AI开发之LangGraph教程3~懂图
很多人刚学 LangGraph 时,看不懂图、状态、节点、边、invoke、stream 这些抽象概念,看着代码只会复制粘贴,不懂底层运行逻辑。
咱们不用官方晦涩的专业术语,全程用工厂流水线 + 共享笔记本做统一类比,结合你手里这段完整示例代码,从概念 → 代码拆解 → 运行逻辑 → 三种执行方式,一步步掰开揉碎讲清楚,看完你就能彻底掌握 LangGraph 基础核心。
一、先建立统一通俗类比(记住这组对应,全程无难点)
先把 LangGraph 所有专业名词,对应成生活里的事物,后面所有讲解都围绕这个类比展开:
表格
| LangGraph 专业概念 | 生活化类比 | 核心作用 |
|---|---|---|
| 整张 Graph 流程图 | 一条固定工序的工厂流水线 | 规定好执行顺序,自动按流程跑任务 |
| State 状态 | 流水线唯一共享笔记本 | 全流程共用同一本本子,存数据、记日志,全程不更换 |
| Node 节点 | 流水线上独立的工人工位 | 每个工位负责一件具体工作,是实际干活的单元 |
| Edge 边 | 工位之间的传送履带 | 规定干完活把任务传给下一个工位,定死执行顺序 |
| START | 流水线进料入口 | 整个流程从这里正式开始触发 |
| END | 流水线成品出口 | 走到这里代表整个流程全部结束 |
| StateGraph | 流水线搭建工具 | 用来创建流水线、绑定统一笔记本、添加工位和履带 |
| compile () 编译 | 流水线组装完工 | 把零散的工位、履带拼装好,变成可以直接开机运行的成品 |
| invoke() | 一次性跑完流水线,最后给结果 | 全程静默执行,中间过程看不到,只返回最终成果 |
| stream() | 边跑流水线边实时播报 | 干完一个工位就反馈一次,能看到每一步中间过程 |
只要记住这组对应,再看代码完全没有理解门槛。
整体程序如下:
"""
LangGraph 简单图示例 - 演示 State 传递和 invoke/stream 区别
本示例创建一个包含 3 个节点的简单图:
START -> node_a -> node_b -> node_c -> END
每个节点:
- 打印简单说明
- 修改 State 中的数据
- 演示 State 在节点间的传递
最后对比 graph.invoke() 和 graph.stream() 的区别
"""
from typing import Annotated, TypedDict
from langgraph.graph import StateGraph, START, END
# ==================== 状态定义 ====================
class State(TypedDict):
"""
图的状态结构
Attributes:
counter: 计数器,每个节点递增
messages: 消息列表,记录每个节点的输出
current_node: 当前节点名称
"""
counter: int
messages: list
current_node: str
# ==================== 节点函数 ====================
def node_a(state: State) -> dict:
"""节点 A:初始化状态"""
print("\n🔵 节点 A 执行中...")
print(f" 接收到的状态: counter={state['counter']}, messages={state['messages']}")
# 修改状态
new_messages = state['messages'] + ["节点A: 初始化完成"]
print(f" 修改后状态: counter={state['counter'] + 1}")
return {
"counter": state['counter'] + 1,
"messages": new_messages,
"current_node": "node_a"
}
def node_b(state: State) -> dict:
"""节点 B:处理数据"""
print("\n🟢 节点 B 执行中...")
print(f" 接收到的状态: counter={state['counter']}, current_node={state['current_node']}")
# 修改状态
new_messages = state['messages'] + ["节点B: 数据处理完成"]
print(f" 修改后状态: counter={state['counter'] + 1}")
return {
"counter": state['counter'] + 1,
"messages": new_messages,
"current_node": "node_b"
}
def node_c(state: State) -> dict:
"""节点 C:输出结果"""
print("\n🟡 节点 C 执行中...")
