MyBatis:高级 - 源码剖析、插件开发与架构设计
一、引言:高级开发的 MyBatis “深水区” 难题
做开发 2 年以上的你,是不是常遇到这些 “知其然不知其所以然” 的问题:
- 用了很久 MyBatis,却不知道 Mapper 接口为什么没有实现类也能调用?
- 想在 SQL 执行前后加监控(比如记录耗时)、加数据权限(比如过滤部门数据),不知道从哪下手?
- 分布式场景下,MyBatis 怎么和分库分表、分布式事务整合,底层会不会有兼容性问题?
这些问题的本质,是对 MyBatis 的底层架构、源码逻辑和扩展机制理解不深。本文会带你 “钻” 进 MyBatis 源码,从核心流程到插件开发,再到架构设计思想,层层拆解,最终让你具备:
1、看懂 MyBatis 源码的能力 —— 排查复杂问题(如 SQL 执行异常、缓存失效)时能定位到具体类和方法;
2、自定义插件的能力 —— 实现 SQL 监控、数据权限、参数加密等定制化需求;
3、基于 MyBatis 做架构设计的能力 —— 在分布式、高并发场景下合理设计持久层。
二、MyBatis 核心架构与执行流程源码剖析
要理解 MyBatis,先得搞懂它的 “骨架”—— 整体架构分层,以及 SQL 从调用到执行的完整流程。这部分会结合源码片段,让你看到每个环节的具体实现。
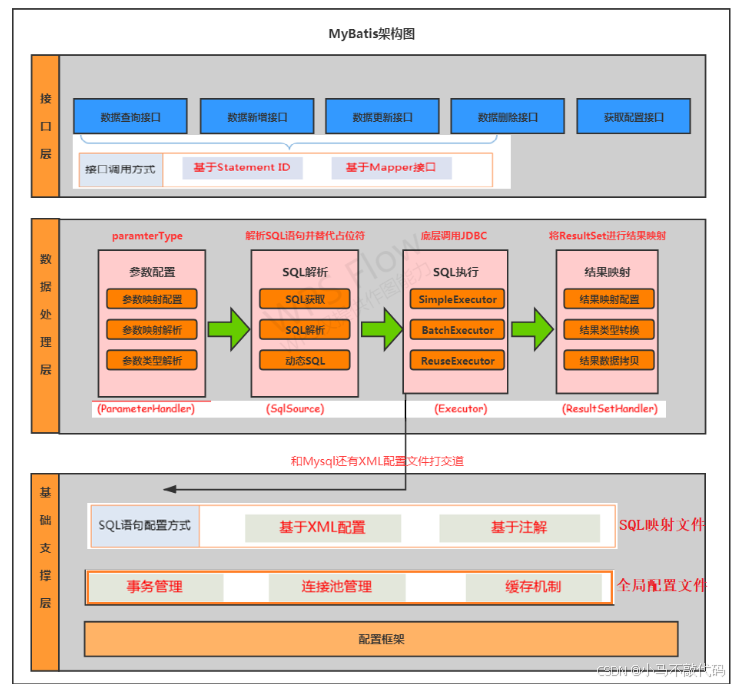
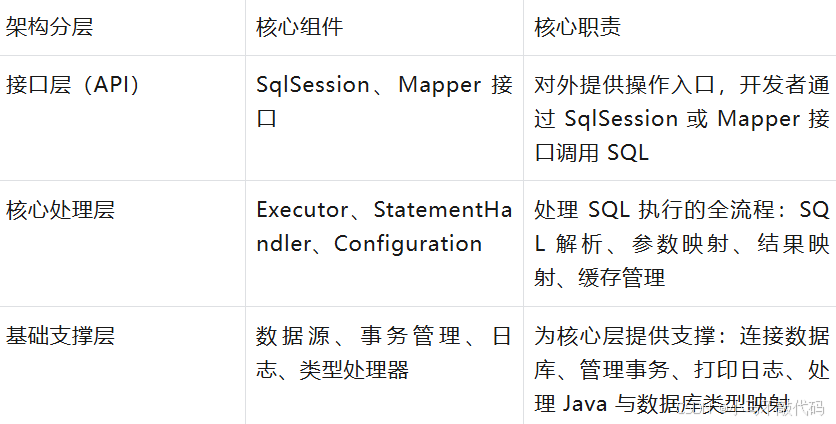
1. MyBatis 整体架构分层(3 层架构)
MyBatis 的架构从下到上分为基础支撑层、核心处理层、接口层,每层职责明确,依赖关系清晰。
MyBatis 整体架构分层图:
关键组件说明:
- Configuration:MyBatis 的 “配置中枢”,存储所有配置信息(数据源、映射文件、插件、缓存等),项目启动时初始化,全局唯一;
- Executor:MyBatis 的 “执行器”,是 SQL 执行的核心,负责调用 StatementHandler 执行 SQL,并管理一级缓存;
- StatementHandler:“SQL 语句处理器”,负责预编译 SQL(创建 PreparedStatement)、设置参数、执行 SQL、处理结果集。
2. SqlSessionFactory 创建流程(源码拆解)
SqlSessionFactory 是 MyBatis 的 “工厂”,负责创建 SqlSession,它的创建过程本质是 “解析配置文件→构建 Configuration→生成工厂实例”。
核心流程:从 XML 到 SqlSessionFactory
以 MyBatis 单独使用(非 Spring 整合)为例,核心代码如下:
// 1. 读取MyBatis配置文件
InputStream inputStream = Resources.getResourceAsStream("mybatis-config.xml");
// 2. 创建SqlSessionFactoryBuilder(建造者模式)
SqlSessionFactoryBuilder builder = new SqlSessionFactoryBuilder();
// 3. 解析配置文件,生成SqlSessionFactory
SqlSessionFactory factory = builder.build(inputStream);
源码拆解:builder.build () 做了什么?
