LangChain链式调用:用Chains把单轮对话变成工作流
序言:如果你还在用
requests.post()一次次调模型,然后手动把输出复制粘贴到下一个Prompt里,这篇文章就是为你写的。
一、从"单点调用"到"流水线":为什么我们需要链
今年1月份,我朋友跟我说他接了一个内容运营工具的活儿。需求听起来很简单:用户输入一个主题,AI自动生成一篇公众号文章。
他一开始的想法很直接:调一次MiniMax 2.5,让它把活儿全干了。Prompt写得老长:“请根据主题提取关键词,然后生成5个标题,再选最好的标题写正文,最后润色……”
结果可想而知。模型要么漏步骤,要么在标题和正文之间逻辑断层,要么生成的正文和标题八竿子打不着。Prompt越长,模型越迷糊,输出质量越不可控。
他试着拆成多次调用:第一次调模型提取关键词,把结果存变量里;第二次把关键词塞进新Prompt生成标题;第三次挑标题写正文。代码很快变成了一团意大利面:
# 第一步:提取关键词
keywords = call_llm(f"提取关键词:{topic}")
# 第二步:生成标题
titles = call_llm(f"根据关键词{keywords}生成5个标题")
# 第三步:选标题(又是手动解析字符串)
best_title = parse_titles(titles)[0]
# 第四步:写正文
article = call_llm(f"标题是{best_title},关键词是{keywords},请写正文")
# 第五步:润色
final = call_llm(f"润色以下文章:{article}")
每一步都依赖前一步的输出,每一步都要手动处理字符串解析,每一步的错误处理都得单独写。更可怕的是,如果他想把"提取关键词"换成用本地模型,或者想在"生成标题"后加一步"查重",整个代码结构都要大改。
那一刻他明白了:AI应用开发,最难的不是调模型,而是把多个模型调用编排成可靠的流水线。
这就是LangChain中"Chain"(链)要解决的问题。它不是让你更聪明地写Prompt,而是让你把单轮对话组装成可编排、可复用、可调试的工作流。
为了理解链的本质,我想用一个接地气的类比:快递分拣中心。
二、快递分拣中心:理解三种链的类比
想象你走进一个快递分拣中心。包裹从传送带进来,经过一系列处理,最终送到正确的目的地。LangChain的三种核心链,正好对应三种不同的分拣流水线。
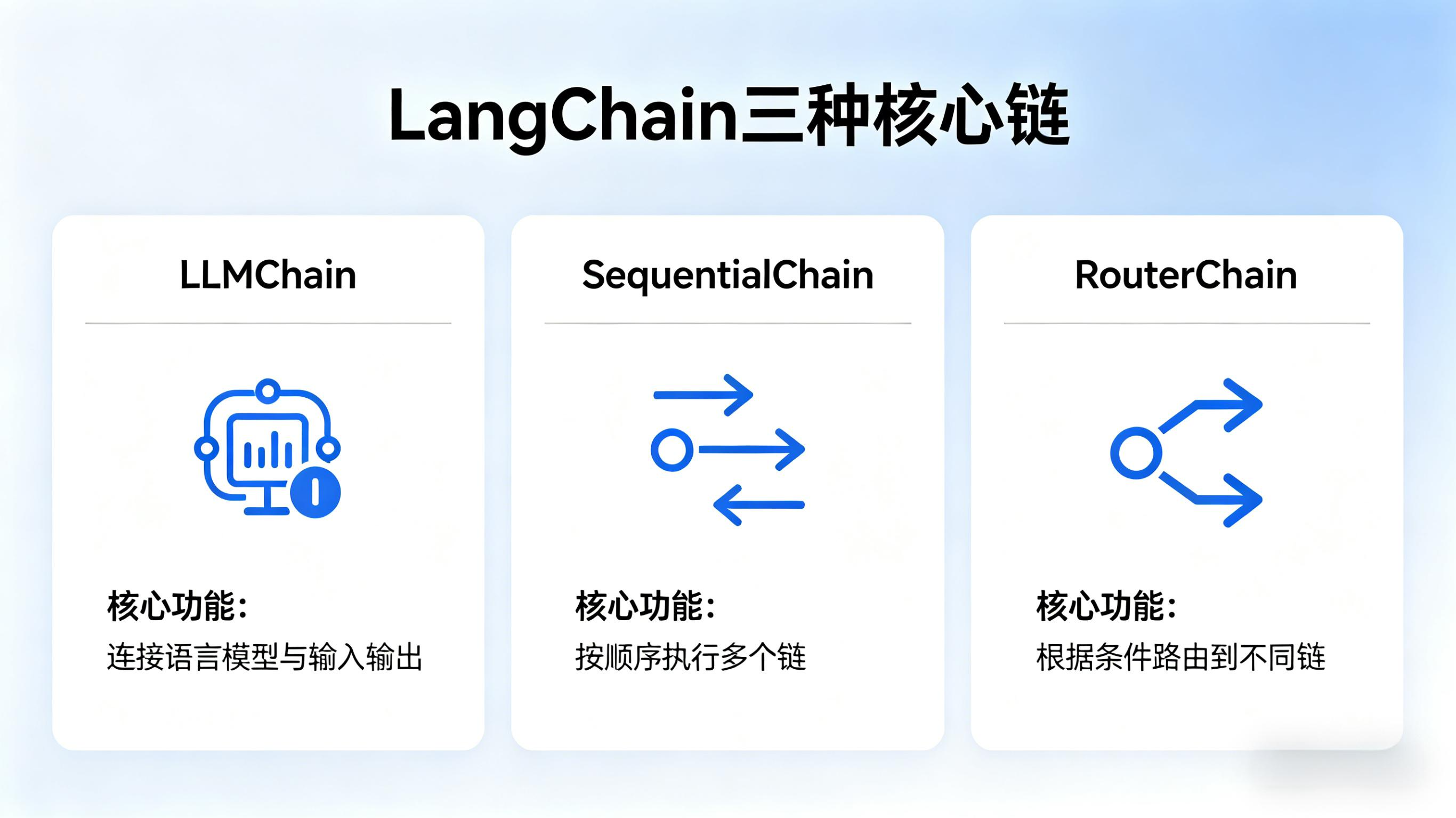
第一种:LLMChain——“单工位打包台”
LLMChain是最基础的链,它只做一件事:把Prompt模板和模型绑在一起,输入变量进去,输出结果出来。就像快递中心的一个单工位打包台——包裹放上去,打包员(模型)处理完,直接输出。
from langchain_core.prompts import ChatPromptTemplate
from langchain_openai import ChatOpenAI
# 一个Prompt模板 + 一个模型 = 一条LLMChain
prompt = ChatPromptTemplate.from_template("把这段话翻译成英文:{text}")
llm = ChatOpenAI(model="minimax-2.5")
# 用管道符 | 组装成链
chain = prompt | llm
# 调用:输入进去,翻译出来
result = chain.invoke({"text": "你好,世界"})
LLMChain的价值在于标准化单步调用。它把"填充模板→调模型→拿结果"这三步封装成一个黑盒,你不用每次都写重复的API调用代码 。
但单工位打包台的能力有限。如果你的包裹需要"先称重→再贴标签→最后打包",一个工位显然不够。这就需要第二种链。
第二种:SequentialChain——“流水线装配线”
SequentialChain是顺序执行的链,前一个链的输出作为下一个链的输入,像流水线一样依次传递。就像快递中心的装配线:包裹先经过称重站,再经过贴标站,最后到达打包站,每一步都依赖前一步的结果。
用一个实战场景演示:翻译→润色的两步流水线。
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.output_parsers import StrOutputParser
from langchain_openai import ChatOpenAI
llm = ChatOpenAI(model="minimax-2.5")
# ===== 第一步:翻译链 =====
translate_prompt = ChatPromptTemplate.from_template(
"你是一位专业翻译,请将以下中文翻译成地道英文:\n{text}"
)
translate_chain = translate_prompt | llm | StrOutputParser()
