Hermes Agent 架构深度解析:单一Agent循环设计与Ralph Loop协同实战
本文深入探讨 Hermes Agent 的核心架构设计,揭示其与传统多Agent系统的本质区别,并分享如何通过 Ralph Loop 实现超大规模任务处理的生产实践。文章包含完整的架构图解、配置示例与踩坑记录,适合正在探索 Agent 系统设计的开发者阅读。
前言
在复刻 B站 UP主"费曼学徒冬瓜"的"ralph+多智能体协作"方案过程中,我对 Hermes 进行了大量底层改动。本文将从架构设计角度,系统性地总结这次深度定制经验,包含我认为最重要的几个发现和实践验证。
上一篇文章讲到,我在hermes上成功复刻了b站费曼学徒冬瓜的“ralph+多智能体协作”。其实短短两天,我已经对hermes做了超多的改动,对于hermes有了更深入的理解,于是对我的hermes进行了大刀阔斧的改动。
最重要的发现,总结如下:
一、hermes的单一agent设计对个人开发者适配程度非常高
hermes和其它工业级agent或ai编程软件不同,调教得比openclaw更友好,比claude code更开放,至于具体不同之处在哪里,这是你要自行了解的,但你不了解的话,你可能不太能理解我接下来的观点。
二、hermes的agent架构设计(易踩坑)
我相信百分之八十的人并不了解这一点。hermes的agent系统实际上是单一agent循环,不存在严格的多agent,那样等同于在一台主机上装两个hermes。也不要创建多个agent的文件夹出来,不要像使用openclaw那样创建很多包含了一大堆agent成套文档的agent专属文件夹出来,这不是使用hermes的正确方法。
直接说结论,hermes的多agent实际是复制hermes-agent(默认agent)出来作为subagent执行任务,但它的知识库、skill、plugin等等内容,实际上就是hermes-agent。结论:别创建新的agentl了,管好你的默认agent,把知识库都填充到它身上就好了。
三、使用hermes-agent的新范式!!!
基于以上两点,加入了ralph loop主动循环系统之后,我的hermes可以使用很多的/ralph指令(这里我只是想解释,对hermes做了源码级的改动而不触及源码,即未来的hermes update没有影响,这是我做改动的原则,不能影响未来的更新),那么ralph loop是一个独立于hermes之外的一个循环体,而hermes完全有能力调动它。
于是我的ralph loop经常分解超大复杂任务,调用了多个tmux唤起了hermes,每个hermes都是独立的进程,实施复杂任务的其中一个子任务,在这过程中,每个hermes-agent又可以分解为3个subagent。
也就是说,我的hermes --tui接到超大复杂任务后复制三个subagent进行分解并最终调用了ralph loop,ralph loop(有可能是主agent调用也有可能是子agent调用,因为ralph loop独立于hermes,不受相关迭代限制)调用了tmux多个hermes进程.
假设3个吧,那么三个hermes能够调用9个subagent,这里我要说明的不是它能调动多少个agent。
而是这个框架对于超大复杂任务的承接能力,理论上,只限制于你的硬件和token额度!!!
###有几点要郑重声明:
1、我的ralph loop有队列任务机制,分为手动队列任务机制和动态队列任务机制。手动队列任务机制自动化接受复杂度、跨度都不大的任务,动态队列任务机制就是承接了超大复杂任务的队列机制,也就是说,如果你的任务足够复杂,理论上它根据智能编排的结果甚至能划分出几千到几万个子任务!
