为什么 AI 智能体不能拥有无限上下文?三重硬约束的深度拆解

如果你使用过 ChatGPT、Claude 或其他 AI 助手,你可能会注意到一个现象:当你和它进行很长的对话,或者在一次提问中塞入大量文档后,AI 的回答质量会明显下降——它开始"忘记"你说过的话、忽略关键细节、甚至给出前后矛盾的答案。
你可能会想:为什么不能直接把上下文窗口做得无限大呢?这样不就能记住所有信息了吗?
答案是:不是不想,而是做不到。让 AI 智能体拥有"无限上下文"这件事,被三道硬约束死死卡住。这三道约束不是工程上的小麻烦,而是根植于数学、物理和信息论三个层面的根本性限制。下面我们来逐一拆解。
第一重约束:注意力机制的二次复杂度(数学层面)
要理解上下文限制,必须先理解 Transformer 架构的核心机制——自注意力(Self-Attention)。
自注意力的工作原理可以这样理解:对于输入序列中的每一个词元(token),模型都要让它和序列中的每一个其他词元进行交互,计算它们之间的关联程度。这就像一个圆桌会议上,每个参会者都要和所有其他参会者两两握手。

10 个人需要 100 次握手,20 个人需要 400 次,40 个人需要 1600 次。人数翻倍,握手次数变为原来的 4 倍。这就是 O(n²) 二次复杂度的核心含义:计算量不是随上下文长度线性增长,而是平方级增长。
具体到实际数据:处理 1,000 个 token 需要约 100 万次注意力运算,处理 32,000 个 token 需要约 10 亿次,处理 100,000 个 token 则需要约 100 亿次。上下文从 32K 翻到 100K,长度只增加了约 3 倍,但计算量暴增了 10 倍。
以一个 70 亿参数的 LLaMA 模型为例(FP16 精度,32 个注意力头,32 层),注意力矩阵的内存占用情况如下:序列长度为 512 时仅需 0.5GB,序列长度为 2,048 时增长到 8GB,序列长度为 8,192 时暴涨到 128GB——这已经超过了单张 H100 GPU 的 80GB 显存容量。序列长度达到 32,768 时,仅注意力矩阵就需要 2,048GB,相当于 25 张 H100 才能勉强装下。
核心公式:注意力矩阵内存占用 = 头数 × n² × batch_size × 层数 × 精度字节数
这里的 n² 是罪魁祸首——它是唯一随上下文长度平方级增长的因子。
