AST 驱动的 MCP 代码上下文服务在 AI Code Review 中的实践
01
背景与整体架构
在日常研发中,AI 辅助代码审查(Code Review)已被广泛使用,但主流方案多仅依赖 Git Diff,只能看到修改片段,缺少类结构、方法依赖、跨文件调用关系等上下文,模型判断容易失真。跨模块返回值的空安全、多线程下的全局变量风险等细节,往往仍需人工反复核对。为解决这些落地问题,我们基于项目实践搭建了一套 AST(抽象语法树)驱动的方案,通过中间件调度补全完整上下文,为模型提供可追溯的结构化信息,从而稳步提升 AI Code Review 的准确性和可用性。
1.1 项目概述
本项目核心是一套面向企业级研发场景的 AI Code Review 增强方案,以 AST 代码解析技术为核心、以 MCP 服务作为调度与接口层,主要用于缓解 AI 代码审查过程中上下文信息不足的问题。方案思路为:通过 AST 解析工具,结构化提取代码中的类定义、方法实现、变量声明、跨模块调用链路等信息,再借助 MCP 服务将这些结构化上下文进行标准化封装,为大模型提供可检索、可调用的上下文能力,使审查可以基于更完整的代码逻辑开展,而不是仅依赖局部 Diff 片段。目前该方案已完成 Java 语言适配,可集成至现有 Code Review 流程;在主服务中补充少量提示词与工具配置即可完成部署。
1.2 系统架构
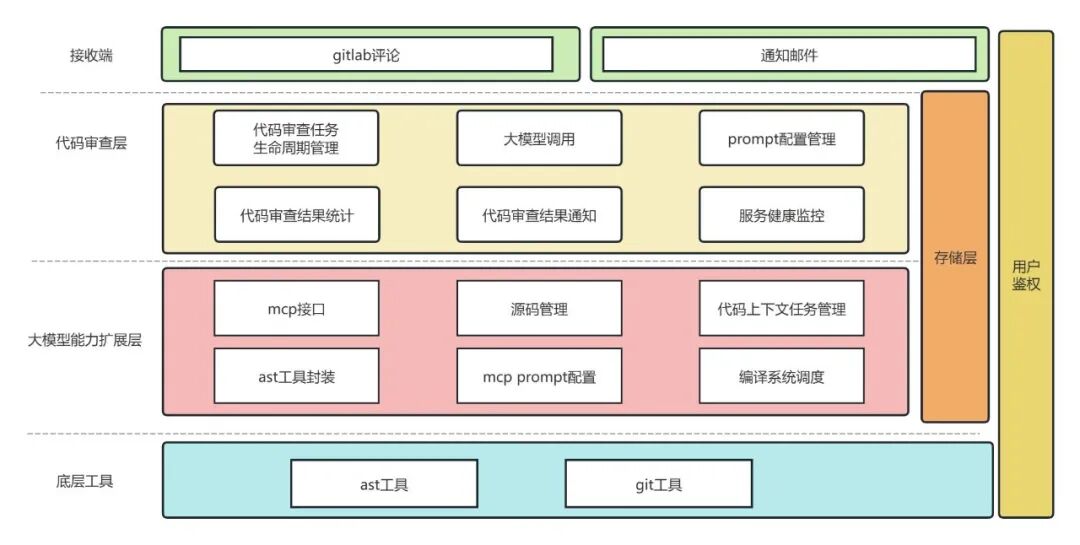
系统后端划分为三层,职责与边界如下:
• 代码审查主服务:作为系统入口,负责发起与编排审查流程,包括接收审查请求、校验参数、调用大模型接口执行审查,以及结果回写与汇总。
• 大模型能力扩展层:基于 MCP 协议(模型上下文协议)封装扩展能力,对外提供统一接口,供大模型在审查过程中按需调用工具与数据。
• 工具层:封装底层能力(如 AST 解析、git操作等),以降低耦合度,便于按模块扩展与替换。
整体采用松耦合设计,便于扩展与维护。后续接入新工具或新增能力时,通常只需在扩展层增加相应封装,并调整相关配置与提示词,无需改动主流程。本文重点介绍扩展层中的代码上下文能力:通过补充 AI Code Review 所需的上下文信息,减少仅凭 Diff 片段带来的信息缺口,提高审查判断的准确性。
02
核心功能模块实现
2.1 核心技术选型及说明
2.1.1 MCP协议
• MCP(模型上下文协议)是 Anthropic 推出的开源标准协议,用于规范大模型与外部工具、数据源的交互格式,减少对接差异。基于 MCP 的封装,通常可以在更换模型时复用既有的工具接口与服务能力。本项目中,MCP 协议用于封装 AST 解析得到的上下文信息,支撑大模型能力扩展层与审查模型的交互。