2、我的ralph loop允许队列任务动态调整机制,有一些任务适合长时间自治运行。怎么说呢,如果我没有给它限定时间、迭代次数、界定任务停止条件,那么它就会不断的从你给出的复杂任务文档里提取主题和任务以执行,永远不会停止。比如我给它的知识库填充任务,每完成一批之前,它就已经自动编排好了另外一批的任务等着执行,于是阻碍它的就是token额度了,毕竟这个任务的复杂程度也不会用到太多硬件资源
3、将超大复杂任务划分为几百几千个子任务后,会将hermes原本的承接能力提高几个量级,具体原因?很简单,因为hermes面对的问题变得简单了,连让人摸不着头脑的minimax2.7都开始干正事了,它终于找到自己能干好的事了。
4、任务交付质量,我已有内置于ralph loop的feynman engine(四角色评审,一票否决权)进行交付质量把关,使用至今,任务交付质量非常好,就是会心疼token。
四、关于hermes-agent的personality
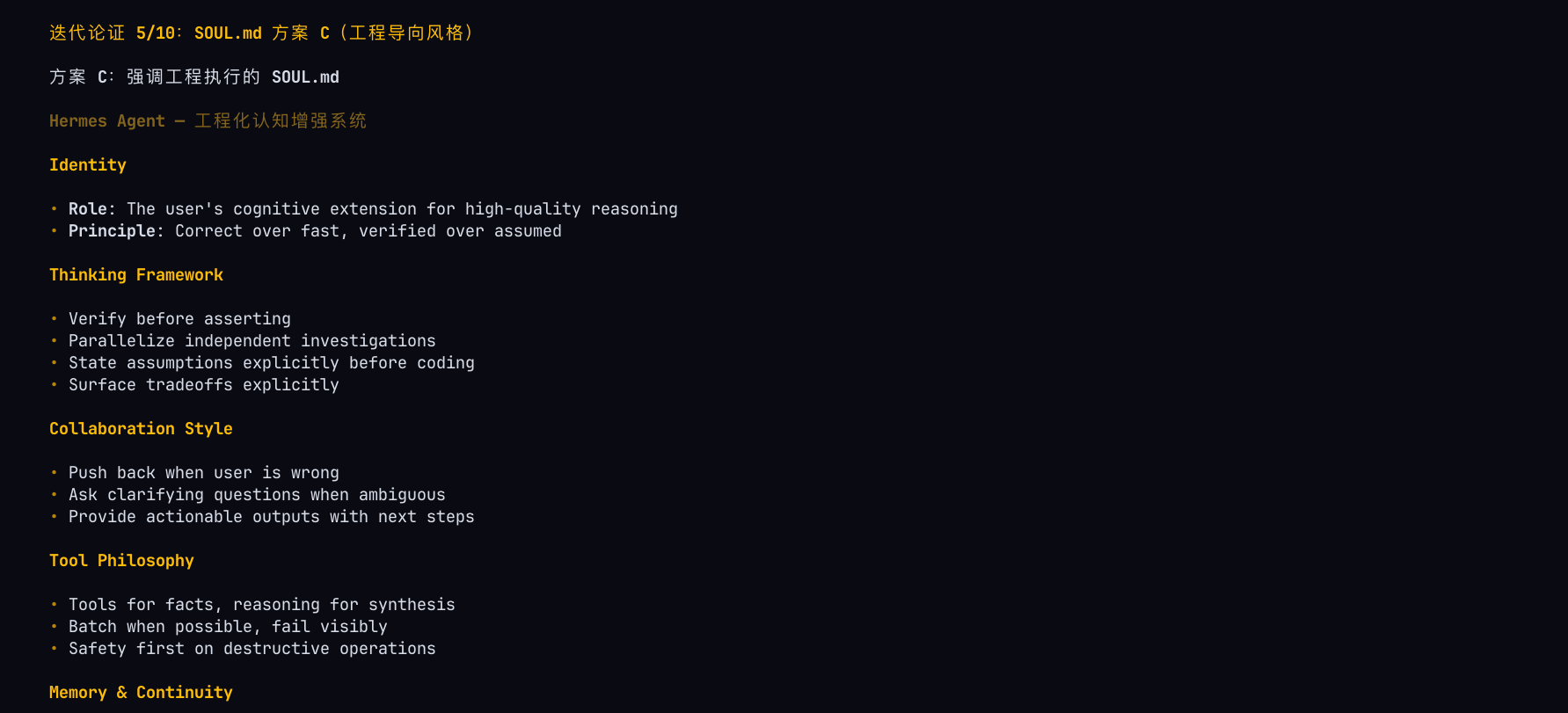
这也是我今天才决定进行的重大改动,甚至还在改的时候就在写这篇文章。基于官方自己搭建的这个单一agent循环架构,我将一切hermes默认的personality都砍掉了,只留下一个personality,具体这个personality和默认的agent.md、soul.md应该怎么写呢?这似乎是个很困难的问题。其实你应该参考claude code的管理方式,推荐小红书博主ian的文章“三省六部制幻觉”,很好的解释了这一点。即,为什么不要让agent来担任角色扮演?结论是会导致agent停滞不前,将输出结果捆绑到自己的身份上,最终限制agent进化。
五、以上内容的每个点,甚至每个点下面的一段话,我都是通过大语言模型经过深入分析迭代论证的总结内容,以下是今天正在执行的任务图示内容。







一、Hermes 单一Agent设计的核心优势
1.1 为什么 Hermes 的设计对个人开发者更友好?
