RPA+AI Agent本地部署与EXE打包实战:电商数据汇总/智能客服/发票归档的踩坑记录与Python代码
去年8月,我们团队3人每天花在数据搬运上的时间超过6小时。最崩溃的一次,同事连续3天做同一个汇总,第三天发现数据错位,整个表全废。
试了一圈方案,最后落地了4个RPA+AI Agent场景。这篇不是教程,是踩坑记录——哪些能跑通、哪些翻了车、真实的技术选型逻辑是什么。
一、电商多店铺数据自动汇总
1.1 业务痛点
5个平台(淘宝、京东、拼多多、抖音、小红书),每天运营要分别登录后台下载订单、推广、库存数据,再贴到汇总表。
一个平台3分钟,5个平台理论15分钟,实际40分钟以上。字段名不统一、日期格式各异,人工对齐极易出错。
1.2 技术方案
第一层:RPA自动抓取
-
指纹浏览器隔离环境(紫鸟、比特、HubStudio),每个店铺独立Cookie和指纹
-
RPA按日期筛选、下载报表、保存到本地指定文件夹
-
通过模拟鼠标键盘操作实现,降低平台风控概率
第二层:AI Agent数据清洗
不同平台字段映射关系:
| 平台 | 金额字段名 | 日期格式 |
|---|---|---|
| 淘宝 | 实付金额 | 2025/6/8 |
| 京东 | 订单金额 | 2025-06-08 |
| 拼多多 | 支付金额 | 2025.06.08 |
接入DeepSeek大模型,提示词核心逻辑:
prompt = """
你是一个数据清洗助手。请将以下各平台原始数据按统一格式处理:
1. 金额字段统一映射为"实付金额"
2. 日期统一转为YYYY-MM-DD格式
3. 缺失值标红,异常值(如金额为负)单独列出
原始数据:
{raw_data}
"""第三层:自动生成报表
清洗后的数据写入Excel,调用openpyxl生成趋势图。定时任务每天早上9点触发,完成后邮件推送。
from openpyxl import Workbook
from openpyxl.chart import LineChart, Reference
def generate_report(cleaned_data, output_path):
wb = Workbook()
ws = wb.active
ws.title = "汇总报表"
# 写入数据
for row in cleaned_data:
ws.append(row)
# 生成趋势图
chart = LineChart()
chart.title = "近7日销售趋势"
data = Reference(ws, min_col=2, min_row=1, max_row=len(cleaned_data))
chart.add_data(data, titles_from_data=True)
ws.add_chart(chart, "E2")
wb.save(output_path)1.3 踩坑记录
-
坑1:云端RPA IP漂移触发风控
某云RPA的IP池不固定,平台后台触发异地登录验证,流程中断。换成纯本地运行的RPA方案后解决——流程在本地执行,IP固定,数据不上传任何第三方服务器。 -
坑2:大模型幻觉导致金额错误
早期直接用LLM做计算,偶尔出现199.9+200=399.80000000000007这类浮点问题。后来改为LLM只做字段映射和格式标准化,数值计算用Python处理。 -
坑3:指纹浏览器兼容性问题
HubStudio 3.2.1版本更新后RPA定位不到元素,回退到3.1.8解决。解决方式是锁定浏览器版本,关闭自动更新。
1.4 效果与部署
| 指标 | 优化前 | 优化后 |
|---|---|---|
| 耗时 | 40分钟/天 | 全自动 |
| 错误率 | 每月3-4次 | 0次 |
| 部署方式 | 本机脚本 | 打包EXE分发,同事双击运行 |
部署方式上,最终选择了支持EXE打包的本地RPA方案。同事不需要安装任何环境,接收文件后双击即可执行,这对非技术同事推广使用很关键。
二、智能客服自动回复(知识库驱动)
2.1 业务痛点
工业配件咨询,问题高度重复(库存、价格、发货时效),分散在网页客服、钉钉、企业微信三个渠道。人工客服月薪5000,大部分时间复制粘贴。
2.2 技术方案
知识库构建
用Markdown格式整理产品信息:
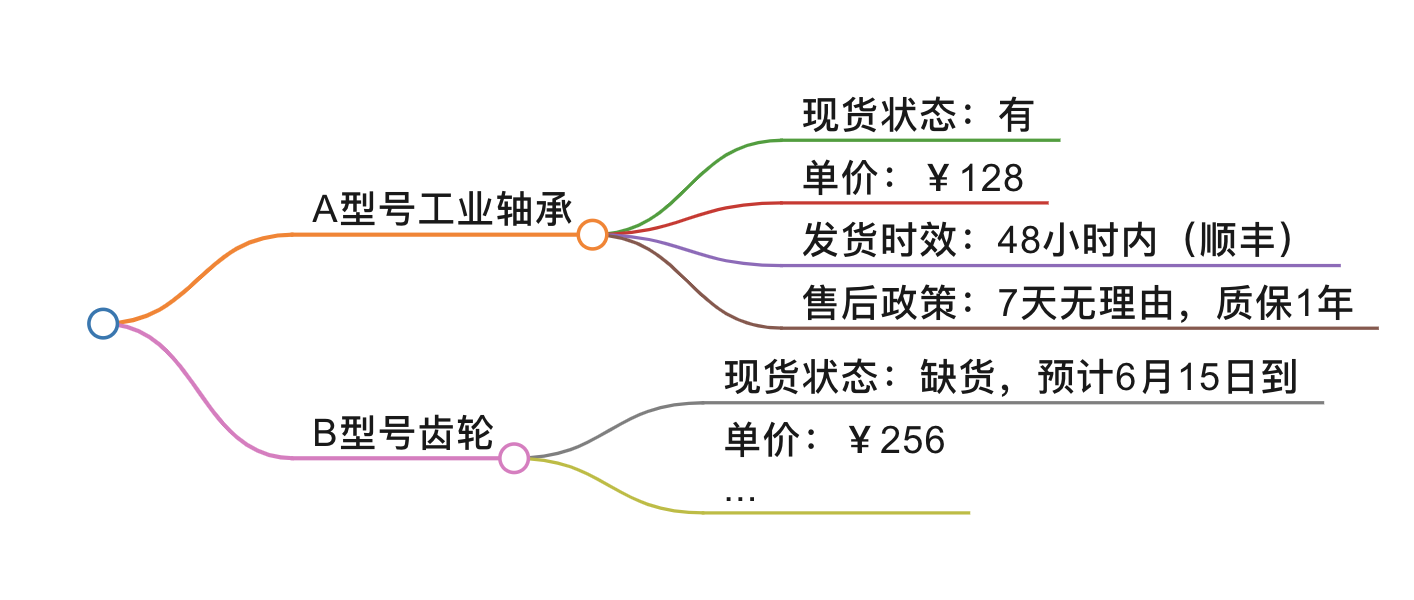