• 技术选型:采用 Spring AI 实现 MCP 协议,主要考虑其与 Spring 生态的集成成本较低,支持自动配置与依赖注入,减少额外适配代码。同时 Spring AI 提供统一的模型调用抽象层,便于接入与切换不同模型厂商;并提供可观测性与安全等配套能力,方便在生产环境中持续运维。其扩展方式也与系统的松耦合设计相匹配,便于后续功能迭代。
2.1.2 AST解析技术
• AST(抽象语法树)将源代码解析为结构化的语法树节点,便于提取类、方法等关键信息。本项目使用 AST 补充 AI Code Review 所需上下文。
• 技术选型:采用 Eclipse JDT 实现 AST 解析,覆盖 Java 多版本语法,并提供较完整的解析能力与 API。在本项目中,它用于解析源码并生成上下文所需的结构化信息,能够满足对较大规模代码库的处理需求。
2.2 MCP服务核心流程介绍
2.2.1 总体流程介绍
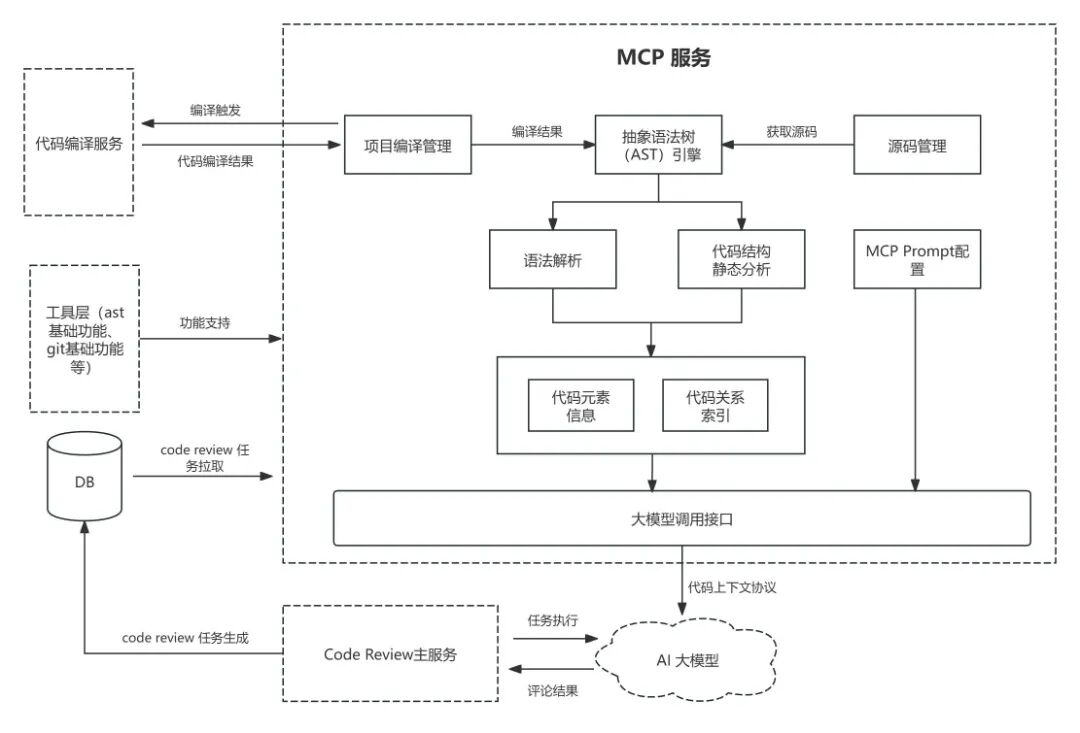
上图展示了 MCP 服务从接收请求到返回上下文的处理链路。服务按模块拆分,职责如下:
• AST 模块:基于项目源码与编译产物进行语法分析与结构解析,构建代码引用关系索引;支持按行号定位代码元素类型,并查询调用/被调用关系与基础元信息。具体实现见 2.2.3 小节。
• 编译管理模块:针对需要编译产物的静态语言,负责生成编译任务、获取并缓存产物,并管理其生命周期。
• 源码管理模块:按 Git Commit ID 获取对应版本源码,并对不同版本的源码进行组织与缓存管理,为 AST 解析提供输入。
• MCP 工具:将上述模块能力封装为统一接口,供大模型按需调用。其接口设计见 2.2.2 小节。
2.2.2 MCP接口介绍
• 接口参数
代码上下文 MCP 接口参数如下(示例中字段名用中文标注):
public class McpContextRequest {
private String 任务ID;
private String 分析文件路径;
private List<Integer> diff行号序列;
}任务ID:全局唯一标识,用于与主服务关联。主服务可据此获取项目信息、Git 提交版本、语言信息等;同时,源码与编译产物的组织管理也以任务为基本单元。
分析文件路径:一次上下文分析以文件为基本单元,该参数用于指定目标文件的路径。
diff行号序列:单个文件在一次 Review 中可能存在多个不连续 Diff,该参数用于传递所有 Diff 的起止行号(偶数个),格式为 [start1, end1, start2, end2, ...]。
• 接口提示词(Prompt)
接口提示词用于描述工具能力、参数含义、使用方式、返回值与异常等信息,影响模型是否能正确识别并调用 MCP 接口。在 Spring AI 中,可通过 @Tool 注解的 description 属性进行配置。
