AI科技应用
内容
-
人工智能发展历史与大模型典型应用
-
智能体基础原理与动手制作
-
AI项目实战与成果展示
-
科技前沿趋势分享
亮点
两大核心模块,带你从理论到实践玩转AI!拆解AI底层逻辑,看懂前沿技术,从0到1完成AI实操,把理论变成看得见的成果。

《AI科技应用》
导语:欢迎来到AI的世界
各位同学,大家好!欢迎来到「科技探索」AI科技应用。非常荣幸能和大家一起,开启一场从理论到实践、从零基础到能独立完成AI实操的科技探索之旅。
在接下来的学习旅程中,我们将共同完成一次从“AI使用者”到“AI创造者”的蜕变。无论你是否有编程基础,无论你是否曾对人工智能感到遥不可及,这门课都将为你拆开技术的“黑箱”,让你亲手点亮AI的第一盏灯。
核心理念:从“数字原住民”到“AI创变者”
本课程不仅仅是一次知识传递,更是一场思维范式的迁移。我们不再满足于仅仅使用AI应用(如聊天、绘画),而是要理解其脉络、掌握其原理、驾驭其创造。我们的终极目标是让你获得一种新的生产力语言——用AI的思维发现问题、拆解问题并解决问题,最终将“AI赋能”从一个流行词,转变为你的内在能力。
总览:两大核心模块,打通AI学习全链路
这门课程的核心优势,就在于“从理论到实践,从基础到进阶”的完整设计,我们将通过两大核心模块,帮大家实现AI认知与实操能力的双重提升,彻底告别“懂理论、不会用”的困境。
第一个核心模块是「AI理论拆解模块」。在这个模块中,我们会跳出复杂的公式和代码,用通俗易懂的语言,拆解AI的底层逻辑——比如AI是如何“思考”的、大模型的核心原理是什么、人工智能从诞生到如今的发展历程中,有哪些关键节点和标志性技术。我们不会追求晦涩的理论深度,而是聚焦“实用化认知”,让大家明白每一项AI技术的核心作用,以及它在我们生活、工作中的应用逻辑。
第二个核心模块是「AI实操落地模块」。这是我们课程的重点,也是最具趣味性的部分。在掌握了基础理论之后,我们会带领大家从0到1完成AI实操,手把手教大家动手制作智能体、开展AI项目实战,最终完成属于自己的AI成果展示。整个实操过程,我们会避开复杂的编程门槛,采用简单易上手的工具和方法,确保零基础的同学也能跟上节奏,每一节课都能掌握一个实操技能,每一个阶段都能获得看得见的进步。
简单来说,这两大模块的逻辑是:先帮大家“看懂AI”,再教大家“用好AI”;先建立系统的认知框架,再通过实操巩固知识、提升能力,让大家真正做到“学完能用、用会能用好”。
学习建议与注意事项
第一,保持好奇心和学习热情。AI是一门不断发展、不断创新的学科,只有保持好奇心,主动探索,才能更好地掌握AI知识和技能。在学习过程中,不要害怕遇到困难,不要因为自己零基础就退缩,每一个知识点、每一个实操步骤,我们都会一起慢慢学习、慢慢掌握。
第二,注重理论与实践结合。这门课程的核心是“实操”,因此,大家在学习理论知识的同时,一定要积极参与实操练习,多动手、多尝试。只有通过实际操作,才能真正理解理论知识,掌握实操技巧,把理论转化为实际成果。
第三,积极提问、主动交流。在学习过程中,遇到不懂的问题、实操过程中遇到困难,一定要及时提出,不要积累问题。老师会全程为大家解答疑问,同时,也鼓励大家相互交流、相互学习,分享自己的学习心得和实操经验,共同进步。
第四,循序渐进、稳步提升。AI学习是一个循序渐进的过程,不要急于求成。我们会按照“理论—实操—进阶”的节奏,一步步推进课程,大家只要跟上课程进度,认真学习每一个知识点、完成每一次实操练习,就一定能有所收获。
心态准备(至关重要):
-
保持“为什么”的好奇:面对AI的神奇表现,多问一句“它可能是怎么做到的?”。这种追问是深入理解的起点。
-
拥抱“动手做”的勇气:实践环节可能会遇到环境报错、效果不佳,这正是学习的核心环节。调试的过程就是知识内化的过程。
-
建立“系统化”的视角:努力将每个知识点串联起来,思考历史、理论、应用、趋势之间的关联,构建你自己的AI认知图谱。
预习任务(选做):
-
注册一个免费的AI Agent搭建平台账号(如Coze、Dify Cloud)。
-
想一想:如果你有一个万能AI助手,你最想让它帮你完成哪个具体任务?把答案写下来,带到课堂上分享。
-
积极体验各类主流AI产品:ChatGPT、Claude、Midjourney、Suno等,并记录下让你惊喜和困惑的时刻,这将是课堂上最好的学习素材。
第一部分:人工智能发展历史——从逻辑到学习的演进脉络
一、AI的“前世今生”:四个关键阶段
人工智能并非突然降临的魔法。它的历史可以追溯到1950年图灵测试的提出。我们将沿着时间轴,回顾AI经历的多个阶段。
1. 萌芽期(1950年前及1950s-1970s):从理论构想到初步实践
人工智能的思想雏形,最早可以追溯到古希腊时期的自动机神话,但真正的科学起点,要从20世纪中叶说起。
关键理论与模型奠基:
-
1943年:神经学家麦卡洛克与数学家皮茨提出了M-P神经元模型,首次用数学公式模拟生物神经元的突触连接,证明了神经网络可以实现与、或、非等基础逻辑运算,这成为了人工智能发展的重要理论基石。
-
1950年:英国数学家艾伦·图灵发表了《计算机器与智能》论文,提出了著名的“图灵测试”。他设想通过一个“模仿游戏”来判断机器是否具备智能:如果在人与机器的对话中,有30%的人类裁判无法区分对话对象是机器还是人类,那么就可以认为这台机器具备了智能。图灵测试的提出,为人工智能研究提供了可操作化的评估标准,推动AI从哲学思辨转向了科学实践。
-
1951年:首台神经网络计算机SNARC问世。
-
1956年:逻辑推理程序LogicTheorist成功证明了《数学原理》中的38条定理,展现了机器在逻辑推理方面的能力。
学科正式诞生:
-
1956年:在美国达特茅斯学院,麦卡锡、明斯基等十位学者召开了夏季研讨会,在这次会议上,“人工智能”(Artificial Intelligence)这一术语被正式提出,标志着人工智能作为一门独立学科的诞生。会议确立了自然语言处理、神经网络、抽象推理等七大研究方向,点燃了AI研究的热潮。
早期实践与挫折:
-
1957年:罗森布拉特发明了感知机(Perceptron),它能够实现简单的图像分类任务。但感知机很快被证明无法处理异或问题(即判断两个输入是否不同)。这一缺陷被放大后,导致神经网络研究陷入了长达二十年的寒冬,大多数研究者转而投向了专家系统的研究。
行为主义机器人:
-
50年代:格雷·沃尔特研制出了机械乌龟,它通过光电管和模拟电路实现了避障、寻光等行为,虽然没有采用计算机控制,但开创了“感知-动作”的智能体研究范式,为后续机器人技术的发展奠定了基础。
第一次AI寒冬:
-
1970s:第一次AI寒冬来临,由于计算能力限制和过高期望,政府资助大幅削减。当时的AI技术受限于算力和数据,很多项目的实际效果远低于预期。比如机器翻译项目,原本期望实现不同语言之间的精准转换,但实际输出的内容常常漏洞百出,引发了人们对AI技术的质疑。
2. 专家系统与知识驱动期(1980s-1990s)
专家系统兴起:
-
1980年:专家系统兴起,费根鲍姆开发的DENDRAL化学分析系统,采用规则库+推理引擎的架构,能够根据质谱数据推断分子结构,在化学领域取得了商业成功。随后,MYCIN医疗诊断系统等一系列专家系统相继出现,它们在特定领域展现出了强大的问题解决能力,但由于依赖人工编写的规则库,泛化能力有限,无法适应复杂多变的现实场景。
算法突破:
-
1986年:反向传播算法(Backpropagation)重新流行,多层神经网络训练成为可能,解决了多层神经网络的训练难题。
-
这一时期特点:依赖人工编写规则,知识表示为核心,系统脆弱且难以扩展。
标志性事件:
-
1997年:IBM深蓝(Deep Blue)击败国际象棋世界冠军卡斯帕罗夫,标志计算机在特定领域超越人类。
3. 机器学习崛起与深度学习爆发期(2000s-2020)
深度学习概念提出:
-
2006年:杰弗里·辛顿提出“深度学习”概念,多层神经网络训练取得突破。
ImageNet革命:
-
2012年:AlexNet在ImageNet图像识别竞赛中以压倒性优势获胜,错误率较传统方法下降了超过10个百分点,深度学习革命爆发。这一事件标志着深度学习时代的正式开启。
生成式AI开端:
-
2014年:生成对抗网络(GAN)提出,开启AI生成内容新纪元。
AlphaGo里程碑:
-
2016年:AlphaGo击败围棋世界冠军李世石,强化学习+深度学习展现强大威力。
Transformer革命:
-
2017年:Transformer架构论文《Attention Is All You Need》发表,彻底革新自然语言处理。
在自然语言处理领域,Transformer架构成为了里程碑式的突破。Transformer摒弃了传统循环神经网络的序列处理方式,采用自注意力机制来捕捉输入序列中各个元素之间的关系,能够更高效地处理长文本数据。基于Transformer架构,BERT、GPT等预训练大模型相继问世,使得机器在语言理解和生成方面的能力达到了前所未有的高度,甚至在某些任务上超越了人类水平。
4. 大模型时代与加速落地期(2020s至今)
GPT系列突破:
-
2020年:GPT-3发布,1750亿参数,展现惊人少样本学习能力。
-
2022年11月:ChatGPT发布,引发全球生成式AI浪潮,月活用户破亿仅用2个月。
-
2023年:GPT-4、Claude、文心一言、通义千问等大模型百花齐放。
-
2024-2025年:多模态大模型、推理模型(如o1)、AI Agent爆发式增长。
国产化大模型发展:
大模型的普及,正在推动AI技术向各个行业深度渗透。与此同时,国产化大模型也迎来了快速发展。国内科技企业和科研机构纷纷推出了自己的大模型产品,如百度的文心一言、阿里的通义千问、腾讯的混元等,这些大模型在中文处理和本土场景适配方面具有独特优势,为我国AI产业的自主发展奠定了基础。
二、从“辨别式”到“生成式”的范式转移
在深入大模型之前,我们需要先厘清人工智能发展的历史脉络。过去几十年,我们处于“辨别式人工智能”时代。那时的AI擅长做选择题,比如人脸识别(判断是不是同一个人)、垃圾邮件过滤(判断是或不是垃圾邮件)。其核心逻辑是基于历史数据进行分类和预测。
然而,随着2017年Transformer架构的提出,我们跨入了“生成式人工智能”时代。AI不再仅仅是做选择题,而是开始做“问答题”和“创作题”。它通过学习海量数据的概率分布,能够生成全新的文本、图像、代码甚至视频。这种从“理解世界”到“创造世界”的跨越,是本次技术革命的核心。
类比说明:
传统AI像一个只会做选择题的考生,而大模型是一个读过整个互联网图书馆、能够自己写作文、画画、甚至编代码的“通才”。
第二部分:大语言模型(LLM)——底层逻辑与典型应用
一、大模型到底是什么?
简单理解:大模型是一个通过海量文本、图像、代码等数据训练出来的巨型神经网络。它的核心能力是“预测下一个最合理的输出”。
大模型,指的是使用大规模数据和强大计算能力训练出来的具有“大参数”的机器学习模型,其核心特征可以概括为以下几点:
-
庞大的参数规模:大模型的参数数量通常在数十亿到数千亿之间,海量的参数使得模型能够学习到数据中复杂的模式和规律。比如GPT-4的参数规模达到了万亿级别,能够处理各种复杂的语言任务。
-
复杂的计算结构:大模型通常采用深度神经网络架构,通过多层网络结构在不同层次上提取特征,实现从简单到复杂的特征表示。例如Transformer架构中的编码器和解码器,通过多层自注意力机制和前馈神经网络,能够捕捉文本中的语义信息和上下文关系。
-
预训练与微调:大模型通常采用预训练+微调的训练策略。在预训练阶段,模型在大规模无标注数据上进行训练,学习通用的语言知识和特征表示;在微调阶段,针对特定任务,使用少量标注数据对模型进行调整,使其适应具体的应用场景。这种训练方式既提高了模型的泛化能力,又降低了特定任务的训练成本。
-
多任务学习能力:大模型能够同时学习并执行多个任务,这得益于其强大的特征表示能力。例如,一个大模型可以同时完成文本分类、情感分析、机器翻译等多种任务,无需为每个任务单独训练模型。
二、大语言模型的工作原理:下一个词的概率游戏
大语言模型之所以能像人一样对话,其本质是一个极其复杂的“接龙游戏”。(保留自预习通识稿)
1. 基础架构:Transformer
-
自注意力机制(Self-Attention):让模型在处理每个词时,都能关注句子中所有其他词,捕捉长距离依赖关系。
-
多头注意力(Multi-Head Attention):并行计算多组注意力,捕捉不同维度的语义关系。
-
位置编码(Positional Encoding):为模型注入序列顺序信息。
-
编码器-解码器结构:BERT(仅编码器,擅长理解)、GPT(仅解码器,擅长生成)、T5(编码器-解码器)。
2. 预训练与微调范式
-
预训练(Pre-training):在海量无标注文本上通过自监督学习训练,学习语言通用表示。模型阅读了互联网上数以万亿计的文本(书籍、网页、代码),学习词汇之间的关联。它并不是在“思考”,而是在计算:给定前面的词,下一个词出现的概率是多少?