# ===== 第二步:润色链 =====
# 注意:这里的{draft}就是第一步的输出
polish_prompt = ChatPromptTemplate.from_template(
"你是一位资深编辑,请润色以下英文,使其更流畅、更符合母语者表达习惯:\n{draft}"
)
polish_chain = polish_prompt | llm | StrOutputParser()
# ===== 组装顺序链 =====
# 用管道符直接把两条链串起来
translate_then_polish = translate_chain | polish_chain
# 调用:中文进去,润色后的英文出来
result = translate_then_polish.invoke({"text": "我们的产品采用最新技术,性能卓越。"})
print(result)
这里的关键在于数据流的自动传递。第一步translate_chain的输出(纯字符串,因为加了StrOutputParser)会自动作为第二步polish_chain的输入变量{draft}。你不需要手动截取、传递、解析,LangChain在底层帮你把管道接好了。
这种写法比传统的SequentialChain类要简洁得多。在旧版LangChain中,你得这么写:
# 旧式写法(不推荐新项目使用)
from langchain.chains import LLMChain, SequentialChain
chain1 = LLMChain(llm=llm, prompt=prompt1, output_key="draft")
chain2 = LLMChain(llm=llm, prompt=prompt2, output_key="final")
overall = SequentialChain(chains=[chain1, chain2], input_variables=["text"])
新旧对比一目了然:LCEL的管道符|让链的组装变得像拼乐高一样直观,而且天然支持流式、异步、批量等高级特性。
第三种:RouterChain——“智能分拣机”
SequentialChain处理的是"一条道走到黑"的线性流程。但现实中,很多任务需要根据输入内容动态选择处理路径。就像快递中心的智能分拣机——包裹上的地址不同,自动分到不同的传送带。
RouterChain(路由链)就是干这个的。它先让模型判断输入属于哪个类别,然后自动分发到对应的子链处理。
用一个客服场景演示:用户的问题可能涉及"退款"、“物流”、"产品咨询"三类,系统需要自动识别意图,再交给不同的专家链处理。
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.output_parsers import StrOutputParser
from langchain_openai import ChatOpenAI
from langchain_core.runnables import RunnableBranch, RunnableLambda
llm = ChatOpenAI(model="minimax-2.5")
# ===== 三条专家子链 =====
# 退款专家
refund_prompt = ChatPromptTemplate.from_template(
"你是退款专员。用户问题:{question}\n请给出退款流程指引。"
)
refund_chain = refund_prompt | llm | StrOutputParser()
# 物流专家
shipping_prompt = ChatPromptTemplate.from_template(
"你是物流专员。用户问题:{question}\n请查询并说明物流状态。"
)
shipping_chain = shipping_prompt | llm | StrOutputParser()
# 产品专家(默认分支)
product_prompt = ChatPromptTemplate.from_template(
"你是产品顾问。用户问题:{question}\n请详细介绍产品信息。"
)
product_chain = product_prompt | llm | StrOutputParser()
# ===== 意图识别函数 =====
def is_refund(q: dict) -> bool:
return any(k in q["question"] for k in ["退款", "退货", "退钱"])
def is_shipping(q: dict) -> bool:
return any(k in q["question"] for k in ["物流", "快递", "发货", "到哪"])
# ===== 组装路由链 =====
route_chain = RunnableBranch(