本项目的提示词按以下 5 个方面组织,便于模型理解与调用:
结合调试经验,提示词优化主要关注两点:一是控制复杂度,既要覆盖关键信息,又避免堆叠冗余细节;可用 Markdown 分层描述,措辞尽量统一且明确。二是在客户端侧补充调用约束(例如在特定场景要求必须调用 MCP 工具),用于减少漏调用或不调用的情况。
• 功能概述:说明工具用途与适用场景。
• 输入参数说明:列出入参并解释含义。
• 输出结果说明:说明返回数据结构及用途。本项目返回 JSON 数据,包含代码关系与元信息,用于辅助依赖分析与影响范围判断。
• 使用场景:列举典型场景,如代码理解、调用链分析、影响面评估、代码评审等。
• 注意事项:补充约束条件、特殊规则与异常处理方式。
• 功能整合:MCP 接口负责调用 AST 模块,将基础能力按代码上下文协议整合为 JSON 返回。协议说明见 2.3.2 小节。
2.2.3 AST功能介绍
• 代码元素元信息解析:解析代码元素类型(局部变量、全局变量、方法、lambda 等)、修饰符、返回类型、方法签名等元信息。
• 行号所属元素获取:根据输入行号定位其所属的代码元素,并返回对应元信息;例如行号落在方法体内时,返回该方法的元信息。
• 调用/使用元素提取:按行解析代码,提取该行引用的全局变量、调用的方法等引用信息。
• 上下文源码获取:返回目标元素所属类/方法的源码片段,用于补全上下文。
• 面向对象特性支持:处理继承、多态、接口实现、匿名内部类等 Java 语法结构,提升解析结果的可用性。
• 全局引用索引:构建代码元素引用索引,用于查找目标方法/变量在工程内的调用位置。
• 元信息截断:对过长的源码或元信息按配置进行截断,在上下文完整性与传输开销之间做取舍,控制大模型 token 消耗。
2.3 代码上下文结构设计
2.3.1 与大模型交互存在的问题
在设计代码上下文结构时,首先要明确的是:以什么形式传递信息、传递哪些信息、信息量控制在什么范围。上下文过少时,模型容易基于片段做出不准确判断;但无节制堆叠信息又会导致 token 消耗上升、理解负担加重,最终影响审查效果。因此,本小节主要说明我们在落地过程中对上下文结构做出的取舍与原因。
• 上下文内容的取舍
上下文设计的核心原则并不是尽量完整,而是只提供对 Code Review 判断真正有帮助的信息。围绕这一点,不同代码元素的处理方式有所不同。
• 对于全局变量
(1) 变量的元信息(类型、修饰符、声明位置等)
(2) 变量的定义源码
(3) 该变量在全局范围内的引用位置
在上下文中同时提供变量定义与全局引用位置后,模型不仅仅依据局部片段推断变量的使用范围,有助于识别变量是否存在多处访问、并发使用或被不同业务逻辑混用的风险。