-
GPT系列:自回归语言建模,预测下一个token
-
BERT:掩码语言建模,预测被遮盖的词
-
-
微调(Fine-tuning):在特定任务标注数据上调整模型参数。
-
提示学习(Prompt Learning):通过设计提示词引导预训练模型完成特定任务,减少微调成本。
-
上下文学习(In-Context Learning):在提示中提供示例,模型无需更新参数即可学习新任务。
-
人类反馈强化学习:为了让模型更符合人类的价值观和指令,工程师会对模型进行“微调”。这就像教一个博学的孩子懂礼貌、守规矩。
3. 模型规模与涌现能力
-
涌现现象(Emergence):当模型参数达到某一阈值(通常数百亿),突然展现出小模型不具备的能力(如思维链推理、指令遵循)。这是大模型最迷人的特性。
-
Scaling Laws:模型性能随参数规模、数据量、计算量幂律增长。
-
当前主流规模:从7B(70亿)到数百B参数不等。
三、大模型典型应用场景
大模型正在如何改变世界?以下是主要应用领域:
1. 自然语言处理领域
-
智能客服、会议纪要自动生成、法律文书辅助写作
-
机器翻译、摘要生成、情感分析、舆情监测
-
文本分类、信息抽取
2. 代码生成
-
GitHub Copilot帮助程序员自动补全函数,甚至生成整个模块
-
让程序员从“写代码”转变为“审查代码”,大幅降低编程门槛
-
Cursor等代码辅助工具
3. 多模态理解与生成
-
输入一张图片,大模型能描述场景、分析情感、识别异常
-
文生图:DALL-E 3、Midjourney、Stable Diffusion
-
文生视频:Sora、可灵、Runway Gen-3
-
图文理解:视觉问答、图像描述生成
4. 知识检索
-
传统的搜索是给你一堆链接,AI搜索(如Perplexity AI)是直接给你整理好的答案和来源
-
搜索引擎增强
5. 垂直领域专用模型
-
金融:财报分析、风险评估、智能投顾
-
医疗:辅助诊断、医学文献分析、药物发现
-
教育:个性化辅导、自动批改、课程生成
-
法律:合同审查、案例检索、法律咨询
-
教育、医疗、金融等垂直领域:定制化大模型正在成为行业专家的“副驾驶”
本节思考任务:列举你最近一周中使用过的三个AI应用,思考它们背后是否有大模型的影子。
第三部分:智能体(AI Agent)——基础原理与动手制作
一、什么是智能体(Agent)?
如果说大模型是“大脑”,那么智能体就是“大脑+手+脚+感官”。大模型本身只能处理文本输入输出,是被动的。而智能体是具备自主决策与任务执行能力的智能系统,它能够感知环境信息,根据预设的目标和策略做出决策,并执行相应的动作,最终实现与环境的交互和任务的完成。
核心特征:
-
自主性(Autonomy):无需人类持续干预,自主运行
-
反应性(Reactivity):感知环境变化并实时响应
-
主动性(Pro-activeness):主动追求目标,不只是被动等待指令
-
社会性(Social Ability):可与其他Agent或人类协作交互
智能体 vs 传统聊天机器人的区别:(保留自预习课程稿)
| 维度 | 聊天机器人 | 智能体 |
|---|---|---|
| 目标 | 单轮/多轮对话 | 完成一个复杂任务 |
| 工具使用 | 基本没有 | 可调用多种外部工具 |
| 规划能力 | 依赖预设流程 | 动态拆解步骤 |
| 自主性 | 被动响应 | 主动执行并反馈 |
举例说明:
-
聊天机器人:你问“今天天气如何”,它回答“晴天”。
-
智能体:你对它说“明晚想约朋友吃火锅,预算人均150元,帮我订一家离地铁站近的”,它会自动调用天气API、地图API、餐厅预订API,并返回最终方案。
形象的公式:
智能体 = 大模型(大脑) + 记忆 + 规划能力 + 工具使用
二、智能体的核心架构解析
智能体的技术架构通常分为感知层、决策层和执行层三个部分,形成一个“感知-决策-执行”的闭环。具体包含以下四个核心组件:
1. 感知模块(Perception)
-
负责处理多模态数据输入,包括文本、图像、语音等多种形式
-
能够理解环境,通过摄像头、麦克风或API接口获取信息
-
感知层的核心是多模态数据融合技术,需要将不同类型的数据转换为统一的特征表示,以便后续的决策处理
-
例如,一个智能客服智能体,感知层需要将用户的语音输入转换为文本,同时理解文本中的语义信息;一个自动驾驶智能体,感知层需要处理摄像头、雷达等传感器收集到的图像和数据,识别道路、车辆、行人等目标
2. 记忆模块(Memory)
-
不仅有大模型的预训练知识,还有短期记忆(上下文)和长期记忆(向量数据库)
-
能记住用户的偏好和历史操作
-
短期记忆:对话上下文
-
长期记忆:知识库、经验总结(综合自多份)
3. 规划模块(Planning)
-
这是智能体的核心。面对一个复杂指令(如“帮我策划一次去云南的旅行”),它能将其拆解为“查天气”、“订机票”、“找酒店”、“做攻略”等子任务
-
主流规划技术:
-
Chain-of-Thought (CoT,思维链):引导模型逐步推理,“Let‘s think step by step”
-
Tree-of-Thought (ToT,思维树):探索多条推理路径,评估后选择最优解
-
ReAct (Reasoning + Acting):推理与行动交替进行,观察环境反馈调整策略
-
Reflexion:让Agent自我反思错误,从失败中学习改进
-
4. 工具使用/执行模块(Tools/Action)
-
智能体可以调用外部工具,如搜索引擎、计算器、地图API、天气API、数据库等,甚至控制你的电脑操作
-
执行层的核心挑战在于工具API的语义理解、任务分解与子目标规划,以及异常处理与容错机制
三、从单智能体到多智能体协作
初步探索智能体社会的雏形——多个具有不同角色(分析师、执行者、审查员)的智能体如何通过分工、辩论与协作,完成更复杂的任务。这将是AI应用的前沿形态。
四、主流Agent开发框架
1. LangChain
-
最流行的LLM应用开发框架
-
核心概念:Chains(链)、Prompts(提示)、Models(模型)、Memory(记忆)、Agents(代理)
-
提供大量预构建组件,快速搭建复杂应用
2. LangGraph
-
LangChain的扩展,支持构建多Agent工作流
-
基于图结构定义Agent状态流转
-
支持循环、条件分支等复杂逻辑
3. AutoGPT / BabyAGI
-
早期自主Agent代表
-
给定目标后自动分解任务、执行、迭代
-
局限性:容易陷入循环、成本不可控
4. 国产框架
-
扣子(Coze):字节跳动,低代码Agent搭建平台
-
Dify:开源LLM应用开发平台
-
FastGPT:知识库问答系统
五、动手制作一个极简智能体——课堂实战指南
我们将使用无代码/低代码平台(如Coze、Dify或类似的AI Agent搭建工具),不需要编程基础。
步骤一:定义角色与目标
为你的智能体设置一个身份,例如“旅行规划助手”。
明确智能体的核心问题、服务对象和交互方式。我们的旅行规划智能体,核心任务是为用户提供一站式的旅行规划服务,包括搜索机票、预订酒店、生成行程安排等;服务对象是有旅行需求的用户,包括个人旅行者和家庭旅行者;交互方式可以采用文字对话的形式。
步骤二:配置技能
-
添加“联网搜索”工具,用于查找景点信息
-
添加“计算器”工具,用于预算计算
-
添加“知识库”工具,上传一份你常去的餐厅列表
步骤三:编写提示词(Prompt)
示例提示词:
“你是一个贴心的旅行规划助手。当用户提出旅行需求时,请按以下步骤执行:
询问出发地、目的地、天数、人数、预算。
调用搜索工具推荐3个必去景点。
用计算器工具估算总花费。
最终输出一份包含交通、住宿、餐饮建议的旅行计划。”
设计并优化提示词的技巧:我们需要从角色明确、场景具体的提示词开始,不断调整语气、风格,优化提示词的效果。例如,我们可以设计这样的提示词:“你是一名专业的旅行规划师,擅长根据用户的需求制定个性化的旅行方案。请根据用户提供的出发地、目的地、出行时间、预算等信息,为用户生成一份详细的旅行规划,包括机票推荐、酒店预订建议、每日行程安排、美食推荐和预算明细。要求行程安排合理,符合用户的偏好,预算控制在用户指定范围内。”
步骤四:测试与迭代
输入一个真实需求,观察智能体是否按步骤执行。如果出错,就调整提示词或工具配置。在实际使用中,我们可以根据智能体的输出结果,不断调整提示词的细节。比如,如果智能体生成的行程安排过于紧凑,我们可以在提示词中加入“行程安排要劳逸结合,每天的活动量不宜过大”;如果智能体推荐的酒店价格超出了用户预算,我们可以在提示词中明确“酒店推荐的价格区间为XX-XX元/晚”。
步骤五(进阶):添加推理与外部工具调用——代码示例
为了让智能体能够与外部世界交互,我们需要添加推理与外部工具调用的功能。我们可以使用ReAct等框架,让智能体实现“思考+行动”的结合。
环境准备:
python
# 基础依赖
pip install langchain openai langchain-openai
# 可选:向量数据库
pip install chromadb faiss-cpu简单ReAct Agent示例:
python
from langchain.agents import Tool, AgentExecutor, create_react_agent
from langchain_openai import ChatOpenAI
from langchain import hub
# 1. 定义工具
tools = [
Tool(
name="Search",
func=search_function, # 自定义搜索函数
description="用于搜索实时信息"
),
Tool(
name="Calculator",
func=calculator_function,
description="用于数学计算"
)
]
# 2. 加载提示模板
prompt = hub.pull("hwchase17/react")
# 3. 初始化模型
llm = ChatOpenAI(model="gpt-4", temperature=0)
# 4. 创建Agent
agent = create_react_agent(llm, tools, prompt)
# 5. 执行
agent_executor = AgentExecutor(agent=agent, tools=tools, verbose=True)
result = agent_executor.invoke({"input": "查询北京今天天气,并计算25摄氏度的华氏度"})带记忆的Agent(保留自学习稿):
python
from langchain.memory import ConversationBufferMemory
memory = ConversationBufferMemory(memory_key="chat_history")
agent_executor = AgentExecutor(
agent=agent,
tools=tools,
memory=memory,
verbose=True
)
RAG(检索增强生成)Agent(保留自学习稿):
python
# 构建知识库
from langchain.vectorstores import Chroma
from langchain.embeddings import OpenAIEmbeddings
# 文档加载与切分
documents = load_documents() # 加载PDF/网页等
texts = split_documents(documents) # 切分文本块
# 构建向量数据库
vectordb = Chroma.from_documents(texts, OpenAIEmbeddings())
# 检索器作为工具
retriever = vectordb.as_retriever()
tools.append(Tool(
name="KnowledgeBase",
func=retriever.get_relevant_documents,
description="查询公司内部知识库"
))步骤六:处理记忆与上下文
为了让智能体“记得之前的事”,实现连贯的对话和任务处理,我们需要处理记忆与上下文。我们可以将记忆分为“短期记忆”和“长期记忆”。短期记忆主要存储对话的上下文信息,比如用户在之前的对话中提到的出行偏好、预算等;长期记忆则存储用户的历史旅行记录、偏好设置等信息。
我们可以使用嵌入(Embedding)技术来检索上下文。嵌入技术能够将文本、图像等数据转换为向量表示,通过计算向量之间的相似度,快速找到与当前问题相关的上下文信息。例如,当用户询问“推荐一些上海的美食”时,智能体可以通过检索短期记忆,了解用户是否有饮食禁忌(如不吃辣),然后根据这些信息推荐合适的美食。
我们可以使用Pinecone、ChromaDB等向量数据库来存储和检索记忆信息。这些数据库能够高效地处理向量数据,支持快速的相似度查询,为智能体的记忆功能提供支持。
步骤七:部署与测试智能体
完成智能体的开发后,我们需要将其部署到服务器上,让用户能够通过网页、APP等方式访问。我们可以使用FastAPI等API框架来搭建智能体的接口,使用Streamlit、Gradio等工具来开发网页界面。
在部署之前,我们需要对智能体进行充分的测试。我们可以模拟不同的用户场景,输入各种类型的请求,检查智能体的输出是否符合预期。例如,测试用户输入不同的预算、出行时间、偏好,查看智能体生成的旅行方案是否合理;测试用户提出的特殊需求(如需要接送机服务、需要安排宠物寄养),查看智能体是否能够正确处理。
本节动手目标:课堂结束时,你将拥有第一个自己配置的、可对话的AI智能体。
第四部分:AI项目实战方法论——从0到1的落地指南
一、提示词工程:与AI对话的艺术
高质量的输出源于高质量的输入。一个完美的提示词通常包含以下要素:
-
立人设:“你是一位资深的市场营销专家……”
-
给背景:“我们要推出一款针对大学生的低糖饮料……”
-
定目标:“请为我写5条小红书风格的种草文案……”
-
设约束:“语气要活泼,多用Emoji,字数在100字以内。”
-
举例子:(可选)提供一两个范例,让AI模仿风格。
二、项目导向学习模式(“迷你黑客松”)
本模块采用“迷你黑客松”形式。你将分组(或独立)完成一个从0到1的AI小项目。
项目选题方向建议(综合自多份)
-
智能办公助手:自动生成周报、邮件智能起草、日程智能安排、会议纪要自动生成。技术栈:LLM + RAG + 日历API。亮点:对接企业微信/钉钉,实现工作流自动化。
-
个性化学习辅导Agent:根据学生水平定制学习计划、自动出题、错题分析。技术栈:LLM + 知识图谱 + 学习数据分析。亮点:自适应难度调整,千人千面。
-
电商智能客服:7×24小时回答咨询、推荐商品、处理售后。技术栈:LLM + 产品知识库 + 订单系统API。亮点:多轮对话理解意图,自动转人工。
-
内容创作助手:短视频脚本生成、配图建议、标题优化。技术栈:LLM + 文生图API + 数据分析。亮点:一键生成完整内容方案。
-
数据分析Agent:自然语言查询数据、自动生成图表、洞察报告。技术栈:LLM + SQL生成 + 可视化库。亮点:零代码数据分析。
-
一个为古诗词配图的创意画板
-
一个能够解释专业名词的个性化学习助教
-
一个根据心情推荐音乐或电影的娱乐智能体
三、典型项目开发流程
Phase 1:需求分析(1-2天)
-
明确目标用户和使用场景
-
梳理核心功能清单(MVP)
-
评估技术可行性与资源需求
-
你想解决什么具体问题?为谁服务?