AI Agent回复流程
from sentence_transformers import SentenceTransformer
import numpy as np
# 加载向量模型(本地运行,无需联网)
model = SentenceTransformer('paraphrase-multilingual-MiniLM-L12-v2')
def retrieve_knowledge(query, knowledge_base, top_k=3):
# 将知识库分段编码
passages = [k['content'] for k in knowledge_base]
passage_embeddings = model.encode(passages)
# 查询编码
query_embedding = model.encode([query])
# 计算相似度
similarities = np.dot(query_embedding, passage_embeddings.T)[0]
top_indices = np.argsort(similarities)[-top_k:][::-1]
return [knowledge_base[i] for i in top_indices]
def generate_reply(query, knowledge_base):
relevant_docs = retrieve_knowledge(query, knowledge_base)
context = "\n".join([doc['content'] for doc in relevant_docs])
prompt = f"""
基于以下产品信息,回答客户问题。要求:自然语言,非固定模板。
产品信息:
{context}
客户问题:{query}
"""
# 调用本地或自申请API
return call_llm(prompt)回调通知
Agent回复后,自动推送对话摘要到钉钉群:
def send_notification(dingtalk_webhook, summary):
import requests
payload = {
"msgtype": "text",
"text": {"content": f"[客服Agent] {summary}"}
}
requests.post(dingtalk_webhook, json=payload)2.3 踩坑记录
-
坑1:知识库更新滞后
价格变动后Agent仍报旧价。解决:知识库文件设为每日自动同步,Agent每次回复前强制重新加载。 -
坑2:多轮对话上下文丢失
客户问"多少钱",再问"那B型号呢",AI把B型号当成A型号报价。解决:引入对话记忆(最近3轮),用Redis缓存。 -
坑3:渠道适配成本高
三个渠道的消息格式和发送方式不同。解决:抽象统一的消息接口层,各渠道单独实现适配器。
2.4 效果
-
80%常见问题自动回复
-
复杂问题自动标记"需人工",转接对应同事
-
回复速度从平均5分钟→秒级
三、合同发票自动归档(OCR+AI校验)
3.1 业务痛点
月底财务处理几十张发票、合同:
-
邮箱下载PDF→打开→提取金额、税号、日期→重命名→分类存储→录入财务系统
-
单张5-8分钟,月底加班常态
-
人工重命名易出错(如把5000写成50000)
3.2 技术方案
[邮箱] → [RPA定时扫描] → [下载PDF] → [OCR识别] → [AI校验] → [自动归档] → [录入财务系统]OCR识别
用pdfplumber+Tesseract提取PDF文字,关键字段正则匹配:
import re
import pdfplumber
def extract_invoice_info(pdf_path):
with pdfplumber.open(pdf_path) as pdf:
text = "\n".join([page.extract_text() or "" for page in pdf.pages])
# 金额匹配(支持"金额:5000"、"合计5000"等格式)
amount = re.search(r'(?:金额|合计|小写)[^\d]*(\d{1,3}(?:,\d{3})*\.\d{2})', text)
