数据库管理-第422期 LM Studio本地LLM运行全攻略(20260423)
数据库管理422期 2026-04-23
数据库管理-第422期 LM Studio本地LLM运行全攻略(20260423)
作者:胖头鱼的鱼缸(尹海文)
Oracle ACE Pro: Database
PostgreSQL ACE
10年数据库行业经验
拥有OCM 11g/12c/19c、MySQL 8.0 OCP、Exadata、CDP等认证
墨天轮MVP,ITPUB认证专家
圈内拥有“总监”称号,非著名社恐(社交恐怖分子)
WX:胖头鱼的鱼缸
CSDN:胖头鱼的鱼缸(尹海文)
墨天轮:胖头鱼的鱼缸
ITPUB:yhw1809
IFClub:胖头鱼的鱼缸
除授权转载并标明出处外,均为“非法”抄袭

上一篇文章发布后,不少朋友私信询问我本地运行LLM并供AI Agent调用的具体方案。本期就结合ROG 幻 X 2025(128GB 版本)硬件环境,完整演示LM Studio本地部署与运行大语言模型的全流程,方便大家学习使用。
我的硬件介绍可以查看之前文章:
数据库管理-第371期 便携生产力神器——ROG 幻X 2025(20251002)
1 固件更新带来的关键变化
在之前OpenClaw实战文章中我曾提到:当手动指定GPU统一内存为96GB 时,Ollama、LM Studio、llama.cpp均无法正常调用该容量显存,显存分配上限被限制在64GB。
若采用动态统一内存管理,LLM虽能加载到统一内存,但会调用CPU算力,完全无法发挥GPU性能,整体运行效率偏低。而在ROG 幻X 2025更新至最新固件版本后,上述问题得到彻底解决:
更新最新固件后,再使用动态统一内存配置时,LLM就可以正常加载在统一内存中并可以正确使用CPU算力了: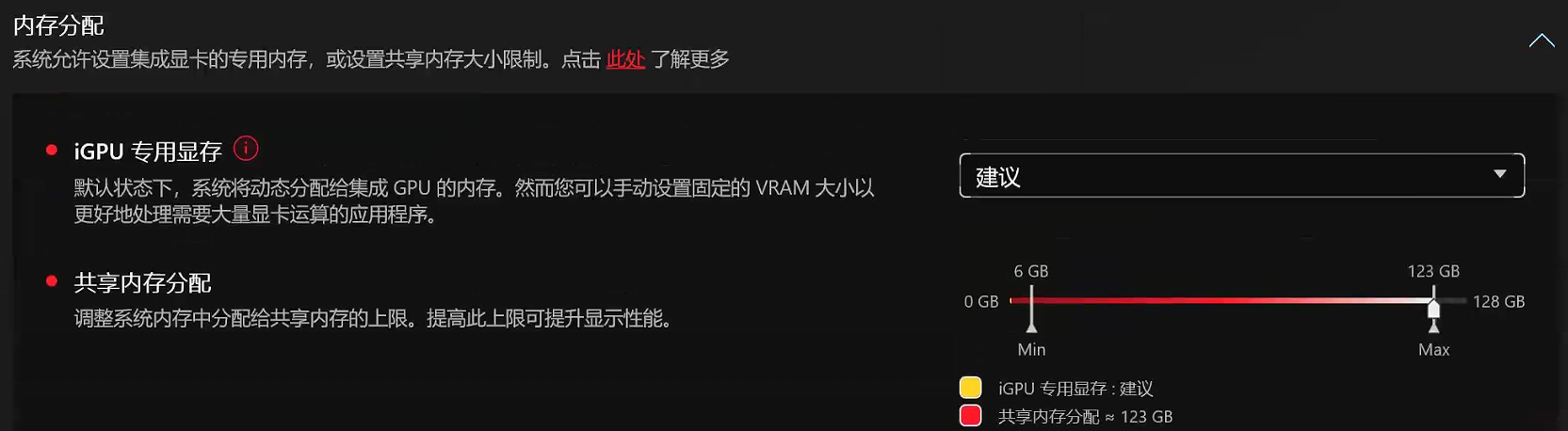
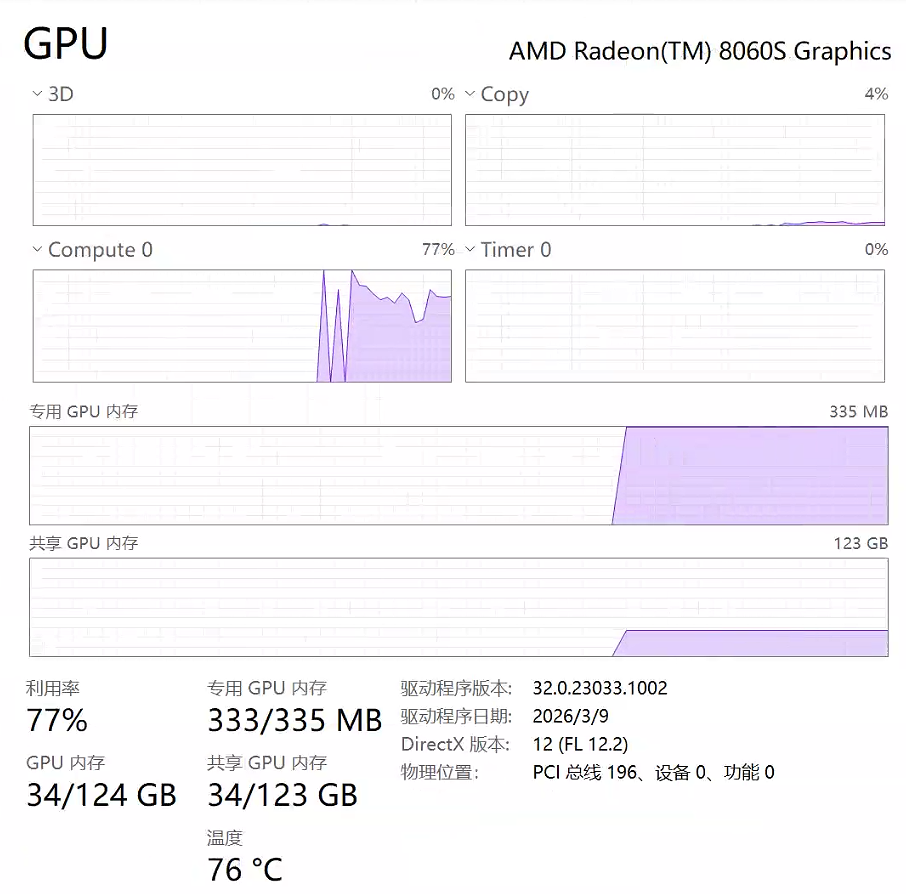
动态统一内存模式下,LLM可正常加载到统一内存,并能使用GPU 算力,无需再手动分配内存大小。同时,统一内存分配硬限制解除后,LLM模型、Embedding模型、Linux虚拟机可同时稳定运行,共同利用内存资源。
2 LM Studio工具介绍
初期我本地运行LLM首选 Ollama,该工具上手简单、操作便捷,但实际使用中存在明显短板:
- 部分版本无法通过Ollama App直接启动LLM,必须依赖ollama命令行执行;