• 对于方法:
(1) Diff 行号所在方法的元信息和完整方法源码,作为分析的核心上下文;
(2) 对所有 Diff 行进行逐行解析,提取该行实际调用到的方法或字段,并补充对应的元信息和源码;
(3) Diff 所在方法在全局范围内的被调用位置,用于辅助判断此次修改可能带来的影响范围。
这样的信息组合,基本可以覆盖“当前方法做了什么”、“它依赖了谁”、“谁又依赖了它”这三个最关键的问题。
• 关于调用链递归深度的取舍:
基于 AST 可以沿调用关系向上、向下递归获取更完整的调用链。但在多轮测试中我们发现:
(1) 调用层级继续加深,对审查结论的增益有限;
(2) 上下文体量会显著增加,模型理解难度上升,token 消耗随之增大。
(3) 因此当前实现中,仅对 Diff 所在元素进行一次向上(被调用方)和一次向下(调用目标)的展开。是否需要更深层递归,一方面取决于模型对复杂代码的处理能力,另一方面也与项目代码规模和 token 预算有关。
(4) 基于上述取舍,系统预留了调用层级与源码截断策略的配置项,便于在更换模型或适配不同项目规模时调整。
• 上下文传递方式的实践经验
在 MCP 接口设计初期,我们曾尝试将 AST 能力拆分为多个基础接口,例如:
-
根据行号获取所属方法元信息;
-
获取行内引用的方法或字段;
-
再根据元信息单独拉取对应源码。
原本希望模型能够根据场景灵活组合这些接口完成上下文构建,但在实际使用中不够稳定:
-
接口漏调,或调用顺序不符合预期;
-
参数填写不完整,导致返回信息缺失;
-
Review 结果波动较大,同一类问题在不同请求中表现不一致。
基于上述问题,我们最终调整为统一上下文接口的设计方式:
由 MCP 服务侧完成 AST 信息的聚合、裁剪与结构化处理,模型通过单一接口获取整理后的代码上下文。配合提示词的迭代,接口调用过程更可控,审查结果的波动也相应降低。
2.3.2 代码上下文与大模型的交互协议
以下示例展示代码上下文的返回结构(为便于说明,字段名使用中文标注):
{
"元素关系": {
"所属元素": {
"10_25": [
{
"元素ID": "E_METHOD_001",
"引用位置": [
{
"文件地址": "com/xxx/service/AService.java",
"行号": 128
},
{
"文件地址": "com/xxx/service/AService2.java",
"行号": 100
}
]
}
],
"引用元素": {
"15": [
{
"元素ID": "E_METHOD_002",
"元素名称": "query",
"元素类型": "METHOD"
},
{
"元素ID": "E_FIELD_003",
"元素名称": "SIZE",
"元素类型": "FIELD"
}
]
},