即便使用 FlashAttention 等优化技术避免了完整存储注意力矩阵,计算量本身的二次增长依然存在。在短序列(128-256 token)时,注意力计算只占模型总计算量的不到 10%;但当序列增长到 1K-4K 以上时,注意力的计算量会占据总计算量的 80% 以上。
第二重约束:KV 缓存的内存爆炸(硬件层面)
如果说二次复杂度是理论上的限制,那么 KV 缓存(Key-Value Cache)就是工程实践中最直接、最痛苦的瓶颈。
KV 缓存是什么?在 LLM 的自回归生成过程中,模型每生成一个新 token,都需要和之前所有已生成的 token 进行注意力计算。如果不做任何优化,每生成一个 token 就要把整个历史重新算一遍。KV 缓存的思路是:把已经计算过的 Key 和 Value 向量存起来,生成新 token 时直接读取,避免重复计算。
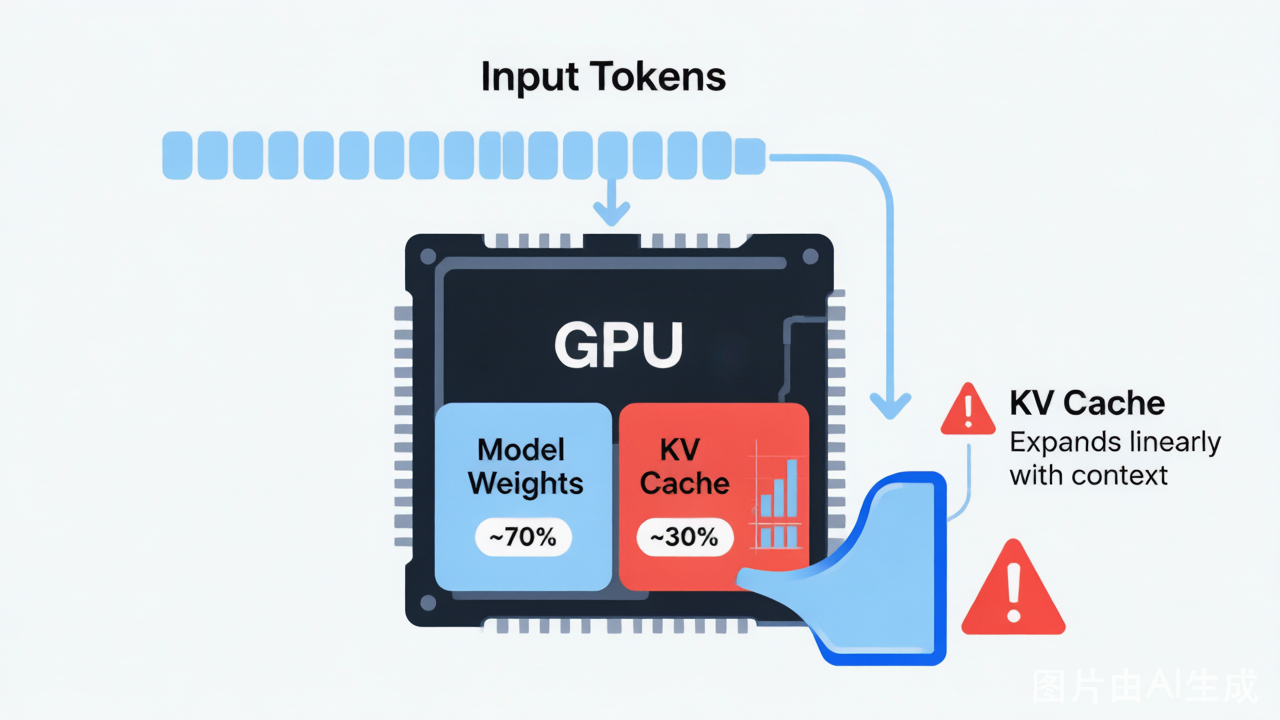
KV 缓存的大小由以下公式决定:
KV 缓存总大小 = batch_size × sequence_length × 层数 × 2 × 头数 × 头维度 × 精度字节数
注意其中的 sequence_length 项:KV 缓存的大小与上下文长度线性正比。上下文从 4K 增长到 128K,缓存就增大 32 倍。以 Llama 2 13B 为例,单个 4K 上下文的请求就需要约 12.5GB 的 KV 缓存,几乎和模型权重本身一样大。如果同时服务 8 个用户,缓存就需要约 100GB。
对于 70B 参数的大模型,情况更加严峻:模型权重本身(FP16)就需要约 140GB,已经需要多张 GPU 才能装下。再加上 KV 缓存,剩余空间极为有限。这就是为什么在 API 服务中,上下文长度越长、同时在线用户越多,需要的 GPU 数量就呈指数级增长——服务成本直接爆炸。
更关键的是,KV 缓存不仅占用空间,还消耗内存带宽。在生成每个新 token 的解码阶段,模型必须从 GPU 显存中读取完整的 KV 缓存。GPU 的计算能力增速远快于内存带宽增速,导致大量计算单元处于"等数据"的空闲状态。KV 缓存越大,这种等待就越严重,推理延迟就越高。
关键洞察:KV 缓存是一个"优化跑步机"——它通过牺牲内存来换取计算效率,但内存瓶颈本身又催生了更严峻的限制。这是一个无法绕开的物理权衡。
第三重约束:信噪比的崩塌(信息论层面)
前两道约束是"做不做得到"的问题,而第三道约束是"做到了有没有用"的问题。
即使我们拥有无限的算力和内存,把上下文窗口做得任意大,一个更根本的问题会出现:模型真的能从海量信息中准确地提取出最相关的内容吗?