- 运行参数调节入口隐蔽、功能有限,难以最大化利用硬件性能;
- 模型推理速度较慢,大参数模型体验不佳。
因此我全面切换至LM Studio,官方地址,安装对应环境的版本即可:
https://lmstudio.ai/
该工具不仅解决了Ollama的上述问题,还因与AMD深度合作,在AMD硬件平台上兼容性更强、运行更稳定,成为本地LLM部署的优选方案。
3 LM Studio完整配置流程
3.1 软件配置
进入配置页面:点击 LM Studio 左下角配置按钮,打开设置界面:
语言切换:英文基础薄弱的用户可选择简体中文(当前为测试版,部分界面显示未完善,不影响核心功能):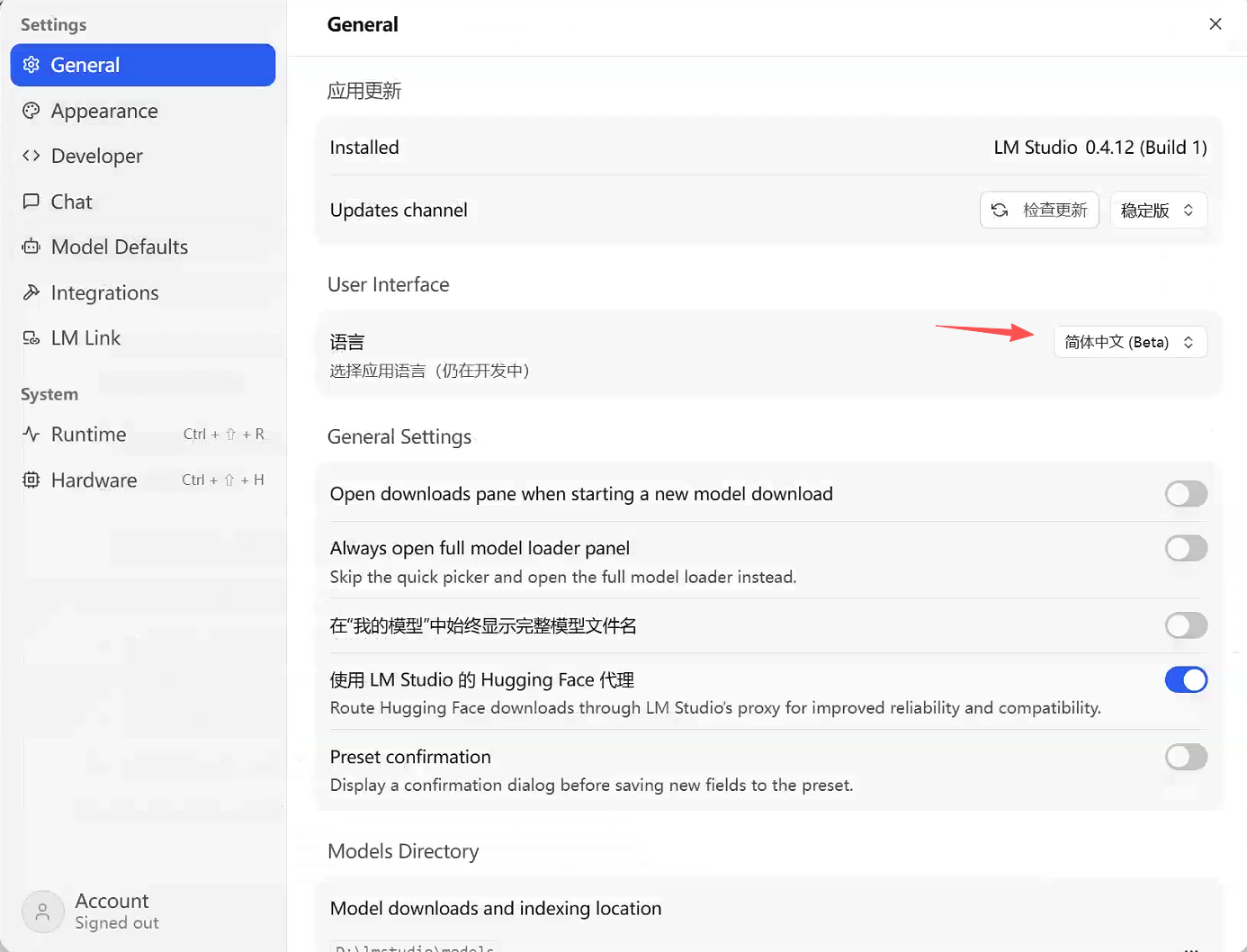
