MCP 进浏览器、KV Cache 跨机房、语音接口继续降本之后,测试体系该补哪一层?
同样是做测试,这两年的工作对象已经换了。
以前主要盯页面、接口、数据库、日志。现在一个需求上线,背后可能串着浏览器调试、代码仓库、工单系统、设计产物、模型服务、语音接口、外部工具调用,甚至跨数据中心的推理链路。Chrome DevTools MCP 已经能让 MCP 客户端驱动浏览器并记录 performance trace;Bolt Connectors 明确基于 MCP,把 Notion、GitHub、Jira、Sentry 这类工程上下文接进工作流;Claude Design 也已经支持导出到 Canva、PDF、PPTX、HTML,并把 handoff bundle 直接交给 Claude Code。
再往底层看,变化还在继续下沉。DeepSeek 的 DeepGEMM 已经把大模型核心计算库做成统一的 CUDA 代码库,并通过轻量 JIT 在运行时编译;Moonshot/Kimi 的新论文开始讨论跨数据中心的 Prefill-as-a-Service,把长上下文 prefill 和 decode 拆开,并把 KV Cache 传到本地解码集群;xAI 新发布的语音接口把 STT 价格继续压低;OpenClaw 相关部署风险则已经被监管和安全圈持续提醒。
这对测试岗位的影响很直接:被测对象已经从“一个应用”扩展成“多上下文、多工具、多执行环境、多算力层”的长链路系统。
测试边界先变,岗位考核后变。
能跑通脚本已经不够,能解释失败原因才开始有区分度。
Agent 项目最难上线的地方,往往不是演示效果,而是权限与审计。
目录
-
被测对象已经从“应用”变成“链路”
-
系统一旦长链路化,测试入口就必须前移
-
自动化测试正在从执行脚本演进为诊断脚本
-
AI 性能测试正在下沉到算子、缓存和调度层
-
多模态一旦进入常规交付,语音测试会快速补课
-
Agent 能不能上线,卡点通常落在权限边界
-
岗位不会先消失,考核方式会先改写
一、被测对象已经从“应用”变成“链路”
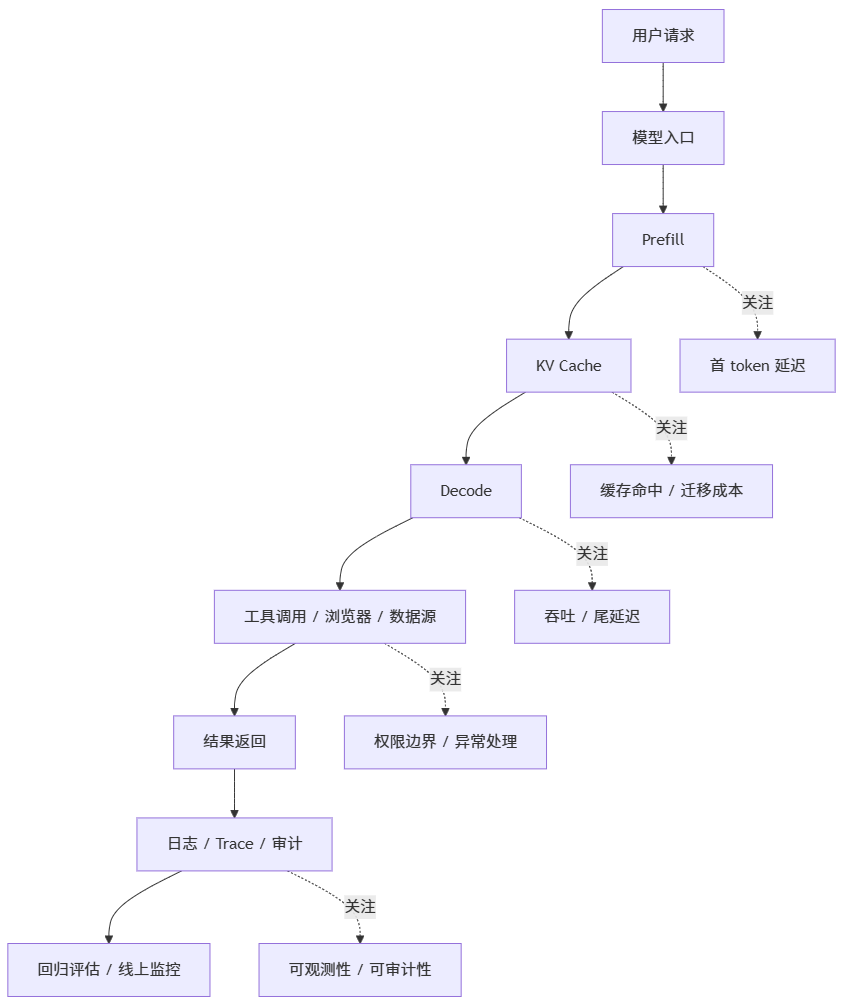
现在很多测试同学会觉得工作越来越碎,问题越来越难复现,定位越来越慢。 这不是个人感觉出了偏差,而是系统形态真的变了。
Chrome DevTools MCP 让浏览器不再只是被点开的页面,而是变成一个可以被 MCP 客户端直接观察和分析的运行环境。Bolt Connectors 把文档、工单、仓库、监控等工具直接接进上下文。Claude Design 则把设计稿、可编辑产物和代码交接继续往同一条链路上拉。原来分散在设计、研发、调试、执行、回归、交付中的能力,正在被同一条工作流重新编排。
这会带来一个非常实际的变化: 缺陷不再只出现在“某个页面按钮点不了”这种单点问题上,而会出现在链路之间。
需求文档理解偏了,后面的生成逻辑就会偏。 工单上下文拿错了,自动化用例就会测偏。 页面能打开,但控制台报错、网络抖动、trace 异常,用户照样会卡。 模型本身没换,但缓存策略、算子实现、资源调度一变,性能和成本就可能完全改观。
所以现在再谈“测试对象”,已经不能只盯某一个功能点。 真正的测试对象,是这条链从输入、上下文、执行、调用到回写的整体行为。
二、系统一旦长链路化,测试入口就必须前移
以前很多团队的测试入口在研发后面。 页面出来了,接口联通了,再开始补功能、兼容、回归、性能。