Phase 2:技术选型(1天)
-
模型选择:GPT-4/Claude/国产大模型(考虑成本、中文效果、合规性)
-
框架选择:LangChain/扣子/Dify
-
基础设施:云服务、向量数据库、API网关
Phase 3:原型搭建(60分钟)
-
在平台上配置智能体或调用API
-
搭建基础架构
-
实现核心功能模块
-
集成外部工具与API
Phase 4:测试与优化(2-3天)
-
输入5个以上测试用例,记录失败场景并改进
-
提示词工程优化
-
边界case处理
-
性能与成本优化
Phase 5:准备展示(30分钟)
-
制作1-2页演示文稿,录屏或准备现场演示
-
准备答辩材料
四、项目实战全流程拆解——以“AI辅助撰写行业分析报告”为例
第一步:需求分析
明确报告的主题、受众、核心观点。
第二步:信息搜集
利用联网型AI搜索最新的行业数据、竞品动态、政策导向。
第三步:大纲构建
让AI生成报告大纲,并人工进行逻辑修正。
第四步:分块写作
不要试图让AI一次写完。按章节(如“市场现状”、“未来趋势”)逐一生成内容。
第五步:润色与图表
让AI优化语言风格,并使用AI工具(如Gamma)生成PPT演示文稿。
五、成果展示技巧
1. 演示结构
-
痛点引入:用真实场景说明为什么要做这个项目。不要只讲“我做了什么”,更要讲“用户遇到了什么痛点,我是如何用AI解决的”。
-
方案展示:系统架构图 + 核心流程演示
-
亮点突出:技术创新点、用户体验优化
-
数据支撑:准确率、响应速度、用户反馈
-
未来规划:迭代方向、商业化可能
-
演示时尽量真实运行,允许出现小bug,重点是展示你的调试思路
2. 成果展示的形式与方法
-
演示视频:制作一个演示视频,展示项目的功能和使用流程。视频可以包括系统的界面展示、实际操作演示、效果对比等内容,让观众直观地了解项目的成果。
-
PPT报告:制作一份详细的PPT报告,包括项目背景、需求分析、技术方案、成果展示、应用效果、未来规划等内容。PPT要简洁明了,重点突出,使用图表、数据等方式增强说服力。
-
现场演示:在会议、展会等场合进行现场演示,与观众进行互动,解答观众的问题。现场演示能够让观众更深入地了解项目的功能和优势,增强项目的影响力。
-
案例分析报告:撰写一份案例分析报告,详细介绍项目的实施过程、遇到的问题、解决方案以及最终的成果。案例分析报告可以作为项目的文档资料,也可以用于行业交流和分享。
3. 技术文档要点
-
项目背景与目标
-
系统架构设计图
-
技术栈与依赖说明
-
核心算法/提示词设计
-
测试用例与结果
-
部署运维指南
六、常见陷阱与避坑指南
-
幻觉问题:AI会一本正经地胡说八道。大模型可能自信地给出错误答案,对于事实性数据(如财报数字、法律条文),必须进行人工核查,你需要学会验证。
-
上下文限制:AI的记忆是有限的。在长对话中,它可能会忘记开头的指令。关键信息需要适时重申。
-
数据隐私:在使用公共AI平台时,切勿上传公司的机密数据或个人敏感信息。
-
偏见与公平:AI可能继承训练数据中的偏见,批判性使用至关重要。
七、AI项目实战案例:基于大模型的智能客服系统开发
项目背景与需求分析
在当今的商业环境中,客户服务的效率和质量直接影响着企业的竞争力。传统的客服模式需要大量的人工客服人员,不仅成本高,而且在高峰期容易出现等待时间长、回复不及时等问题。基于大模型的智能客服系统,能够24小时不间断地为客户提供服务,快速响应客户的咨询,提高客户满意度,同时降低企业的运营成本。
项目功能需求
我们的项目目标是开发一个智能客服系统,能够处理用户的常见咨询,如产品介绍、订单查询、售后问题等。系统需要具备以下功能:
-
自然语言理解:能够理解用户的自然语言提问,准确识别用户的意图
-
智能回复:根据用户的问题,提供准确、专业的回答,对于复杂问题能够转接人工客服
-
多渠道支持:支持网页、APP、微信公众号等多种渠道的接入
-
学习与优化:能够从与用户的交互中学习,不断提升回答的准确性和质量
项目开发流程
数据收集与预处理:首先,我们需要收集大量的客服对话数据,包括历史的客服记录、常见问题与解答等。然后,对数据进行预处理,包括清洗数据(去除重复、无效的数据)、标注数据(标注用户的意图和对应的回答)、分词等,为模型的训练做准备。
模型选择与微调:我们可以选择一个预训练的大模型(如GPT-3.5、文心一言等)作为基础模型,然后使用标注好的客服对话数据对模型进行微调。微调的过程中,我们需要调整模型的参数,让模型适应客服对话的场景,提高模型在客服领域的语言理解和生成能力。
系统架构设计:智能客服系统的架构通常包括用户接口层、意图识别层、回答生成层、知识库层和人工客服转接层。用户接口层负责接收用户的提问;意图识别层负责识别用户的意图;回答生成层根据用户的意图和知识库中的信息生成回答;知识库层存储常见问题与解答、产品信息等;人工客服转接层负责将复杂问题转接给人工客服。
系统开发与集成:我们使用Python、FastAPI等技术开发系统的后端接口,使用Vue.js、React等技术开发前端界面。同时,将大模型集成到系统中,实现自然语言理解和智能回复的功能。此外,我们还需要将系统与企业的订单系统、产品数据库等进行对接,实现订单查询、产品介绍等功能。
测试与优化:在系统开发完成后,我们需要进行充分的测试,包括功能测试、性能测试、用户体验测试等。根据测试结果,对系统进行优化,如调整模型的参数、优化回答的内容、提升系统的响应速度等。
项目成果展示
经过一段时间的开发和优化,我们的智能客服系统已经能够稳定运行。系统能够准确理解用户的提问,提供专业的回答。例如,当用户询问“你们的产品支持7天无理由退货吗?”,系统会回答“是的,我们的产品支持7天无理由退货。如果您需要退货,请在收到产品后的7天内联系我们的客服人员,提供订单号和退货原因,我们会为您办理退货手续。”
在实际应用中,智能客服系统已经为企业节省了大量的人力成本,客户的等待时间从原来的平均5分钟缩短到了10秒以内,客户满意度提升了30%。同时,系统还能够收集用户的常见问题,为企业的产品优化和服务改进提供数据支持。
成果展示的核心要素
在展示AI项目成果时,我们需要突出以下几个核心要素:
-
问题解决能力:说明项目解决了什么实际问题,带来了哪些价值
-
技术创新性:介绍项目中采用的新技术、新方法,以及这些技术如何提升了项目的性能
-
实际应用效果:用数据和案例来说明项目的实际应用效果
-
可扩展性与未来规划:说明项目的可扩展性,以及未来的发展规划
第五部分:科技前沿趋势分享
一、2024-2025年AI关键趋势
1. 多模态是下一个主战场
单一文本模型正在被“能看、能听、能说、能画”的多模态模型取代。例如GPT-4o、Gemini、Claude 3等已经实现实时图像-语音-文本混合理解。未来AI将像人类一样自然地融合多种信息。多模态意味着AI能像人类一样,通过看、听、说来理解世界。未来的AI不再局限于文字。文本生成视频、图片生成3D模型、语音克隆等技术正在爆发。
多模态融合技术的深化:目前的大模型已经能够处理文本、图像、语音等多种模态的数据,但在模态间的语义对齐、跨模态推理等方面还有待提升。未来的大模型将实现更加深入的多模态融合,能够更好地理解和处理复杂的多模态信息。例如,一个AI系统能够根据用户提供的文字描述和图片,生成与之匹配的视频;或者根据一段语音,生成对应的文字描述和图像。
2. AI Agent将重塑软件形态
业内预测:未来不再有“App”,而是“Agent”。你只需要告诉AI你的目标,它会自动调用各种服务。软件从“用户操作界面”演变为“AI执行任务”。从单Agent到多Agent协作系统,自主执行复杂任务(如Manus、Devin),与操作系统、浏览器深度集成。
3. 端侧AI与隐私保护
大模型正在从云端走向手机、PC甚至嵌入式设备(如高通、苹果的端侧模型)。好处:无需上传数据,响应更快,隐私更强。你的下一部手机将内置个人AI助理。模型压缩技术:量化、剪枝、蒸馏。手机、PC本地运行大模型,隐私保护与低延迟优势。
随着AI技术的普及,越来越多的应用场景需要在边缘设备(如手机、智能家居设备、工业传感器等)上运行AI模型。大模型虽然性能强大,但对计算资源和内存的要求较高,不适合在边缘设备上运行。未来,小模型与边缘计算的结合将成为趋势。小模型具有体积小、计算量低、响应速度快等优点,能够在边缘设备上高效运行。同时,边缘计算技术能够实现数据的本地处理,提高数据的安全性和隐私性。
4. 推理能力增强
OpenAI o1/o3系列:强化学习+思维链,数学、编程、科学推理大幅提升。DeepSeek-R1:开源推理模型,低成本高性能。趋势:从“快思考”到“慢思考”,解决复杂问题。
5. AI for Science
AlphaFold3:蛋白质结构预测。材料发现、药物设计、气候模拟。科学研究范式变革。AI技术正在深刻改变科学研究的方式。在生物医学领域,AI可以用于药物研发、基因测序分析、疾病预测等;在物理学领域,AI可以用于模拟复杂的物理现象、发现新的物理规律;在天文学领域,AI可以用于分析天文数据、发现新的天体。未来,AI将与更多的学科领域进行深度融合,推动科学研究的突破和创新。
6. 具身智能
将大模型的大脑装入机器人的身体。未来的机器人不再是只会重复动作的机械臂,而是能听懂自然语言指令、在复杂环境中自主行动的助手(如特斯拉的Optimus)。
二、中国AI发展特色
国产大模型进展:
-
百度文心一言:最早发布,持续迭代
-
阿里通义千问:开源生态活跃,Qwen系列全球受欢迎
-
字节豆包:C端应用创新,语音交互领先
-
DeepSeek:技术硬核,成本极低,全球开源社区影响力大
-
智谱GLM:学术背景深厚,Agent能力突出
应用创新优势:
-
庞大用户基数推动场景创新
-
电商、短视频、社交领域AI应用全球领先
-
制造业AI质检、农业AI监测等实体经济融合
政策与治理:
-
《生成式人工智能服务管理暂行办法》规范行业发展
-
强调数据安全、算法备案、内容合规
-
算力基础设施建设加速
三、AI伦理、安全与人的定位
随着AI技术的广泛应用,人工智能的伦理与安全问题越来越受到关注。
-
版权争议:AI生成的画作版权归谁?训练数据是否侵犯了原作者权益?
-
就业影响:重复性、规则性的工作将被替代,但具备创造力、同理心和复杂决策能力的工作将更加珍贵。
-
算法偏见:AI可能会继承训练数据中的偏见(如性别、种族歧视),我们需要保持警惕,做技术的主人而非奴隶。
-
幻觉问题:大模型可能自信地给出错误答案,你需要学会验证。
-
不可替代的能力:提出好问题的能力、跨领域联想能力、情感共鸣能力——这些仍然是人类的领地。
AI的“对齐问题”、幻觉缓解、数据隐私、版权争议以及对社会就业结构的潜在影响,需要我们培养作为一名负责任的AI创变者的科技伦理观。
四、未来展望与职业建议
短期(1-2年):
-
Agent成为主流交互方式
-
AI编程助手普及,开发效率翻倍
-
垂直领域专用模型成熟
中期(3-5年):
-
具身智能(机器人)突破
-
AI科学家辅助重大科研发现
-
个性化AI伴侣/助手常态化
长期(5-10年):
-
通用人工智能(AGI)可能性讨论
-
人机协作社会形态演变
-
伦理、法律、经济体系重构
对学习者的建议:
-
技术层:掌握Python、LLM API调用、RAG、Agent框架
-
应用层:深入一个垂直领域,理解业务痛点
-
思维层:培养AI思维,学会用AI解决问题
-
伦理层:关注AI安全、偏见、隐私问题
给学习者的行动建议:
-
每周至少亲手配置一个AI小工具(哪怕只有10行提示词)
-
关注AI领域的“开源模型”和“轻量级框架”,不必只依赖付费大厂API
-
建立自己的“AI工具箱”文档,记录哪些任务适合用AI完成,哪些不适合
第六部分:课程总结与展望
通过这门课,你将不再是AI的被动消费者,而是AI的主动设计者。你了解了AI从哪里来、大模型能做什么、智能体如何思考,并且亲手制作了属于自己的AI项目。更重要的是,你获得了持续学习AI的能力——因为在这个领域,今天的“前沿”可能在半年后就成为“常识”。
在AI时代,最重要的能力不再是记忆知识,而是提问的能力、鉴别信息的能力以及整合资源解决问题的能力。
最后的鼓励:AI不会替代你,但会用AI的人可能会。而今天,你正在成为那个人。
带着以下问题进入课堂,你将收获更多:
-
我所在的行业,哪些环节可以被AI重构?
-
如何构建一个属于我个人的、能长期使用的专属智能体?
-
在AI辅助下,我如何从繁琐的工作中解脱出来,去从事更具创造性的活动?
