论文浅尝 | 利用多智能体大语言模型实现知识图谱自动化增补(NeurIPS 2025)


01
动机

知识图谱在众多领域中对于结构化知识和推理至关重要,但随着科学文献的爆炸式增长,手动构建与更新知识图谱已难以扩展。传统自然语言处理方法在理解领域术语和复杂语义关系方面存在局限,而现有的大型语言模型虽具备强大的文本理解能力,但在构建知识图谱时常面临幻觉、模式不一致与计算成本高等问题。为此,本文提出 KARMA(Knowledge-graph Augmentation with Reasoning Multi-Agent systems),一个基于多智能体大语言模型的自动化知识图谱增强框架,旨在通过协同式、模块化的智能体系统实现高效、准确、可扩展的知识抽取与集成。

02
贡献

本文的主要贡献包括:
-
提出KARMA多智能体框架:首次将多智能体LLM系统系统化应用于知识图谱增强任务,通过九个专业化智能体协作完成文档解析、实体发现、关系提取、模式对齐与冲突消解,显著提升知识抽取的准确性与一致性。
-
设计跨智能体验证与迭代优化机制:通过智能体间的交叉验证(如关系提取与模式对齐的互检)与基于辩论的冲突消解策略,有效缓解LLM的幻觉问题,提升抽取结果的可信度。
-
实现领域自适应与模块化扩展:支持动态调整提示策略以适配不同科学领域,模块化设计便于融入新实体类型、关系或更新LLM模型,具有良好的可扩展性与适应性。
-
实验验证与开源实现:在三个生物医学领域(基因组学、蛋白质组学、代谢组学)的1200篇PubMed文献上进行系统性实验,结果表明KARMA能识别多达38,230个新实体,LLM验证正确率达83.1%,冲突边减少18.6%,性能显著优于单智能体基线模型。

03
方法

3.1 整体问题定义
给定一个现有知识图谱 和一组非结构化科学文献 ,目标是自动从每篇文献 中提取一组 新的知识三元组 ,并将其融合到 中,生成一个增强的知识图谱 。
3.2 智能体核心方法与流程
KARMA通过九个智能体的管道式协作完成此任务,每个智能体都针对特定子任务进行了优化,其流程如图1所示。
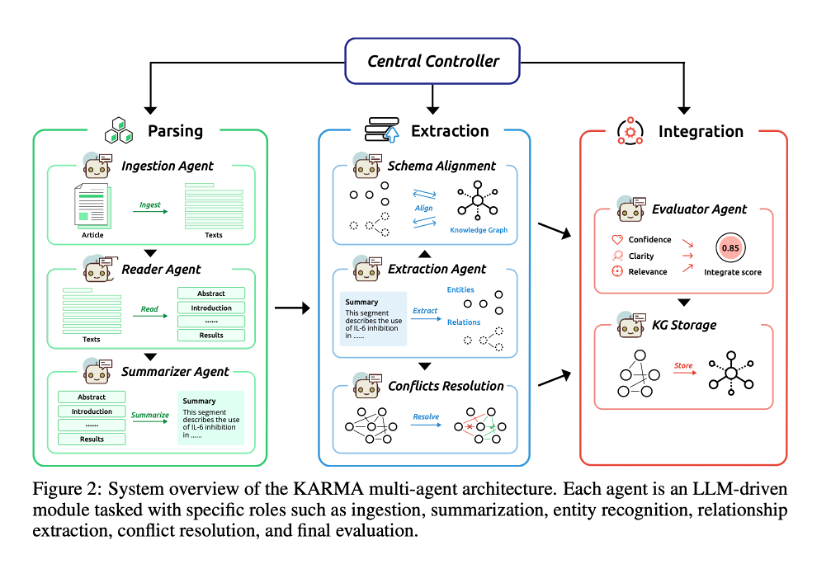
图 1 KARMA 整体流程图
1. 文档预处理智能体
摄入智能体(IA):
-
输入:原始文档(PDF/HTML)。
-
核心操作:使用LLM(如GLM-4)解析文档结构,执行
normalize(p_i)处理OCR错误和格式不一致问题,同时提取元数据metadata(p_i)(标题、作者、期刊、日期)。 -
输出:标准化文本及元数据,供下游智能体处理。
阅读智能体(RA):
-
核心操作:将文档分割为逻辑段落 。为每个段落 计算相关性分数 :其中LLM根据段落内容与当前知识图谱 中实体的关联度进行评分。
-
过滤:丢弃 的段落( 为领域特定阈值),以减少噪声。
摘要智能体(SA):
-
目的:减少计算开销,为下游提取任务提供高信噪比输入。
-
核心操作:对每个保留段落 ,生成浓缩摘要 :提示 要求LLM保留关键实体、关系和领域术语。
2. 知识提取智能体
实体提取智能体(EEA):
-
核心操作:在摘要 上执行LLM驱动的命名实体识别(NER),生成候选实体集合 :其中 表示使用领域本体(如UMLS、MeSH)进行过滤和规范化,将表面形式(如“acetylsalicylic acid”)映射为规范实体(如“Aspirin”)。
-
实体链接:对于每个新实体 ,通过最小化嵌入空间距离,将其链接到知识图谱中的现有节点 :不匹配的实体则作为候选新节点 。
关系提取智能体(REA):
-
核心操作:对于摘要 中的每个实体对 ,使用LLM分类器预测其关系 的概率分布:
-
三元组生成:选取概率超过阈值 的关系,形成候选三元组集合 。支持多标签预测,即一对实体间可能存在多种关系。
3. 知识融合智能体
模式对齐智能体(SAA):
-
任务:将EEA和REA识别出的新实体/关系类型与知识图谱现有模式对齐。
-
核心操作:对于新实体 ,SAA将其分类到预定义类型 (如
Drug,Disease):类似地,为新关系类型寻找最接近的现有关系。
冲突消解智能体(CRA):
-
任务:检测候选三元组 与知识图谱中现有三元组 的逻辑冲突。
-
核心操作:定义冲突函数 ,当检测到矛盾时,启动基于LLM的辩论机制:若结果为
Contradict,则丢弃该三元组或提交专家审核。
评估智能体(EA):
-
置信度
-
清晰度
-
相关性 其中 为sigmoid函数, 为权重。
-
任务:为每个通过冲突检测的候选三元组 计算全局质量分数,决定是否最终集成。
-
核心操作:聚合来自多个智能体的验证信号,计算三个维度的分数:
-
集成决策:若平均分超过阈值 ,则集成该三元组:

04
实验

4.1 实验设置
1. 数据集
从PubMed收集1,200篇科学文献,涵盖三个领域:
-
基因组学:720篇,关注基因变异、调控元件等
-
蛋白质组学:360篇,关注蛋白质结构、相互作用网络
-
代谢组学:120篇,关注代谢通路、代谢物分析
2. 基线模型
-
单智能体基线:使用单一LLM直接提取所有三元组
-
多模型对比:分别在GLM-4、GPT-4o、DeepSeek-v3上实现KARMA
3. 评估指标
|
指标类别 |
具体指标 |
说明 |
|
核心指标 |
平均置信度 (Average Confidence) |
新增三元组的平均置信度得分 |
|
平均清晰度 (Average Clarity) |
关系表述的明确程度 |
|
|
平均相关性 (Average Relevance) |
与领域主题的相关性 |
|
|
图统计指标 |
覆盖率增益 (Coverage Gain) |
新增实体数量 |
|
连通性增益 (Connectivity Gain) |
节点度数的净增长 |
|
|
质量指标 |
冲突比率 (Conflict Ratio ) |
因矛盾被移除的边比例 |
|
LLM正确率 (LLM-based Correctness) |
独立LLM验证的正确率 |
|
|
QA一致性 (Question-Answer Coherence) |
知识图谱问答的准确率 |
|
|
人工评分 (Human Evaluation Score) |
专家评估的质量得分 |
4.2 主要结果
1. 总体性能对比
在基因组学领域,KARMA (DeepSeek-v3) 从720篇文献中提取了 58,412个候选三元组,经过冲突消解和质量评估后,最终集成了 42,187个高质量三元组。其中,38,230个三元组包含至少一个新实体,显著扩展了图谱的覆盖范围。
各模型在不同领域上的表现如表1所示:
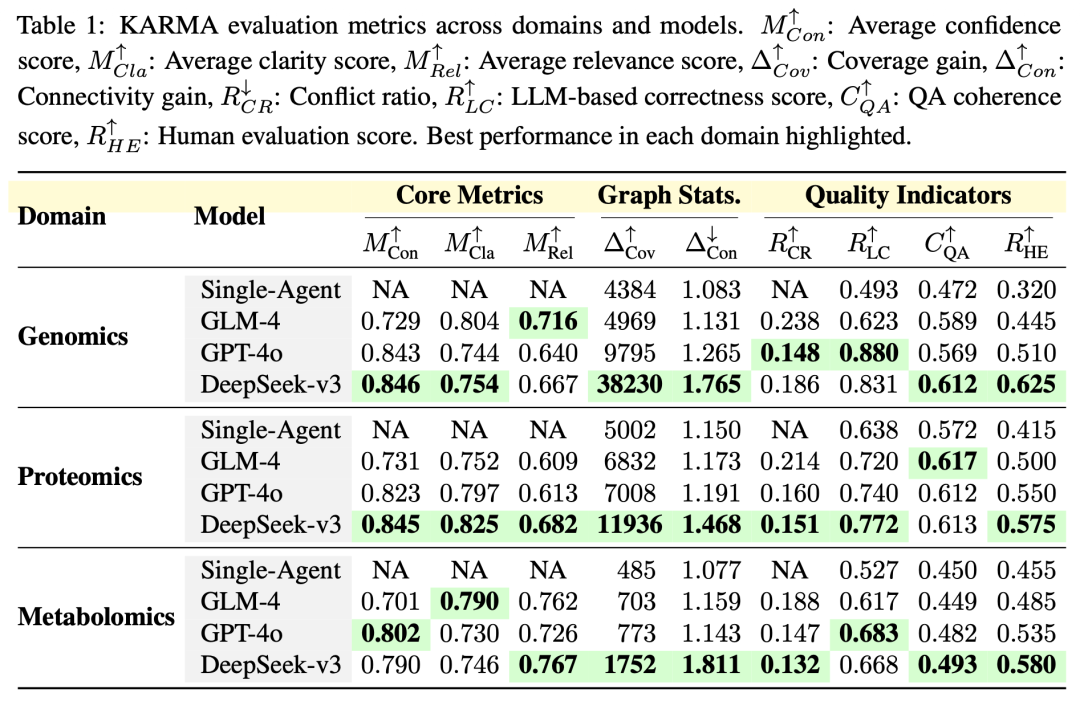
表 1 KARMA跨领域性能对比表
关键发现如下:
-
KARMA在所有指标上显著优于单智能体基线
-
DeepSeek-v3在覆盖率增益上表现最佳(基因组学38,230个新实体)
