RAG系统中的离线解析与知识库构建
文章目录
在 RAG系统的开发中,一个常见误区是:把大部分精力投入到在线检索优化、向量数据库调优、大模型选型与提示词工程上,而忽视了离线解析与知识库构建的质量。
然而,现实是如果知识库本身质量低下,再好的检索模型也无法无中生有,再强的生成模型也会被错误或缺失的上下文误导。
离线解析阶段构建的知识库,决定了RAG系统的信息覆盖度、检索准确率、生成答案的可信度。换句话说:离线解析是 RAG的地基,地基不牢,上层建筑再华丽也无济于事。
一、离线解析的完整流程
离线解析与知识库构建通常包含以下五个核心步骤:
- 多格式文档解析:从 PDF、PPT、Word、图片、视频等原始文件中提取可读文本
- 内容清洗与规范:去除噪声、统一编码、修复乱码、规范化格式
- 文本分块(Chunking):将长文档切分为适合检索与生成的语义单元
- Embedding 向量生成:将文本块转换为向量,供语义检索使用
- 索引构建与存储:建立向量索引并持久化到向量数据库(如 Milvus、Qdrant、Pinecone)
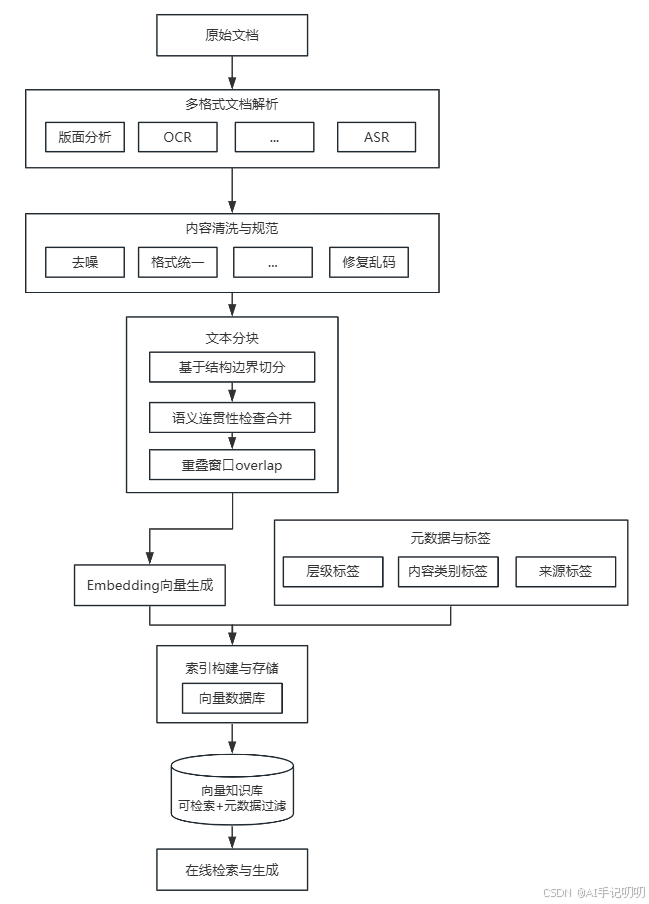
这五步环环相扣,前一步的输出质量直接决定后一步的上限
二、多格式文档解析中的常见问题
现实中的企业文档格式五花八门,每种格式都有其特点。这些典型问题又是如何去解决?