我们跟踪SqlSessionFactoryBuilder.build()方法的源码,关键步骤在XMLConfigBuilder类中:
解析配置文件(XMLConfigBuilder.parse ())
// XMLConfigBuilder.java 核心方法
public Configuration parse() {
if (parsed) {
throw new BuilderException("Each XMLConfigBuilder can only be used once.");
}
parsed = true;
// 解析mybatis-config.xml的根节点<configuration>
parseConfiguration(parser.evalNode("/configuration"));
return configuration;
}
// 解析<configuration>下的所有子节点(数据源、映射文件等)
private void parseConfiguration(XNode root) {
try {
// 1. 解析<properties>标签(配置文件变量)
propertiesElement(root.evalNode("properties"));
// 2. 解析<settings>标签(全局配置,如缓存、下划线转驼峰)
Properties settings = settingsAsProperties(root.evalNode("settings"));
loadCustomVfs(settings);
loadCustomLogImpl(settings);
// 3. 解析<typeAliases>标签(实体类别名)
typeAliasesElement(root.evalNode("typeAliases"));
// 4. 解析<plugins>标签(插件)
pluginElement(root.evalNode("plugins"));
// 5. 解析<environments>标签(数据源、事务)
environmentsElement(root.evalNode("environments"));
// 6. 解析<mappers>标签(映射文件)
mapperElement(root.evalNode("mappers"));
} catch (Exception e) {
throw new BuilderException("Error parsing SQL Mapper Configuration. Cause: " + e, e);
}
}
构建 Configuration 对象
parseConfiguration()方法会把所有配置(数据源、映射文件、插件)解析后存入Configuration对象,这个对象贯穿 MyBatis 生命周期,后续创建 SqlSession、执行 SQL 都依赖它。
生成 SqlSessionFactory 实例
解析完成后,SqlSessionFactoryBuilder会创建DefaultSqlSessionFactory(SqlSessionFactory 的唯一实现类),并传入 Configuration 对象:
// SqlSessionFactoryBuilder.java
public SqlSessionFactory build(Configuration config) {
return new DefaultSqlSessionFactory(config);
}
关键结论:
SqlSessionFactory 是 “单例” 的,项目启动时创建一次即可,不要频繁创建(会导致连接池重复初始化);
所有配置最终都存在 Configuration 中,后续修改配置(如动态添加 Mapper)可直接操作该对象。
3. SqlSession 执行 SQL 的底层逻辑(源码拆解)
当我们调用mapper.selectUserById(1)时,MyBatis 底层是怎么把这个调用转化为 SQL 执行的?整个流程分为 “获取 SqlSession→创建 Mapper 代理→执行 SQL” 三步。
步骤 1:获取 SqlSession(DefaultSqlSessionFactory.openSession ())
// DefaultSqlSessionFactory.java
@Override
public SqlSession openSession() {
// 获取默认的执行器类型(SIMPLE)和事务隔离级别
return openSessionFromDataSource(configuration.getDefaultExecutorType(), null, false);
}
private SqlSession openSessionFromDataSource(ExecutorType execType, TransactionIsolationLevel level, boolean autoCommit) {
Transaction tx = null;
try {
// 1. 从Configuration中获取环境配置(数据源、事务管理器)
final Environment environment = configuration.getEnvironment();
final TransactionFactory transactionFactory = getTransactionFactoryFromEnvironment(environment);
// 2. 创建事务(Transaction)
tx = transactionFactory.newTransaction(environment.getDataSource(), level, autoCommit);
// 3. 创建执行器(Executor),这里会应用插件(Plugin.wrap())
final Executor executor = configuration.newExecutor(tx, execType);
// 4. 创建DefaultSqlSession(SqlSession的实现类)
return new DefaultSqlSession(configuration, executor, autoCommit);
} catch (Exception e) {
closeTransaction(tx); // may have fetched a connection so lets call close()
throw ExceptionFactory.wrapException("Error opening session. Cause: " + e, e);
} finally {
ErrorContext.instance().reset();
}
}
步骤 2:创建 Mapper 接口代理(为什么没有实现类也能调用?)
我们调用sqlSession.getMapper(UserMapper.class)时,MyBatis 会通过MapperProxyFactory动态生成代理对象,核心是InvocationHandler(JDK 动态代理)。
获取 Mapper 代理的入口
// DefaultSqlSession.java
@Override
public <T> T getMapper(Class<T> type) {
// 从Configuration的mapperRegistry中获取Mapper代理工厂
return configuration.getMapper(type, this);
}
// MapperRegistry.java
public <T> T getMapper(Class<T> type, SqlSession sqlSession) {
// 获取MapperProxyFactory(每个Mapper接口对应一个工厂)
final MapperProxyFactory<T> mapperProxyFactory = (MapperProxyFactory<T>) knownMappers.get(type);
if (mapperProxyFactory == null) {
throw new BindingException("Type " + type + " is not known to the MapperRegistry.");
}
try {
// 创建Mapper代理对象
return mapperProxyFactory.newInstance(sqlSession);
} catch (Exception e) {
throw new BindingException("Error getting mapper instance. Cause: " + e, e);
}
}
动态生成代理对象(MapperProxyFactory.newInstance ())
// MapperProxyFactory.java
public T newInstance(SqlSession sqlSession) {
// 创建InvocationHandler的实现类MapperProxy
final MapperProxy<T> mapperProxy = new MapperProxy<>(sqlSession, mapperInterface, methodCache);
return newInstance(mapperProxy);
}
// 生成JDK动态代理对象
protected T newInstance(MapperProxy<T> mapperProxy) {
return (T) Proxy.newProxyInstance(
mapperInterface.getClassLoader(),
new Class[] { mapperInterface },
mapperProxy
);
}
代理对象的调用逻辑(MapperProxy.invoke ())
当我们调用userMapper.selectUserById(1)时,实际会执行MapperProxy.invoke()方法:
// MapperProxy.java
@Override
public Object invoke(Object proxy, Method method, Object[] args) throws Throwable {
try {
// 1. 如果是Object类的方法(如toString()、hashCode()),直接执行
if (Object.class.equals(method.getDeclaringClass())) {
return method.invoke(this, args);
} else {
// 2. 其他方法(Mapper接口方法),通过MapperMethod执行
return cachedInvoker(method).invoke(proxy, method, args, sqlSession);