-
GPT-4o在LLM正确率上领先(基因组学88.0%)
-
多智能体协作将冲突边减少18.6%
2. 领域特异性分析
-
基因组学:数据规模最大,DeepSeek-v3展现出最佳召回率与准确率平衡
-
蛋白质组学:各模型表现相对均衡,GLM-4在QA一致性上领先
-
代谢组学:数据稀疏,但KARMA仍能有效挖掘代谢通路关系
4.3 消融实验
为验证各智能体的贡献,本文进行系统消融研究:
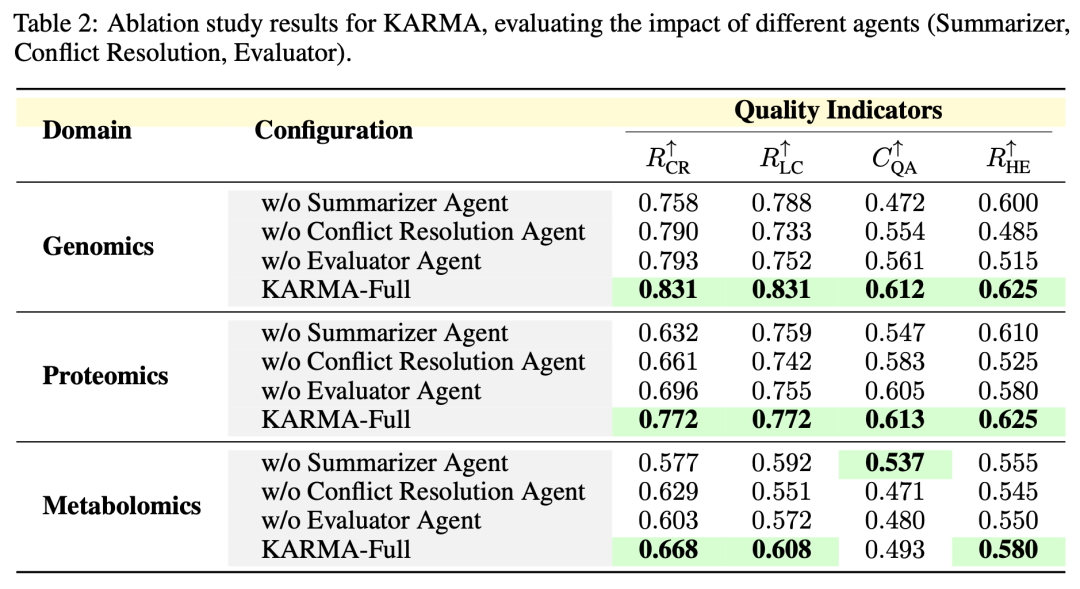
表2 消融实验结果
关键结论:
-
移除摘要智能体:噪声增加,准确率下降22.9%
-
移除冲突消解:逻辑一致性降低,QA一致性下降4.9%
-
移除评估智能体:低质量边集成,整体质量显著下降

05
总结

KARMA是一个创新的多智能体LLM框架,通过分解知识抽取任务为多个专业化智能体,实现了对科学文献的高效、准确、可解释的知识图谱增强。该框架不仅提升了抽取质量与一致性,还具备良好的领域适应性与可扩展性。实验证明其在多个生物医学领域中均优于现有方法,为自动化知识图谱构建与更新提供了有力工具。未来可进一步探索跨领域泛化、实时更新机制与更多样化的知识表示形式。
笔记整理:汪研,东南大学硕士研究生,研究方向为自然语言处理
论文链接:KARMA: Leveraging Multi-Agent LLMs for Automated Knowledge Graph Enrichment
发表会议:NeurIPS 2025

往期推荐

RECOMMEND
1
构建AI原生的科学知识图谱服务:浙大联合上海AI Lab发布SciGraph-SCP Server
2
3
OpenKG
OpenKG(中文开放知识图谱)旨在推动以中文为核心的知识图谱数据的开放、互联及众包,并促进知识图谱算法、工具及平台的开源开放。


点击阅读原文,进入 OpenKG 网站。

欢迎加入 MCP 技术社区!与志同道合者携手前行,一同解锁 MCP 技术的无限可能!
更多推荐


 7
7 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)