity < 0.3:
return "simple" # 简单问答、格式化输出
elif complexity < 0.7:
return "medium" # 多步推理、知识检索
else:
return "complex" # 复杂分析、创意生成
def _assess_complexity(self, query: str, context: dict) -> float:
"""评估任务复杂度(0-1)"""
score = 0.0
# 查询长度
if len(query) > 500:
score += 0.2
# 是否需要多步推理
if any(kw in query for kw in ["对比", "分析", "为什么", "怎么做"]):
score += 0.3
# 上下文复杂度
if context.get("history_turns", 0) > 10:
score += 0.2
# 是否涉及工具调用
if context.get("requires_tools", False):
score += 0.3
return min(score, 1.0)
| 策略 | 月均成本 | 效果损失 |
|---|---|---|
| 全部用GPT-4o | ¥15万 | 0% |
| 智能路由 | ¥3.5万 | <2% |
| 全部用Qwen-Turbo | ¥0.8万 | 15-20% |
智能路由可以在效果损失<2%的前提下,降低75%的成本。
陷阱七:监控盲区——出了问题三小时后才知道
问题描述
Agent不是传统软件——它的"bug"不会报错,而是悄悄给出错误答案。
没有监控,你根本不知道Agent什么时候"犯病"了。
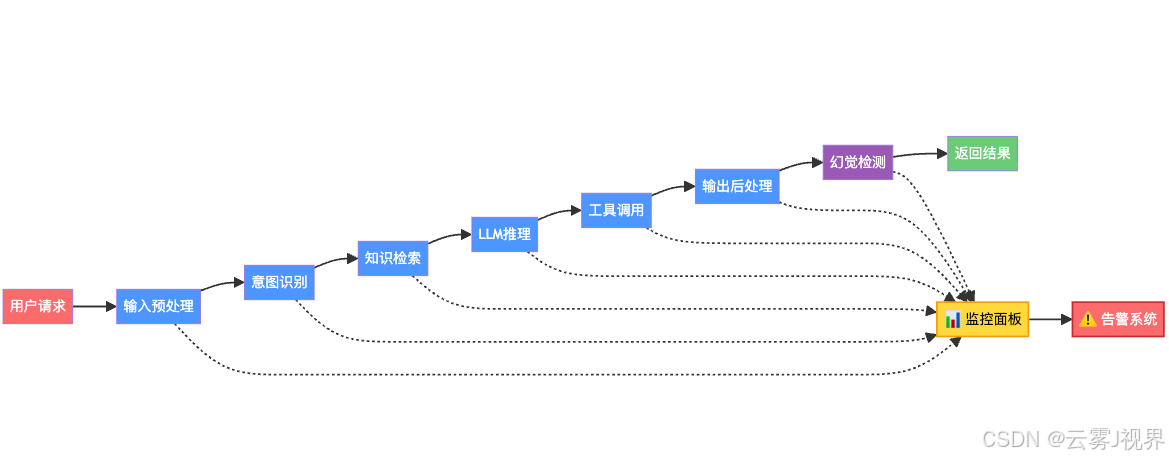
解决方案:全链路可观测性
传统软件的bug会抛异常,你能在日志里找到。但Agent的"bug"不会报错——它只是悄悄给出了一个错误但看起来很合理的答案。
所以Agent的监控不能只看"有没有报错",还要看:
- 幻觉率是不是在上升?(模型可能因为知识库更新出了问题)
- 响应时间是不是在变长?(可能是上下文过长或工具调用卡住了)
- Token消耗是不是异常飙升?(可能是死循环或重复调用)
- 用户会话放弃率是不是在涨?(Agent体验在变差)
我们的做法是在Agent的每个环节都埋点,构建全链路可观测性——从用户输入到最终响应,每一步的耗时、状态、异常都被记录。
class AgentObserver:
"""Agent全链路监控"""
def __init__(self):
self.trace_store = []
self.alert_rules = [
{"metric": "hallucination_rate", "threshold": 0.1, "window": "5min"},
{"metric": "latency_p95", "threshold": 5000, "window": "5min"},
{"metric": "error_rate", "threshold": 0.05, "window": "1min"},
{"metric": "token_cost_hourly", "threshold": 500, "window": "1hour"},
]
def trace(self, request_id: str):
"""记录完整调用链"""
return AgentTrace(
request_id=request_id,
stages=[
"input_preprocess",
"intent_classification",
"knowledge_retrieval",
"llm_inference",
"tool_execution",
"output_postprocess",
"hallucination_check",
]
)
def check_alerts(self):
"""检查告警规则"""
for rule in self.alert_rules:
current_value = self._get_metric(rule["metric"], rule["window"])
if current_value > rule["threshold"]:
self._fire_alert(rule, current_value)
总结:从Demo到生产的Checklist
| 阶段 | 检查项 | 状态 |
|---|---|---|
| 输入层 | 输入预处理管道 | ☐ |
| 输入层 | Prompt注入防护 | ☐ |
| 推理层 | 幻觉检测机制 | ☐ |
| 推理层 | 上下文分层管理 | ☐ |
| 工具层 | 弹性调用框架(重试+熔断+降级) | ☐ |
| 成本层 | 智能模型路由 | ☐ |
| 评估层 | 四维评估体系 | ☐ |
| 运维层 | 全链路可观测性 | ☐ |
| 运维层 | 告警规则配置 | ☐ |
记住一个原则:
Agent的价值不在于Demo有多酷,而在于生产环境能跑多稳。
本文基于17个企业级Agent项目的真实复盘。如果你也在做Agent落地,欢迎在评论区分享你踩过的坑。
参考资料:
- 企业AI Agent落地调研报告(2026 Q1,127家企业)
- LangChain / LlamaIndex 生产环境最佳实践
- OpenAI API Production Best Practices
- 《Building LLM Applications for Production》— Chip Huyen

欢迎加入 MCP 技术社区!与志同道合者携手前行,一同解锁 MCP 技术的无限可能!
更多推荐
 9
9 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)