print(f" 接收到的状态: counter={state['counter']}, current_node={state['current_node']}")
# 修改状态
new_messages = state['messages'] + ["节点C: 最终输出完成"]
print(f" 修改后状态: counter={state['counter'] + 1}")
return {
"counter": state['counter'] + 1,
"messages": new_messages,
"current_node": "node_c"
}
# ==================== 构建图 ====================
graph_builder = StateGraph(State)
# 添加节点
graph_builder.add_node("node_a", node_a)
graph_builder.add_node("node_b", node_b)
graph_builder.add_node("node_c", node_c)
# 添加边:START -> node_a -> node_b -> node_c -> END
graph_builder.add_edge(START, "node_a")
graph_builder.add_edge("node_a", "node_b")
graph_builder.add_edge("node_b", "node_c")
graph_builder.add_edge("node_c", END)
# 编译图
graph = graph_builder.compile()
# ==================== 演示函数 ====================
def demo_invoke():
"""
演示 graph.invoke() 方法
特点:
- 同步执行整个图
- 返回最终状态
- 无法看到中间过程
"""
print("=" * 70)
print("📌 方法一: graph.invoke()")
print("=" * 70)
print("特点: 同步执行,返回最终状态,无法看到中间过程")
print("-" * 70)
# 初始状态
initial_state = {
"counter": 0,
"messages": [],
"current_node": ""
}
print(f"\n初始状态: {initial_state}")
print("\n开始执行 invoke()...")
# 执行图
result = graph.invoke(initial_state)
print("\n" + "-" * 70)
print("invoke() 执行完成!")
print("-" * 70)
print(f"\n最终状态: {result}")
print(f"\n消息列表:")
for msg in result['messages']:
print(f" - {msg}")
print(f"\n计数器最终值: {result['counter']}")
def demo_stream():
"""
演示 graph.stream() 方法
特点:
- 流式执行
- 可以看到每个节点执行后的中间状态
- 适合长时间运行的任务
"""
print("\n\n")
print("=" * 70)
print("📌 方法二: graph.stream()")
print("=" * 70)
print("特点: 流式执行,可以看到每个节点的中间状态")
print("-" * 70)
# 初始状态
initial_state = {
"counter": 0,
"messages": [],
"current_node": ""
}
print(f"\n初始状态: {initial_state}")
print("\n开始执行 stream()...")
# 流式执行图
step = 0
for event in graph.stream(initial_state):
step += 1
print(f"\n--- 步骤 {step}: 收到事件 ---")
for node_name, node_output in event.items():
print(f" 节点名称: {node_name}")
print(f" 节点输出: {node_output}")
print("\n" + "-" * 70)
print("stream() 执行完成!")
def demo_stream_values():
"""
演示 graph.stream(values=True) 方法
特点:
- 流式执行
- 返回完整的状态快照,而不是增量更新
"""
print("\n\n")
print("=" * 70)
print("📌 方法三: graph.stream(values=True)")
print("=" * 70)
print("特点: 流式执行,返回完整状态快照")
print("-" * 70)
# 初始状态
initial_state = {
"counter": 0,
"messages": [],
"current_node": ""
}
print(f"\n初始状态: {initial_state}")
print("\n开始执行 stream(values=True)...")
# 流式执行图(返回完整状态)
step = 0
for state_snapshot in graph.stream(initial_state, stream_mode="values"):
step += 1
print(f"\n--- 步骤 {step}: 状态快照 ---")
print(f" counter: {state_snapshot['counter']}")
print(f" current_node: {state_snapshot['current_node']}")
print(f" messages: {state_snapshot['messages']}")
print("\n" + "-" * 70)
print("stream(values=True) 执行完成!")