}
} catch (Throwable t) {
throw ExceptionUtil.unwrapThrowable(t);
}
}
步骤 3:执行 SQL(MapperMethod+Executor+StatementHandler)
MapperMethod是 “Mapper 方法的封装体”,负责把接口方法映射到具体的 SQL 语句,再通过Executor和StatementHandler执行 SQL。
MapperMethod 的执行逻辑
// MapperMethod.java
public Object execute(SqlSession sqlSession, Object[] args) {
Object result;
// 根据SQL类型(SELECT/INSERT/UPDATE/DELETE)执行不同逻辑
switch (command.getType()) {
case INSERT: {
Object param = method.convertArgsToSqlCommandParam(args);
result = rowCountResult(sqlSession.insert(command.getName(), param));
break;
}
case UPDATE: {
Object param = method.convertArgsToSqlCommandParam(args);
result = rowCountResult(sqlSession.update(command.getName(), param));
break;
}
case DELETE: {
Object param = method.convertArgsToSqlCommandParam(args);
result = rowCountResult(sqlSession.delete(command.getName(), param));
break;
}
case SELECT:
if (method.returnsVoid() && method.hasResultHandler()) {
executeWithResultHandler(sqlSession, args);
result = null;
} else if (method.returnsMany()) {
result = executeForMany(sqlSession, args);
} else if (method.returnsMap()) {
result = executeForMap(sqlSession, args);
} else if (method.returnsCursor()) {
result = executeForCursor(sqlSession, args);
} else {
// 单条查询(如selectUserById)
Object param = method.convertArgsToSqlCommandParam(args);
result = sqlSession.selectOne(command.getName(), param);
}
break;
case FLUSH:
result = sqlSession.flushStatements();
break;
default:
throw new BindingException("Unknown execution method for: " + command.getName());
}
if (result == null && method.getReturnType().isPrimitive() && !method.returnsVoid()) {
throw new BindingException("Mapper method '" + command.getName()
+ " attempted to return null from a method with a primitive return type (" + method.getReturnType() + ").");
}
return result;
}
Executor 执行 SQL(以 SimpleExecutor 为例)
SqlSession的selectOne()最终会调用Executor的query()方法:
// SimpleExecutor.java
@Override
public <E> List<E> query(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler) throws SQLException {
// 1. 获取SQL语句(从MappedStatement中获取,MappedStatement是映射文件中<select>等标签的封装)
BoundSql boundSql = ms.getBoundSql(parameter);
// 2. 创建缓存Key(一级缓存的Key由SQL、参数、分页等信息组成)
CacheKey key = createCacheKey(ms, parameter, rowBounds, boundSql);
// 3. 执行查询(先查缓存,再查数据库)
return query(ms, parameter, rowBounds, resultHandler, key, boundSql);
}
@Override
public <E> List<E> query(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, CacheKey key, BoundSql boundSql) throws SQLException {
ErrorContext.instance().resource(ms.getResource()).activity("executing a query").object(ms.getId());
if (closed) {
throw new ExecutorException("Executor was closed.");
}
// 4. 清理本地缓存(如果需要),然后先查一级缓存
if (queryStack == 0 && ms.isFlushCacheRequired()) {
clearLocalCache();
}
List<E> list;
try {
queryStack++;
// 5. 从一级缓存中获取数据
list = resultHandler == null ? (List<E>) localCache.getObject(key) : null;
if (list != null) {
// 6. 缓存命中,处理输出参数(如存储过程的输出参数)
handleLocallyCachedOutputParameters(ms, key, parameter, boundSql);
} else {
// 7. 缓存未命中,从数据库查询
list = queryFromDatabase(ms, parameter, rowBounds, resultHandler, key, boundSql);
}
} finally {
queryStack--;
}
if (queryStack == 0) {
// 8. 处理延迟加载的结果
for (DeferredLoad deferredLoad : deferredLoads) {
deferredLoad.load();
}
deferredLoads.clear();
// 9. 如果是STATEMENT级别的缓存,清空一级缓存
if (configuration.getLocalCacheScope() == LocalCacheScope.STATEMENT) {
clearLocalCache();
}
}
return list;
}
// 从数据库查询的核心方法
private <E> List<E> queryFromDatabase(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, CacheKey key, BoundSql boundSql) throws SQLException {
List<E> list;
// 1. 先向缓存中放入“占位符”,避免重复查询(解决循环依赖)
localCache.putObject(key, EXECUTION_PLACEHOLDER);
try {
// 2. 调用StatementHandler执行SQL,获取结果集
list = doQuery(ms, parameter, rowBounds, resultHandler, boundSql);
} finally {
// 3. 移除占位符
localCache.removeObject(key);
}
// 4. 把查询结果放入一级缓存
localCache.putObject(key, list);
// 5. 如果是存储过程,处理输出参数
if (ms.getStatementType() == StatementType.CALLABLE) {
localOutputParameterCache.putObject(key, parameter);
}
return list;
}
// 真正执行SQL的方法(创建Statement,设置参数,执行查询)
@Override
public <E> List<E> doQuery(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, BoundSql boundSql) throws SQLException {
Statement stmt = null;
try {
Configuration configuration = ms.getConfiguration();
// 1. 创建StatementHandler(这里会应用插件)
StatementHandler handler = configuration.newStatementHandler(wrapper, ms, parameter, rowBounds, resultHandler, boundSql);
// 2. 创建PreparedStatement(预编译SQL)
stmt = prepareStatement(handler, ms.getStatementLog());
// 3. 执行查询,处理结果集
return handler.query(stmt, resultHandler);
} finally {
// 4. 关闭Statement
closeStatement(stmt);
}
}
StatementHandler 处理 SQL 与结果集
StatementHandler是 SQL 执行的 “最终执行者”,负责预编译 SQL、设置参数、执行 SQL、映射结果集:
// PreparedStatementHandler.java(StatementHandler的实现类,处理预编译SQL)
@Override
public <E> List<E> query(Statement statement, ResultHandler resultHandler) throws SQLException {
// 1. 执行SQL(PreparedStatement.execute())
PreparedStatement ps = (PreparedStatement) statement;
ps.execute();
// 2. 处理结果集(通过ResultSetHandler映射到Java对象)
return resultSetHandler.handleResultSets(ps);
}
// ResultSetHandler处理结果集(以DefaultResultSetHandler为例)
@Override
public List<Object> handleResultSets(Statement stmt) throws SQLException {
ErrorContext.instance().activity("handling results").object(mappedStatement.getId());
final List<Object> multipleResults = new ArrayList<>();
int resultSetCount = 0;
// 1. 获取第一个结果集
ResultSetWrapper rsw = getFirstResultSet(stmt);
// 2. 获取结果映射(<resultMap>标签的封装)
List<ResultMap> resultMaps = mappedStatement.getResultMaps();
int resultMapCount = resultMaps.size();
validateResultMapsCount(rsw, resultMapCount);
// 3. 遍历结果集,映射成Java对象
while (rsw != null && resultMapCount > resultSetCount) {
ResultMap resultMap = resultMaps.get(resultSetCount);
// 4. 核心:把ResultSet映射到Java对象列表
handleResultSet(rsw, resultMap, multipleResults, null);
rsw = getNextResultSet(stmt);
cleanUpAfterHandlingResultSet();
resultSetCount++;
}
// 5. 处理存储过程的输出参数
String[] resultSets = mappedStatement.getResultSets();
if (resultSets != null) {
while (rsw != null && resultSetCount < resultSets.length) {
ResultMapping parentMapping = nextResultMaps.get(resultSets[resultSetCount]);
if (parentMapping != null) {
String nestedResultMapId = parentMapping.getNestedResultMapId();
ResultMap nestedResultMap = configuration.getResultMap(nestedResultMapId);
handleResultSet(rsw, nestedResultMap, null, parentMapping);
}
rsw = getNextResultSet(stmt);
cleanUpAfterHandlingResultSet();
resultSetCount++;
}
}
// 6. 返回结果(如果是单条结果,取第一个元素)
return collapseSingleResultList(multipleResults);
}
关键结论:
- Mapper 接口的实现是 JDK 动态代理,核心是MapperProxy;
- SQL 执行的核心流程:SqlSession→MapperMethod→Executor→StatementHandler→ResultSetHandler;
- 一级缓存由Executor的localCache(HashMap)实现,缓存 Key 由 SQL、参数、分页等信息组成。
三、MyBatis 插件开发实战(2 个核心案例)
MyBatis 插件是 “扩展 MyBatis 功能的利器”,基于 JDK 动态代理,能拦截四大核心接口的方法,实现定制化需求。这部分会讲清插件原理,再通过 2 个实战案例教你开发插件。
1. 插件原理:拦截四大核心接口
MyBatis 插件本质是 “动态代理的增强”,能拦截的接口只有 4 个:
- Executor:拦截 SQL 执行(如 query、update);
- StatementHandler:拦截 SQL 预编译、参数设置、结果处理(如 prepare、parameterize、query);
- ParameterHandler:拦截参数设置(如 setParameters);
- ResultSetHandler:拦截结果集处理(如 handleResultSets)。
插件工作流程:
1、开发者实现Interceptor接口,重写intercept()(拦截逻辑)、plugin()(生成代理对象)、setProperties()(接收配置参数);
2、在mybatis-config.xml中配置插件,指定拦截的接口和方法;
3、MyBatis 初始化时,会通过Plugin.wrap()方法为四大接口生成代理对象;
4、调用接口方法时,会先执行插件的intercept()逻辑,再执行原方法。
核心类:Plugin(MyBatis 插件的 “代理工厂”)
Plugin类实现了InvocationHandler,是插件代理的核心,关键方法是wrap()和invoke():
// Plugin.java
public static Object wrap(Object target, Interceptor interceptor) {
// 1. 获取插件要拦截的接口和方法(从Interceptor的@Intercepts注解中解析)
Map<Class<?>, Set<Method>> signatureMap = getSignatureMap(interceptor);
Class<?> type = target.getClass();
// 2. 获取目标对象实现的所有可拦截接口
Class<?>[] interfaces = getAllInterfaces(type, signatureMap);
// 3. 如果有可拦截接口,生成代理对象;否则返回原对象
if (interfaces.length > 0) {
return Proxy.newProxyInstance(
type.getClassLoader(),
interfaces,
new Plugin(target, interceptor, signatureMap)
);
}
return target;
}
// 代理对象的调用逻辑
@Override
public Object invoke(Object proxy, Method method, Object[] args) throws Throwable {
try {
// 1. 获取当前方法所属接口的可拦截方法
Set<Method> methods = signatureMap.get(method.getDeclaringClass());
// 2. 如果当前方法是要拦截的方法,执行插件的intercept()
if (methods != null && methods.contains(method)) {
return interceptor.intercept(new Invocation(target, method, args));
}
// 3. 否则执行原方法
return method.invoke(target, args);
} catch (Exception e) {
throw ExceptionUtil.unwrapThrowable(e);
}
}
2. 实战案例 1:SQL 执行耗时监控插件
需求:记录每一条 SQL 的执行时间,超过 100ms 时打印警告日志,帮助排查慢查询。
步骤 1:实现 Interceptor 接口
package com.example.mybatis.plugin;
import org.apache.ibatis.executor.Executor;
import org.apache.ibatis.mapping.MappedStatement;
import org.apache.ibatis.plugin.*;
import org.apache.ibatis.session.ResultHandler;
import org.apache.ibatis.session.RowBounds;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import java.util.Properties;
// @Intercepts:指定要拦截的接口和方法(这里拦截Executor的query和update方法)
@Intercepts({
@Signature(
type = Executor.class, // 要拦截的接口
method = "query", // 要拦截的方法名
args = {MappedStatement.class, Object.class, RowBounds.class, ResultHandler.class} // 方法参数类型(用于区分重载方法)
),
@Signature(
type = Executor.class,
method = "update",
args = {MappedStatement.class, Object.class}
)
})
public class SqlTimeMonitorPlugin implements Interceptor {
private static final Logger logger = LoggerFactory.getLogger(SqlTimeMonitorPlugin.class);
// 慢查询阈值(毫秒),可通过配置文件设置
private long slowSqlThreshold = 100;
// 核心:拦截逻辑(SQL执行前后记录时间)
@Override