开启开发者模式:打开Developer Mode,解锁Runtime(运行时)等高级配置项: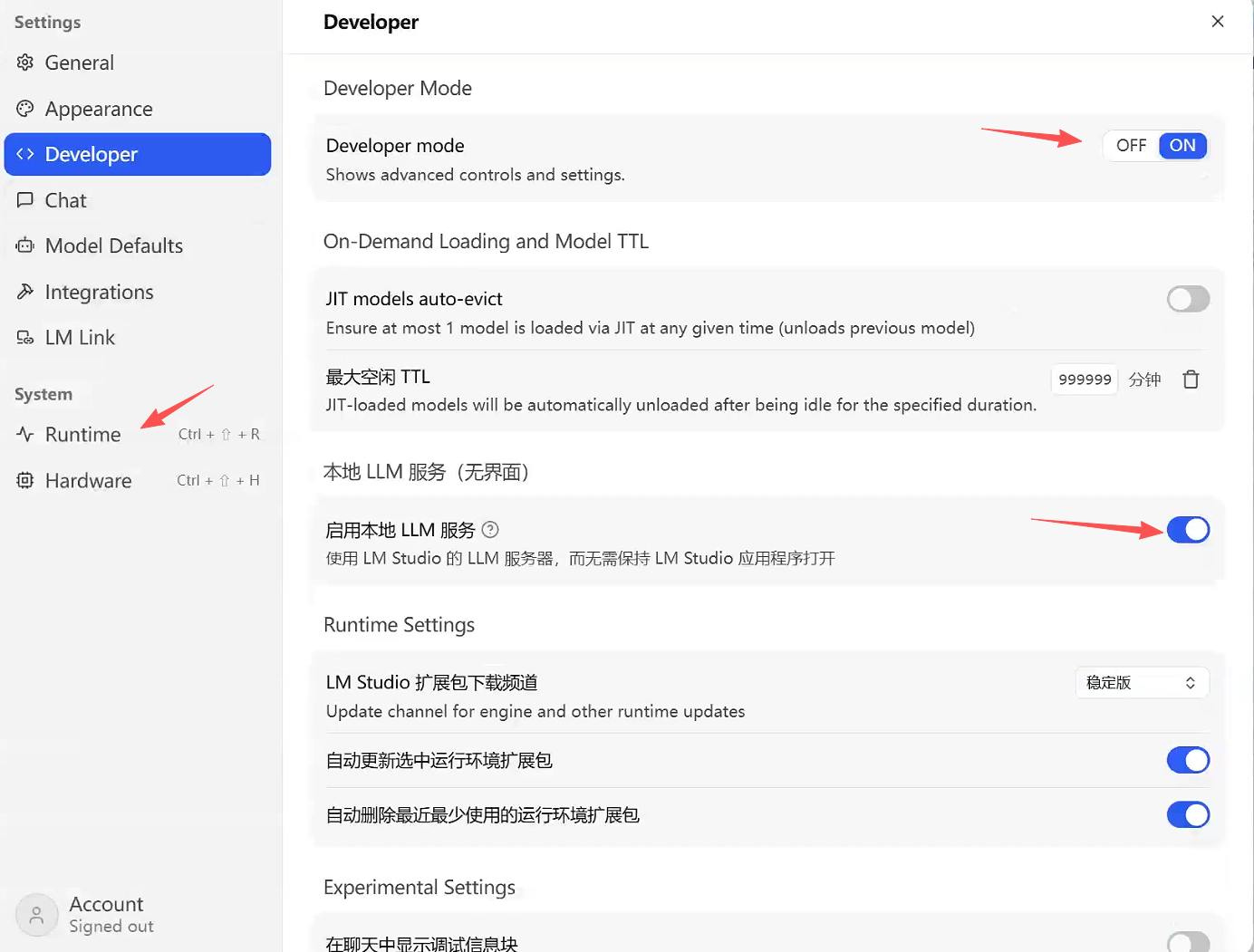
运行时引擎选择:GGUF格式模型默认使用llama.cpp引擎,推荐选择Vulkan而非ROCm——ROCm稳定性较差,二者推理性能几乎无差异;同时可在此页面直接更新llama.cpp版本: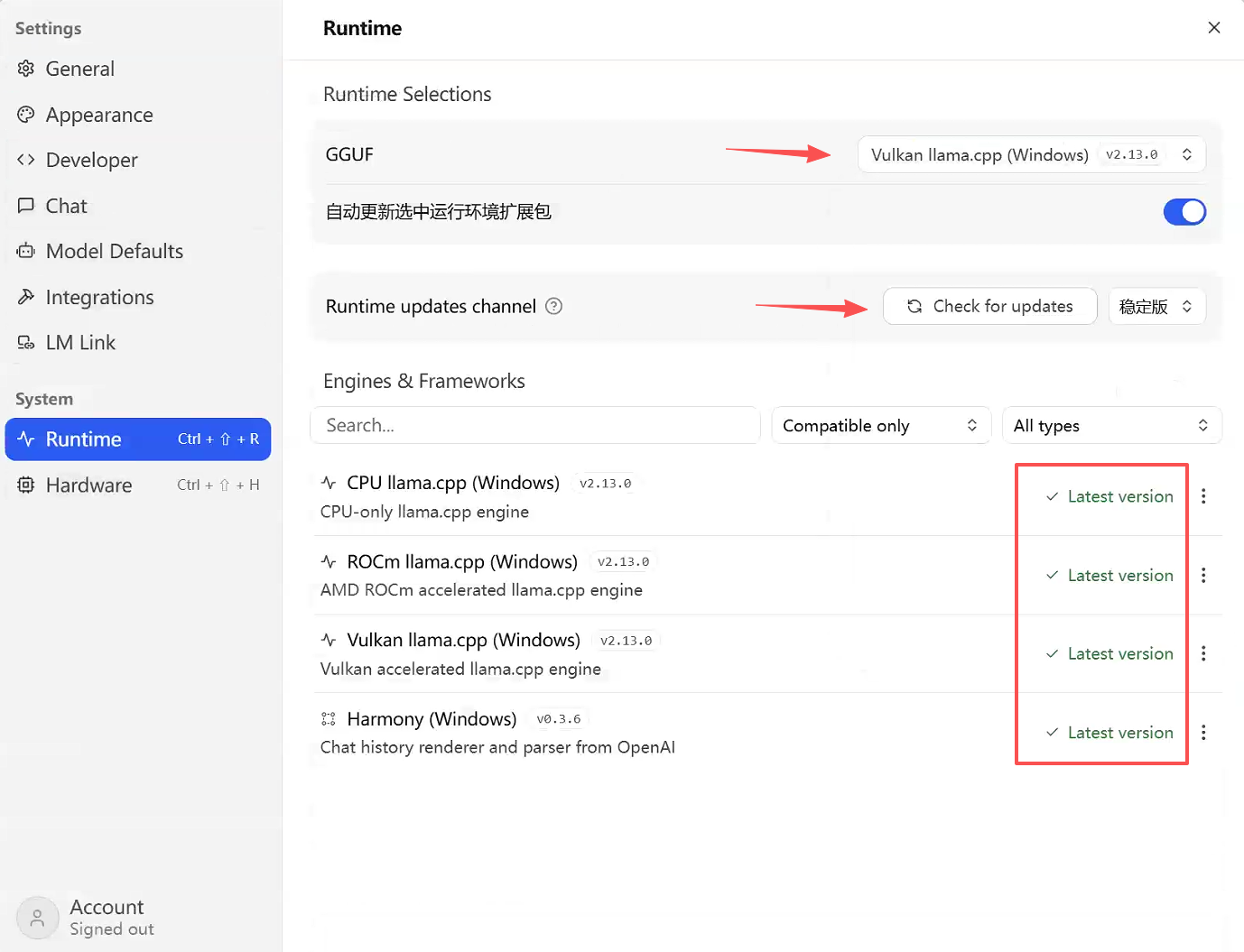
硬件调度设置:在Hardware(硬件)页面,开启GPU加速,实时查看硬件占用状态: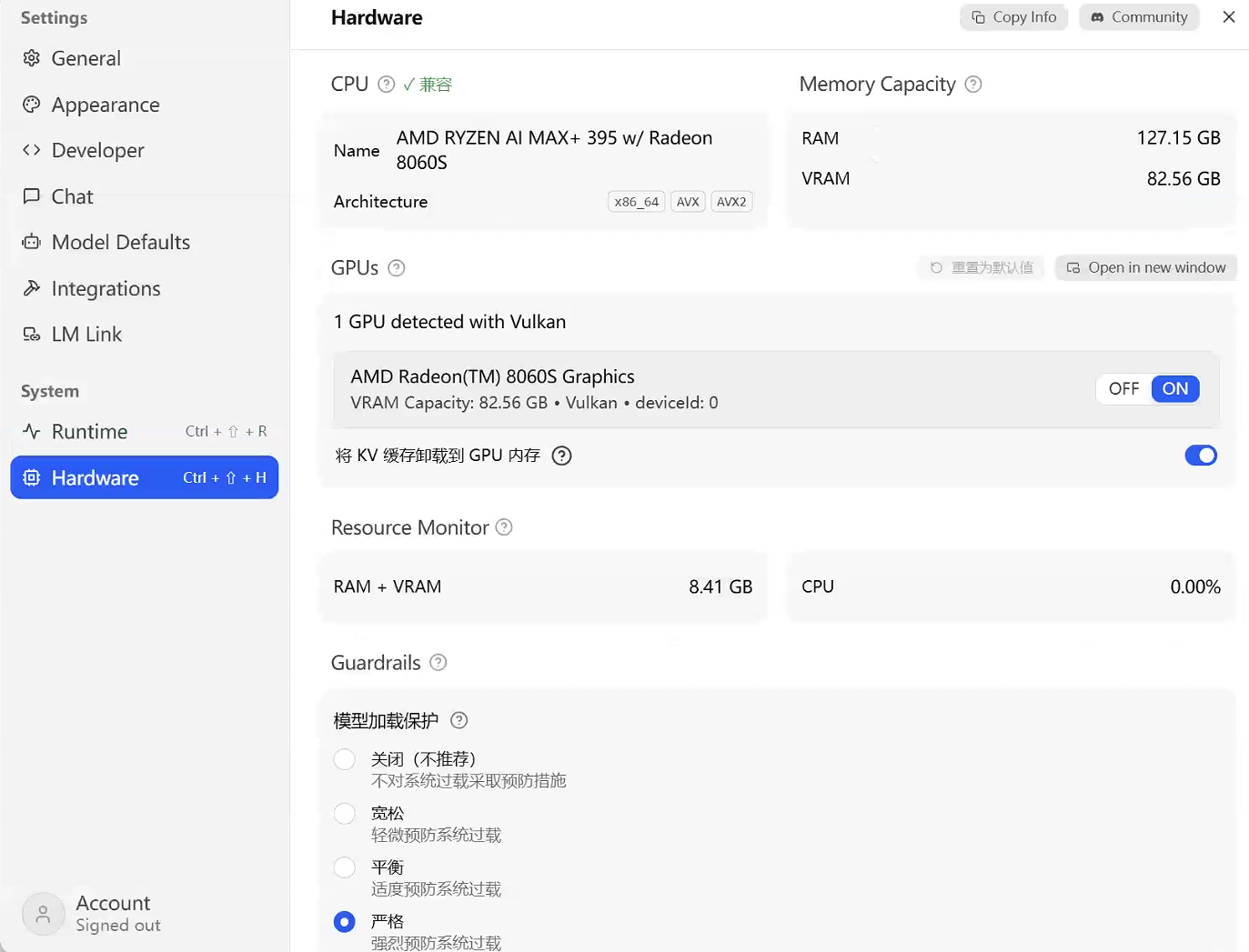
3.2 LLM下载
- 工具内下载:在LM Studio下载页面,工具会自动匹配硬件配置,推荐适配的模型版本;