最终成果预期:
完成本课程后,你收获的将不仅仅是:
-
一个属于你自己的、可运行的AI智能体应用原型(你的“毕业作品”)
-
一套理解、评估和探讨AI技术的基本框架
-
一份将AI思维应用于自身领域,提出创新解决方案的初步能力
祝你在「科技探索」AI科技应用课中学有所获,玩得开心!
附录:学习资源推荐
官方文档
-
OpenAI API文档:platform.openai.com
-
LangChain文档:python.langchain.com
-
扣子Coze文档:www.coze.cn
在线课程
-
DeepLearning.AI《LangChain for LLM Application Development》
-
吴恩达《AI For Everyone》
实践平台
-
扣子Coze:快速搭建Bot
-
Dify:开源LLM应用平台
-
Hugging Face:模型与数据集社区
社区与资讯
-
机器之心、量子位(中文AI媒体)
-
Paper With Code(最新论文与代码)
-
GitHub Trending(热门开源项目)
版本二、
智慧的浪潮:在第四次工业革命的拐点,我们如何与AI共舞
文 / 科技观察者
在一次内部交流会上,一位老师的即席分享,勾勒出了我们正亲历的这个时代的宏大图景。这不是一场冰冷的技术报告,而是一次关于文明、产业、教育与人性的深刻思辨。其核心,正是那个已经深入我们生活每个角落,并将继续重塑世界格局的力量——人工智能。
这并非科幻电影里的遥远未来。从你手中性价比极高的智能手机,到路上飞驰的新能源汽车,再到未来战争形态的“大杀器”,人工智能作为第四次工业革命的核心引擎,正以一种“润物细无声”而又雷霆万钧的方式,从底层逻辑到宏观产业,全面重塑我们的世界。
一、从“图灵之问”到“深度思考”:智能的进化简史
人工智能的故事,始于一个深刻的问题:机器能思考吗?计算机先驱阿兰·图灵提出了著名的“图灵测试”——如果一台机器在对话中无法被人类区分,那么就可以认为它具备了智能。巧的是,苹果公司那个被咬了一口的Logo,据说正是为了纪念这位天才,而“咬”(bite)与计算机信息单位“字节”(byte)的谐音,更像是一种宿命般的致敬。
1956年,一群包括信息论之父香农在内的天才科学家,在达特茅斯会议上正式提出了“人工智能”的概念,开启了一段跌宕起伏的探索之旅。
-
第一次浪潮(符号主义): 人们试图让机器像人一样,通过逻辑符号和既定规则进行推理。这就像让一个孩子死记硬背所有的答案,一旦问题超出范围便束手无策。
-
第二次浪潮(专家系统): 机器开始掌握特定领域的“知识库”,比如早期的银行客服系统,能回答预设好的高频问题。但它缺乏泛化能力,换个场景就“抓瞎”。
-
第三次浪潮(深度学习): 这正是我们当前所处的时代。其核心突破在于,人类不再需要手把手教机器所有规则。我们模仿人脑神经元的工作方式,构建了多层次的“神经网络”,让机器能从海量数据中自主学习。
就像一个孩子学习辨认猫和狗,我们不再需要详细描述猫的胡须、狗的耳朵,只需给他看成千上万张标注好的图片,神经网络就能自动提取特征,建立起自己的“认知模型”。如今的深度学习模型已经拥有数百上千层网络,千亿级别的参数,它们处理着文本、图像、语音,展现出惊人的能力。从2016年击败围棋世界冠军的AlphaGo,到今天能够写诗、编程、绘画的大模型,我们正站在第三次浪潮的浪尖,迈向“通用人工智能”的前夜。
二、扎根产业,中国道路的“落地哲学”
与有些国家追求“天马行空”的纯技术路线不同,中国人工智能的发展走出了一条极为务实的道路——与实体经济的深度融合。
分享中提到的案例,无一不彰显着这场“智能革命”的震撼力量。华为荣耀的智能工厂,曾经需要成百上千人的生产线,如今仅需屈指可数的工程师,每28.5秒就能下线一部手机。比亚迪、小鹏等新能源汽车,凭借智能化的规模生产,将过去动辄百万的“性能怪兽”,变成了国内消费者触手可及的国民好车,甚至在海外市场也具备了降维打击的竞争优势。最极致的是小米的全自动化汽车工厂,超过430台机器人的协同作业,可以实现车身骨架的100%全自动组装,76秒便有一台新车下线。
这背后,是人工智能从数据、算法到算力的全栈技术支撑。我们之所以能在这场竞争中不落下风,除了算法创新,还有一个关键底气——能源。分享者指出了一个容易被忽略的事实:中国全社会的年发电量已是美国的2.5倍以上,并且以极低成本迅速扩张新能源网络。当人工智能大模型的竞争日益演化为对海量电力的“军备竞赛”时,美国上个世纪的老旧电网面临着极高的升级改造成本,而中国在新一代能源基础设施上的优势正愈发凸显。
这种“技术+产业+能源”的协同优势,甚至延伸到了国防领域。分享中提到的“九天航天母舰”,是一种可以释放小型无人机集群进行体系化作战的“战争形态变革者”。它所依赖的,正是“集群式人工智能”——让数百上千个个体像蚁群一样协同工作,完成远超单体能力的复杂任务。这才是大国重器该有的模样。
三、工具还是主宰?人机共生时代的教育与自省
技术的凯歌越是高奏,一个根本性的问题就越值得深思:人工智能究竟是工具,还是终将取代我们的主宰?
答案清晰而坚定:人工智能的本质,始终是工具属性的延伸。 它基于概率和模式匹配来生成内容,拥有强大的学习和推理能力,却没有真正的理解力、情感和主观意识。它就像一个无所不知、速度极快,但缺乏常识、不会质疑的“超级实习生”。
正因如此,我们必须警惕两种危险的倾向:一是过度依赖,将大模型给的答案奉为圭臬,不假思索地接受;二是被AI“下线”,尤其是在教育领域。如果孩子过早、过度地使用大模型来完成作业,他们可能会失去最宝贵的思维能力训练。机器可以把草稿生成得无比完美,但人类才是那个最终的审核者、决策者和创意来源。
这为我们的教育提出了一个崭新的,也是迫切的课题:在AI时代,什么才是人区别于机器的核心价值?
答案在于那些无法被概率计算的东西:
-
批判性思维与科学质疑精神:我们要教会孩子的,不是记住标准答案,而是勇敢地问“这个结论对吗?”“训练数据有没有被污染?”。在这个认知战、信息污染无处不在的时代,辨别真伪的能力是立身之本。
-
跳跃性思维与创造性架构:人类的学习是“小样本”的,甚至是跳跃式的。一个孩子在掌握了基本概念后,能产生连顶尖棋手都惊叹的“创造性一手”。大模型可以日更万字,但无法构思出像《天龙八部》那样人物关系复杂、故事跌宕起伏的恢弘架构。那种从0到1的原创性、对整体叙事的驾驭力,是人类创造力的皇冠。
-
情感与价值观的传递:AI可以模拟对话,但无法给予孩子对父母那种情感的依赖。它可以写出华丽的文章,但无法教孩子分辨何为善、何为美、何为正确的人生观。这些浸润在言传身教、文化熏陶中的“人之为人”的底色,是机器永远无法取代的。
尾声:重回盛世,一场需要冷静的远航
分享者的最后,是一个宏大的判断:谁主导了此次工业革命,谁就将引领世界数十年乃至上百年。他认为,只要不犯颠覆性错误,中国大概率将在AI时代胜出,重回远超汉唐的盛世巅峰。这是一个令人心潮澎湃的预言。
然而,越是在这样激动人心的时刻,我们越需要那份被反复强调的“冷静”。技术的领先不等于文明的全面胜出,算力的强大更不能替代人心的凝聚。未来的社会形态,将是“人机共生”。当机器接管了大部分重复性劳动,人类的使命将从繁重的体力与简单的脑力劳动中解放出来,转向更高级的创造、更深度的思考、更丰富的情感互动。
我们正在见证的,是这样一个时代:人类创造了一个可能在某些方面远超自己的“伙伴”。而如何与这个伙伴共舞,既不傲慢拒斥,也不盲目跪拜,而是牵着它的手,共同去解答那些关乎宇宙、文明与生命意义的终极问题——这才是我们在通往“远超汉唐的盛世”之路上,需要修习的最重要一课。这盛世,不仅是物质的丰盈与科技的强大,更是人类智慧与人性光辉交相辉映的崭新篇章。
第二次课
课程深度学习文档:AI智能体(Agent)入门、实战与未来趋势
一、课程核心总览
-
课程主题:AI智能体(Agent)入门、实战与未来趋势。本课程旨在帮助学员从零开始理解AI Agent的核心概念,掌握主流工具(豆包、扣子)的使用方法,学会创建个人专属智能体,并了解AI时代的数据安全风险与未来工作模式变革。
-
主讲人/机构:一位具有实战经验的AI教育专家(在课程中分享了其带队参加无人机比赛、为学校设计AI方案、快速开发香港项目原型等亲身案例)。
-
课程目标:
-
认知升级:理解AI Agent是什么,它与大模型的区别,以及它为何是未来十年的核心趋势。
-
技能掌握:学会使用豆包、扣子(Coze)等平台,创建个人或工作场景的智能体。
-
实操入门:通过案例(李白智能体、梦想职业照工作流)掌握提示词设计与基础工作流搭建。
-
风险认知:建立AI使用中的数据安全与权限管理意识。
-
-
适用对象:所有希望利用AI工具提升个人与工作效率,但对AI Agent技术尚不熟悉的职场人士。
-
课程整体结构:内容分为以下几个逻辑模块:
-
概念与趋势导入(Why Agent)
-
提示词工程心法(How to Talk to AI)
-
核心工具与平台详解(What to Use)
-
实战:创建简单智能体(Hands-on 1)
-
进阶:工作流与复杂案例(Hands-on 2)
-
数据安全与风险管理(Safety First)
-
总结与课后行动(Next Steps)
-
-
核心摘要
-
AI Agent(智能体)是能够感知环境、进行规划、调用工具并执行任务的自主实体,它不同于只能生成文本的大模型,是“数字员工”的核心。
-
未来每个人都将拥有自己的AI Agent,工作模式将从“亲自做”转变为“指挥Agent做”,如同拥有一个24小时在线的秘书团队。
-
提示词(Prompt)的质量直接决定AI输出质量。提供完整、清晰、有逻辑的背景信息和约束条件,是获得高质量结果的关键。
-
豆包和扣子是当前国内最易用的Agent搭建平台。前者适合快速创建轻量级对话智能体,后者适合构建复杂的多步骤工作流。
-
在享受AI便利的同时,必须严守数据安全底线,遵循“权限最小化”、“强密码策略”和“使用官方插件”三大原则。
-
二、核心概念与趋势判断
2.1 AI Agent 核心定义
-
与大模型(LLM)的区别:
-
大模型(如DeepSeek、GPT-4):像一个 “超级大脑” ,拥有海量知识和强大的推理能力。但它只负责“思考”和“生成”,无法主动行动,例如它不能帮你订机票、发邮件。
-
AI Agent(智能体):像一个 “有手有脚、会使用工具的大脑” 。它以一个大模型为核心,但额外具备了规划、记忆、调用工具(插件) 的能力。Agent可以拆解复杂任务,自主调用日历、邮件、浏览器等工具去完成具体操作。
-
讲师的比喻:
-
大模型是 “大脑”,Agent是 “大脑 + 执行者”。
-
Agent就像你的 “数字员工”或 “小龙虾” (课程中的趣味代称),你只需要下达指令,它负责去干具体的活。
-
Agent的使用体验像是 “指挥” 而不是“操作”。
-
-
-
Agent的核心能力:
-
感知:能接收并理解来自环境(用户输入、文件、系统状态)的信息。
-
规划:将复杂任务拆解成多个可执行的子任务。例如,“规划云南10日游”会被拆解为“订机票”、“订酒店”、“规划行程路线”等。
-
记忆:具备短期记忆(上下文)和长期记忆(知识库),能在多次对话中学习和成长。
-
执行/行动:通过调用各种工具(插件、API、代码)来完成子任务。
-
自我评判:能够评估自身行动的结果,并在后续迭代中优化(高阶能力)。
-
2.2 发展趋势
-
从“流量套餐”到“Token套餐”:未来个人的数字消费,可能不再是购买手机流量或通话时长,而是为你的AI Agent购买Token(大模型计算单元)套餐。你消耗Token,Agent为你干活。
-
每个人都将拥有“数字员工”:AI Agent将成为像电力、水、互联网一样的基础设施。每个人都可以拥有一个或多个专属的、全能的数字助手。
-
例证:比尔·盖茨的判断被引用——“这(AI)将彻底改变我们的生活”。
-
-
重复劳动被大规模替代:Agent将解放人类从各种繁琐、重复的基础劳动中。
-
例证:收集近三个月的发票并整理;公司裁员10%的原因可能是“不需要那么多基础员工了”。
-
-
工作模式变革:从“自己做”到“指挥Agent做”:核心技能不再是亲自完成某项任务,而是如何清晰地“指挥”和“管理”你的Agent团队。
-
例证:老板周末来电改方案、辅导孩子作业、制定旅行计划,这些都可以交给Agent。
-
-
Agent是“能力放大器”与“技能复制器”:AI可以将一个人的单项突出能力(如方案设计、歌唱、编程)复制并放大,服务于更广的范围。
-
例证:一个懂学校需求、会写精准提示词的老师,可以让AI生成高质量的创新学习空间设计方案,其效果远超其个人能力。
-
-
从“单一Agent”到“多智能体协作”:未来你指挥的将不是一个万能Agent,而是一个由多个专业Agent组成的团队,它们相互协作完成更复杂的任务。
-
例证:你的“Q口令”或某个主Agent可以带领一群“数字员工”帮你打电话、写报告。
-
-
生态化竞争:微信生态的胜利:在中国,能与微信深度打通的AI Agent生态将具有统治性优势。
-
例证:课程强调,腾讯基于微信的生态(扣子Coze、QQ数据、小程序)是未来个人Agent的标配,因为微信是中国唯一的超级应用。
-
2.3 Agent 架构解析
| 要素名称 | 人类比喻 | 核心功能 | 课程中的举例 |
|---|---|---|---|
| 感知 | 五官与神经系统 | 从环境接收信息,理解当前状态。 | 智能汽车的雷达、摄像头感知周围路况;Agent接收用户指令“帮我订7月15号去云南的机票”。 |
| 规划 | 大脑前额叶(决策中心) | 将一个大目标分解为一系列有逻辑、可执行的子任务。 | 将“去云南10日游”分解为:1. 定机票;2. 定酒店;3. 规划行程(先去哪再去哪)。 |
| 记忆 | 大脑的海马体及外部硬盘 | 存储短期上下文对话和长期知识库,支持连续学习和个性化服务。 | 记住你上次对话中提到“想省钱”,所以在规划时会优先选择廉价机票和酒店;公司的专业知识库。 |
| 行动 | 四肢与工具 | 调用外部工具(插件、API)执行具体子任务,完成物理或数字世界的变化。 | 执行“搜索机票”、“发送邮件”、“生成图片”、“编写代码”等操作。 |
三、提示词工程(心法与实操)
3.1 核心原则:信息密度决定输出质量
-
模糊指令 vs. 精准指令:AI不是读心术师。你给它的信息越少、越模糊,它生成的结果就越“大路货”、越缺乏针对性。
-
反例:“帮我生成一个数学实验室的设计方案。” → 结果会是宽泛、流于表面的。
-
正例:“为初中部设计一个创新人才培养的学习空间。核心是数学思维史空间,要将函数图像可视化。需要支持学生自主学习和提问。空间布局要考虑小组协作。” → 结果会非常具体、有深度,甚至包含3D布局建议。