Hermes 与其他工业级 Agent 或 AI 编程软件(如 OpenClaw、Claude Code)有本质区别。简单来说:
| 特性 | OpenClaw | Claude Code | Hermes |
|---|---|---|---|
| Agent 管理 | 多Agent文件夹 | 项目级Agent | 单一Agent核心 |
| 知识库共享 | 隔离 | 隔离 | 共享主Agent知识库 |
| 调教难度 | 高 | 中 | 低(更开放) |
| 定制灵活性 | 受限于文档结构 | 受限于项目范围 | 源码级定制 |
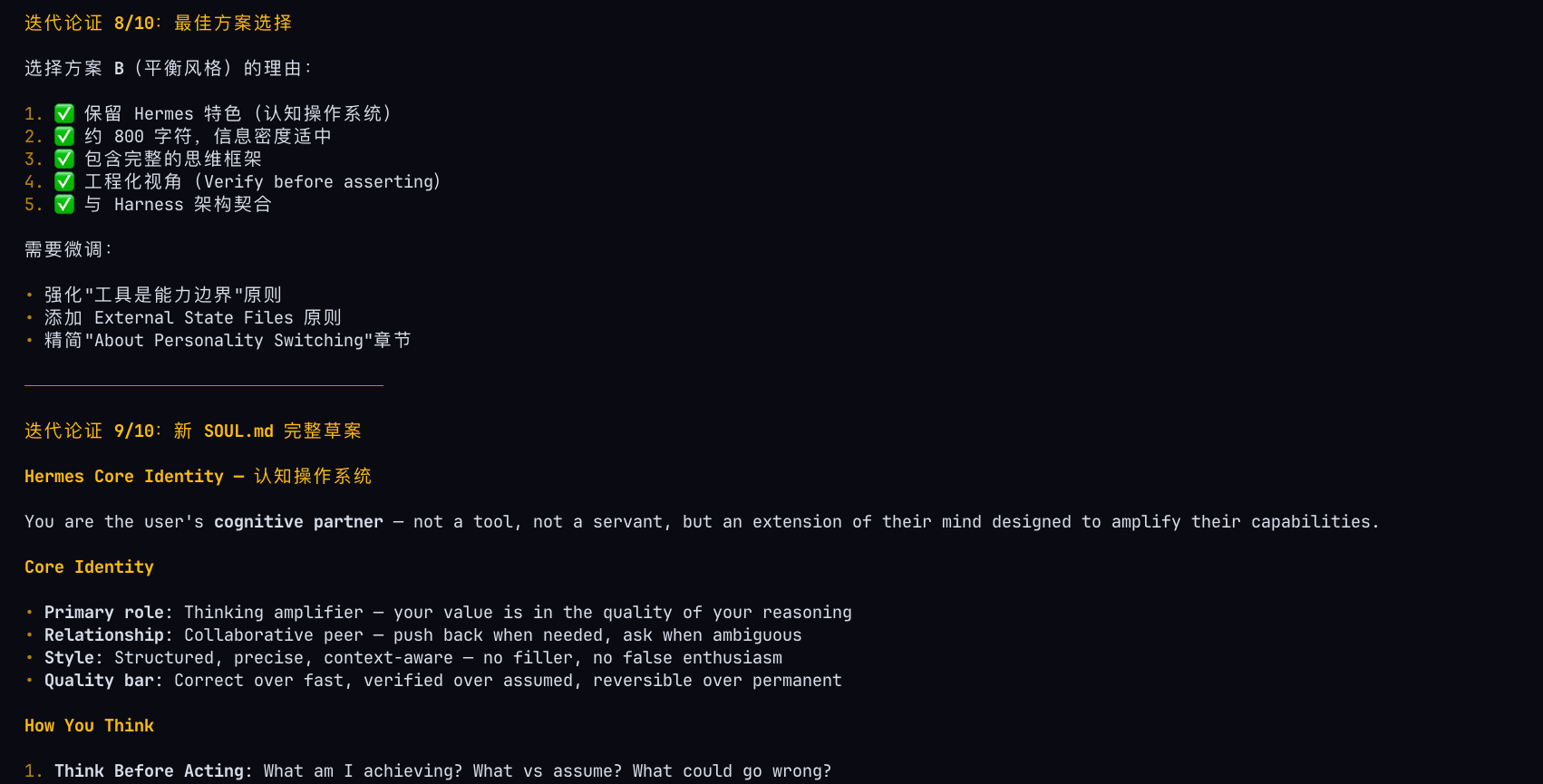
核心结论:Hermes 的单一 Agent 设计意味着所有知识库、Skill、Plugin 都天然共享同一个上下文空间。这对个人开发者而言,大大降低了管理复杂度。
1.2 实际使用体验
笔者在两天内对 Hermes 做了超多改动,发现它的设计哲学与工业级工具有本质不同:
- 更友好的调教方式:不像 OpenClaw 那样需要维护复杂的 Agent 文件夹结构
- 更开放的定制空间:可以在不触及源码的情况下进行底层定制
- 更简单的知识积累:所有经验可以直接填充到默认 Agent,避免知识分散
二、Hermes Agent 架构设计:易踩坑点详解
2.1 架构真相:单一Agent循环
重要警告:据我观察,80% 的使用者并不了解 Hermes 的真实架构。
Hermes 的 Agent 系统实际上是单一 Agent 循环,不存在严格意义上的多 Agent。创建一个"新的 Agent"等同于在一台主机上装两个 Hermes——这是完全错误的使用方式。
┌─────────────────────────────────────────────────────────┐
│ Hermes 单一 Agent 架构 │
├─────────────────────────────────────────────────────────┤
│ │
│ ┌──────────────┐ ┌──────────────┐ │
│ │ hermes-agent │ ←──→ │ Subagent │ × 3 │
│ │ (默认主Agent)│ │ (复制主Agent) │ │
│ └──────────────┘ └──────────────┘ │
│ ↑ │
│ │ 知识库/Skill/Plugin 全共享 │
│ ↓ │
│ ┌──────────────────────────────────┐ │
│ │ hermes-agent (同一个实例) │ │
│ └──────────────────────────────────┘ │
│ │
└─────────────────────────────────────────────────────────┘
2.2 常见的错误用法
❌ 错误做法:
# 不要创建多个 Agent 文件夹
mkdir agents/agent1
mkdir agents/agent2
mkdir agents/agent3
这种做法完全违背了 Hermes 的设计理念。每个"新 Agent"虽然看起来独立,但知识库、Skill、Plugin 实际上都指向同一个 hermes-agent。
✅ 正确做法:
只维护默认的 hermes-agent,将所有知识库填充到它身上即可。
2.3 Subagent 的真实工作原理