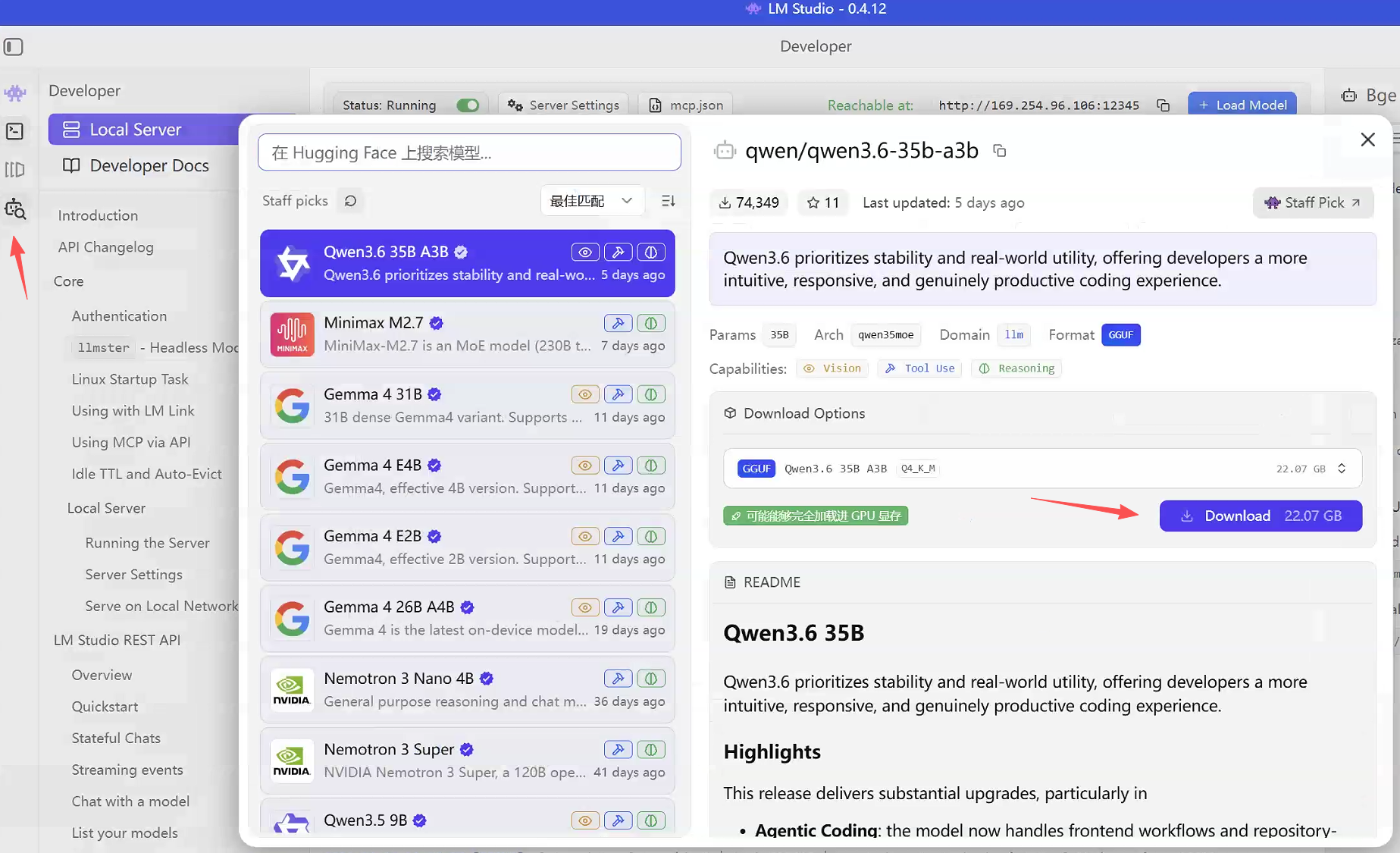
- 手动下载:也可前往Hugging Face(https://huggingface.co/)下载GGUF格式模型,放入软件配置的指定模型存储目录即可识别。
3.3 服务配置
加载模型前需完成服务配置:自定义端口号,开启网络发现功能,支持局域网内其他设备调用该本地LLM服务: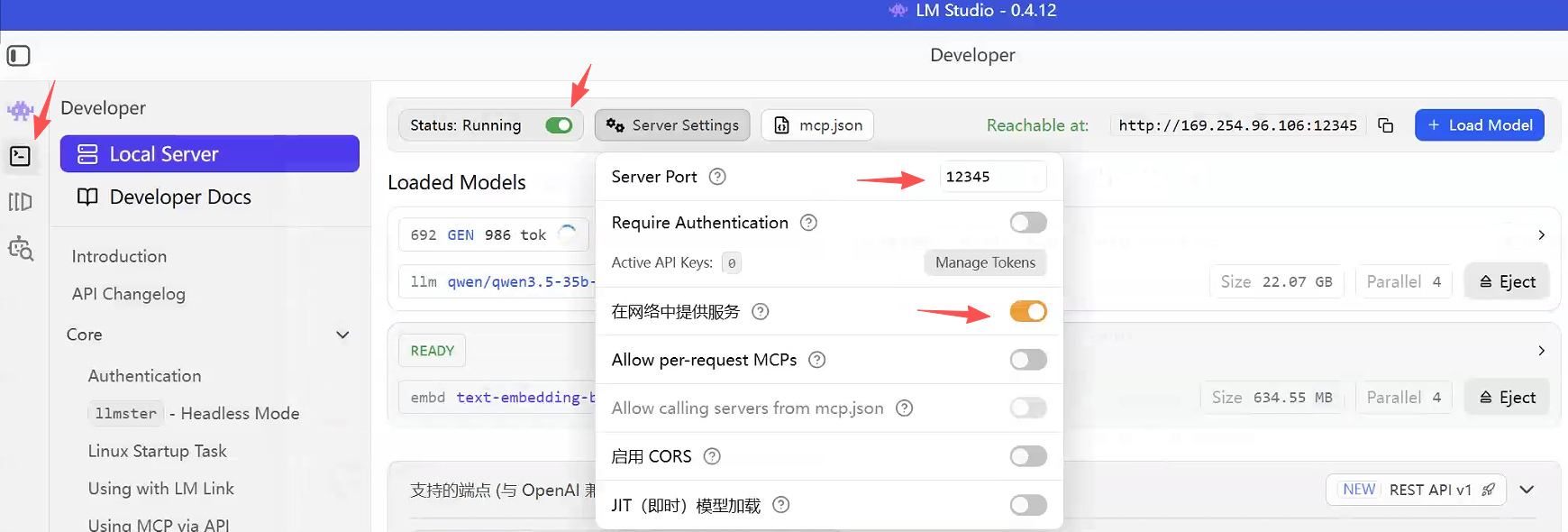
4 LLM模型加载与运行实测
启动LM Studio服务后,点击Load Model加载模型,以下为Qwen3.5系列模型实测配置与性能数据。
通用加载优化建议
- 保持模型支持的最大上下文长度;
- GPU卸载比例拉满,防止模型加载失败;
- 适当降低CPU线程池大小,对推理性能影响极小;