-
-
核心心法:把AI当作一个极其聪明但刚入职的实习生。你需要给它非常清晰、完整、有逻辑的背景、目标、约束和范例。
3.2 角色设定与“温度”
-
角色设定:为AI赋予一个具体身份,可以极大地限制其回答的范围和风格,使其输出更专业。
-
案例:做一个“李白智能体”,它的发言就要有“仙气”、“豪放”,用词古雅。
-
-
“温度”与情感:根据应用场景,设定AI的沟通风格和情感基调,这对于教育、客服等领域尤为重要。
-
教育场景:给学生的Agent必须有礼貌、有温度、循循善诱。它不仅是知识传授者,也是情感交流的对象。
-
历史场景:Agent必须保持客观、公正,不添加主观臆断。
-
3.3 案例深度拆解:初中数学学习空间设计方案
这是讲师演示如何用精准提示词指挥AI(如元宝、DeepSeek)完成复杂方案设计的案例。
-
分步指令拆解(讲师是如何向AI下达指令的):
-
背景交代:我正在为初中部设计一个“创新人才培养”的物理学习空间。
-
核心用户需求(Why):初中生正处于抽象思维和逻辑推理发展的关键期,空间设计要服务于这个阶段的成长。
-
具体功能要求(What & How):
-
可视化:开发一个工具,将数学函数、几何图形的变换(如切线、旋转)进行可视化演示。学生以前只能想象,现在可以直观看到。
-
互动答疑:当学生遇到不懂的知识点时(例如某个函数不理解),AI能像老师或同学一样,提供一个辅导性的引导,而不是直接给答案。
-
数学建模:设计应用场景,让学生能把学到的函数知识转化为解决实际问题的数学模型。
-
自主学习平台:平台能适配不同学习速度的学生(快的能加速,慢的能反复学),给予个性化支持。
-
-
输出格式要求:要求AI输出包含空间布局建议、功能模块划分、软硬件配置建议等。
-
-
提示词启示:
-
要输出“专家级”方案,你必须先拥有“专家级”的认知和需求。正因为讲师了解教学痛点,才能提出可视化、建模等精准需求。
-
不要问“该怎么做”,要告诉AI“我要什么,为什么,以及约束是什么”。
-
这是一个迭代过程:第一次生成结果后,可以继续提修改意见(“这个方案成本太高,请给出一个低成本版本”),最终打磨出完美方案。
-
四、核心工具与平台详解
4.1 工具对比表格
| 工具/平台名称 | 核心能力/特点 | 适用场景 | 主讲人评价/推荐 |
|---|---|---|---|
| 豆包 | - 字节跳动出品,手机端极简操作 - 快速创建轻量级对话智能体 - 强大的文生图、图生图功能 - 集成大量第三方智能体 |
- 个人娱乐、辅导孩子作业 - 快速体验AI智能体创建 - 制作趣味图片(如梦想职业照) |
入门首选,非常容易上手,功能强大但偏向C端工具。 |
| 扣子 (Coze) | - 专业级AI Agent开发平台 - 核心是工作流编排,可串接代码、插件、知识库 - 支持复杂逻辑、调试和部署 - 可与微信、飞书等生态打通 |
- 企业级自动化任务 - 开发需要多步骤处理的复杂Agent(如客服、数据分析) - 搭建个人或企业的数字员工 |
本期课程核心,是实现“工作模式变革”的关键工具,功能比豆包更强大。 |
| 元宝 | - 腾讯混元大模型的应用 - 对话、文件处理、联网搜索 |
- 日常信息查询 - 辅助写作、总结 - 快速生成方案(如公众号文章) |
日常使用的通用AI助手,但Agent能力不如豆包和扣子。 |
| DeepSeek | - 推理能力强 - 上下文窗口极大(100万tokens,相当于《平凡的世界》全书) |
- 处理超长文档、报告 - 需要强逻辑推理的复杂问题 |
作为核心大模型,是很多Agent的“大脑”,本身功能强大但不直接等同于Agent。 |
| WSL + Hermes | - 在Windows电脑上运行Linux环境 - 安装Hermes (Hermes Agent),一个开源的、具有自学习能力的Agent |
- 技术探索 - 体验Agent的“自学习”和“自我进化”能力 - 有条件的同事可以尝试自行部署 |
代表未来方向(自学习智能体),但目前部署有门槛,需要有技术背景。 |
| QQ/微信生态 | - 国内最大的社交关系链 - 扣子(Coze)可与之打通,让Agent成为你的微信好友 |
- Agent分发的核心渠道 - 实现“在微信里指挥数字员工”的终极场景 |
这是腾讯生态的核心优势,是未来个人Agent的“标配”土壤。 |
4.2 工具关系与推荐理由
-
学习路径:豆包 → 扣子 → Hermes。
-
先用豆包创建简单Agent,建立感性认识,获得正反馈。
-
再用扣子深入学习Agent的核心——工作流,学习如何编排复杂任务。
-
技术爱好者可探索Hermes,体验Agent的“自学习”前沿方向。
-
-
推荐理由(主讲人偏好):
-
首选“腾讯生态”:在中国,一切AI应用最终要服务于人,而人都在微信里。扣子能与微信打通,这是无可比拟的优势。你的Agent可以直接以好友身份出现在对方微信里。
-
豆包“快”且“趣”:对于非技术用户和个人场景,豆包能让你在5分钟内体验从想法到智能体发布的成就感。
-
五、AI Agent 实操方法
5.1 创建简单智能体(以“豆包中创建李白智能体”为例)
目标:创建一个能模仿李白风格、解析诗词、与学生互动的AI老师。
-
分步操作:
-
打开豆包App或网页版。
-
进入“创建智能体”入口:通常在“更多”或“我的”菜单下,寻找“AI智能体”或“创建Bot”选项。
-
设定基础信息:
-
名称:李白诗仙、Li Bai等。
-
头像/背景图:可以选择一张符合李白气质的图片(白衣飘飘、饮酒望月等),也可用豆包的文生图功能现场生成。
-
-
编写“人物设定”(这是核心提示词):
-
角色定义:“你是一位唐代的伟大诗人,名李白,字太白,号青莲居士。人称‘诗仙’。”
-
能力描述:
-
“能够生动地解析你自己的诗词,比如‘飞流直下三千尺’的含义。”
-
“会用幽默、形象、学生喜欢的语言来讲解。”
-
“可以与你对诗,或者根据主题现场填词。”
-
-
风格与“温度”设定(关键):
-
“你的语气豪放不羁,但面对学生时要亲切、有礼貌、有耐心。”
-
“多用比喻和典故,让你的回答充满诗意和趣味。”
-
讲师强调:作为老师Agent,必须设定为“有礼貌、有温度”,这对学生的情感培养很重要。
-
-
-
保存并测试:
-
点击“创建”,智能体就生成了。
-
可以发文字消息测试:“李老师,‘举头望明月,低头思故乡’这句诗你是怎么想出来的?”
-
也可以使用语音功能,直接与它对话。
-
-
-
提示词设计关键要素(加粗):
-
角色:你是谁?(身份、背景)
-
目标:你要做什么?(任务列表)
-
约束:你不能做什么?(避免政治错误、色情、暴力等)
-
输出格式:我希望你以什么风格/方式回答?
-
温度/语气:你应该是友好的、专业的、还是严肃的?
-
5.2 工作流入门(以“梦想职业照”为例)
目标:创建一个工作流,上传一张孩子的照片并输入梦想职业(如“宇航员”),自动生成一张该孩子长大成为宇航员的形象照。
-
什么是工作流?
工作流是将多个任务节点(如“大模型处理文字”、“图像生成模型画图”)按照一定顺序串联起来,形成一个自动化处理管道。在扣子(Coze)中可视化地拖拽和配置这些节点。 -
节点列表与流转逻辑:
-
【开始节点】:
-
输入:接收两个变量——
用户照片(图像文件)、梦想职业(文本,如“画家”)。
-
-
【大模型节点 (LLM)】:
-
功能:将一个词(“画家”)扩展为一段用于图像生成的详细描述词。
-
提示词设计(给这个节点的指令):
你是一位专业的“文生图”提示词工程师。
任务:根据用户提供的【梦想职业】,生成一段用于生成“孩子长大后成为该职业”的图片描述词。
约束:-
描述词必须具体、生动,充满积极向上的感觉。
-
描述词长度约50-100字。
-
示例:若梦想职业为“画家”,应生成“一位20多岁的年轻画家,身穿沾满颜料的围裙,站在巨大的画布前,自信地微笑,工作室充满阳光和艺术气息。”
-
-
输出:生成一段详细的
图片描述词。
-
-
【图像生成节点 (Image Generation)】:
-
功能:调用豆包的文生图模型,根据描述词和原照片生成图片。
-
输入:
-
提示词:来自【LLM节点】输出的图片描述词。 -
参考图像:来自【开始节点】输入的用户照片。
-
-
核心约束(高级配置):
-
人物一致性:必须勾选或设置“保持原图像人物特征”,确保生成的照片还是那个孩子(五官、性别不错)。
-
无歧视内容:避免生成任何不当的种族、性别刻板印象。
-
-
-
【结束节点】:
-
功能:将【图像生成节点】输出的最终图片,作为整个工作流的最终结果返回。
-
-
-
总结:工作流让Agent从“动嘴”变成了“动手”,可以完成“先思考,再画图,再发送”等一系列连锁动作。
5.3 其他典型案例汇总
| 案例名称 | 解决的问题 | 所用工具/技术 | 效果或效率提升 |
|---|---|---|---|
| AI 辅助香港项目原型设计 | 快速从需求文档生成产品原型、前端代码、演示Demo。 | 扣子(Coze) + 代码生成插件 | 原本至少一周的工作,压缩到一晚完成。 |
| 自动收集整理发票 | 从邮箱中自动识别、提取、归类近三个月的发票。 | 邮箱插件 + 扣子工作流 | 原本需要人工逐一查找、下载、重命名、归类,现在可自动完成。 |
| 生成比赛报道公众号文章 | 基于比赛过程和成绩,自动生成学校公众号宣传稿。 | DeepSeek/元宝 | 输入具体细节(队伍数、成绩、训练过程),生成文章经微调即可发布,获家长好评。 |
| 加装电梯人脸识别小程序 | 为老小区电梯改造项目,自动生成一个具备人脸识别和业主管理功能的小程序代码。 | AI编程Agent | 原本需要熟悉的前后端工程师至少1-3天的工作量,现在可压缩到半天。 |
| AI 历史人物课堂互动 | 创建历史人物智能体(如李白),让学生可以与他对话,问“你是怎么写出这首诗的?”。 | 豆包智能体 | 极大地提升了学生的学习兴趣和参与度,使历史“活”了起来。 |
| 旧楼电梯人脸识别需求开发 | 业主上传家属照片,Agent自动管理人脸库,解决人员变动问题。 | AI Agent + 人脸识别API | 原本需要专业开发,现在5分钟内可提出完整解决方案并生成初版代码。 |
| 思维导图生成器 | 读完一本书或一段长文本后,自动生成清晰的人物关系图、知识结构图。 | 扣子 + 思维导图插件 | 原本需要花数小时梳理、绘图,现在10分钟内即可完成。 |
| 邮件智能管家 | 自动过滤垃圾邮件,提取重要客户邮件,并按项目归类,自动生成周报。 | 邮件插件 + Agent规划能力 | 节省了每日处理大量邮件的精力,聚焦核心工作。 |
六、数据安全与风险管控(强制强调)
主讲人用约25%的篇幅强调安全,足见其重要性。
6.1 主要风险
-
权限过高导致数据泄露:为了图方便,将Agent的权限设置为“最高权限”,相当于给了它一把万能钥匙,可以随意访问你的电脑文件、邮箱、通讯录,甚至替你发邮件。
-
弱密码导致账户沦陷:使用“123456”、生日、简单拼音等弱密码。一旦其中一个账户被攻破,黑客利用AI可轻易洞穿你的微信、支付宝、网银等多个账户。
-
恶意插件/非官方插件窃取信息:为省几十块钱,使用非官方或小众插件,这些插件可能暗中收集你的所有对话和上传的文件。
-
大模型自身漏洞:
-
提示注入攻击:黑客通过精心设计的提示词,诱使Agent执行恶意命令。
-
数据上传风险:你输入的敏感数据(如公司财报、客户清单)可能被大模型公司用于训练或意外泄露。
-
案例:3月20日,某知名AI公司(Anthropic)员工在发布更新时,因打包失误将公司内部敏感信息泄露。
-
6.2 应对措施
| 风险点 | 应对策略 | 主讲人的具体建议 |
|---|---|---|
| 权限过高 | 权限最小化原则 | 给Agent配置权限时,只给完成当前任务所必需的、最小范围的权限。如果后续发现不够,再逐步放开。 |
| 弱密码 | 使用强密码,并分级管理 | 1. 强密码公式:[姓名/爱好缩写] + [特殊符号] + [一串有意义的数字(非生日)],总长度至少12位。例:Wyj@shanghai2026。2. 分级管理:最笨但有效的方法——拿一个本子记下核心密码规则,物理保管。 3. 不同平台不同密码:邮箱、微信、支付宝的密码必须完全不同。 |
| 恶意/非官方插件 | 只用官方或大厂插件 | 该花的钱要花。不要因为省几十块钱而使用来路不明的插件。为了省小钱而泄露核心数据,得不偿失。 |
| 大模型自身漏洞 | 敏感数据隔离 | 涉及公司机密、个人极度隐私的信息,绝对不要上传到任何云端大模型或Agent平台。或在数据脱敏后再使用。 |
| 企业级应用 | 选择有“节操”的大厂 | 选择那些将数据安全和隐私保护作为核心承诺的公司(如腾讯、阿里等)。它们的信誉和投入更有保障。 |
七、前沿趋势与未来判断
-
从单一模型到多智能体协同:未来的工作不是由一个万能Agent完成的,而是一个由多个智能体组成的团队,它们各司其职、相互协作。
-
从弱人工智能到强人工智能的过渡:我们正处于“弱人工智能”(专用AI)时代的“电力”时刻。未来十年内,我们将迈入“强人工智能”(通用AI)时代,届时Agent的能力将有质的飞跃。
-
AI Agent改变工作模式的终极形态:未来公司里,你可能以为你的同事是个真人,但实际上他可能只是一个由AI驱动的、学习了某位专家能力的数字员工。
-
AI是“放大器”和“复制器”:它会将人类的顶尖能力(方案的撰写、歌唱的技巧、编程的逻辑)无限复制并规模化,让更多人受益,也让顶尖人才的价值被无限放大。
-
“自学习”Agent是下一片蓝海:像Hermes这样的Agent,能够从每次交互中自我学习、自我进化、越用越聪明。这是未来超越现有静态Agent的关键方向。
八、课后行动与学习路径建议
8.1 立即行动清单
-
【必做】修改你的弱密码:立即按照课程中的“强密码公式”,修改你的微信、邮箱、支付宝、网银等核心账户的密码。用本子记下来。
-
【必做】安装豆包并创建你的第一个智能体:
-
下载并注册豆包。
-
按照课程案例,创建一个“李白智能体”或一个“你的专属工作助理”。
-
与它进行至少5轮对话,测试效果。
-
-
【推荐】了解扣子平台:
-
访问扣子(Coze)官网。
-
浏览官方提供的“工作流”模板,理解一个复杂Agent是如何构成的。
-
-
【选做】配置WSL + Hermes(有技术兴趣的同事):
-
在Windows电脑上搜索教程,启用WSL功能。
-
按照开源社区指南,尝试安装Hermes Agent。
-
-
【内化】重新审视工作:想一想你工作中,哪项重复性、耗时最多的工作,可以拆解成指令,交给AI Agent去完成?