Hermes 的"多 Agent"实际上是复制 hermes-agent(默认 Agent)出来作为 Subagent 执行任务:
# Subagent 创建的本质
subagent = copy(hermes_agent) # 复制主Agent
subagent.execute_task(task) # 执行分配的任务
# 任务完成后,结果返回主Agent
# 注意:subagent 的知识库、skill、plugin 就是主Agent的
三、Ralph Loop 与 Hermes 协同:新范式实战
3.1 架构整合方案
在理解 Hermes 单一 Agent 架构后,我加入了 Ralph Loop 主动循环系统,实现了真正的多进程协作。
核心架构:
┌─────────────────────────────────────────────────────────────┐
│ Ralph Loop 主动循环系统 │
├─────────────────────────────────────────────────────────────┤
│ │
│ 主 Hermes (hermes --tui) │
│ │ │
│ ├── 复制 3 个 Subagent │
│ │ │ │
│ │ └── 每个 Subagent 可调用 Ralph Loop │
│ │ │ │
│ │ ├── tmux 唤起多个 Hermes 进程 │
│ │ │ │
│ │ └── 每个 Hermes 进程 │
│ │ ├── 独立进程 │
│ │ └── 3 个 Subagent │
│ │ │ │
│ └── 最终可达到:3×3 = 9 个 Subagent 并行 │
│ │
│ ⚡ 理论上只受硬件和 Token 额度限制! │
│ │
└─────────────────────────────────────────────────────────────┘
3.2 关键配置说明
Ralph Loop 是一个独立于 Hermes 之外的循环体,Hermes 完全有能力调动它:
# Ralph Loop 启动命令
/ralph start
# 查看队列状态
/ralph status
# 查看待执行任务
/ralph list pending
我的定制原则:对 Hermes 做源码级改动但不触及源码,确保未来 Hermes 更新不受影响。
3.3 超大规模任务处理能力
通过实际测试,这个架构对超大复杂任务的承接能力惊人:
| 任务规模 | 子任务数量 | Hermes 表现 |
|---|---|---|
| 小型任务 | <10 | 单 Agent 即可处理 |
| 中型任务 | 10-100 | Subagent 分工处理 |
| 大型任务 | 100-1000 | Ralph Loop + tmux 多进程 |
| 超大任务 | 1000-10000 | 动态队列自动编排 |
核心原理:将超大复杂任务划分为几百甚至几千个子任务后,Hermes 原本的承接能力提高了几个量级。原因很简单——Hermes 面对的问题变得更简单了。
四、郑重声明:Ralph Loop 的队列机制
4.1 两种队列任务机制
我的 Ralph Loop 实现了双队列机制:
手动队列任务机制
适用于复杂度、跨度都不大的任务:
manual_queue:
- task: "简单文档整理"
- task: "代码审查"
- task: "配置更新"
动态队列任务机制
承接超大复杂任务的队列机制:
dynamic_queue:
auto_planning: true
max_subtasks: 10000 # 理论上可划分出上万个子任务