答案是不行。研究表明,当上下文长度大幅增加时,模型的注意力会被分散,出现所谓的"迷失在中间"(Lost in the Middle)现象。模型对序列开头和结尾的信息关注较多,但对中间位置的关键信息却容易忽略。你塞入的信息越多,无关噪声就越多,真正有价值的信号被淹没的概率就越大。
一个巨大的上下文窗口就像一个巨大的"杂物抽屉"。如果你把日志、旧需求、矛盾笔记等所有信息都一股脑塞进去,模型会被噪声淹没,导致输出质量比提供更少但更结构化的信息时更差。
小窗口加高质量信息,效果远胜于大窗口加大量噪声。这是信息论的基本原理——信息检索的质量取决于信噪比,而非绝对信息量。
用一句通俗的话总结:你能给 AI 的信息越多,AI 反而越容易"分心"。这不是 AI 不够聪明,而是任何信息处理系统都面临的基础性约束。
三重约束的叠加效应
数学层:O(n²) 复杂度
上下文加倍,计算量变为 4 倍。这是 Transformer 架构的基因性限制,无法通过工程手段彻底消除。
硬件层:KV 缓存膨胀
缓存随上下文线性增长,但 GPU 显存有限。70B 模型在 128K 上下文下,仅缓存就可能需要数百 GB。
信息层:信噪比退化
上下文越大,有效信号越容易被噪声淹没。模型在长上下文中更容易"迷失"关键信息。
这三道约束不是独立存在的,而是相互叠加、相互放大的。数学层面的复杂度导致计算需求暴增,计算需求暴增迫使更多 GPU 并行工作,而并行又带来通信开销和 KV 缓存的分布式管理难题。同时,越来越大的上下文让信噪比问题越来越严重。三重约束形成了一个"不可能三角"——你无法同时拥有无限上下文、低成本推理和高质量输出。
业界如何应对?构建记忆系统而非更大的缓冲区
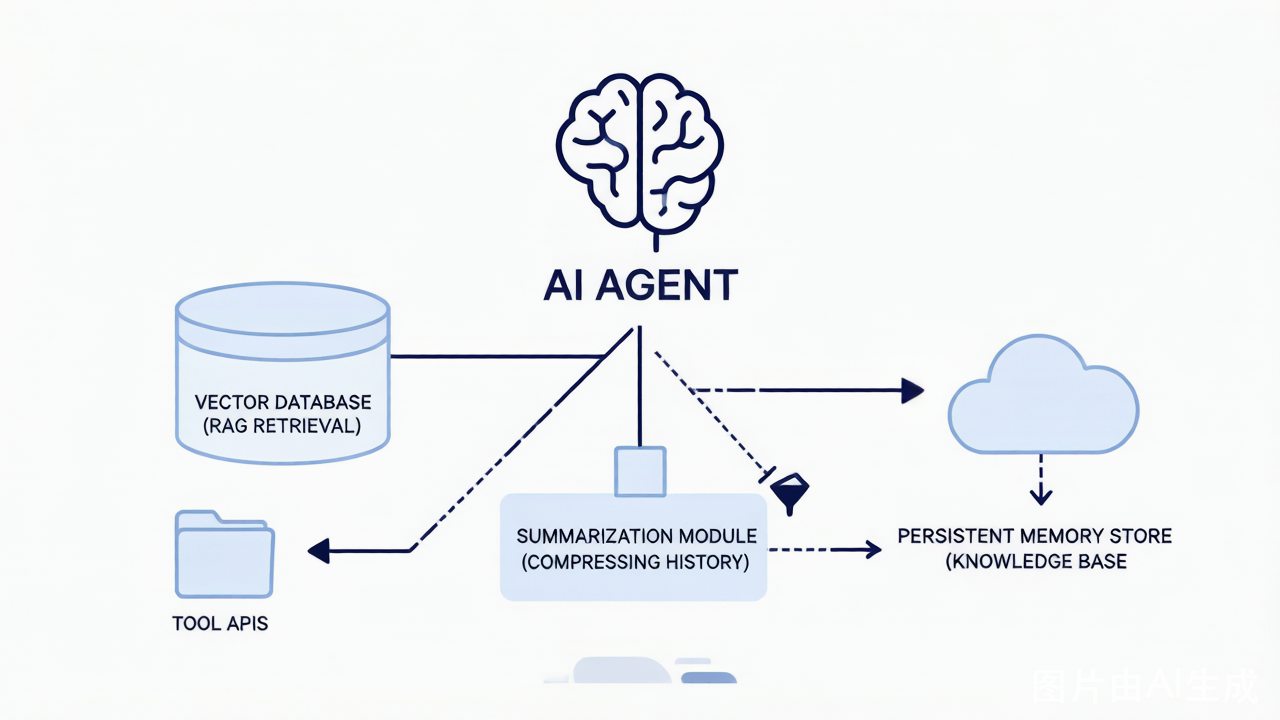
既然"暴力扩展上下文"这条路走不通,业界正在转向更聪明的策略。核心思想可以概括为一句话:不要把所有信息都塞进上下文,而是让 AI 学会"按需取用"信息。
目前主流的技术方案包括以下几种:
| 方案 | 核心思路 | 代表技术 |