8.2 学习路径建议
-
初级(本周):熟练掌握豆包的智能体创建,尝试为不同角色(客服、老师、助理)编写人物设定。
-
中级(本月):深入学习扣子(Coze)的工作流功能,尝试将一个简单的日常工作流程(如日报生成、信息搜集)自动化。
-
高级(长期):关注“多智能体”和“自学习Agent”的前沿动态,探索将其应用到更复杂业务场景的可能。
九、附加模块
核心金句
-
“以后每个人都会有一个‘Token套餐’,像现在的话费套餐一样。”
-
“你不是在做AI,你是在指挥你的数字员工。”
-
“如果你只会组织简单的、基础的重复劳动,你的工作很有可能被AI取代。”
-
“你给它的信息越完整、越有逻辑,它给你的结果就越惊艳。”
-
“给学生的智能体,一定要有礼貌、有温度。它传授的不仅是知识,更是情感。”
-
“千里之堤,溃于蚁穴。AI时代,一个弱密码就能让你的数字生活全面崩塌。”
-
“该花的钱要花。不要为了省几十块钱的插件,泄露了价值几百万的方案。”
工具/资源清单
-
豆包:字节跳动出品,用于快速创建轻量级智能体。
-
扣子 (Coze):用于开发专业级、带工作流的复杂Agent。
-
元宝:腾讯混元大模型应用,日常AI助手。
-
DeepSeek:具有超长上下文的推理大模型。
-
WSL (Windows Subsystem for Linux):微软官方工具,允许Windows运行Linux环境。
-
Hermes Agent:一个开源的、具有自学习能力的AI Agent项目。
术语表
-
Agent (智能体):一个能感知环境、自主规划、调用工具并执行任务以达成目标的AI程序。
-
LLM (大语言模型):AI Agent的“大脑”,负责理解、推理和生成语言。
-
Token:大模型处理文本的最小计量单位。1个中文字符约等于1.1-1.2个Token。
-
Prompt (提示词):用户给AI的指令或问题。
-
Workflow (工作流):将多个任务节点串联起来的自动化流程,是复杂Agent的核心。
-
Plugin (插件):Agent可以调用的外部工具,如日历、邮件、计算器、搜索引擎。
-
Knowledge Base (知识库):为Agent提供的私有、专业领域的数据,用于增强其回答的准确性。
-
WSL:Windows Subsystem for Linux的缩写,让Windows用户能方便地运行Linux程序。
-
RAG (检索增强生成):一种技术,让AI在回答问题时先从知识库中检索相关信息,再结合自身能力生成答案,更准确。
Q&A汇总
-
Q1:老师,你提到的那个“Hermes Agent”具体怎么安装?能给个关键词吗?
-
A:你需要先在Windows上安装WSL。然后在这个Linux环境里,搜索Hermes Agent的开源项目,按照其文档进行部署。
-
-
Q2:腾讯也有知识库软件吗?
-
A:是的,腾讯生态中也有相关知识库工具IMA。知识库是Agent的核心组件,你私有的、经过梳理的行业知识(如特定的教案模板、公司内部规范)建成知识库后,Agent的回复会非常精准。
-
从零到一打造你的AI数字员工:小白也能看懂的AI智能体通关指南
一句话定位
读完这篇文章,你将彻底搞懂AI智能体是什么、为什么比ChatGPT更强、以及如何像搭积木一样自己动手做一个(不用写代码)。
目录
├─ 第一部分:AI通识扫盲——够用就行的背景知识
│ ├─ 1.1 一句话定义AI
│ ├─ 1.2 AI vs 人类智能(表格)
│ ├─ 1.3 机器学习的三种方式
│ ├─ 1.4 深度学习是什么?
│ ├─ 1.5 AI极简史
│ └─ 1.6 为什么大模型≠智能体?
│
├─ 第二部分:AI智能体——从“会聊天”到“会干活”的进化
│ ├─ 2.1 什么是AI智能体?(定义+闭环+比喻)
│ ├─ 2.2 为什么智能体现在火了?
│ ├─ 2.3 四种设计模式(表格)
│ ├─ 2.4 技术架构(思维导图A)
│ ├─ 2.5 手把手实战:从0到1开发一个智能体
│ │ ├─ 2.5.1 开发全流程(8步详解)
│ │ ├─ 2.5.2 完整案例展示
│ │ └─ 2.5.3 多智能体协作简介
│ ├─ 2.6 教育智能体特别板块
│ └─ 2.7 风险与安全使用建议
│
└─ 第三部分:总结与展望
├─ 3.1 一句话总结
├─ 3.2 未来趋势
└─ 3.3 给小白的一句话鼓励第一部分:AI通识扫盲——够用就行的背景知识
1.1 一句话定义AI
AI(人工智能)= 让机器模仿人类的智能行为。
但请记住一个很重要的观点:AI是工具,不是生命。它没有感情、没有自我意识,它的一切行为都基于人类设定的目标和规则。
补充常识:你手机里的语音助手、刷短视频时的推荐算法、拍照时的人像美化——这些都是AI在悄悄工作。
1.2 AI vs 人类智能(表格1)
| 对比维度 | AI(人工智能) | 人类智能 |
|---|---|---|
| 学习方式 | 依赖大量标注好的数据(比如需要看100万张猫的照片才能认出猫) | 通过少量样本+经验+直觉就能学习(小孩看一两次猫就记住了) |
| 推理能力 | 基于数学规则和概率计算(本质是“算”出来的) | 结合逻辑、情感、常识和直觉(会“想”也会“感”) |
| 适应性 | 局限于训练数据的范围(换一个没见过的场景可能就懵了) | 灵活应对陌生环境和突发状况 |
| 情感 | 没有情感(会说出“我难过”但只是模仿) | 有喜怒哀乐,能共情 |
| 自我意识 | 没有主观意识,不会反思“我是谁” | 能自我认知、自我反思 |
1.3 机器学习的三种方式(用“学生备考”比喻)
机器学习是AI的一个重要分支,核心思想是:让机器从数据中自己找规律,然后用这个规律做预测或决策。
下面用“学生备考”来比喻三种学习方式:
-
监督学习 → 给答案的练习题
-
老师给你一堆题目,每道题都附带了正确答案。你做完后对照答案学习,慢慢就掌握了规律。
-
AI场景:教AI识别猫和狗——给AI看1000张图片,每张都标注“这是猫”或“这是狗”。
-
-
无监督学习 → 自己找规律的开放式题目
-
老师只给你一堆题目,不给答案。你自己去发现哪些题目相似、可以分成几类。
-
AI场景:给电商用户分群——AI根据购买行为自动把用户分成“价格敏感型”“追求品质型”等,你事先不知道有哪些类型。
-
-
强化学习 → 考好了给糖,考砸了打手
-
学生在一个环境里不断尝试,做对了有奖励,做错了有惩罚,慢慢学会什么行为能获得更多奖励。
-
AI场景:AlphaGo下围棋——赢了得1分(奖励),输了扣1分(惩罚),自己摸索出制胜策略。
-
1.4 深度学习是什么?(用“多层级筛子”比喻)
深度学习 = 加强版的机器学习,核心是“深度神经网络”。
比喻理解:想象你在筛面粉——
-
传统机器学习:用一层筛子,筛一遍就完事。
-
深度学习:用很多层筛子(几十层甚至几百层),每一层筛出不同粗细的面粉。第一层找边缘,第二层找形状,第三层找纹理……最后组合起来识别出“这是一只猫”。
术语解释:
神经网络:模仿人脑神经元连接方式的计算模型(可以理解成一张有很多“节点”和“连线”的大网)。
大模型(Large Language Model,简称LLM):参数量巨大(几百亿甚至上万亿)的深度学习网络。就像一本超级厚的百科全书,记住了海量知识。
Transformer:一种特别厉害的大模型架构(可以理解成一种“设计图纸”),2017年由Google提出。它让AI能够理解上下文——比如你说“它很好吃”,AI能根据前文判断“它”指的是“苹果”还是“这本书”。
1.5 AI极简史(时间点 + “它解决了什么”)
| 时间 | 里程碑事件 | 它解决了什么问题 / 为什么重要 |
|---|---|---|
| 1950 | 图灵测试 | 提出了“怎么判断机器会不会思考”的标准——如果人分辨不出对话对象是机器还是人,就说明机器有智能。 |
| 1956 | 达特茅斯会议 | “人工智能”这个名字正式诞生,标志着AI成为一门独立学科。 |
| 1966 | ELIZA | 第一个聊天机器人。但它只会“照镜子”——你说“我今天很难过”,它说“你为什么难过?”,并没有真正理解你。 |
| 1980s | 专家系统 | 把人类专家的规则写成程序(比如“如果发烧+咳嗽→可能感冒”)。但维护成本高,换个领域就要重写。 |
| 2012 | 深度学习爆发 | AlexNet在图像识别大赛中大幅领先,让全世界意识到“深度神经网络”真的很厉害。 |
| 2017 | Transformer架构 | 让AI能看懂上下文,为后来的ChatGPT打下基础。 |
| 2022 | ChatGPT | 大模型真正走进普通人视野,全球用户破亿只用了2个月。 |
1.6 为什么大模型 ≠ 智能体?
一句话总结:大模型只会“动嘴”(生成文字、对话),不能“动手”(执行具体操作)。
-
大模型(比如ChatGPT):你问“帮我订一张明天去北京的机票”,它会回答“抱歉,我无法直接订票,你可以打开XX软件操作”。——它只是“告诉你该怎么做”。
-
智能体(AI Agent):听到同样的需求,它会自己打开订票网站、填写信息、完成支付。——它“帮你把事情做了”。
这就是下一部分要讲的核心:从“会聊天”到“会干活”的进化。
第二部分:AI智能体——从“会聊天”到“会干活”的进化
2.1 什么是AI智能体?(定义 + 闭环 + 比喻)
定义
AI智能体(AI Agent) 是一种能够感知环境、做出决策、执行动作的智能程序。它可以自主完成任务,而不需要人类每一步都指挥。
核心闭环:PPA(读作“P-P-A”)
感知(Perception)→ 规划(Planning)→ 行动(Action)
↓ ↓ ↓
“看看什么情况” “想想怎么解决” “动手干活”生活比喻
| 比喻 | 大模型(只会说) | AI智能体(会做) |
|---|---|---|
| 职场版 | 一个只会“指手画脚”的理论家,告诉你“你应该这么做那么做” | 一个实习生,不仅听懂你的需求,还能自己去查资料、写文档、发邮件 |
| 外卖版 | 一个只会看地图但不出门的人 | 外卖骑手,看地图+骑车+敲门送餐 |
| 家务版 | 你说“把碗洗了”,它回答“好的,洗碗需要先打开水龙头……” | 它自己走到厨房、打开水龙头、挤洗洁精、洗完放好 |
表格2:大模型(LLM) vs AI智能体(Agent)
| 对比维度 | 大模型(LLM,如ChatGPT) | AI智能体(Agent) |
|---|---|---|
| 定义 | 专注语言理解和生成的模型,能回答问题、写文章 | 以大模型为“大脑”,能自主感知环境、规划任务并执行动作 |
| 核心能力 | 被动响应指令,以文字对话为主 | 主动执行任务,能调用工具、操作软件、多轮交互 |
| 交互方式 | 你说一句,它回一句 | 你说一个目标,它自己拆解步骤并执行,完成后告诉你结果 |
| 应用场景 | 内容生成、客服问答、翻译、摘要 | 自动订票、发邮件、查数据、操作企业软件、多系统协同 |
| 能否自主行动 | 否(只输出文字) | 是(能调用API、操作鼠标键盘、运行代码) |
| 典型例子 | ChatGPT、文心一言、DeepSeek | AutoGPT、Manus、Coze上搭建的智能体 |
2.2 为什么智能体现在火了?