# ==================== 主程序 ====================
if __name__ == "__main__":
# 显示图结构
print("=" * 70)
print("LangGraph 简单图示例")
print("=" * 70)
print("\n图结构 (ASCII):")
print(graph.get_graph().draw_ascii())
# 保存 PNG 图像
try:
png_data = graph.get_graph().draw_mermaid_png()
output_path = "d:\\PyProjects\\lang_graphics\\b002_graph.png"
with open(output_path, "wb") as f:
f.write(png_data)
print(f"\n图结构已保存到: {output_path}")
except Exception as e:
print(f"无法生成PNG图片: {e}")
# 演示三种执行方式
demo_invoke()
demo_stream()
demo_stream_values()
# 总结
print("\n\n")
print("=" * 70)
print("📊 总结: invoke() vs stream() 对比")
print("=" * 70)
print("""
┌─────────────────┬────────────────────────┬────────────────────────┐
│ 方法 │ invoke() │ stream() │
├─────────────────┼────────────────────────┼────────────────────────┤
│ 执行方式 │ 同步,阻塞 │ 流式,非阻塞 │
│ 返回值 │ 最终状态 │ 每个节点的事件流 │
│ 中间状态 │ 不可见 │ 可见 │
│ 适用场景 │ 快速获取结果 │ 长时间任务、进度显示 │
│ 用户体验 │ 等待时间长 │ 实时反馈 │
└─────────────────┴────────────────────────┴────────────────────────┘
""")
其执行结果如下:
======================================================================
LangGraph 简单图示例
======================================================================
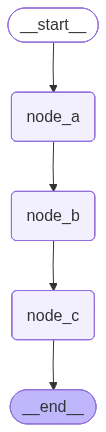
图结构 (ASCII):
+-----------+
| __start__ |
+-----------+
*
*
*
+--------+
| node_a |
+--------+
*
*
*
+--------+
| node_b |
+--------+
*
*
*
+--------+
| node_c |
+--------+
*
*
*
+---------+
| __end__ |
+---------+
图结构已保存到: d:\PyProjects\lang_graphics\b002_graph.png
======================================================================
📌 方法一: graph.invoke()
======================================================================
特点: 同步执行,返回最终状态,无法看到中间过程
----------------------------------------------------------------------
初始状态: {'counter': 0, 'messages': [], 'current_node': ''}
开始执行 invoke()...
🔵 节点 A 执行中...
接收到的状态: counter=0, messages=[]
修改后状态: counter=1
🟢 节点 B 执行中...
接收到的状态: counter=1, current_node=node_a
修改后状态: counter=2
🟡 节点 C 执行中...
接收到的状态: counter=2, current_node=node_b
修改后状态: counter=3
----------------------------------------------------------------------
invoke() 执行完成!
----------------------------------------------------------------------
最终状态: {'counter': 3, 'messages': ['节点A: 初始化完成', '节点B: 数据处理完成', '节点C: 最终输出完成'], 'current_node': 'node_c'}
消息列表:
- 节点A: 初始化完成
- 节点B: 数据处理完成
- 节点C: 最终输出完成
计数器最终值: 3
======================================================================
📌 方法二: graph.stream()
======================================================================
特点: 流式执行,可以看到每个节点的中间状态
----------------------------------------------------------------------
初始状态: {'counter': 0, 'messages': [], 'current_node': ''}
开始执行 stream()...
🔵 节点 A 执行中...
接收到的状态: counter=0, messages=[]
修改后状态: counter=1
--- 步骤 1: 收到事件 ---
节点名称: node_a
节点输出: {'counter': 1, 'messages': ['节点A: 初始化完成'], 'current_node': 'node_a'}
🟢 节点 B 执行中...
接收到的状态: counter=1, current_node=node_a
修改后状态: counter=2
--- 步骤 2: 收到事件 ---
节点名称: node_b
节点输出: {'counter': 2, 'messages': ['节点A: 初始化完成', '节点B: 数据处理完成'], 'current_node': 'node_b'}
🟡 节点 C 执行中...