- 适度调大评估批处理大小,减少Prompt加载耗时,避免切片过小,提升GPU利用率;
- 不建议开启mmap (),易导致内存占用异常或运行卡顿。
4.1 qwen3.5-35b-a3b实测
LLM加载配置如下: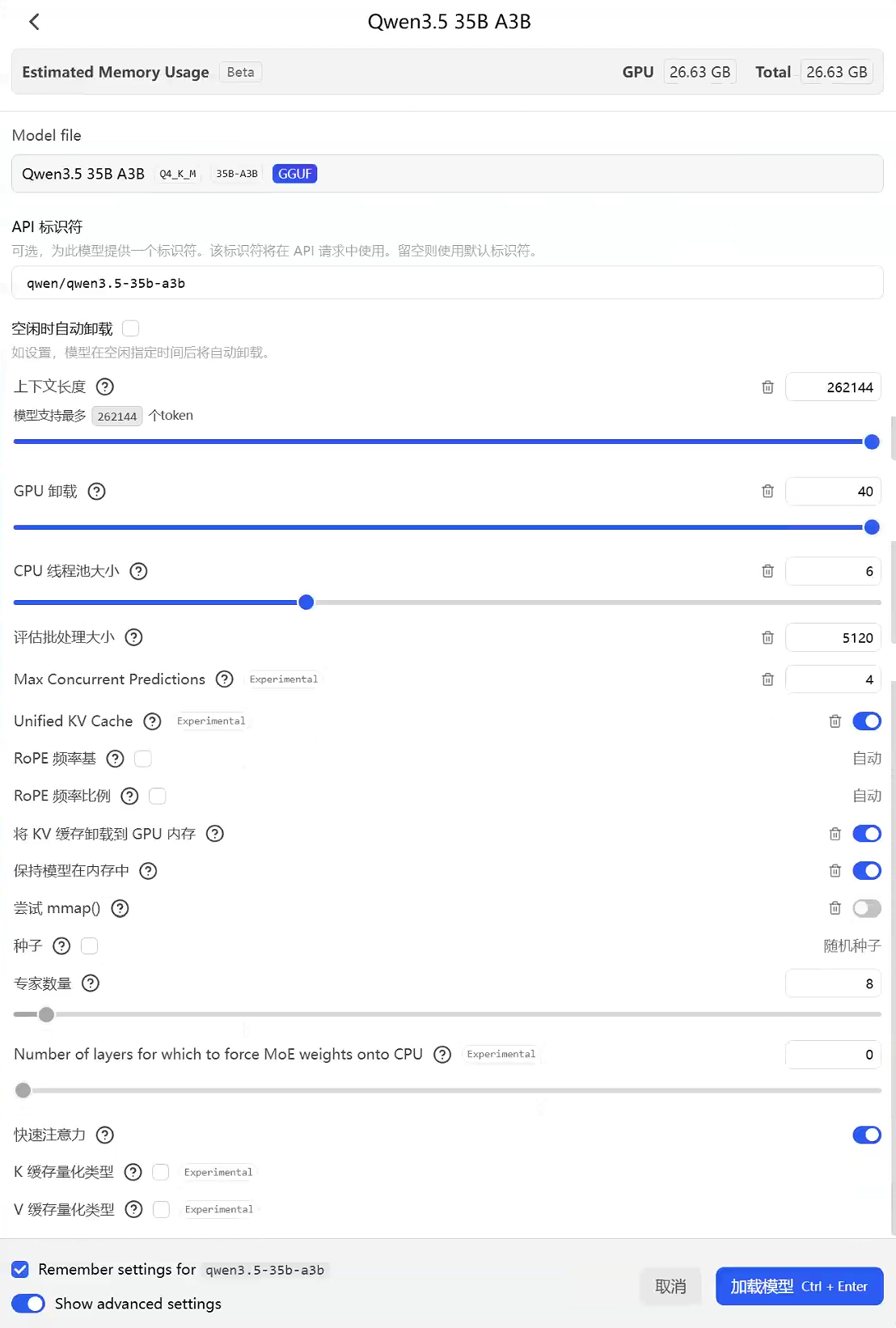
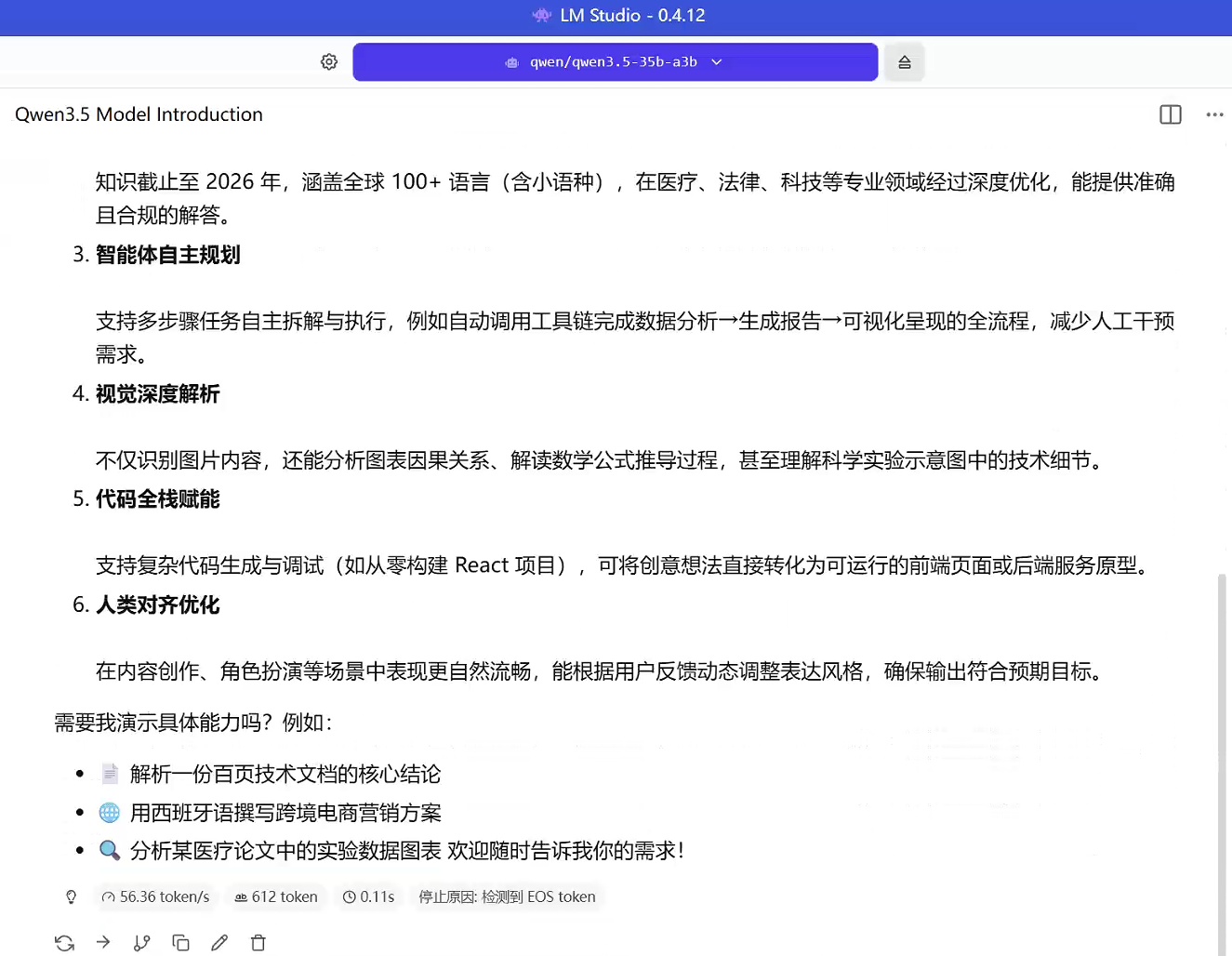
qwen3.5-35b-a3b的推理速度大概是56+Tokens/s。运行状态:流畅稳定,适合日常对话、文本生成等场景。
4.2 qwen3.5-122b-a10b实测
LLM加载配置如下: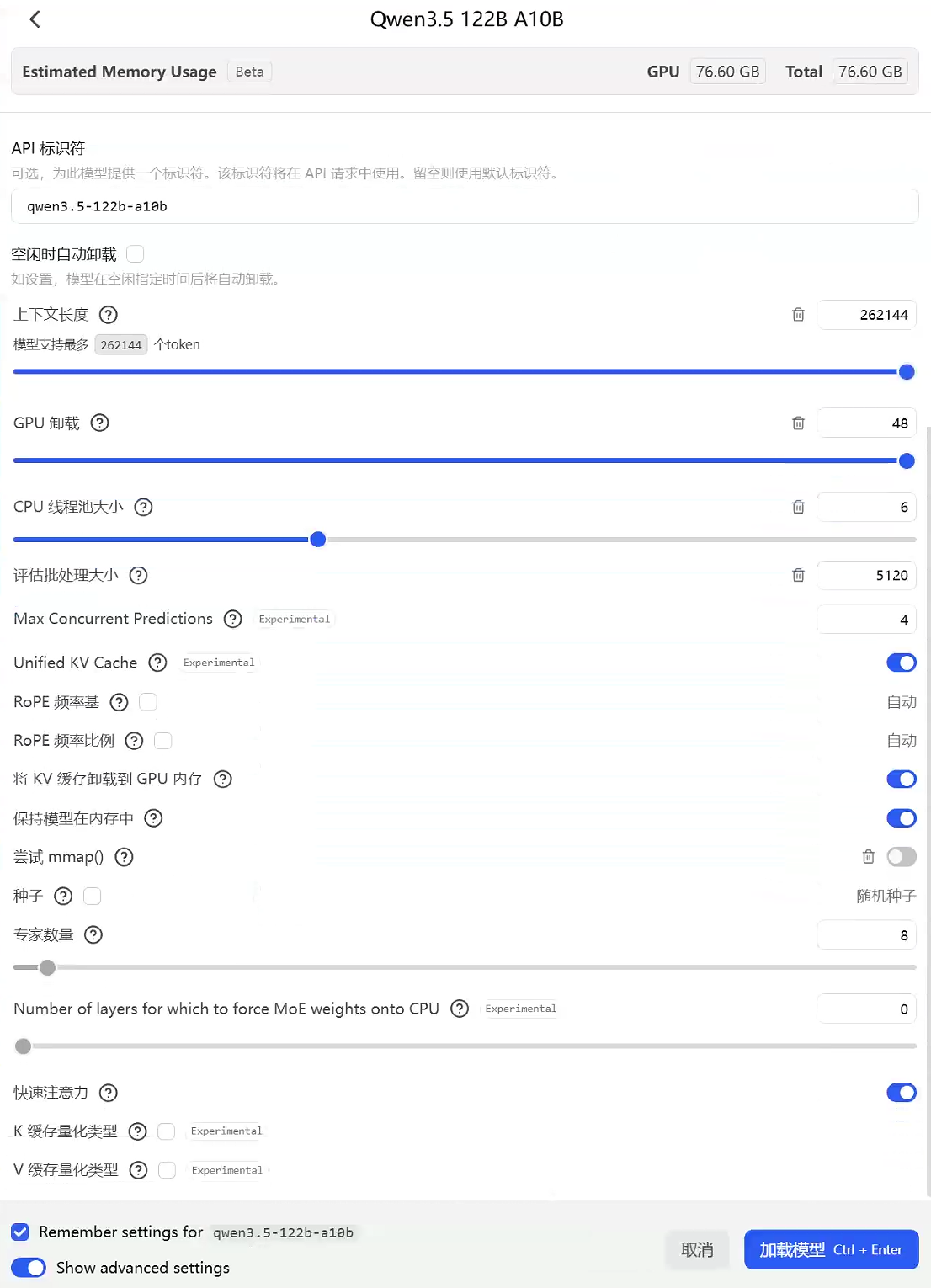
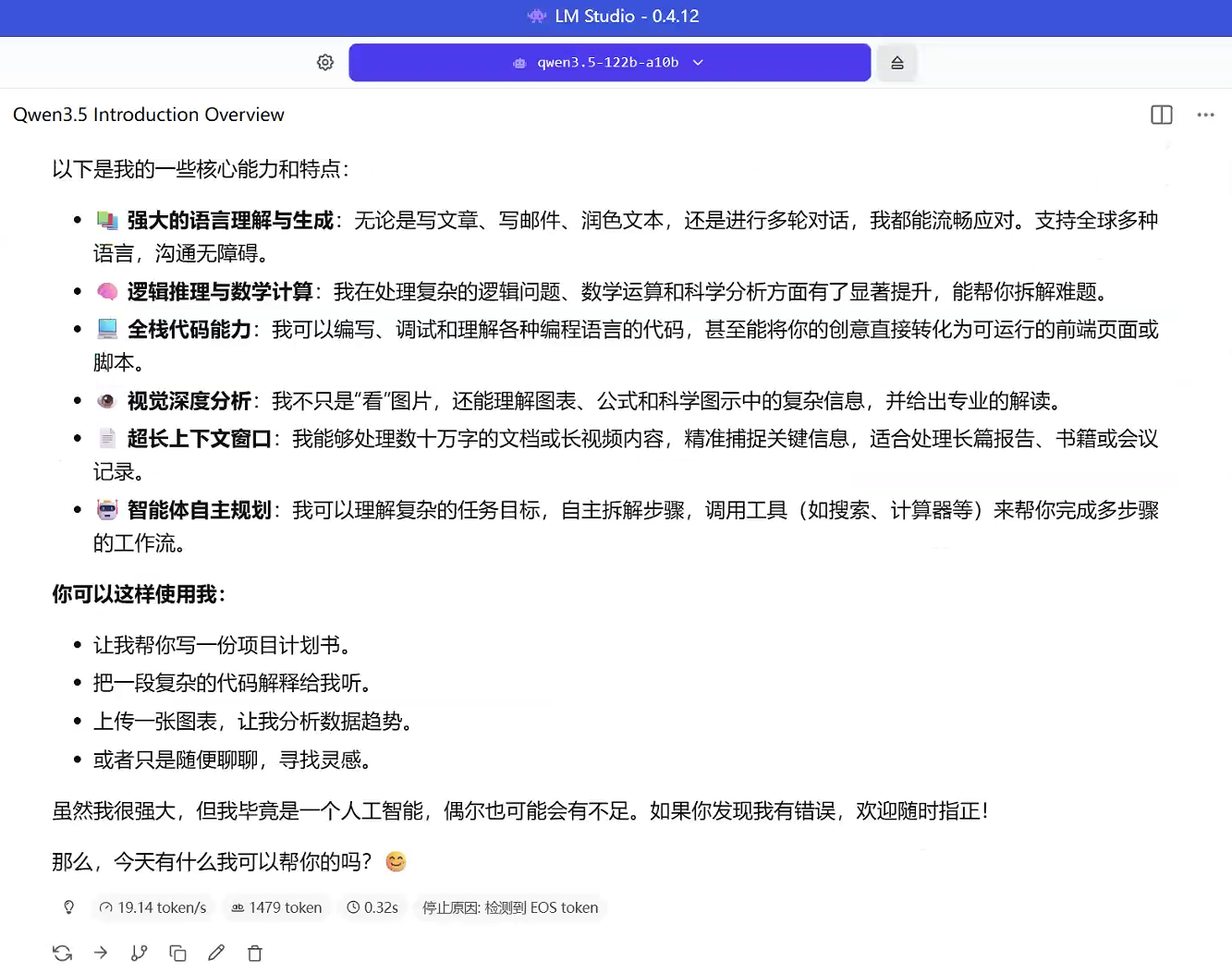
qwen3.5-122b-a10b的推理速度大概是19+Tokens/s。运行状态:速度偏慢,适合对精度要求高、对实时性无强需求的场景。
如需加载Embedding模型,操作方式类似,这里就不做演示了。
总结
本文基于ROG 幻X 2025(128GB 版本)硬件环境,完整演示了LM Studio本地部署、配置、运行LLM的全流程,解决了传统工具的性能与兼容性痛点,可直接用于本地AI Agent调用、离线大模型体验等场景。
老规矩,知道写了些啥。

欢迎加入 MCP 技术社区!与志同道合者携手前行,一同解锁 MCP 技术的无限可能!
更多推荐


 8
8 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)