链路一旦拉长,这个顺序就会越来越吃亏。
因为真正影响结果的东西,很多出现在代码执行之前。 比如需求文档怎么写,工单字段怎么规范,知识库内容是不是可检索,日志和埋点能不能支撑诊断,工具调用有没有权限分层,设计交付是否能被后续代码和测试系统直接利用。Bolt Connectors 的价值就在这里:它不是多接了几个插件,而是把上下文直接从源头拿进来,减少“人手复制上下文”这类高噪声动作。Claude Design 往 Canva、PPTX、HTML 和 Claude Code 的导出与 handoff,也说明设计到实现之间的交接正在被进一步压缩。
这意味着测试必须往前站。 不是为了抢研发的活,而是因为很多后置问题,本质上是前置约束没有建好。
![]()
后面的测试能力差距,很多不会出在“谁脚本写得更快”。 而会出在“谁更早把上下文、权限、埋点、可观测性和回归入口铺好”。
三、自动化测试正在从执行脚本演进为诊断脚本
这一层变化,Chrome DevTools MCP 给得最直接。
它不只是让 MCP 客户端把浏览器打开。官方示例里已经明确写到,客户端可以驱动浏览器并记录 performance trace;在连接运行中的 Chrome 时,MCP server 还会访问所选 profile 下的所有打开窗口。这个能力边界,已经不是传统意义上“帮你自动点页面”那么简单了。([GitHub][1])
这对测试开发的影响很大。
过去写 UI 自动化,很多脚本价值主要体现在“执行步骤”和“断言结果”。 脚本挂了,常见报错是元素没找到、页面超时、断言不通过。
后面真正有价值的自动化,会越来越像这样:
-
先执行操作
-
再自动抓浏览器现场
-
再结合 network、console、trace、页面状态做定位
-
最后把诊断结果回写给缺陷系统或流水线
这才是“长链路系统里的自动化”。
因为问题越来越不是“有没有执行到第 7 步”,而是“为什么执行到第 7 步时系统抖了”。 能不能把失败解释清楚,会比“脚本有没有跑完”更重要。
同样的变化也出现在上下文侧。Bolt 的 Connectors 可以直接连 Notion、Linear、GitHub、Miro、Sentry、Jira 等工具,官方还明确写到:Bolt 可以读取页面、拉取任务、创建 issue,能做什么取决于 Connector 支持什么动作,而且这些动作默认全部开启,可按工具逐项控制。([bolt.new][3])
这意味着自动化的输入,也在变化。 以前自动化主要吃页面结构、接口协议和测试数据。 后面自动化还会直接吃:
-
需求文档
-
工单状态
-
仓库变更
-
日志异常
-
浏览器现场
-
设计交接产物
这已经不是传统脚本维护问题。 这是上下文治理问题。
四、AI 性能测试正在下沉到算子、缓存和调度层
很多团队现在谈 AI 性能测试,思路还停在传统接口压测。 看 RT、TPS、错误率。 这当然有用,但只够看表层。
真正往下看,性能问题已经在往基础设施层转移。
DeepGEMM 的官方描述非常明确:它是一个统一的高性能 tensor core kernel library,把现代大模型里的 GEMMs、MoE、MQA scoring、HyperConnection 等关键计算原语收进同一套 CUDA 代码库,而且通过轻量 JIT 在运行时编译,不需要安装阶段就做 CUDA 编译。([GitHub][2])
这说明什么?