"元素信息": {
"E_METHOD_001": {
"元素类型": "METHOD",
"方法所在类全路径名": "com.xxx.service.AService",
"方法名": "process",
"方法返回类型": "void",
"方法修饰符列表": ["public"],
"注解列表": [],
"方法入参列表": [],
"方法异常列表": [],
"方法在源码中的起始行号": 120,
"方法在源码中的结束行号": 189,
"方法中引用的全局变量列表": [],
"源文件路径": "AService.java",
"该方法是接口时其所有实现类对应的方法列表":[],
"元素源代码": "public void process(String param) { // 业务逻辑实现 }"
},
"E_METHOD_002": {...},
"E_FIELD_003": {
"元素类型": "FIELD",
"字段所在类全路径名": "com.xxx.constant.Config",
"字段名": "SIZE",
"字段类型": "int",
"修饰符列表": ["public", "static", "final"],
"字段注解列表": [],
"字段在源码中的起始行号": 25,
"字段在源码中的结束行号": 25,
"字段源码所在源文件路径": "Config.java",
"元素源代码": "public static final int SIZE = 100;"
}
}
}
}
}• 整体结构设计
返回结果主要包含两部分:
两部分通过元素ID进行关联;元素ID在本次返回中全局唯一,可作为关联键。
• 元素关系:描述代码片段与代码元素之间的关系。
• 元素信息:描述代码元素本身的元信息及源码。
• 元素关系介绍
-
所属元素
所属元素用于描述代码片段与其所属代码元素之间的关系。例如,上例中,key 为 "10_25" 的对象含义为:
(1)10_25 表示 Java 源文件中的绝对行号区间
(2)该区间内的代码属于方法E_METHOD_001
(3)引用位置用于描述该方法在全局范围内被引用的位置
(4)当代码片段位于方法体中时,该区间通常仅对应一个方法元素;当片段覆盖多个连续字段定义时,区间可能同时属于多个字段元素。
• 引用元素
引用元素用于描述代码片段中某一行使用到的其他代码元素。例如,上例中,key 为 "15" 的对象含义为:
(1)15 表示 Java 源文件中的绝对行号。
(2)在 Java 文件第 15 行,按出现顺序调用了方法 query(元素ID 为 E_METHOD_002),并使用了全局字段 SIZE(元素ID 为 E_FIELD_003)。