-
PDF
问题:排版复杂,多栏、表格、图文混排导致文本顺序错乱。
解决:使用版面分析技术,识别阅读顺序
如:PP-Structure、LayoutLMv3、YOLO (v8/v9) + 阅读顺序规则 -
PPT
问题:嵌入图片中的文字无法提取
解决:对图片元素做 OCR
如:PaddleOCR、Tesseract OCR、EasyOCR -
扫描件/图片
问题:OCR 会破坏表格结构、代码缩进、公式格式
解决:区域检测 + 针对性处理
如:PP-Structure(Layout Recovery)、LaTeX-OCR、LayoutParser -
视频/音频
问题:无文字信息
解决:使用 ASR转写成文本
如:Whisper、FunASR -
Markdown/HTML
问题:如何保留原始结构化信息标题层级、列表、代码块等)
解决:正则解析+保留原始结构标签
如:markdown-it、BeautifulSoup、lxml
不要使用一刀切式的解析方式。对不同格式、不同内容类型(表格/代码/自然段)应采用不同的解析策略,并在输出中保留类型标签(如<table>、<code>),为后续分块和检索提供线索。
三、文本分块
文本分块是离线解析中最影响检索效果的环节之一,也是最容易被随意处理的环节。
1. 固定长度切分
许多初版 RAG 系统采用“按固定 Token 数切块”的简单策略,这会带来典型问题:
- 语义被切断:一个完整的论点、一段逻辑完整的代码函数、一张表格,被硬生生切成两半
- 检索失败:用户问题命中后半段的词语,但后半段缺少前半段的上下文,导致召回内容不可用
- 答案质量下降:生成模型拿到不完整的上下文,容易产生幻觉或答非所问
错误示例:一段 2000 字的代码被固定 512 token 切分,导致函数定义在 chunk1,函数实现在 chunk2 , 检索时无法完整召回
正确做法:在 def/class/function 边界处切分
2. 规则 + 语义融合(推荐)
更好的做法是基于文档结构 + 语义边界进行智能切分:
- 基于结构边界:优先在标题、段落、列表项、表格行、代码块边界处切分
- 语义连贯性检查:使用小型 Embedding 模型判断相邻句子的语义相似度,相似度高的合并
- 长度平衡:设定目标块大小(如 256–1024 tokens),允许一定弹性,避免过大或过小
3. 重叠窗口(Overlap)
在切分时,让相邻块之间保留一段重叠内容(例如块大小 512token,重叠 64token):
- 好处:即使一个关键句子恰好在边界处,也会出现在两个块中,降低信息丢失风险
- 代价:向量数据库存储成本增加,检索召回量增加(需要去重或重排)
对连续性强的文档(如故事、技术论述)使用重叠窗口;对强结构化文档(如表格列表、代码)可减小或不用重叠。
四、Embedding 与索引构建
- Embedding 模型选择:根据领域(通用/中文/代码/法律/医疗)选择合适模型,如 BGE、text-embedding-3-small、GTE、text2vec-large-chinese 等
- 批量生成:注意 API 速率限制与成本控制
- 向量数据库:选择合适的索引类型(HNSW、IVF_FLAT等),平衡召回率与查询延迟
分块质量直接影响 Embedding 的语义表征能力,一个混杂了多个主题的块,其向量会变得模糊,难以被精准召回。
五、层级标签与元数据
很多 RAG系统只存储文本+向量,忽略了元数据与标签。浪费了天然的信息。
1. 层级标签(结构标签)
-
捕获文档的原始层级结构
如H1、H2、H3、一、1.1 -
内容类别标签
如表格、代码块、政策条例、步骤、定义、免责声明 -
来源标签(溯源信息)
记录每个块的出处,如文档名、页码、幻灯片编号、音频时间戳、URL
(生成答案时提供引用来源,大幅提升可信度。) -
元数据过滤的典型场景
元数据让检索从“纯语义搜索”升级为结构化过滤 + 语义搜索
(在向量数据库中为每个向量附加元数据(如 Milvus 的 expr 过滤、Pinecone的filter 过滤))
六、离线与在线的联动关系
离线解析的每一个决策,都会在在线检索与生成环节产生连锁反应
- chunk 大小:决定 LLM 单次能看到的上下文量。块太大,超过上下文窗口;块太小,丢失长期依赖
- 元数据质量:决定能否做精准的元数据过滤。元数据缺失,只能用语义检索,命中率下降
- 解析质量:直接影响 Embedding 的质量。解析错误(如乱序、错位),向量代表的是错误语义
- 标签丰富度:支持混合检索(语义+关键词+结构化)。标签越丰富,检索策略越灵活
- 重叠窗口策略:增加冗余,提高召回率,但略微增加存储与去重开销
七、总结
- 离线解析是RAG系统的地基,决定了系统的上限。地基不稳,再好的在线模型也无法弥补。
- 不要只关注在线检索与模型选型,需要花同样甚至更多的时间打磨文档解析、清洗、分块、元数据设计。
- 元数据和内容标签是实现精准检索和高可信答案的关键。
RAG 系统的竞争,最终是知识库质量的竞争。而知识库质量,始于离线解析的每一处细节。

欢迎加入 MCP 技术社区!与志同道合者携手前行,一同解锁 MCP 技术的无限可能!
更多推荐


 22
22 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)