public Object intercept(Invocation invocation) throws Throwable {
// 1. 记录SQL执行开始时间
long startTime = System.currentTimeMillis();
try {
// 2. 执行原方法(SQL查询或更新)
return invocation.proceed();
} finally {
// 3. 计算执行耗时
long costTime = System.currentTimeMillis() - startTime;
// 4. 获取SQL的ID(映射文件中<select>等标签的id,如"com.example.mapper.UserMapper.selectUserById")
MappedStatement ms = (MappedStatement) invocation.getArgs()[0];
String sqlId = ms.getId();
// 5. 打印日志(超过阈值打印警告)
if (costTime > slowSqlThreshold) {
logger.warn("慢查询警告:SQL[{}] 执行耗时:{}ms(阈值:{}ms)", sqlId, costTime, slowSqlThreshold);
} else {
logger.info("SQL[{}] 执行耗时:{}ms", sqlId, costTime);
}
}
}
// 生成代理对象(直接使用MyBatis提供的Plugin.wrap())
@Override
public Object plugin(Object target) {
return Plugin.wrap(target, this);
}
// 接收配置参数(从mybatis-config.xml中读取slowSqlThreshold)
@Override
public void setProperties(Properties properties) {
// 读取配置的阈值,没有则用默认值100
String threshold = properties.getProperty("slowSqlThreshold");
if (threshold != null && !threshold.isEmpty()) {
slowSqlThreshold = Long.parseLong(threshold);
}
}
}
步骤 2:在 mybatis-config.xml 中配置插件
<configuration>
<!-- 配置插件 -->
<plugins>
<plugin interceptor="com.example.mybatis.plugin.SqlTimeMonitorPlugin">
<!-- 设置慢查询阈值为200ms(覆盖默认的100ms) -->
<property name="slowSqlThreshold" value="200"/>
</plugin>
</plugins>
</configuration>
步骤 3:测试效果
执行userMapper.selectUserById(1)后,控制台会打印日志:
INFO [main] c.e.m.p.SqlTimeMonitorPlugin - SQL[com.example.mapper.UserMapper.selectUserById] 执行耗时:50ms
如果执行一条慢 SQL(如复杂联表查询),耗时 300ms,会打印警告:
WARN [main] c.e.m.p.SqlTimeMonitorPlugin - 慢查询警告:SQL[com.example.mapper.OrderMapper.selectOrderList] 执行耗时:300ms(阈值:200ms)
3. 实战案例 2:数据权限控制插件
需求:根据当前登录用户的部门 ID,动态在查询 SQL 的 WHERE 条件后添加 “部门过滤”(如AND dept_id = 101),确保用户只能查看自己部门的数据。
关键思路:
- 拦截StatementHandler的prepare()方法(该方法负责预编译 SQL);
- 解析 SQL 语句,获取 WHERE 子句,动态添加部门条件;
- 从 ThreadLocal 中获取当前登录用户的部门 ID(ThreadLocal 用于存储当前请求的用户信息)。
步骤 1:创建用户上下文工具类(ThreadLocal 存储用户信息)
package com.example.mybatis.context;
// 用户上下文(存储当前登录用户的信息,如用户ID、部门ID)
public class UserContext {
// ThreadLocal:每个线程存储自己的用户信息,避免多线程共享问题
private static final ThreadLocal<UserInfo> USER_THREAD_LOCAL = new ThreadLocal<>();
// 设置当前用户信息(在登录拦截器或Controller中调用)
public static void setUserInfo(UserInfo userInfo) {
USER_THREAD_LOCAL.set(userInfo);
}
// 获取当前用户信息(插件中调用)
public static UserInfo getUserInfo() {
return USER_THREAD_LOCAL.get();
}
// 清除当前用户信息(请求结束后调用,避免内存泄漏)
public static void clear() {
USER_THREAD_LOCAL.remove();
}
// 用户信息封装类
public static class UserInfo {
private Long userId;
private Long deptId; // 部门ID(用于数据权限过滤)
// getter/setter
public Long getUserId() { return userId; }
public void setUserId(Long userId) { this.userId = userId; }
public Long getDeptId() { return deptId; }
public void setDeptId(Long deptId) { this.deptId = deptId; }
}
}
步骤 2:实现数据权限插件(拦截 StatementHandler)
package com.example.mybatis.plugin;
import com.example.mybatis.context.UserContext;
import org.apache.ibatis.executor.statement.StatementHandler;
import org.apache.ibatis.mapping.BoundSql;
import org.apache.ibatis.mapping.MappedStatement;
import org.apache.ibatis.plugin.*;
import org.apache.ibatis.reflection.MetaObject;
import org.apache.ibatis.reflection.SystemMetaObject;
import org.apache.ibatis.session.Configuration;
import java.sql.Connection;
import java.util.Properties;
// 拦截StatementHandler的prepare()方法(预编译SQL前修改SQL)
@Intercepts({
@Signature(
type = StatementHandler.class,
method = "prepare",
args = {Connection.class, Integer.class} // prepare方法的参数:Connection和resultSetType
)
})
public class DataPermissionPlugin implements Interceptor {
// 需要进行数据权限控制的Mapper接口前缀(如"com.example.mapper.dept."开头的Mapper)
private String permissionMapperPrefix;
@Override
public Object intercept(Invocation invocation) throws Throwable {
// 1. 获取当前登录用户信息(从ThreadLocal中获取)
UserContext.UserInfo userInfo = UserContext.getUserInfo();
// 如果没有用户信息(如匿名访问),不进行权限控制,直接执行原方法
if (userInfo == null || userInfo.getDeptId() == null) {
return invocation.proceed();
}
// 2. 获取StatementHandler对象(目标对象)
StatementHandler statementHandler = (StatementHandler) invocation.getTarget();
// 3. 通过MetaObject反射获取StatementHandler的属性(MyBatis提供的反射工具类,避免直接用反射)
MetaObject metaObject = SystemMetaObject.forObject(statementHandler);
// 4. 获取MappedStatement(包含SQL的ID、参数等信息)
MappedStatement mappedStatement = (MappedStatement) metaObject.getValue("delegate.mappedStatement");
// 5. 获取SQL的ID(如"com.example.mapper.dept.UserMapper.selectUserList")
String sqlId = mappedStatement.getId();
// 6. 判断当前SQL是否需要进行数据权限控制(匹配Mapper前缀)
if (!sqlId.startsWith(permissionMapperPrefix)) {
return invocation.proceed();
}
// 7. 获取BoundSql(包含原始SQL语句)
BoundSql boundSql = (BoundSql) metaObject.getValue("delegate.boundSql");
String originalSql = boundSql.getSql();
// 8. 动态添加部门条件(在WHERE子句后拼接"AND dept_id = ?")