|---|---|---|
| 检索增强生成(RAG) | 不把所有数据放入上下文,而是先查询外部知识库,仅把最相关的文档片段提供给模型 | 向量数据库 + 语义检索 |
| 层次化摘要 | 对长文档或历史对话进行多层级的、有损但有用的摘要,保留决策、约束等核心信息 | 递归摘要、滑动窗口摘要 |
| 稀疏注意力 | 不再让每个 token 关注所有 token,只计算局部窗口或特定模式,将复杂度从 O(n²) 降至 O(n×k) | Longformer、BigBird |
| 线性注意力 | 使用数学近似,通过改变矩阵乘法顺序避免实例化 n×n 矩阵,实现 O(n) 复杂度 | Performer、Infini-attention |
| 工具支持的持久记忆 | 让模型使用外部工具来读写持久化记忆,而不是把所有记忆都塞进当前会话 | MCP 协议、文件系统读写 |
| 智能体工作流拆分 | 将复杂任务拆解,由不同的子智能体分阶段处理,每个子智能体只获取其任务所需的特定上下文 | 多 Agent 协作、任务编排 |
其中,RAG(检索增强生成)是目前最主流、最有效的方案。它的思路很像人类的记忆方式:你不需要把整本百科全书背下来,只需要知道"去哪找"和"怎么查"。RAG 让 AI 具备了类似的能力——上下文窗口只存放当前任务最关键的信息,而庞大的知识库则通过检索按需调用。
Google DeepMind 提出的 Infini-attention 是另一个值得关注的方向。它通过一个固定大小的内存矩阵来替代线性增长的 KV 缓存,在 65K token 的上下文长度下实现了 114 倍的内存压缩,并成功将短序列训练获得的能力泛化到 100 万 token 的长序列。
行业共识:AI 记忆的未来不在于"更大的窗口",而在于构建混合记忆系统。就像人脑有短期记忆、工作记忆和长期记忆的分工一样,未来的 AI 系统将是上下文窗口(即时信息)+ 检索数据库(外部知识)+ 压缩摘要(历史浓缩)+ 持久存储(跨会话记忆)的组合。
总结