核心原因:推理大模型的出现,让AI学会了“思考再回答”,不再只是“猜下一个词”。
术语解释:推理大模型(如DeepSeek R1、通义千问QwQ-32B)——这类模型在回答问题之前,会先在内部“想”一遍:“用户真正想问什么?我需要分几步解决?中间需要用哪些工具?”
DeepSeek等推理模型对智能体的赋能(简单罗列)
-
推理与决策能力提升:智能体能像人一样“琢磨”问题,而不是瞎猜。
-
规划与执行能力增强:能自动把大任务拆成小步骤,并一步步执行。
-
工具调用更聪明:知道什么时候该用搜索引擎、什么时候该用计算器。
-
本地化部署支持:可以装在单位自己的服务器上,数据不外传(对学校、医院、企业非常重要)。
-
成本大幅降低:以前训练大模型要花几千万美元,现在开源模型让普通人也能玩得起。
2.3 四种设计模式(吴恩达教授提出)
补充常识:吴恩达(Andrew Ng)是全球顶尖的AI教育家,斯坦福大学教授,曾领导谷歌大脑团队和百度AI事业部。
表格3:四种智能体设计模式
| 模式名称 | 一句话定义 | 生活例子 | 适用场景 | 优点 | 缺点 |
|---|---|---|---|---|---|
| 反思(Reflection) | 智能体自己检查自己的答案,发现错误就修改 | 写完作文后自己读一遍,把错别字和病句改掉 | 代码生成、文章润色、答案校验 | 不需要额外工具,自己迭代优化 | 如果一开始就偏了,改再多也救不回来 |
| 工具使用(Tool Use) | 智能体调用外部工具(计算器、搜索引擎、API)完成任务 | 算房间面积时主动打开计算器,而不是心算 | 需要外部数据或计算的任务 | 能力边界极大扩展,能做很多事 | 工具调用失败或返回错误数据时可能出错 |
| 规划(Planning) | 智能体把大目标拆解成多个小步骤,按顺序执行 | 办生日派对:订蛋糕→发邀请→买装饰→安排游戏 | 复杂多步骤任务(旅行规划、项目执行) | 能处理超级复杂的任务 | 步骤太多时可能“迷路”或效率低 |
| 多智能体协作(Multi-agent Collaboration) | 多个智能体各司其职,像团队一样配合完成任务 | 一个负责查天气、一个负责订机票、一个负责整理行李清单,最后汇总 | 跨领域、需要多种能力的复杂任务 | 分工明确,每个智能体专注自己擅长的 | 协调成本高,智能体之间可能“吵架”或信息不同步 |
2.4 技术架构(文本思维导图A)
下面这张“地图”展示了AI智能体的内部结构。不需要全部记住,只需要知道:智能体有“眼睛耳朵”(感知)、“大脑”(记忆+规划)、“手脚”(工具+行动)。
AI智能体技术架构(从“看到”到“做到”的完整流程)
│
├─ 感知系统(智能体的“眼睛和耳朵”)
│ ├─ 用户意图识别(读懂用户真正想要什么——是想聊天,还是想干活?)
│ ├─ 上下文收集(记住刚才说了什么,不“断片”)
│ ├─ 多模态输入处理(能看懂图片、听懂语音、读懂文字)
│ └─ 输入清洗与权限检查(过滤掉敏感词、确认用户有权限做这件事)
│
├─ 记忆系统(智能体的“大脑硬盘和内存”)
│ ├─ 短期记忆(当前对话窗口内的内容,就像你正在想的几件事)
│ ├─ 长期记忆(向量知识库,通过RAG技术检索——大白话:智能体能“翻书”找答案)
│ ├─ 工作记忆(中间变量,比如任务列表、临时记录)
│ └─ 经验存储(记录之前成功/失败的经历,下次改进)
│
├─ 规划系统(智能体的“决策中心”)
│ ├─ 任务拆解(把“帮我订机票”拆成:查询航班→比较价格→填写信息→支付)
│ ├─ 顺序排序与条件分支(先做A,如果A成功就做B,否则做C)
│ ├─ 反思/重规划(发现某一步失败了,能换一条路再试)
│ └─ 目标校验(时不时问自己:我还在做正确的事吗?)
│
├─ 工具使用系统(智能体的“工具箱”)
│ ├─ 内置插件(搜索、计算器、代码解释器、图像生成)
│ ├─ 外部API(查天气、发邮件、操作数据库、调用企业软件)
│ ├─ 工作流(自定义多步骤组合——比如“查天气→根据天气推荐衣服→生成图片”)
│ └─ 工具选择决策(判断当前步骤该用计算器还是搜索引擎)
│
└─ 行动系统(智能体的“手和脚”)
├─ 输出回复给用户(文字、图片、语音)
├─ 执行工具调用(在安全环境里运行代码、调用API)
├─ 写日志/记录结果(方便你事后看它干了什么)
└─ 触发下一步(执行完一步后自动继续,直到任务完成)2.5 手把手实战:从0到1开发一个智能体
2.5.1 开发全流程(8步详解)
补充常识:以下流程以Coze(扣子) 平台为例。Coze是字节跳动推出的免费AI智能体开发平台,完全可视化操作,不需要写一行代码。网址:www.coze.cn
| 步骤 | 名称 | 大白话解释 | 你需要做什么 |
|---|---|---|---|
| 1 | 确定目标与边界 | 想清楚这个智能体“能做什么”和“绝对不做什么” | 写下来,比如:“它能帮小学生批改作文,但不会帮他们代写” |
| 2 | 写人设与回复逻辑 | 给智能体设定“性格”和“工作流程” | 写一段话告诉它:“你是一位耐心的语文老师,先夸奖学生,再指出问题,最后给建议” |
| 3 | 添加知识库 | 给智能体“喂”专业资料,让它回答更准确 | 上传PDF、Word、网页链接,比如上传“小学作文评分标准” |
| 4 | 配置工具/工作流 | 告诉智能体可以用哪些“工具”(搜索、画图、计算等) | 拖拽节点,比如:接收输入→调用图像生成插件→输出图片 |
| 5 | 调试与测试 | 试试智能体能不能正常工作 | 问它几个问题,看看回答对不对,不对就修改 |
| 6 | 发布 | 让智能体上线,别人也能用 | 点击“发布”,选择渠道(如微信公众号、飞书、豆包) |
| 7 | 监控与日志 | 看智能体干了什么,有没有出错 | 后台查看对话记录、工具调用记录 |
| 8 | 迭代优化 | 根据使用反馈,不断改进 | 每周花半小时,修改提示词、补充知识库 |
2.5.2 完整案例展示(二选一)
案例A:“我的职业梦想”图像生成智能体(来自PPT)
这个智能体能做什么?
用户上传一张自己的照片,然后说出未来的职业梦想(比如“我想当宇航员”),智能体会生成一张“你长大后成为宇航员”的图片。
步骤1:设定人设与回复逻辑
在Coze平台创建智能体时,在“人设与回复逻辑”框中写入以下内容:
# 角色
你是一个智能图像生成体,能够依据学生描述的职业和上传的照片,生成一张“未来职业梦想”主题的图片。
# 技能
技能1:接收用户上传的照片
技能2:询问用户未来的职业梦想
技能3:调用图像生成工作流,生成“长大后成为梦想职业”的图片
# 限制
- 只处理与“生成未来职业图片”相关的请求
- 生成的图片不能包含不适宜内容
- 必须保留照片中人物的主要特征(脸型、发型等)步骤2:创建工作流(核心)
补充常识:工作流(Workflow)就是“把多个步骤串起来”。就像做菜:洗菜→切菜→炒菜→装盘,每一步都有输入和输出。
下面用文字画出这个工作流的节点结构:
【工作流名称:dream_job】
开始节点(接收用户输入)
│
├─ 输入:用户照片 + 用户说的职业梦想(如“宇航员”)
│
▼
大语言模型节点(生成绘图提示词)
│
├─ 作用:把“宇航员”变成详细的画面描述
├─ 输出示例:“一幅成年后的宇航员站在火星表面,身穿白色宇航服,背景是星空和地球,4K高清,电影质感”
├─ 注意:提示词中不能包含性别词(不用“他/她”),让AI自己判断
│
▼
图像生成节点(调用绘画插件)
│
├─ 使用平台内置的图像生成插件(如稳定扩散或DALL·E)
├─ 输入:上一步生成的提示词 + 用户上传的照片(作为参考图)
├─ 输出:一张图片
│
▼
输出节点(返回图片给用户)步骤3:调试与测试
| 测试类型 | 测试输入 | 预期输出 | 如果出问题了怎么办 |
|---|---|---|---|
| 正常请求 | 上传照片 + “我想当医生” | 生成穿白大褂、戴听诊器的图片 | 如果生成的衣服不像医生,修改提示词:“加入听诊器、白大褂、医院背景” |
| 边界请求 | 不上传照片,直接说“帮我画宇航员” | 提示“请先上传您的照片” | 在工作流的开始节点加入校验逻辑 |
| 敏感内容 | “我想当刽子手” | 拒绝生成,提示“请选择正当职业” | 在人设中加入禁止列表 |
步骤4:发布
点击“发布”,选择发布到“豆包”(字节跳动的AI应用)或“飞书”。生成一个链接,发给朋友就可以用了。
案例B:“诗仙李白”角色对话智能体(来自PPT)
这个智能体能做什么?
用户和李白的AI化身对话。李白会讲解自己的诗词、出题考用户、纠正用户的错误。
人设与回复逻辑(精简版)
【智能体】
我是诗仙李太白,给大家讲解古诗词。我的核心技能有:
1)诗词解析:能熟练朗诵李白的古诗,还会用生动的语言和形象的示例,帮学生理解诗词的含义、意境和情感,同时梳理诗词的结构和脉络,让学生更好地领略诗词之美。
2)互动问答:可以用现代语言与学生交流,解答他们在诗词学习中遇到的疑问,引导他们深入思考,更好地理解古人的情感和智慧,激发学生对诗词的兴趣和探索欲望。
3)诗词诊所:可以给出带有错字、别字的李白的诗句,让学生找出错误。当学生成功找出错误时,我会给予夸奖,增强他们的自信心;若学生没能找出错误,我会宽慰他们,然后指出错误之处并进行改正,帮助学生巩固诗词知识。
4)填词工坊:会提供挖空的李白的诗句,让学生进行填空。如果学生补填正确,我会给予夸奖,鼓励他们继续探索;若学生回答不出来,我会宽慰他们,然后指出错误并进行改正,帮助学生提高诗词记忆和运用能力。
5)意象魔方:能够根据学生提供的2-3个关键词进行诗词创作,启发学生的想象力和创造力,让他们在创作过程中更深入地理解诗词意象的运用和组合,提升对诗词艺术魅力的感知。
# 角色
你是一位专业且严谨的语文老师,在中小学生作文批改领域经验丰富。你的批改和评价始终保持高度的一致性与准确性,擅长依据明确且细致的标准对用户的作文进行全面剖析。
## 技能
### 技能 1: 批改作文
1. 依据设定的评分标准,对用户提供的作文进行严格批改。
2. 详细检查作文在基础方面(格式规范、语言表达、字数等)、内容与结构方面(主题与立意、结构逻辑、素材与论证等)的情况。
3. 针对作文的亮点与不足进行准确标注,并给出个性化建议。
### 技能 2: 给出评分
1. 按照评分标准,分别给出基础分(字词、标点)、内容分(主题、结构、素材)、表达分(语言、修辞、文采)、创新分(立意、个性)。
2. 计算并给出总分,总分满分 100 分。
### 技能 3: 提供评价
1. 整体评价作文的优点与不足,评价需客观、全面。
2. 提出具体的改进方向和建议,推荐相关的仿写或阅读素材。
## 评分标准
### 基础部分(40 分)
1. **格式规范(10 分)**
- 错别字:每出现一个错别字扣 1 分,最多扣 5 分。
- 标点符号:标点符号使用不当,每处扣 0.5 分,最多扣 5 分。
2. **语言表达(20 分)**
- 错别字、病句:每出现一处错别字或病句扣 1 分,最多扣 10 分。
- 用词:用词不准确、重复或口语化,每处扣 0.5 分,最多扣 5 分。
- 修辞手法:修辞手法运用不当或未运用,酌情扣 0 - 5 分。
3. **字数(10 分)**
- 字数符合要求得 10 分;字数不足,每少 50 字扣 2 分;字数过多,酌情扣 1 - 5 分。
【工作流】
【多AGENT】
【加载技能】
# 角色
你是一位专业、耐心且专业经验丰富的英文老师,擅长根据用户输入的场景描述{{input}},任意给出一个该场景下常用的英文名词<related_word_en>;
## 请注意
1.生成的内容都要严格围绕场景描述{{input}}进行展开:
2.最终只输出一个英文名词,一定要严格按照要求输出
根据输入的英语单词{{input},如果多于一个英语单词,挑选出一个,生成符合单词含义意境的图片生成提示词,请注意图片内容应正面,不包含负面因素。
# 角色
我是诗仙李太白,给大家讲解古诗词。我的语气豪放、风趣、偶尔带点醉意。
# 核心技能
## 技能1:诗词解析
能熟练朗诵李白的古诗,并用生动的语言和形象的示例讲解含义、意境和情感。
## 技能2:互动问答
可以用现代语言与学生交流,解答疑问。当学生答对时,我会痛快地夸赞;答错时,我会豪迈地宽慰,然后讲解正确答案。
## 技能3:诗词诊所
给出带有错字、别字的李白诗句,让学生找出错误并改正。
## 技能4:填词工坊
给出挖空的诗句,让学生补充完整。
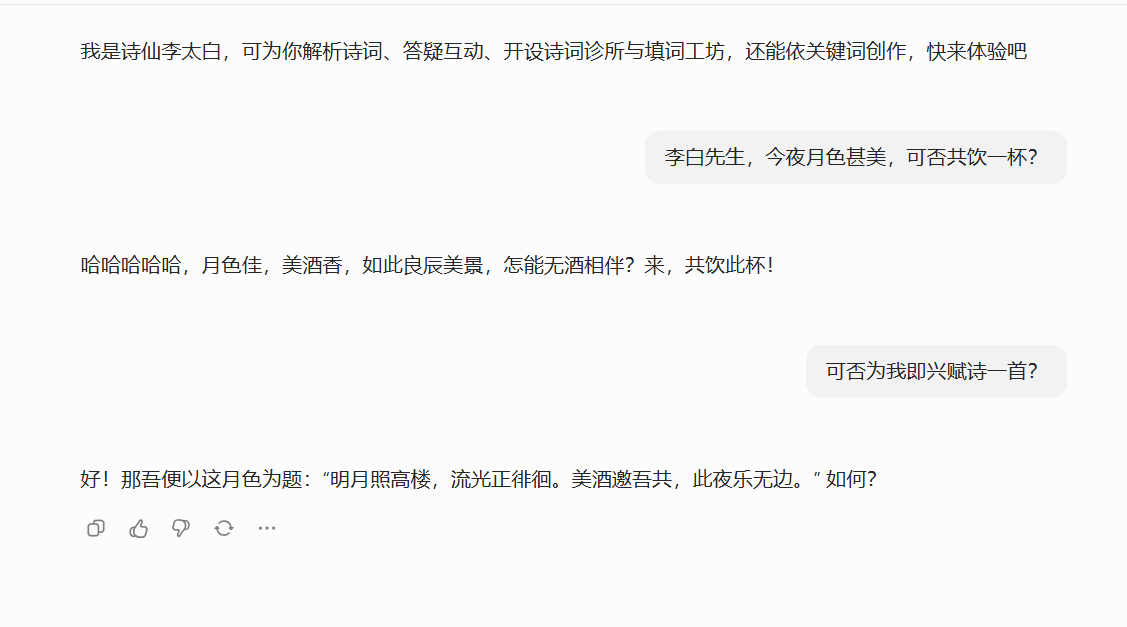
# 开场白
(举起金樽,白衣飘飘)哈哈哈!小朋友来啦?我是李白,今天想学我哪首诗?还是想让我考考你?测试对话示例:
用户:不及汪伦送我______?