接收到的状态: counter=2, current_node=node_b
修改后状态: counter=3
--- 步骤 3: 收到事件 ---
节点名称: node_c
节点输出: {'counter': 3, 'messages': ['节点A: 初始化完成', '节点B: 数据处理完成', '节点C: 最终输出完成'],'current_node': 'node_c'}
----------------------------------------------------------------------
stream() 执行完成!
======================================================================
📌 方法三: graph.stream(values=True)
======================================================================
特点: 流式执行,返回完整状态快照
----------------------------------------------------------------------
初始状态: {'counter': 0, 'messages': [], 'current_node': ''}
开始执行 stream(values=True)...
--- 步骤 1: 状态快照 ---
counter: 0
current_node:
messages: []
🔵 节点 A 执行中...
接收到的状态: counter=0, messages=[]
修改后状态: counter=1
--- 步骤 2: 状态快照 ---
counter: 1
current_node: node_a
messages: ['节点A: 初始化完成']
🟢 节点 B 执行中...
接收到的状态: counter=1, current_node=node_a
修改后状态: counter=2
--- 步骤 3: 状态快照 ---
counter: 2
current_node: node_b
messages: ['节点A: 初始化完成', '节点B: 数据处理完成']
🟡 节点 C 执行中...
接收到的状态: counter=2, current_node=node_b
修改后状态: counter=3
--- 步骤 4: 状态快照 ---
counter: 3
current_node: node_c
messages: ['节点A: 初始化完成', '节点B: 数据处理完成', '节点C: 最终输出完成']
----------------------------------------------------------------------
stream(values=True) 执行完成!
======================================================================
📊 总结: invoke() vs stream() 对比
======================================================================
┌─────────────────┬────────────────────────┬────────────────────────┐
│ 方法 │ invoke() │ stream() │
├─────────────────┼────────────────────────┼────────────────────────┤
│ 执行方式 │ 同步,阻塞 │ 流式,非阻塞 │
│ 返回值 │ 最终状态 │ 每个节点的事件流 │
│ 中间状态 │ 不可见 │ 可见 │
│ 适用场景 │ 快速获取结果 │ 长时间任务、进度显示 │
│ 用户体验 │ 等待时间长 │ 实时反馈 │
└─────────────────┴────────────────────────┴────────────────────────┘
并生成图(png):
二、逐个精讲核心基础概念
1. TypedDict 类型字典
专业定义Python 提供的类型工具,用来自定义规范字典的结构,强制规定字典必须包含哪些键、每个键对应什么数据类型。
通俗解释普通 Python 字典很随意,随便乱写键名、乱存数字字符串;TypedDict 就是给字典立规矩、定模板:只能有指定的几个字段,每个字段是什么类型都不能乱改。