String newSql = addDeptCondition(originalSql, userInfo.getDeptId());
// 9. 替换BoundSql的SQL为新SQL(反射修改)
metaObject.setValue("delegate.boundSql.sql", newSql);
// 10. 执行原方法(预编译修改后的SQL)
return invocation.proceed();
}
// 动态添加部门条件到SQL的WHERE子句
private String addDeptCondition(String originalSql, Long deptId) {
// 处理SQL(忽略大小写,找到WHERE子句的位置)
String lowerSql = originalSql.toLowerCase();
int whereIndex = lowerSql.indexOf("where");
if (whereIndex == -1) {
// 如果没有WHERE子句,添加WHERE和部门条件(如"SELECT * FROM user WHERE dept_id = 101")
return originalSql + " WHERE dept_id = " + deptId;
} else {
// 如果有WHERE子句,在WHERE后拼接部门条件(如"SELECT * FROM user WHERE age > 20 AND dept_id = 101")
// 截取WHERE前的SQL和WHERE后的SQL
String beforeWhere = originalSql.substring(0, whereIndex + "where".length());
String afterWhere = originalSql.substring(whereIndex + "where".length());
// 拼接新SQL
return beforeWhere + " " + afterWhere + " AND dept_id = " + deptId;
}
}
@Override
public Object plugin(Object target) {
return Plugin.wrap(target, this);
}
// 接收配置参数(从mybatis-config.xml中读取需要权限控制的Mapper前缀)
@Override
public void setProperties(Properties properties) {
permissionMapperPrefix = properties.getProperty("permissionMapperPrefix");
}
}
步骤 3:配置插件
<configuration>
<plugins>
<!-- 数据权限插件 -->
<plugin interceptor="com.example.mybatis.plugin.DataPermissionPlugin">
<!-- 需要进行权限控制的Mapper接口前缀 -->
<property name="permissionMapperPrefix" value="com.example.mapper.dept."/>
</plugin>
<!-- 其他插件(如SQL耗时监控插件) -->
<plugin interceptor="com.example.mybatis.plugin.SqlTimeMonitorPlugin">
<property name="slowSqlThreshold" value="200"/>
</plugin>
</plugins>
</configuration>
步骤 4:测试效果
1. 登录时设置用户信息(如在 Controller 或拦截器中):
// 模拟登录:当前用户部门ID为101
UserContext.UserInfo userInfo = new UserContext.UserInfo();
userInfo.setUserId(1L);
userInfo.setDeptId(101L);
UserContext.setUserInfo(userInfo);
2. 执行userMapper.selectUserList()(该 Mapper 的 SQL ID 为com.example.mapper.dept.UserMapper.selectUserList):
原始 SQL:SELECT * FROM user WHERE age > 20
修改后 SQL:SELECT * FROM user WHERE age > 20 AND dept_id = 101
3. 请求结束后清除用户信息(避免内存泄漏):
UserContext.clear();
插件开发注意事项:
- 拦截方法的参数类型要准确(如Executor.query()有多个重载,需通过args指定参数类型区分);
- 用MetaObject操作目标对象的属性(MyBatis 提供的反射工具,兼容不同版本);
- 插件执行顺序:配置在前面的插件先执行(如先执行数据权限插件,再执行 SQL 监控插件);
- 避免过度拦截(如只拦截需要的 Mapper 或方法,减少性能损耗)。
四、MyBatis 架构设计思想与扩展点
MyBatis 的架构设计非常灵活,大量使用设计模式,同时提供了多个扩展点,让开发者能在不修改源码的情况下定制功能。
1. 设计模式在 MyBatis 中的应用
MyBatis 中用到了多种设计模式,理解这些模式能帮你更好地看懂源码和设计自己的组件。
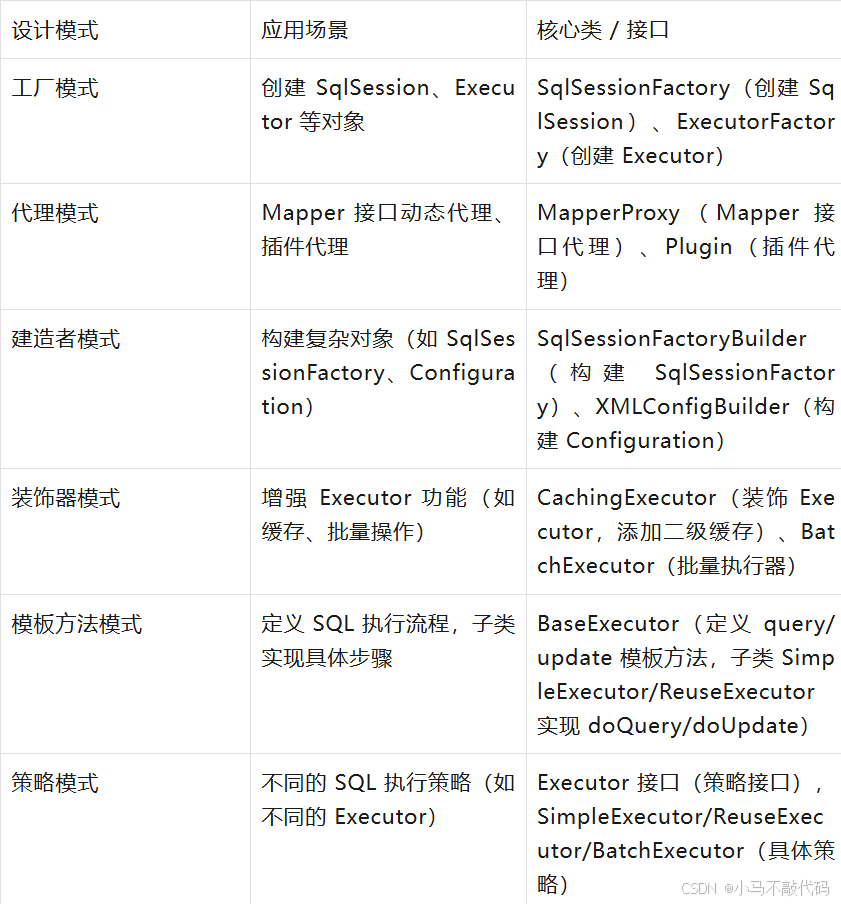
示例:装饰器模式(CachingExecutor)
CachingExecutor是Executor的装饰类,在原Executor的基础上添加了二级缓存功能:
// CachingExecutor.java
public class CachingExecutor implements Executor {
// 被装饰的Executor(如SimpleExecutor)
private final Executor delegate;
// 二级缓存(由Mapper的Cache对象提供)
private final TransactionalCacheManager tcm = new TransactionalCacheManager();
public CachingExecutor(Executor delegate) {
this.delegate = delegate;
delegate.setExecutorWrapper(this);
}
@Override
public <E> List<E> query(MappedStatement ms, Object parameterObject, RowBounds rowBounds, ResultHandler resultHandler) throws SQLException {
BoundSql boundSql = ms.getBoundSql(parameterObject);
CacheKey key = createCacheKey(ms, parameterObject, rowBounds, boundSql);
return query(ms, parameterObject, rowBounds, resultHandler, key, boundSql);
}
@Override
public <E> List<E> query(MappedStatement ms, Object parameterObject, RowBounds rowBounds, ResultHandler resultHandler, CacheKey key, BoundSql boundSql) throws SQLException {
// 1. 获取当前Mapper的二级缓存
Cache cache = ms.getCache();
if (cache != null) {
// 2. 检查是否需要刷新缓存(如配置了flushCache="true")
flushCacheIfRequired(ms);
if (ms.isUseCache() && resultHandler == null) {
// 3. 处理存储过程的输出参数
ensureNoOutParams(ms, boundSql);
// 4. 从二级缓存中获取数据
@SuppressWarnings("unchecked")
List<E> list = (List<E>) tcm.getObject(cache, key);
if (list == null) {
// 5. 缓存未命中,调用被装饰的Executor查询数据库
list = delegate.query(ms, parameterObject, rowBounds, resultHandler, key, boundSql);
// 6. 把查询结果放入二级缓存
tcm.putObject(cache, key, list); // issue #578 and #116
}
return list;
}
}
// 7. 如果没有二级缓存,直接调用被装饰的Executor查询
return delegate.query(ms, parameterObject, rowBounds, resultHandler, key, boundSql);
}
// 其他方法(如update、commit等)都会委托给delegate执行,并处理缓存逻辑
}
2. MyBatis 的可扩展点(3 个核心扩展点)
除了插件,MyBatis 还提供了多个可扩展点,开发者可通过实现接口来定制功能。
扩展点 1:TypeHandler(类型处理器)
作用:处理 Java 类型与数据库类型的映射(如 Java 的 LocalDateTime 与数据库的 DATETIME,Java 的枚举与数据库的 INT)。
实战案例:自定义枚举类型处理器
假设我们有一个UserStatus枚举(0 - 禁用,1 - 正常),需要映射到数据库的 INT 类型:
定义枚举:
public enum UserStatus {
DISABLED(0, "禁用"),
ENABLED(1, "正常");
private final int code;
private final String desc;
UserStatus(int code, String desc) {
this.code = code;
this.desc = desc;
}
// 根据code获取枚举
public static UserStatus getByCode(int code) {
for (UserStatus status : values()) {
if (status.code == code) {
return status;
}
}
throw new IllegalArgumentException("无效的用户状态码:" + code);
}
// getter
public int getCode() { return code; }
public String getDesc() { return desc; }
}
实现 TypeHandler:
package com.example.mybatis.typehandler;
import com.example.mybatis.enums.UserStatus;
import org.apache.ibatis.type.BaseTypeHandler;
import org.apache.ibatis.type.JdbcType;
import java.sql.CallableStatement;
import java.sql.PreparedStatement;
import java.sql.ResultSet;
import java.sql.SQLException;
// 处理UserStatus枚举与INT的映射
public class UserStatusTypeHandler extends BaseTypeHandler<UserStatus> {
// 设置参数(Java枚举→数据库INT)
@Override
public void setNonNullParameter(PreparedStatement ps, int i, UserStatus parameter, JdbcType jdbcType) throws SQLException {
ps.setInt(i, parameter.getCode());
}
// 从ResultSet中获取值(数据库INT→Java枚举)
@Override
public UserStatus getNullableResult(ResultSet rs, String columnName) throws SQLException {
int code = rs.getInt(columnName);
return rs.wasNull() ? null : UserStatus.getByCode(code);
}
@Override
public UserStatus getNullableResult(ResultSet rs, int columnIndex) throws SQLException {
int code = rs.getInt(columnIndex);
return rs.wasNull() ? null : UserStatus.getByCode(code);
}
@Override
public UserStatus getNullableResult(CallableStatement cs, int columnIndex) throws SQLException {
int code = cs.getInt(columnIndex);
return cs.wasNull() ? null : UserStatus.getByCode(code);
}
}
配置 TypeHandler:
<configuration>
<typeHandlers>
<!-- 配置自定义类型处理器,指定枚举类型和处理器 -->
<typeHandler handler="com.example.mybatis.typehandler.UserStatusTypeHandler" javaType="com.example.mybatis.enums.UserStatus"/>
</typeHandlers>
</configuration>
使用效果:
插入时:user.setStatus(UserStatus.ENABLED) → 数据库存储为 1;
查询时:数据库的 1 → 自动映射为UserStatus.ENABLED。
扩展点 2:ObjectFactory(对象工厂)
作用:创建 Java 对象的工厂,默认是DefaultObjectFactory,可自定义创建逻辑(如创建对象时注入依赖、设置默认值)。
实战案例:自定义 ObjectFactory 为对象设置默认值
package com.example.mybatis.objectfactory;
import org.apache.ibatis.reflection.factory.DefaultObjectFactory;
import java.util.List;
import java.util.Properties;
public class CustomObjectFactory extends DefaultObjectFactory {
// 创建单个对象
@Override
public <T> T create(Class<T> type) {
T instance = super.create(type);
// 为User对象设置默认年龄(如果是User类)
if (type == com.example.mybatis.entity.User.class) {
((com.example.mybatis.entity.User) instance).setAge(18); // 默认年龄18
}
return instance;
}
// 创建带参数的对象(如有参构造器)
@Override
public <T> T create(Class<T> type, List<Class<?>> constructorArgTypes, List<Object> constructorArgs) {
T instance = super.create(type, constructorArgTypes, constructorArgs);
// 同样可在这里设置默认值
return instance;
}
// 设置配置参数
@Override
public void setProperties(Properties properties) {
super.setProperties(properties);
}
// 判断是否是集合类型
@Override
public <T> boolean isCollection(Class<T> type) {
return super.isCollection(type);
}
}
配置 ObjectFactory:
<configuration>
<objectFactory type="com.example.mybatis.objectfactory.CustomObjectFactory">
<!-- 可配置参数,在setProperties中读取 -->
<property name="defaultAge" value="18"/>
</objectFactory>
</configuration>
使用效果:
创建User对象时,即使不设置age,默认值也是 18:
User user = new User();
System.out.println(user.getAge()); // 输出18
扩展点 3:LanguageDriver(语言驱动)
作用:解析 SQL 语句的驱动,默认支持 XML 和注解 SQL,可自定义支持其他格式的 SQL(如 Freemarker、Velocity 模板 SQL)。
实战案例:使用 MyBatis 提供的 RawLanguageDriver 支持原生 SQL
MyBatis 默认的XMLLanguageDriver支持动态 SQL,如果需要禁用动态 SQL,可使用RawLanguageDriver:
// Mapper接口中指定LanguageDriver
import org.apache.ibatis.annotations.LanguageDriver;
import org.apache.ibatis.scripting.raw.RawLanguageDriver;
@Mapper
public interface UserMapper {
// 使用RawLanguageDriver,不解析动态SQL(如${}会直接拼接,需注意SQL注入)
@Select("SELECT * FROM user WHERE username = ${username}")
@LanguageDriver(RawLanguageDriver.class)
User selectByUsername(String username);
}
五、分布式场景下 MyBatis 最佳实践
高级开发者常面临分布式、高并发场景,这部分会讲 MyBatis 与分库分表、分布式事务的整合,以及高并发下的性能优化。
1. MyBatis 与 Sharding-JDBC 整合(分库分表)
Sharding-JDBC是轻量级分库分表框架,通过代理数据源实现分库分表,MyBatis 只需配置 Sharding-JDBC 的数据源即可,无需修改 SQL。
整合步骤(SpringBoot+Sharding-JDBC):
- 引入依赖:
<!-- Sharding-JDBC核心依赖 -->
<dependency>
<groupId>org.apache.shardingsphere</groupId>