(RunnableLambda(is_refund), refund_chain),
(RunnableLambda(is_shipping), shipping_chain),
product_chain # 默认分支
)
# ===== 调用测试 =====
print(route_chain.invoke({"question": "我要退款怎么操作?"}))
print(route_chain.invoke({"question": "我的快递到哪了?"}))
print(route_chain.invoke({"question": "这款手机支持5G吗?"}))
RunnableBranch是LCEL中实现路由的核心组件。它接收一系列(条件, 子链)元组,按顺序匹配条件,命中则执行对应的子链,都不命中就走默认分支。
这比旧版的MultiPromptChain要灵活得多。旧版需要预定义Prompt模板列表,由模型内部判断路由;而LCEL的RunnableBranch允许你用任意Python函数做判断逻辑,甚至可以用另一个LLM调用来做意图识别,完全由你控制。
三、实战演示:三条链解决真实问题
理解了三种链的区别,我们来看一个更完整的实战:搭建一个"内容运营助手",把前面提到的"提取关键词→生成标题→撰写正文"完整实现。
实战一:简单链——翻译后润色
这个场景适合展示链的组合与数据流。我们不仅要串两条链,还要在中间插入一个"格式化"步骤。
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.output_parsers import StrOutputParser
from langchain_openai import ChatOpenAI
from langchain_core.runnables import RunnableLambda
llm = ChatOpenAI(model="minimax-2.5")
# 第一步:翻译
translate = (
ChatPromptTemplate.from_template("将以下中文翻译成英文:\n{text}")
| llm | StrOutputParser()
)
# 中间步骤:格式化(纯Python函数,用RunnableLambda包装)
def add_prefix(text: str) -> str:
return f"[翻译结果]\n{text}\n\n[请润色以上文本]"
format_step = RunnableLambda(add_prefix)
# 第二步:润色
polish = (
ChatPromptTemplate.from_template("{formatted_text}")
| llm | StrOutputParser()
)
# 组装完整链:翻译 → 格式化 → 润色
# 注意数据流:translate输出给format_step,但format_step的输出键是formatted_text
# 需要用字典映射调整数据流
workflow = (
{"text": RunnableLambda(lambda x: x["text"])}
| translate
| {"formatted_text": format_step}
| polish
)
# 更简洁的写法:直接用管道符串联,利用自动类型推断
simple_chain = translate | RunnableLambda(add_prefix) | polish
result = simple_chain.invoke({"text": "我们的AI平台帮助企业降本增效。"})
print(result)
这里展示了LCEL的一个核心优势:任何Python函数都可以被包装成Runnable,无缝接入管道。RunnableLambda让自定义逻辑(比如数据清洗、格式转换、外部API调用)可以和模型调用一样,用|串联起来。
实战二:顺序链——从主题到文章
这个场景展示多步骤复杂编排。我们用字典语法实现并行+串行的混合流程。
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.output_parsers import StrOutputParser, CommaSeparatedListOutputParser
from langchain_openai import ChatOpenAI
from langchain_core.runnables import RunnableParallel, RunnablePassthrough
llm = ChatOpenAI(model="minimax-2.5")
# ===== 步骤1:提取关键词 =====
keyword_prompt = ChatPromptTemplate.from_template(