程序中的作用我们用它定义 State,相当于提前规定好:整张流水线的共享笔记本,只能有 counter、messages、current_node 三项内容,不能随意新增或乱改格式。
2. State 状态
专业定义LangGraph 流程图的全局共享数据容器,贯穿所有节点,是全图统一的数据存储中心。
通俗解释就是流水线那本唯一的共享笔记本:
- 整条流水线从头到尾,只用这一本本子;
- 每个工位都能翻看本子读取数据;
- 每个工位都能修改本子上的内容;
- 框架会自动把修改后的本子传给下一个工位,不用我们手动传参、赋值。
本程序 State 结构说明
counter: int:计数器,每经过一个工位就加 1,记录流程走了几步;messages: list:消息日志列表,记录每个工位的工作记录;current_node: str:标记当前正在干活的工位名称。
3. StateGraph 图构造器
专业定义LangGraph 核心构建类,用于初始化流程图、绑定全局状态、管理节点与流向。
通俗解释专门用来搭建流水线的工具。创建时必须传入 State,相当于给流水线绑定规则:整条流水线所有工位,必须统一使用这本共享笔记本,不能各用各的。
4. Node 节点
专业定义流程图中最小的可执行单元,本质是普通 Python 函数,负责具体业务逻辑处理与状态更新。
通俗解释流水线上一个个独立的工人工位。每个节点都是一个独立函数,遵循固定规则:
- 自动接收框架传过来的共享状态(笔记本);
- 读取笔记本里的数据,做自己的业务处理;
- 处理完成后,返回修改后的内容,由框架自动更新到全局笔记本。
本程序里 node_a、node_b、node_c 就是三个各司其职的工位。
5. Edge 边
专业定义用于定义节点之间的执行流向,指定流程执行的先后顺序。
通俗解释工位之间连接的传送履带。没有边的话,各个工位都是孤立的,不会自动流转;加了边,就定死了谁干完活、传给谁,形成固定流程。
6. START / END 内置标记
专业定义LangGraph 内置常量,分别代表流程图的起始入口和终止出口。
通俗解释
START:流水线的进料口,程序从这里触发,进入第一个工位;END:流水线的收尾出口,流程走到这里,直接结束整个执行。
7. 图编译 compile ()
专业定义将搭建好的节点、流向关系,编译为可调度、可直接运行的流程图实例。
通俗解释我们手动加完工位、连好履带后,流水线还是零散的;调用 compile() 就是一键组装完工,把所有结构整合起来,变成可以直接开机运行的完整流水线。
8. 状态自动更新机制
专业定义节点返回字典后,LangGraph 自动将增量数据合并更新到全局 State 中,并自动向下游节点传递。
通俗解释工人在工位改完笔记本后,只需要把修改的内容交上去就行;框架会自动帮你把内容写到共享笔记本上,再自动传给下一个工位,全程不用自己写赋值、传参代码。
9. 三种执行模式
- graph.invoke():阻塞式一次性执行,跑完整张流程,只返回最终状态,看不到中间步骤;
- graph.stream():流式分步执行,每跑完一个节点,立刻返回当前节点的执行结果;
- graph.stream(stream_mode="values"):流式执行,每跑完一个节点,返回整本笔记本的完整状态快照,能清晰看到数据一步步变化。
三、逐段拆解完整源码(概念 + 代码一一对应)
1. 导入依赖模块
python
运行
from typing import Annotated, TypedDict
from langgraph.graph import StateGraph, START, END
- 导入
TypedDict:用来定义状态模板; - 导入
StateGraph:流水线搭建工具; - 导入
START/END:流程起始和结束标记。
2. 定义全局状态 State
python
运行
class State(TypedDict):
counter: int
messages: list
current_node: str
用 TypedDict 立下规矩:全局共享笔记本只有三个固定字段,全图所有节点都要遵守这个格式。
3. 定义三个节点(工人工位)
以 node_a 为例,三个节点逻辑结构完全一致:
python
运行
def node_a(state: State) -> dict:
print("\n🔵 节点 A 执行中...")