该结构仅记录可跨范围引用的元素(如方法、全局字段等),不包含局部变量。数组顺序表示元素在该行中的相对出现顺序,用于区分同一行存在多次调用或重载等场景。
• 元素信息介绍
元素关系中出现的元素ID,其详细信息统一在元素信息中定义。
元素ID作为关联键,可以保证:
-
每个方法或字段的元信息只出现一次。
-
元素关系中仅通过元素ID进行引用。
-
减少同一元素在不同位置重复传输源码与属性信息。
03
效果验证
选取两个在未补充 AST 上下文时较容易出现误判的用例,进行对比验证:
1.空指针用例
• 该 Diff 中调用的 normalize 方法在 key=unknown 时会返回 null。
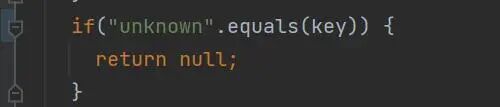
• 未补充 AST 上下文时,模型仅基于 Diff 难以判断 normalize 的返回值是否可能为 null,因此容易遗漏空指针风险。
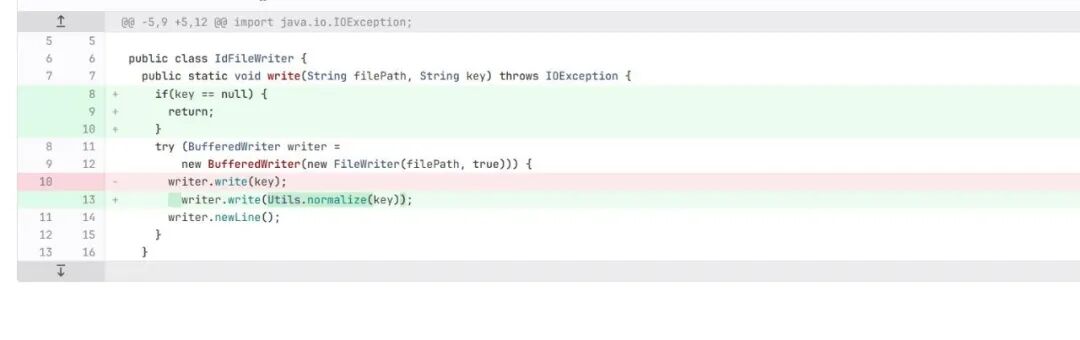

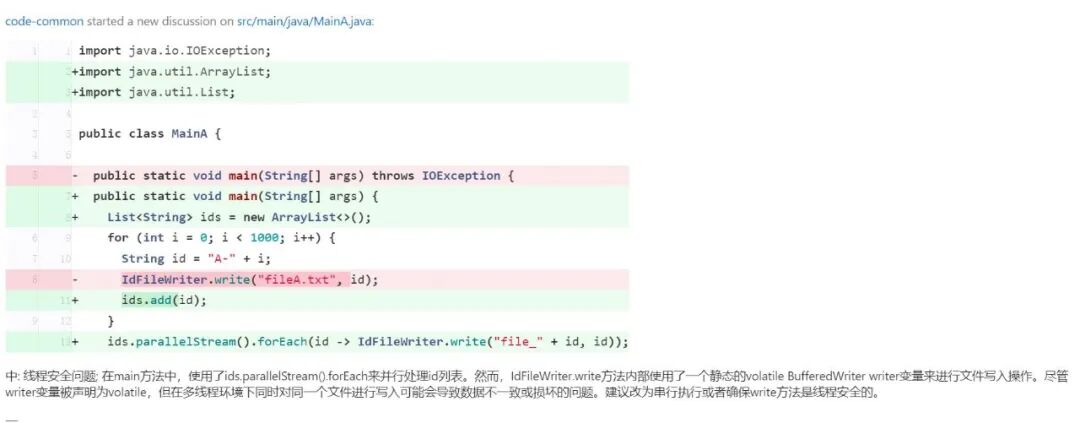
2. 多线程用例
• 未补充 AST 上下文时,模型仅看到 parallelStream 的使用,往往只能基于经验给出线程安全风险提示,结论不够稳定。
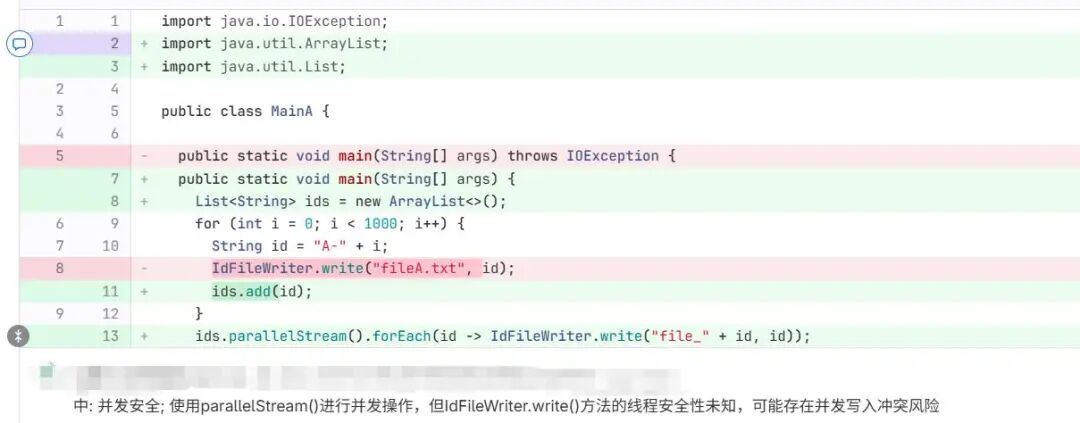
• 补充 AST 上下文后,模型可获取 write 的完整实现与相关引用信息,从而更有依据地判断是否存在线程安全问题,并给出修复建议。
04
结论
本文基于 AST 构建了一个面向代码上下文的 MCP 服务,在代码分析系统与大模型之间提供统一的上下文获取与传递方式,用于缓解 AI Code Review 场景中常见的上下文不足问题。相比仅基于代码片段或 Diff 的审查方式,该方案可以向模型补充代码结构关系与元素归属信息,使审查更接近“在完整静态上下文中理解修改”的过程。
在工程实现上,方案采用分层解耦的方式,通过统一的数据结构与交互协议,将 AST 解析结果组织为模型可消费的上下文输入。在保持可扩展性的同时,该设计降低了系统间耦合,便于在现有 Code Review 流程中集成与复用。
此外,AST 工具与 MCP 服务也可用于代码审查以外的场景,例如变更影响分析、依赖关系梳理、代码理解辅助与架构分析等。它们提供的是“可检索的结构化上下文”,上层应用可按需组合到不同流程中。
后续将围绕多语言 AST 支持、解析性能与资源开销优化,以及部署与调用方式的简化继续完善,以适配更大规模代码库与多样化研发环境。


欢迎加入 MCP 技术社区!与志同道合者携手前行,一同解锁 MCP 技术的无限可能!
更多推荐

 10
10 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)