"从以下主题中提取3-5个核心关键词,用逗号分隔:\n{topic}"
)
keyword_chain = keyword_prompt | llm | CommaSeparatedListOutputParser()
# ===== 步骤2:生成标题(需要关键词) =====
title_prompt = ChatPromptTemplate.from_template(
"根据主题\"{topic}\"和关键词{keywords},生成3个吸引人的标题。"
)
# 注意:这里用字典组装输入,让keyword_chain和原始topic并行传递
title_chain = (
{"topic": RunnablePassthrough(), "keywords": keyword_chain}
| title_prompt | llm | StrOutputParser()
)
# ===== 步骤3:撰写正文(需要标题+关键词) =====
article_prompt = ChatPromptTemplate.from_template(
"标题:{title}\n"
"关键词:{keywords}\n"
"请撰写一篇800字的公众号文章,要求:\n"
"1. 开头用故事引入\n"
"2. 中间结合关键词展开论述\n"
"3. 结尾给出行动号召"
)
# 组装完整顺序链
content_pipeline = (
{"topic": lambda x: x["topic"]} # 原始输入透传
| RunnableParallel({
"keywords": keyword_chain,
"title": title_chain,
})
| article_prompt | llm | StrOutputParser()
)
# 调用
result = content_pipeline.invoke({"topic": "AI智能体如何改变企业办公"})
print(result)
这段代码的精妙之处在于数据流的编排:
keyword_chain和title_chain并不是简单串联。title_chain需要同时拿到原始topic和keywords的输出;RunnableParallel让"提取关键词"和"生成标题"可以并行执行(虽然这里因为依赖关系实际是串行,但语法上展示了并行能力);- 最终
article_prompt同时接收title和keywords两个变量,组装成完整的Prompt。
如果用旧式SequentialChain,你需要手动定义每个链的output_key和input_variables,代码量至少翻倍,而且可读性远不如管道符清晰 。
实战三:路由链——根据意图分发处理
这个场景展示条件分支的动态编排。我们升级前面的客服例子,让意图识别本身也用模型来做,而不是硬编码关键词匹配。
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.output_parsers import StrOutputParser
from langchain_openai import ChatOpenAI
from langchain_core.runnables import RunnableBranch, RunnableLambda
llm = ChatOpenAI(model="minimax-2.5")
# ===== 意图识别链(用模型判断) =====
intent_prompt = ChatPromptTemplate.from_template(
"判断以下用户问题的意图类别,只输出一个单词(refund/shipping/product):\n{question}"
)
intent_chain = intent_prompt | llm | StrOutputParser()
# ===== 三条专家链 =====
refund_chain = (
ChatPromptTemplate.from_template("你是退款专家。问题:{question}\n给出详细退款步骤。")
| llm | StrOutputParser()
)
shipping_chain = (
ChatPromptTemplate.from_template("你是物流专家。问题:{question}\n说明如何查询物流。")
| llm | StrOutputParser()
)
product_chain = (
ChatPromptTemplate.from_template("你是产品专家。问题:{question}\n详细介绍产品特性。")
| llm | StrOutputParser()
)
# ===== 路由判断函数 =====
def route_by_intent(x: dict) -> str:
intent = x["intent"].strip().lower()