# 1. 自动接收上一步传过来的共享状态
print(f" 接收到的状态: counter={state['counter']}, messages={state['messages']}")
# 2. 读取状态、处理业务逻辑
new_messages = state['messages'] + ["节点A: 初始化完成"]
print(f" 修改后状态: counter={state['counter'] + 1}")
# 3. 返回修改内容,框架自动更新全局状态
return {
"counter": state['counter'] + 1,
"messages": new_messages,
"current_node": "node_a"
}
通用规则
- 函数第一个参数固定为
state: State,框架自动注入当前全局状态; - 不能直接修改原
state,只能读取后生成新数据; - 通过
return 字典的方式,告知框架需要更新哪些字段。
node_b、node_c 同理,依次完成计数累加、日志记录、节点标记。
4. 搭建并编译流程图
python
运行
# 1. 创建流水线搭建工具,绑定全局状态
graph_builder = StateGraph(State)
# 2. 添加工位(节点)
graph_builder.add_node("node_a", node_a)
graph_builder.add_node("node_b", node_b)
graph_builder.add_node("node_c", node_c)
# 3. 安装传送履带(边),定执行顺序
graph_builder.add_edge(START, "node_a")
graph_builder.add_edge("node_a", "node_b")
graph_builder.add_edge("node_b", "node_c")
graph_builder.add_edge("node_c", END)
# 4. 组装流水线,变成可运行实例
graph = graph_builder.compile()
流程顺序固定:START → node_a → node_b → node_c → END,严格按顺序自动流转。
5. 初始状态初始化
python
运行
initial_state = {
"counter": 0,
"messages": [],
"current_node": ""
}
给共享笔记本初始化空白状态:计数器从 0 开始,日志为空,暂无执行节点。
6. 三种执行方式演示函数
(1)demo_invoke () 演示一次性执行
启动流水线后,程序阻塞等待,一口气跑完所有节点,全部结束后只返回最终的完整状态,完全看不到中间每个节点的执行过程。
(2)demo_stream () 演示基础流式执行
按节点顺序逐个执行,跑完一个节点就立刻返回该节点的增量结果,可以清晰看到每个工位单独的输出。
(3)demo_stream_values () 演示状态快照流式执行
同样分步执行,但每次返回整本共享笔记本的完整数据,能直观看到 counter、messages 从初始到最终的每一步变化,是调试代码最常用的模式。
7. 主程序入口
运行后自动打印流程图结构、保存流程图图片,依次执行三种演示方式,最后汇总对比表格,直观展示三种执行模式的差异。
四、三种执行模式深度对比(结合运行效果)
1. graph.invoke()
- 执行特点:同步阻塞、全程静默跑完所有节点;
- 返回内容:只返回流程结束后的最终完整状态;
- 运行表现:三个节点连续执行,控制台只打印过程日志,最后统一出结果;
- 适用场景:简单任务、不需要看中间进度、只想要最终结果。
2. graph.stream()
- 执行特点:分步流式执行,一个节点执行完毕就触发一次返回;
- 返回内容:每次返回当前节点的单独输出;
- 运行表现:执行完 node_a 立刻推送结果,再执行 node_b、node_c,一步一反馈;
- 适用场景:聊天交互、长时间任务、需要实时展示执行进度。
3. graph.stream(stream_mode="values")
- 执行特点:和普通 stream 一样分步执行;
- 返回内容:每次返回全局完整状态快照,包含所有字段的最新值;
- 运行表现:能看到状态从初始 → node_a 后 → node_b 后 → node_c 后的完整变化;
- 适用场景:代码调试、学习状态流转、排查流程异常。
五、整张流程图完整运行全流程复盘
- 定义
State:定制全局共享笔记本的格式; - 编写节点函数:搭建三个独立工位,实现状态读取与修改;
- 创建
StateGraph:初始化流水线,并绑定统一笔记本; - 添加节点、添加边:布置工位、连接传送履带,固定执行顺序;
- 调用
compile():组装流水线,生成可运行实例; - 定义初始状态:给笔记本初始化空白数据;
- 调用 invoke/stream:启动流水线;
- 框架自动流转:从 START 进入,依次执行 node_a → node_b → node_c,最后到 END 结束;
- 全程自动传递、自动更新全局状态,无需手动处理数据流转。
六、核心知识点总结(通俗口诀)
- TypedDict 给状态定规矩,State 是全图共享笔记本;
- Node 是干活工位,Edge 是流转传送带;
- START 是流程入口,END 是流程终点;
- StateGraph 搭建流水线,compile 组装就能跑;
- 节点接收状态读数据,return 字典改数据;
- invoke 一口气跑完只给结果,stream 一步一反馈看过程;
- stream 带 values 看完整状态快照,调试学习最实用。

欢迎加入 MCP 技术社区!与志同道合者携手前行,一同解锁 MCP 技术的无限可能!
更多推荐

 14
14 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)