说明模型服务的性能,不再只是“请求到了模型就算完事”。 很多差异会来自:
-
算子实现
-
精度策略
-
kernel 调度
-
硬件利用率
-
通信与计算的重叠方式
再看 Kimi 新论文,给出的方向更直接。论文提出 Prefill-as-a-Service,把长上下文 prefill 卸载到独立的高计算密度集群,再把 KV Cache 通过普通以太网传给本地 PD 集群做 decode;作者同时提到,这个方案不是简单把 KV Cache 变小就结束,而是还要配合 selective offloading、bandwidth-aware scheduling、cache-aware request placement 等系统设计。论文案例里,相比基线方案拿到了更高吞吐。
这一层变化对测试的启发很明确:
AI 性能测试不能只测接口快不快,还要测系统为什么这样快,为什么突然变慢。
后面更该盯住的指标,至少包括这些:
-
首 token 延迟
-
长上下文吞吐
-
尾延迟
-
batch 策略波动
-
KV Cache 命中与迁移成本
-
不同精度 / 不同硬件下的结果与性能双回归
谁还把 AI 性能测试只理解成“压接口”,后面一定会遇到解释不了的问题。
五、多模态一旦进入常规交付,语音测试会快速补课
很多团队以前不怎么碰语音,不是因为不需要,而是因为成本、接入复杂度和交互链路都偏高。
xAI 最新公布的语音接口价格里,STT 批处理是每小时 0.10 美元,流式是每小时 0.20 美元。官方同时把电话、会议、视频/播客、电话场景等作为评估维度列了出来。([xAI][5])
价格往下走,企业把语音接进客服、助手、办公、教育、车载这些场景的意愿就会上来。 一旦进入常规交付,测试就不能继续停在 demo 级验证。
后面语音测试会很快补这些能力:
-
ASR 准确率与领域词识别
-
TTS 一致性与自然度
-
打断、插话、重试
-
弱网、噪声、回声
-
流式返回时延
-
多轮上下文保持
-
语音链路里的权限与数据合规
这也是为什么很多看上去“和测试没关系”的接口降价,实际会直接改写测试工作量结构。 成本一降,试验品就容易变成正式需求。 正式需求一上生产,测试方法就必须跟上。
六、Agent 能不能上线,卡点通常落在权限边界
Agent 项目最容易被低估的,不是效果评估,而是安全测试。
OpenClaw 的例子已经很典型。Reuters 报道里提到,中国工信部曾警告 OpenClaw 在配置不当时可能带来网络攻击和数据泄露风险,并要求部署组织审计公网暴露、加强身份认证和访问控制。同一篇报道还提到,Moltbook 暴露出的安全缺陷让数千人的私有数据受到影响。([Reuters][6])
这件事对测试团队的提醒非常直接:Agent 一旦获得工具权限,风险就不再只是“答错一句话”。
它可能会:
-
越权读取内容
-
误删文件
-
误发消息
-
错改任务状态
-
调用不该调用的外部能力
-
在多工具链路里把一次错误放大成系统性事故
所以后面的智能体测试,基础项至少应该包括:
-
最小权限
-
高风险操作确认
-
插件与工具白名单
-
审计日志
-
凭证隔离
-
回滚与熔断
-
异常行为告警
很多团队现在把这些当成上线前补充检查。 这个顺序后面会越来越危险。 权限边界本身,就应该是测试范围的一部分。
七、岗位不会先消失,考核方式会先改写
很多人最关心的问题还是那个: 测试岗位会不会被替代?
我更倾向于先看另一个变化。 岗位名称未必先变,考核方式会先变。
以前很多团队看的是:
-
用例写了多少
-
回归跑完没有
-
bug 提了多少
-
自动化覆盖率到了没有
后面越来越多的团队会看这些:
-
能不能把问题定位到链路中的具体一层
-
能不能把自动化从执行扩展到诊断
-
能不能建立 AI 服务的性能基线
-
能不能把权限、审计、可观测性纳入测试设计
-
能不能把文档、工单、日志、浏览器、模型服务串成可回归的闭环
这对三类人影响都很大。
对在校生来说,最重要的不是把所有新词背下来,而是知道行业现在到底在测什么。 对初级工程师来说,最关键的是别停在“会跑工具”。 对中级工程师来说,真正拉开差距的,是能不能把测试方法从短链路系统升级到长链路系统。
可以把这两类工作方式放在一起看:
|
维度 |
传统自动化测试 |
链路型测试 |
|---|---|---|
|
关注对象 |
页面、接口、数据库 |
上下文、工具调用、模型服务、权限边界 |
|
自动化目标 |
执行步骤、断言结果 |
执行、诊断、回写、解释失败 |
|
性能视角 |
RT、TPS、错误率 |
首 token、吞吐、缓存、调度、尾延迟 |
|
风险重点 |
功能正确性 |
权限、审计、工具边界、数据暴露 |
|
方法难点 |
脚本维护 |
上下文治理、可观测性、系统级定位 |
这不是为了制造焦虑。 它只是把岗位变化说得更准确一点。
测试这行后面不会只剩一种能力。 但只会页面点点点、接口压一压、脚本跑一跑,这条路会越来越窄。
系统已经从单体应用走到了长链路协同。 测试方法要不要跟着升级,已经不是一个学习态度问题,而是交付能力问题。
你现在手里的项目,测试关注点还停在页面和接口,还是已经开始覆盖上下文、浏览器诊断、模型性能、工具权限和审计闭环了?

欢迎加入 MCP 技术社区!与志同道合者携手前行,一同解锁 MCP 技术的无限可能!
更多推荐

 10
10 0
0- 0



 已为社区贡献14条内容
已为社区贡献14条内容

所有评论(0)