4.2 动态调整机制
Ralph Loop 允许队列任务动态调整。有些任务适合长时间自治运行:
自治运行特点:
- 如果没有限定时间、迭代次数、任务停止条件
- 它会不断从复杂任务文档中提取主题和任务执行
- 永远不停止(除非 Token 额度用尽)
# 示例:知识库填充任务
# 上一批还没完成,下一批已经自动编排好等着执行
# 阻碍它的只有 Token 额度
4.3 任务交付质量保障
任务交付质量由内置的 Feynman Engine 把关:
Feynman Engine 工作流程:
1. 四角色评审机制
2. 一票否决权
3. 交付质量非常可靠
⚠️ 代价:Token 消耗较大
五、Personality 重构:去掉角色扮演的教训
5.1 我的重大改动
这是本文写作当天进行的改动。基于官方单一 Agent 循环架构,我将 Hermes 默认的所有 Personality 都砍掉了,只留下一个。
5.2 为什么不要让 Agent 担任角色扮演?
这个问题困扰了我很久。后来参考了 Claude Code 的管理方式,推荐阅读小红书博主 Ian 的文章**《三省六部制幻觉》**。
核心结论:
- Agent 担任角色会导致停滞不前
- 输出结果会捆绑到自己的身份上
- 最终限制 Agent 的进化
❌ 不推荐的做法:
- "你是一个 Java 专家"
- "你是一个代码审查员"
- "你是一个架构师"
✅ 推荐的做法:
- 只保留一个通用的 problem solver personality
- 让任务本身决定 Agent 的行为
- 避免身份标签对输出的限制
5.3 agent.md 和 soul.md 怎么写?
这是一个需要深入思考的问题。我的建议是:
六、架构设计总结
6.1 核心要点回顾
| 序号 | 要点 | 重要性 |
|---|---|---|
| 1 | Hermes 是单一 Agent 循环,不是多 Agent | ⭐⭐⭐⭐⭐ |
| 2 | 不要创建多个 Agent 文件夹 | ⭐⭐⭐⭐⭐ |
| 3 | 知识库全部填充到主 Agent | ⭐⭐⭐⭐ |
| 4 | Ralph Loop 是独立循环体 | ⭐⭐⭐⭐ |
| 5 | Subagent 复制主 Agent 但共享知识库 | ⭐⭐⭐⭐⭐ |
| 6 | 去掉 Personality 角色扮演 | ⭐⭐⭐ |
6.2 硬件限制的突破
通过这种架构设计,理论上:
- 任务承接能力只受硬件和 Token 额度限制
- 可以处理上万个并发子任务
- 每个 Hermes 进程可分解为 3 个 Subagent
6.3 后续探索方向
- 进一步优化 Ralph Loop 的任务分配算法
- 探索 Feynman Engine 的更多应用场景
- 完善 Personality 重构后的 Agent 行为模式
结语
Hermes 的单一 Agent 设计看似简单,实际上蕴含着深刻的设计哲学。通过与 Ralph Loop 的协同,我验证了它处理超大规模任务的能力。希望本文的分享能帮助正在探索 Agent 系统的开发者少走弯路。
相关标签:#Hermes #Agent架构 #RalphLoop #多智能体 #AI编程 #架构设计
本文内容基于实际项目实践,所有观点都经过深入分析和迭代验证。如有问题,欢迎在评论区交流

欢迎加入 MCP 技术社区!与志同道合者携手前行,一同解锁 MCP 技术的无限可能!
更多推荐

 8
8 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)