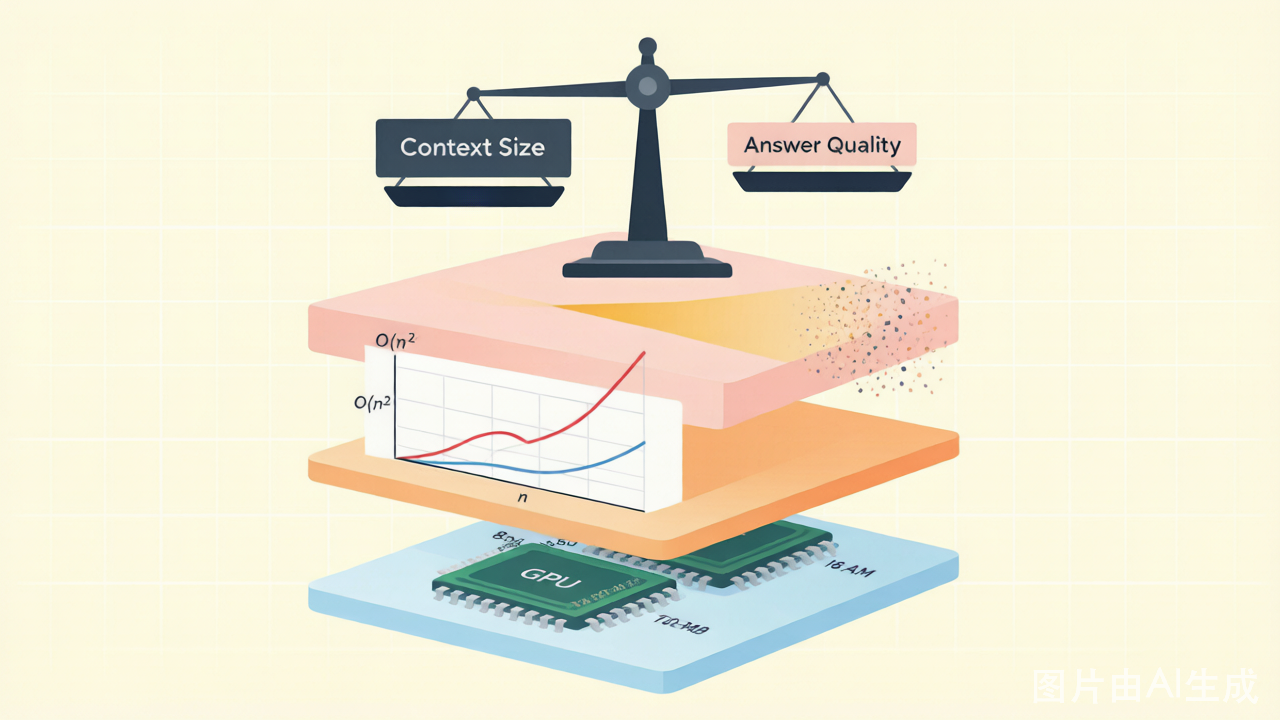
回到最初的问题:为什么 AI 智能体不能拥有无限上下文?
答案不是单一的,而是三道硬约束层层叠加的结果:
在数学层面,Transformer 自注意力的 O(n²) 复杂度让计算量随上下文长度平方级增长,这是架构本身的基因性限制。
在硬件层面,KV 缓存随上下文线性膨胀,而 GPU 显存是有限的。大模型加长上下文加多用户并发,三者叠加会导致硬件需求指数级增长,成本不可承受。
在信息论层面,更大的上下文并不等于更好的答案。当噪声淹没信号时,AI 反而会"迷失在信息的海洋中",输出质量不升反降。
这三重约束形成了一个"不可能三角":你无法同时拥有无限上下文、低成本推理和高质量输出。任何号称"无限上下文"的方案,本质上都是在用某种巧妙的折中——比如压缩、检索或注意力近似——来绕过这三道墙中的某一两道。
理解了这个底层原理,你就能更好地理解:为什么使用 AI 时"把信息整理好再给"比"一股脑全塞进去"效果更好,为什么 RAG 架构如此重要,以及为什么 AI 智能体的设计越来越像一个"懂得去哪里找信息"的系统,而不是一个"什么都能记住"的超大内存。
这其实是一个很美的结论:限制塑造了架构,而架构定义了智能的形态。正是因为有了上下文限制,我们才被迫去设计更聪明、更高效的信息组织和检索方式——而这,或许恰恰是让 AI 变得更像"智能体"而非"数据库"的关键一步。
参考资料:Omar Bahgat《Context Windows Explained》、Michael Brenndoerfer《Quadratic Attention Bottleneck》、腾讯云开发者社区《KV缓存详解》、Towards Data Science《How LLMs Handle Infinite Context》等。

欢迎加入 MCP 技术社区!与志同道合者携手前行,一同解锁 MCP 技术的无限可能!
更多推荐
 10
10 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)