if "refund" in intent:
return "refund"
elif "shipping" in intent:
return "shipping"
else:
return "product"
# ===== 组装完整路由链 =====
# 先识别意图,再根据意图分发
full_router = (
{"question": lambda x: x["question"], "intent": intent_chain}
| RunnableLambda(route_by_intent)
| RunnableBranch(
(lambda x: x == "refund", refund_chain),
(lambda x: x == "shipping", shipping_chain),
product_chain
)
)
# 调用
print(full_router.invoke({"question": "我要退货,流程是什么?"}))
这个例子展示了链的嵌套能力:意图识别本身是一条链,路由分发是另一条链,专家处理是第三条链。三层嵌套,但代码结构依然清晰,因为每一层都是独立的Runnable,通过管道符连接。
四、LCEL语法糖:为什么管道符|改变了游戏规则
前面反复提到LCEL(LangChain Expression Language),它用管道符|替代了传统的链类(LLMChain、SequentialChain等)。这个改变不只是语法糖,而是底层架构的升级。
统一接口:万物皆Runnable
在LCEL的世界里,PromptTemplate、LLM、OutputParser、Python函数、甚至字典,都实现了同一个Runnable接口。这个接口定义了标准方法:
invoke(input):单输入单输出batch(inputs):批量处理stream(input):流式输出ainvoke/astream:异步版本
这意味着,你可以对任何组件调用.invoke(),也可以用|把它们串起来。管道符底层调用的是__or__方法,它会自动检查前一个组件的输出类型和后一个组件的输入类型是否匹配,不匹配时在链构建阶段就报错,而不是等到运行时才炸。
流式与异步的原生支持
传统链要支持流式输出,需要额外配置回调和事件处理。LCEL的链天然支持流式:
# 流式输出:模型生成一个字,前端展示一个字
for chunk in chain.stream({"topic": "AI发展趋势"}):
print(chunk, end="")
在FastAPI等异步框架中,直接调用chain.invoke()会阻塞事件循环。LCEL提供了ainvoke和astream,让链可以无缝接入异步环境:
async def chat(question: str):
async for chunk in chain.astream({"question": question}):
yield chunk
透明可调试
传统链像黑盒,出了问题只能打印中间结果猜。LCEL的链结构本身就是清晰的管道图,配合LangSmith追踪,你可以看到每一步的输入输出、耗时、Token消耗,调试效率提升一个数量级。
五、写在最后:从"调API"到"搭流水线"
回到开头那个内容运营工具。用LCEL重构后,代码变成了这样:
content_pipeline = (
keyword_chain
| title_chain
| article_chain
| polish_chain
)
result = content_pipeline.invoke({"topic": "AI智能体如何改变企业办公"})
四步流水线,一行组装,一行调用。每一步都是独立的、可测试的、可替换的组件。想换本地模型?改llm的定义就行。想加一步"查重"?在管道中间插一个RunnableLambda。想并行生成多个版本?用RunnableParallel同时跑三条链。
这就是链式调用的本质:把AI开发从"写脚本"变成"搭流水线"。
脚本是一次性的、脆弱的、难以维护的。流水线是模块化的、可编排的、可扩展的。当业务需求变化时,你不需要重写代码,只需要重新排列组合已有的组件。
LangChain的Chains,特别是LCEL的管道符语法,让这种流水线思维在Python代码中变得极其自然。它不提供魔法,只提供一种组织复杂度的方式——而组织复杂度,正是工程化的核心能力。
如果你今天还在用裸API调用做AI应用,不妨花半天时间,把最核心的那段多步骤逻辑改成LCEL链。当你看到代码从一团意大利面变成一条清晰的管道,你会明白:链式调用不是LangChain的噱头,而是AI应用开发的必修课。

欢迎加入 MCP 技术社区!与志同道合者携手前行,一同解锁 MCP 技术的无限可能!
更多推荐
 10
10 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)