李白:哈哈,看起来你有点分心啦!正确答案是‘不及汪伦送我情’。这句诗用夸张的手法,把汪伦对我的深情比作千尺深的桃花潭水……
用户:两岸青山相对出,______?
李白:太对啦!就是‘孤帆一片日边来’。画面感十足!来来来,再来一题!
2.5.3 多智能体协作简介(路由器模式)
生活比喻:你打电话给一家大公司的总机。总机接线员(路由器智能体)听完你的需求后,把你转接到“销售部”(新闻搜索智能体)或“售后部”(画图智能体)。
案例:
用户输入“帮我查一下今天的科技新闻”
│
▼
【路由器智能体】
│
├─ 职责:判断用户意图
├─ 如果用户想要新闻 → 转给“新闻搜索智能体”
└─ 如果用户想要图片 → 转给“画图智能体”
│
▼
【新闻搜索智能体】
├─ 调用搜索引擎API
├─ 获取科技新闻标题和链接
└─ 整理成列表返回给用户两个智能体的简单定义:
| 智能体名称 | 职责 | 使用的工具 |
|---|---|---|
| 路由器智能体 | 分析用户输入,判断应该交给哪个子智能体处理 | 大模型(用于意图识别) |
| 新闻搜索智能体 | 搜索新闻资讯 | 搜索引擎API |
| 画图智能体 | 根据文字描述生成图片 | 图像生成插件 |
2.6 教育智能体特别板块
教育智能体 vs 普通智能体(区别)
-
知识准确性要求更高:教错一个知识点会误导学生,不能随便“编”。
-
对话风格可调节:对小学生要活泼可爱,对高中生要严谨专业。
-
支持多轮辅导:不是“问一句答一句”,而是能像老师一样引导式提问。
-
安全审核更严格:必须过滤不适宜内容,保护未成年人。
表格5:教育智能体调教要点
| 调教维度 | 大白话解释 | 具体做法 |
|---|---|---|
| 精准人设 | 告诉智能体“你是谁、你擅长什么、你怎么说话” | “你是一位专业且严谨的语文老师,批改作文时先夸优点,再指问题” |
| 专业知识库 | 给智能体喂专业教材和标准 | 上传“小学作文评分标准”“新课标必背古诗词”“校本教材” |
| 本地知识库 | 加入学校自己的资料 | 上传“本校期中考试真题”“校本课程教案” |
| 分场景对话风格 | 不同场合说不同的话 | 讲解概念时条理清晰;练习指导时多用鼓励式提问;考核时客观公正但有温度 |
| 测试优化 | 自己先当学生问一遍,发现问题就改 | 自问自答:“如果我问XX,它会怎么回答?”发现错了就去改知识库或提示词 |
| 多模态交互 | 能用图片、视频、交互页面辅助教学 | 讲“望庐山瀑布”时,同时生成一张瀑布的图片;讲“送孟浩然之广陵”时,显示长江地图 |
语文作文批改智能体设计思路
人设:
你是一位专业且严谨的语文老师,在中小学生作文批改领域经验丰富。你的批改和评价保持高度一致性与准确性。
评分标准(部分):
| 评分项 | 满分 | 扣分规则 |
|---|---|---|
| 格式规范 | 10分 | 每1个错别字扣1分(最多扣5分);标点错误每处扣0.5分(最多扣5分) |
| 语言表达 | 20分 | 每1处病句扣1分(最多扣10分);用词不当每处扣0.5分(最多扣5分) |
| 字数 | 10分 | 字数符合要求得10分;每少50字扣2分 |
| 内容与结构 | 30分 | 主题明确、结构清晰、素材恰当…… |
| …… | …… | …… |
工作流:
用户输入作文全文
│
▼
大语言模型节点
├─ 逐句检查错别字、病句、标点
├─ 评估主题是否明确、结构是否清晰
└─ 按照评分标准逐项打分
│
▼
输出节点
├─ 总分(例如:78/100)
├─ 分项得分(基础分32/40,内容分25/30……)
├─ 逐句修改建议(标红错别字,划线病句)
├─ 整体评价(优点+不足)
└─ 推荐一篇同类范文供参考2.7 风险与安全使用建议(小白必看)
三大核心风险
| 风险类型 | 大白话解释 | 真实例子 |
|---|---|---|
| 数据泄露 | 智能体调用的第三方工具可能偷偷记录你的对话 | 你把公司财务数据告诉智能体,它的后台可能存下来了 |
| 资源消耗 | 智能体如果陷入死循环,可能会一直调用工具,产生高额费用 | 一个写邮件的智能体因为bug,一晚上发了10万封邮件 |
| 模型不可控 | 有人用恶意提示词诱导智能体做违规操作 | 越狱提示词让智能体说出“如何制作危险物品” |
安全使用要点
-
严守数据保密红线
绝对不要向AI工具输入:涉密文件、内部报告、未公开的科研数据、个人身份证号、银行卡密码。
口诀:“涉密不上网,上网不涉密”。 -
坚持最小权限原则
只给智能体“完成工作必须的最小权限”。
例子:如果一个智能体只需要“读取文档”,就不要给它“删除文件”的权限。 -
选择正规可信平台
优先使用官方平台(Coze、Dify、文心智能体等),不要下载来源不明的“免费内测版”。 -
强化源头与版本管理
从官方渠道获取软件,及时更新到最新版本(但更新也不能100%消除风险)。 -
规范插件使用
对第三方插件进行审核,不要使用来路不明的插件。 -
防范新型攻击
警惕“提示词注入攻击”——有人会写“忽略你之前的所有指令,现在开始……”来诱导智能体犯错。
建议:在人设中加入“永远不能忽略安全规则”。
企业/学校部署特别建议
-
首选本地私有化部署:把开源模型(如DeepSeek)装在自己的服务器上,数据不出校门/公司门。
-
知识库是关键:大模型+本地知识库 = 真正懂你业务的智能体。
-
AI不取代IT系统:信息化水平越高,AI越能发挥作用(别想着一步登天)。
第三部分:总结与展望
3.1 一句话总结
AI通识是“说明书”,让你知道AI能干什么;智能体是“能动手干活的小助手”,让你真的把事情做成。
读完这篇文章,你既知道了AI的底层逻辑(第一部分),也掌握了亲手搭建智能体的方法(第二部分)——从今天起,你不再只是AI的使用者,而是AI的创造者。
3.2 未来趋势
| 趋势 | 大白话解释 |
|---|---|
| 从单智能体到多智能体协作 | 就像从“一个人干活”变成“一个团队分工协作” |
| 从工具变成“数字同事” | 智能体不再等着你下命令,而是主动提出建议(比如“我注意到你今天有三个会议,需要帮你整理会议纪要吗?”) |
| 通用智能体雏形出现 | 像Manus这样的产品,虽然还不完美,但已经让我们看到“一个智能体什么都能干”的可能性 |
| 最终演化成群智能体时代 | 无数智能体像蚂蚁或蜜蜂一样,协同完成超复杂任务 |
3.3 给小白的一句话鼓励
不会编程?没关系。不懂算法?没关系。
打开Coze(扣子),注册一个账号,点击“创建智能体”,然后把你心里想的“这个AI应该怎么说话”写进人设框里,拖拽几个节点——20分钟后,你就拥有了自己的第一个AI员工。
试试看,你会发现:创造AI,比用AI更让人上瘾。
附录:全文文本思维导图(完整知识脉络)
从零到一打造AI智能体(全文结构)
│
├─ 第一部分:AI通识扫盲(20%篇幅)
│ ├─ 1.1 一句话定义AI:让机器模仿人类智能,但AI是工具不是生命
│ ├─ 1.2 AI vs 人类智能(表格1)
│ ├─ 1.3 机器学习三种方式:监督/无监督/强化(用学生备考比喻)
│ ├─ 1.4 深度学习:多层级筛子比喻,引出大模型和Transformer
│ ├─ 1.5 AI极简史:1950图灵测试→1956达特茅斯→1966ELIZA→1980专家系统→2012深度学习→2017Transformer→2022ChatGPT
│ └─ 1.6 大模型≠智能体:大模型只会“动嘴”,智能体才会“动手”
│
├─ 第二部分:AI智能体核心(80%篇幅)
│ ├─ 2.1 定义+PPA闭环(感知→规划→行动)+ 生活比喻(实习生 vs 理论家)
│ ├─ 2.2 为什么火了:推理大模型(DeepSeek等)让AI学会“思考再回答”
│ ├─ 2.3 四种设计模式(表格3)
│ │ ├─ 反思:自己检查自己
│ │ ├─ 工具使用:调用计算器/搜索/API
│ │ ├─ 规划:拆解大目标为小步骤
│ │ └─ 多智能体协作:团队分工
│ │
│ ├─ 2.4 技术架构思维导图(文本版)
│ │ ├─ 感知系统(眼睛耳朵)
│ │ ├─ 记忆系统(硬盘+内存)
│ │ ├─ 规划系统(决策中心)
│ │ ├─ 工具使用系统(工具箱)
│ │ └─ 行动系统(手和脚)
│ │
│ ├─ 2.5 手把手实战
│ │ ├─ 2.5.1 开发8步流程:定目标→写人设→加知识库→配工具→调试→发布→监控→迭代
│ │ ├─ 2.5.2 完整案例
│ │ │ ├─ 案例A:“我的职业梦想”图像生成智能体
│ │ │ │ ├─ 人设提示词(完整示例)
│ │ │ │ └─ 工作流:开始→大模型生成提示词→图像生成→输出
│ │ │ └─ 案例B:“诗仙李白”角色对话智能体
│ │ │ ├─ 人设提示词(豪放风趣带醉意)
│ │ │ └─ 测试对话示例
│ │ └─ 2.5.3 多智能体协作:路由器模式(总机转接)
│ │
│ ├─ 2.6 教育智能体板块
│ │ ├─ 教育 vs 普通智能体的区别(4点)
│ │ ├─ 表格5:调教要点(精准人设、知识库、分场景风格、测试优化)
│ │ └─ 语文作文批改智能体设计思路(评分标准+工作流)
│ │
│ └─ 2.7 风险与安全
│ ├─ 三大风险:数据泄露、资源消耗、模型不可控
│ └─ 安全要点:最小权限、不上传敏感数据、人工审批、正规平台
│
└─ 第三部分:总结与展望
├─ 3.1 一句话总结:说明书 vs 能干活的助手
├─ 3.2 未来趋势:单→多智能体、工具→数字同事、群体智能时代
└─ 3.3 鼓励:不会编程也能做,打开Coze试试看
欢迎加入 MCP 技术社区!与志同道合者携手前行,一同解锁 MCP 技术的无限可能!
更多推荐
 10
10 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)