<artifactId>sharding-jdbc-spring-boot-starter</artifactId>
<version>4.1.1</version>
</dependency>
- 配置分库分表规则(application.yml):
假设我们有 2 个库(db0、db1),每个库有 2 个用户表(user_0、user_1),按user_id取模分库分表:
spring:
shardingsphere:
datasource:
# 配置数据源(db0、db1)
names: db0,db1
db0:
type: com.zaxxer.hikari.HikariDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
jdbc-url: jdbc:mysql://localhost:3306/db0?useSSL=false&serverTimezone=UTC
username: root
password: 123456
db1:
type: com.zaxxer.hikari.HikariDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
jdbc-url: jdbc:mysql://localhost:3306/db1?useSSL=false&serverTimezone=UTC
username: root
password: 123456
# 分库分表规则
rules:
sharding:
tables:
# 逻辑表名(MyBatis中使用的表名)
user:
# 数据节点(库.表)
actual-data-nodes: db${0..1}.user_${0..1}
# 分库策略(按user_id取模2,决定用db0还是db1)
database-strategy:
standard:
sharding-column: user_id
sharding-algorithm-name: database_inline
# 分表策略(按user_id取模2,决定用user_0还是user_1)
table-strategy:
standard:
sharding-column: user_id
sharding-algorithm-name: table_inline
# 分库算法(inline表达式,user_id % 2 = 0→db0,1→db1)
sharding-algorithms:
database_inline:
type: INLINE
props:
algorithm-expression: db${user_id % 2}
table_inline:
type: INLINE
props:
algorithm-expression: user_${user_id % 2}
# 打印执行的SQL(方便调试分库分表逻辑)
props:
sql-show: true
- MyBatis 使用逻辑表名:
Mapper 接口和映射文件中直接使用逻辑表名user,Sharding-JDBC 会自动路由到对应的库和表:
<!-- UserMapper.xml -->
<select id="selectUserById" resultType="User">
SELECT * FROM user WHERE user_id = #{userId}
</select>
- 测试效果:
查询user_id=1:Sharding-JDBC 路由到db1.user_1;
查询user_id=2:路由到db0.user_0;
控制台会打印分库分表后的 SQL:SELECT * FROM db1.user_1 WHERE user_id = ?。
2. MyBatis 与 Seata 整合(分布式事务)
Seata是阿里开源的分布式事务框架,支持 AT、TCC、SAGA 等模式,MyBatis 整合 Seata 只需配置 Seata 的数据源代理即可。
整合步骤(SpringBoot+Seata+AT 模式):
引入依赖:
<!-- Seata核心依赖 -->
<dependency>
<groupId>io.seata</groupId>
<artifactId>seata-spring-boot-starter</artifactId>
<version>1.6.1</version>
</dependency>
<!-- Seata的MyBatis支持(数据源代理) -->
<dependency>
<groupId>io.seata</groupId>
<artifactId>seata-all</artifactId>
<version>1.6.1</version>
</dependency>
配置 Seata(application.yml):
seata:
# 事务组名称(需与Seata Server配置一致)
tx-service-group: my_test_tx_group
# 服务发现(这里用file配置,生产环境可用nacos/eureka)
service:
vgroup-mapping:
my_test_tx_group: default
grouplist:
default: 127.0.0.1:8091
# 数据源代理模式(AT模式需用AT代理)
data-source-proxy-mode: AT
在 Service 方法上添加@GlobalTransactional(分布式事务注解):
@Service
public class OrderService {
@Autowired
private OrderMapper orderMapper;
@Autowired
private InventoryMapper inventoryMapper; // 库存Mapper(另一个服务或库)
// 分布式事务:创建订单+扣减库存,要么都成功,要么都失败
@GlobalTransactional(rollbackFor = Exception.class)
public void createOrder(Order order) {
// 1. 创建订单(MyBatis操作订单库)
orderMapper.insertOrder(order);
// 2. 扣减库存(MyBatis操作库存库,假设是另一个库)
Inventory inventory = new Inventory();
inventory.setProductId(order.getProductId());
inventory.setReduceCount(order.getQuantity());
int rows = inventoryMapper.reduceInventory(inventory);
if (rows == 0) {
throw new RuntimeException("库存不足");
}
// 3. 模拟异常,测试回滚
// throw new RuntimeException("测试分布式事务回滚");
}
}
测试效果:
正常执行:订单创建成功,库存扣减成功;
出现异常(如库存不足):订单创建和库存扣减都会回滚,确保数据一致性。
3. 高并发下 MyBatis 性能优化
- 批量操作优化:
批量插入用foreach标签时,设置batchSize(如每次 500 条),避免 SQL 过长;
优先使用BatchExecutor(执行器类型设为 BATCH),减少数据库连接次数:
// 获取SqlSession时指定Executor类型为BATCH
SqlSession sqlSession = sqlSessionFactory.openSession(ExecutorType.BATCH);
UserMapper userMapper = sqlSession.getMapper(UserMapper.class);
for (User user : userList) {
userMapper.insertUser(user);
}
sqlSession.commit(); // 批量提交
sqlSession.close();
- SQL 预编译缓存:
MyBatis 默认缓存预编译的 PreparedStatement(ReuseExecutor会复用 Statement),高并发场景可使用ReuseExecutor;
数据库开启预编译缓存(如 MySQL 的query_cache_type,但 MySQL 8.0 后已移除,建议用 MyBatis 二级缓存)。
- 数据库连接池优化:
使用 HikariCP(SpringBoot 默认),配置合理的连接池参数:
spring:
datasource:
hikari:
maximum-pool-size: 20 # 最大连接数(根据CPU核心数调整,一般是CPU核心数*2+1)
minimum-idle: 5 # 最小空闲连接数
idle-timeout: 300000 # 空闲连接超时时间(5分钟)
connection-timeout: 30000 # 连接超时时间(30秒)
六、总结
1. MyBatis 初中高级知识点体系梳理
通过三篇文章,我们构建了完整的 MyBatis 知识体系:
初级:环境搭建、CRUD 基础、配置文件解析,解决 “能用” 的问题;
进阶:动态 SQL、关联查询、缓存机制,解决 “用好” 的问题;
高级:源码剖析、插件开发、架构设计,解决 “会改、会扩展” 的问题。
2. 高级开发者能力提升路径
源码阅读:从SqlSessionFactoryBuilder→SqlSession→Executor→StatementHandler,跟踪 SQL 执行全流程;
插件开发:从简单的 SQL 监控,到复杂的数据权限、参数加密,积累实战经验;
架构设计:结合分库分表、分布式事务,设计高可用、高并发的持久层;
性能优化:从 SQL 优化、缓存优化、连接池优化,到 JVM 优化,全方位提升系统性能。

欢迎加入 MCP 技术社区!与志同道合者携手前行,一同解锁 MCP 技术的无限可能!
更多推荐

 21
21 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)