# 税号匹配
tax_id = re.search(r'[A-Z0-9]{15,20}', text)
# 日期匹配
date = re.search(r'\d{4}[年/-]\d{1,2}[月/-]\d{1,2}[日]?', text)
return {
'amount': amount.group(1).replace(',', '') if amount else None,
'tax_id': tax_id.group(0) if tax_id else None,
'date': date.group(0) if date else None,
'raw_text': text[:500] # 保留原始文本用于校验
}AI校验层
接入大模型做合理性检查:
def validate_with_llm(extracted_info):
prompt = f"""
请校验以下发票信息是否合理:
- 金额是否为数字且大于0
- 日期格式是否正确
- 税号长度是否为15-20位
如有异常,标注具体问题。
提取信息:
{json.dumps(extracted_info, ensure_ascii=False)}
"""
result = call_llm(prompt)
if "异常" in result:
return False, result
return True, "校验通过"自动归档
按规则重命名:{日期}-{供应商}-{金额}.pdf
分类存储:/发票/2025/06/
import os
from datetime import datetime
def archive_invoice(pdf_path, info, base_dir="/发票"):
# 解析日期
date_str = info['date'] or datetime.now().strftime("%Y%m%d")
year, month = date_str[:4], date_str[4:6] if len(date_str) == 8 else date_str[5:7]
# 构建路径
target_dir = os.path.join(base_dir, year, month)
os.makedirs(target_dir, exist_ok=True)
# 重命名
new_name = f"{date_str}-{info.get('supplier', '未知')}-{info['amount']}.pdf"
target_path = os.path.join(target_dir, new_name)
os.rename(pdf_path, target_path)
return target_path3.3 踩坑记录
-
坑1:扫描件PDF无法提取文字
pdfplumber 0.11.0版本在Windows下提取扫描件会报PDFObjRef错误。解决:先用Tesseract OCR,再用LLM做二次校正。 -
坑2:金额单位混淆
有的发票金额单位是"元",有的是"万元"。AI校验层加入单位推断逻辑。 -
坑3:财务系统字段变更
ERP升级后字段名变了,RPA脚本报错。解决:字段映射单独抽成配置文件field_mapping.json,不硬编码。
3.4 效果
-
单张处理从5-8分钟→全自动
-
月底无需加班
-
数据全本地存储,财务合规通过审计
四、周报自动生成(多系统数据采集+LLM总结)
4.1 业务痛点
每周五花1-2小时写周报:各系统截图→复制数据→贴PPT→排版。领导格式要求常变,上周模板这周作废。
4.2 技术方案
RPA数据采集层
| 数据源 | 采集内容 | 方式 |
|---|---|---|
| CRM | 客户跟进记录 | 模拟登录→筛选本周→导出 |
| 电商平台 | 销售数据 | 同案例一 |
| 项目管理 | 任务完成情况 | API调用 |
| 各系统 | 关键页面截图 | 模拟操作→截图保存 |
LLM总结层
提示词核心:
prompt = """
基于以下本周数据,生成周报:
数据:
{data}
要求:
1. 本周完成:列出3-5项核心成果,附具体数字
2. 下周计划:基于未完成任务推断
3. 遇到的问题:数据中的异常或延迟项
4. 需要支持:明确列出需要资源或决策的事项
格式:每段不超过3行,有逻辑、有重点,不要堆砌数据。
"""自动排版层
用python-docx生成Word,按公司模板插入截图和表格:
from docx import Document
from docx.shared import Inches
def generate_weekly_report(data, screenshots, template_path, output_path):
doc = Document(template_path)
# 替换占位符
for paragraph in doc.paragraphs:
if "{本周完成}" in paragraph.text:
paragraph.text = paragraph.text.replace("{本周完成}", data['completed'])
if "{下周计划}" in paragraph.text:
paragraph.text = paragraph.text.replace("{下周计划}", data['plans'])
# 插入截图
for screenshot in screenshots:
doc.add_picture(screenshot, width=Inches(5.5))
doc.save(output_path)定时任务:每周五16:00自动运行,16:30邮件推送草稿。
4.3 踩坑记录
-
坑1:LLM总结过于笼统
早期输出"本周工作进展顺利",毫无信息量。解决:在提示词中强制要求"引用具体数字"。 -
坑2:截图分辨率问题
不同电脑分辨率不同,截图位置偏移。解决:用窗口句柄定位,而非绝对坐标。 -
坑3:模板频繁变更
领导每周换格式。解决:模板抽离为可配置Word文档,RPA动态读取。
4.4 效果
-
从2小时/周→10分钟/周(检查LLM生成内容)
-
报告质量稳定,不受周五疲劳影响
五、技术选型:本地RPA vs 云端RPA的实测对比
做这4个案例,我换过3款工具,最终选型逻辑:
| 需求 | 某云RPA | 本地RPA方案 |
|---|---|---|
| 内网/离线环境 | ❌ 必须联网 | ✅ 纯本地运行,离线可执行 |
| 数据安全 | ⚠️ 数据上云 | ✅ 全本地存储,不上传第三方 |
| 打包分发 | ❌ 需安装环境 | ✅ 可打包EXE,双击运行 |
| AI费用 | 按功能/机器人收费 | 自申请API,按token计费 |
| 指纹浏览器 | 部分支持 | 支持紫鸟、比特、HubStudio等 |
选型结论:对数据敏感、需内网离线部署、预算有限的团队,本地RPA方案更合适。
我当前在测试的本地RPA工具实测体验:
这个工具叫蓝印RPA,几个核心能力对应了我们团队的刚需:
-
离线运行:内网环境直接执行,无需联网,这是我们能过等保测评的前提
-
EXE打包:写好的流程打包成可执行文件,同事双击就能跑,不用装环境
-
数据本地存储:所有流程、数据、日志全在本地,符合财务审计要求
-
AI费用透明:接大模型用的是自己申请的API(文心一言、豆包、DeepSeek、Kimi都支持),用多少付多少,一个月AI调用费用几十块
但也存在局限:
-
社区生态不如大厂成熟,部分高级功能文档不够详细
-
遇到冷门问题需要自己去GitHub翻issue或社区提问
-
可视化流程编辑器的体验还有优化空间
对于小团队来说够用且省钱,但如果你需要企业级SLA保障或丰富的预置组件库,建议还是看大厂方案。
六、适合谁?不适合谁?
适合:
-
有重复数据搬运需求的个人开发者/小团队
-
业务系统老旧、不想改造系统的中小企业
-
数据不能上云的合规场景
不适合:
-
追求"零代码"完全不懂技术的用户(仍需基础逻辑配置)
-
流程极度复杂、每一步都需要人工判断的场景
-
期望100%无人值守、一次配置永久不管的心态
RPA+AI Agent不是万能药。它最适合的是那些重复、规则明确、耗时间的活儿。
我这一年最大的感受:省下来的时间不是让你摸鱼的,是用来做更有价值的事的。
如果你也在被复制粘贴折磨,建议从最简单的场景开始——自动登录+抓取数据,跑通了再慢慢加AI能力。
技术是用来解决问题的,不是用来炫技的。

欢迎加入 MCP 技术社区!与志同道合者携手前行,一同解锁 MCP 技术的无限可能!
更多推荐


 13
13 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)